论文地址:https://arxiv.org/abs/2405.14867
项目官网:https://tianweiy.github.io/dmd2/
代码地址:https://github.com/tianweiy/DMD2
发表时间:2024年5月24日

分布匹配蒸馏(DMD)生成的一步生成器能够与教师模型在分布上保持一致,即蒸馏过程不会强制要求其采样轨迹与教师模型形成一一对应关系。然而,为确保实际训练的稳定性,DMD需要通过大量噪声-图像对计算额外的回归损失。这些噪声-图像对由教师模型通过多步骤确定性采样器生成。这不仅在大规模文本到图像合成中计算成本高昂,还限制了学生模型的质量,使其与教师模型的原始采样路径过于紧密绑定。
- 首先,我们消除了回归损失和构建昂贵数据集的需求。研究表明,由此产生的不稳定性源于“伪”评价器未能准确估计生成样本的分布特征,为此我们提出双时间尺度更新规则作为解决方案。
- 其次,我们将GAN损失整合到蒸馏过程中,用于区分生成样本与真实图像。这使得学生模型能在真实数据上进行训练,从而缓解教师模型“真实”分数估计的不准确性,进而提升生成质量。
- 第三,提出了一种创新的训练方法,通过在训练过程中模拟推理阶段生成器样本,实现了学生模型的多步采样,并有效解决了先前研究中存在的训练与推理输入不匹配问题。
DMD2:在ImageNet-64×64数据集上FID分数达到1.28,在零样本COCO 2014数据集上FID分数为8.35。推理成本降低了500%×,超越了原始教师模型。
此外,通过提炼SDXL方法展示了该方案能生成百万像素级图像,其视觉质量在少步长方法中表现卓越,甚至超越了原始教师模型。
1 Introduction
扩散模型在效果上非常好,但是推理成本偏高。现有的少步数推理方法往往导致质量下降(学生模型通过学习教师模型的成对噪声与图像映射关系,却难以完美复现其行为特征)。
DMD方法,其核心目标在于与教师模型在分布层面上达成一致——通过最小化学生模型与教师模型输出分布之间的Jensen-Shannon(JS)散度或近似Kullback-Leibler(KL)散度,而非需要精确学习从噪声到图像的具体路径。尽管DMD已取得业界领先成果,但相较于基于生成对抗网络(GAN)的方法[23-29],其研究热度仍显不足。究其原因,DMD仍需额外引入回归损失来确保训练稳定性。这要求教师模型的采样生成数百万组噪声-图像配对,这对文本到图像合成而言成本尤为高昂。此外,回归损失还削弱了DMD非配对分布匹配目标的核心优势——由于这种机制的存在,学生模型的质量上限会被教师模型所制约。
本文提出了一种在保持训练稳定性的同时消除DMD回归损失的方法。通过将GAN框架整合到DMD中,突破了分布匹配的极限,并开发出名为“逆向模拟”的创新训练流程实现少步长采样。综合来看,我们的研究成果构建了最先进的快速生成模型,仅需四步采样即可超越原始模型。
DMD2在单步图像生成领域取得突破性进展:在ImageNet-64×64数据集上FID值达1.28,在零样本COCO 2014数据集上达到8.35,创下新标杆。我们还通过从SDXL蒸馏生成高质量百万像素图像,验证了该方法的可扩展性,为少步长方法树立了新标准。
简而言之,我们的主要贡献包括:
- DMD2,无需依赖回归损失即可实现稳定训练,从而省去昂贵的数据收集环节,使训练过程更加灵活且可扩展。
- 通过实验证明,DMD框架[22]中不使用回归损失导致的训练不稳定源于伪扩散判别器训练不足,并提出双时间尺度更新规则来解决该问题。
- 将生成对抗网络(GAN)目标整合到DMD框架中,通过训练判别器区分学生生成器与真实图像样本。这种在分布层面施加的额外监督机制,比原始回归损失更符合DMD的分布匹配理念,有效缓解了教师扩散模型的近似误差并提升了图像质量。
- 在原有仅支持单步生成器的DMD基础上,我们创新性地引入多步生成器支持技术。与以往的多步蒸馏方法不同,通过在训练过程中模拟推理时的生成器输入,避免了训练与推理之间的领域不匹配问题,从而提升了整体性能。
2 Related Work
Diffusion Distillation. 近年来,扩散加速技术主要聚焦于通过蒸馏法提升生成过程的效率[9,10,13-20,22,23,30]。这类方法通常训练生成器以更少的采样步骤逼近教师模型的常微分方程(ODE)采样轨迹。值得注意的是,Luhman等人[16]预先计算了由教师模型使用ODE采样器生成的噪声与图像配对数据集,并利用该数据集训练学生模型在单次网络评估中进行映射回归。后续研究如渐进式蒸馏[10,13]则无需离线预计算这种配对数据集,而是通过迭代训练一系列学生模型,每个模型的采样步骤数量都比前序模型减半。互补技术Instaflow [11]通过拉直ODE轨迹,使得单步学生模型更容易逼近。一致性蒸馏[9,12,19,26,31,32]和TRACT [33]则训练学生模型使其输出在ODE轨迹的任意时间步都保持自洽性,从而与教师模型保持一致。
GANs 另一项研究采用对抗训练方法,使生成器与判别器在更广泛的分布层面上达成对齐。在ADD模型[23]中,生成器初始权重来自扩散模型,通过附加分类器[34]GAN目标函数进行训练。在此基础上,LADD模型[24]采用预训练扩散模型作为判别器,并在潜在空间中运行,从而提升可扩展性并实现更高分辨率的合成。受DiffusionGAN [28,29]启发,UFOGen模型[25]在判别器的真实与伪造分类前引入噪声注入机制,通过平滑分布来稳定训练动态。近期部分研究将对抗目标与蒸馏损失相结合,以保持原始采样轨迹。例如,SDXL-Lightning模型[27]将DiffusionGAN损失[25]与渐进式蒸馏目标[10,13]整合;而一致性轨迹模型[26]则将生成对抗网络[35]与改进的一致性蒸馏[9]相结合。
Score Distillation 该方法最初应用于文本到三维合成领域[36-39],通过预训练的文本到图像扩散模型作为分布匹配损失函数。这些方法利用预训练扩散模型预测的分数,将渲染视图与文本条件下的图像分布进行对齐,从而优化三维物体。近期研究将分数蒸馏技术[36,37,40-42]拓展为扩散蒸馏[22,43-45]。值得注意的是,DMD [22]通过最小化近似KL散度实现优化,其梯度由两个分数函数的差异构成:一个是固定且预训练的,用于目标分布;另一个则是动态训练的,用于生成器输出分布。
3 Background: Diffusion and Distribution Matching Distillation
扩散模型通过迭代去噪生成图像:在正向扩散过程中,噪声会逐步叠加到样本x∼prealx∼p_{real}x∼preal上,使其从数据分布中逐渐转化为纯高斯噪声,整个过程分为预定的T个步骤。
因此,在每个时间步t,扩散后的样本遵循分布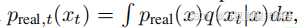
,其中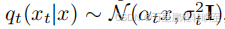
,αt和σt是根据噪声调度确定的标量[46,47]。扩散模型通过学习逆向推导去噪过程,根据当前噪声样本xt和时间步t预测去噪估计值µ(xt,t),最终从数据分布prealp_{real}preal生成图像。训练完成后,该去噪估计值与扩散分布的数据似然函数梯度(即评分函数[47])相关联:

对图像进行采样通常需要几十到几百个去噪步骤。
Distribution Matching Distillation (DMD) 通过最小化扩散目标分布prealp_{real}preal,t与生成器输出分布pfakep_{fake}pfake,t之间近似Kullback-Liebler(KL)散度在时间t上的期望值,该方法将多步骤扩散模型简化为单步生成器G [22]。由于DMD通过梯度下降训练生成器,仅需计算该损失函数的梯度,而该梯度可通过两个评分函数的差值来实现:

其中z∼N(0,I)是随机高斯噪声输入,θ为生成器参数,F表示前向扩散过程(即噪声注入),其噪声水平对应时间步t,sreals_{real}sreal和sfakes_{fake}sfake则是基于各自分布训练的扩散模型µrealµ_{real}µreal和µfakeµ_{fake}µfake所近似得到的分数(公式(1))。DMD采用冻结的预训练扩散模型作为µrealµ_{real}µreal(教师模型),在训练生成器G时动态更新µfakeµ_{fake}µfake,通过使用去噪分数匹配损失函数对一步生成器的样本(即假数据)进行优化[22,46]。
YIN等人[22]发现,为了对分布匹配梯度(公式(2))进行正则化并获得高质量的一步模型,需要引入额外的回归项[16]。为此,他们构建了一个噪声-图像配对数据集(z,y),其中图像y是通过教师扩散模型生成的,并采用确定性采样器[48,49,52]从噪声图z开始生成。当输入相同的噪声z时,回归损失函数会将生成器输出与教师模型的预测结果进行对比:
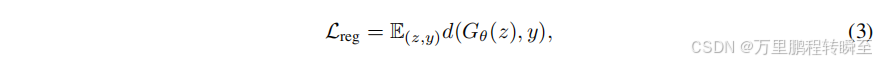
其中d表示距离函数,例如LPIPS [53]在其实现中采用的方案。在大规模文本到图像合成任务或具有复杂条件约束的模型中,这会成为重大瓶颈[54-56]。以SDXL [57]为例,生成一对噪声-图像样本需要约5秒时间,若要覆盖Yin等人[22]使用的LAION 6.0数据集[58]中的1200万条提示,累计耗时将达700个A100天。仅数据构建成本就已超过我们总训练计算量的4倍×(详见附录F)。这种正则化目标与DMD匹配师生分布的目标存在矛盾,因为它会促使学习者遵循教师的采样路径。
4 Improved Distribution Matching Distillation
我们重新审视了DMD算法[22]中的多个设计选择,并确定了显著的改进。
我们的方法将复杂的扩散模型(灰色,右)提炼为单步或多步生成器(红色,左)。训练过程包含两个交替步骤:1.使用隐式分布匹配目标(红色箭头)的梯度和GAN损失(绿色)优化生成器;2.训练评分函数(蓝色)来建模生成器产生的“假”样本分布,并训练GAN判别器(绿色)以区分假样本与真实图像。如图所示,学生生成器可以是单步或多步模型,并包含中间步骤输入。

4.1 Removing the regression loss: true distribution matching and easier large-scale training
DMD [22]中使用的回归损失函数[16]虽然能确保模式覆盖和训练稳定性,但设计使得大规模蒸馏过程变得复杂,并且与分布匹配的核心理念相悖,从而从根本上限制了蒸馏生成器的表现水平,使其只能达到教师模型的水平。我们的首个改进方案就是移除这个损失项。
4.2 Stabilizing pure distribution matching with a Two Time-scale Update Rule
若直接从DMD中省略公式(3)所示的回归目标函数,会导致训练过程不稳定且质量显著下降(见表3)。

例如我们发现生成样本的平均亮度及其他统计指标会出现剧烈波动,始终无法收敛到稳定状态(详见附录C)。我们认为这种不稳定源于伪扩散模型µfakeµ_{fake}µfake的近似误差——由于该模型基于生成器非平稳输出分布进行动态优化,无法准确追踪伪分数。
这种误差不仅导致近似偏差,还会产生生成器梯度偏移(如文献[30]所述)。为此我们采用受Heusel等人[59]启发的双时标更新规则:通过不同频率训练µfakeµ_{fake}µfake和生成器G,确保µfakeµ_{fake}µfake能精准追踪生成器输出分布。实验表明,在每个生成器更新周期内进行5次伪分数更新(不包含回归损失),既能保持良好稳定性,又能达到与ImageNet上原始DMD相当的质量水平(见表3)。
4.3 Surpassing the teacher model using a GAN loss and real data
DMD2在训练稳定性与性能表现方面已达到与DMD [22]相当的水平,且无需构建昂贵的数据集(表3)。但蒸馏生成器与教师扩散模型之间仍存在性能差距。我们推测这种差异可能源于DMD所使用的实数评分函数µrealµ_{real}µreal中存在近似误差,这些误差会传导至生成器并导致次优结果。由于DMD的蒸馏模型从未使用真实数据进行训练,因此无法从这些误差中恢复。
为解决这一问题,我们在模型训练流程中引入了额外的GAN目标函数。通过训练判别器来区分真实图像与生成器生成的图像,经过真实数据训练的GAN分类器能够突破教师网络的局限性,使生成器在样本质量上超越其性能。我们将GAN分类器整合到深度弥散模型(DMD)时采用了极简设计:在6层假扩散去噪器瓶颈层之上添加分类分支(见图3)。
该分类分支与UNet编码器上游特征通过最大化标准非饱和GAN目标函数进行训练:
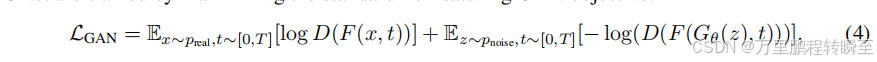
其中D表示判别器,F是第3节定义的前向扩散过程(即噪声注入),其噪声强度对应时间步t。生成器G通过最小化该目标函数实现优化。我们的设计灵感来源于先前使用扩散模型作为判别器的研究[24,25,27]。需要指出的是,这种GAN目标函数更符合分布匹配的哲学理念,因为它不需要配对数据,并且独立于教师的采样轨迹。
4.4 Multi-step generator
通过本次改进方案,我们在ImageNet和COCO数据集上实现了与教师扩散模型相媲美的性能表现(详见表1和表5)。但研究发现,像SDXL [57]这类大容量模型仍难以被整合到单步生成器中——这既源于模型容量的限制,也由于从噪声到高度多样化且细节丰富的图像之间存在复杂的优化路径。这一发现促使我们对DMD算法进行扩展,使其支持多步采样机制。
我们预先设定了一个包含N个时间步(t1,t2,…tN)的固定时间表,在训练和推理阶段保持一致。在推理过程中,每个步骤都会交替执行去噪与噪声注入操作,遵循一致性模型[9]以提升样本质量。具体来说,从高斯噪声z0∼N(0,I)开始,我们交替进行去噪更新xˆti=Gθ(xti,ti)和前向扩散步骤 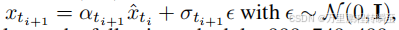
,直至生成最终图像xˆtN。我们的四步模型采用以下时间表:教师模型经过1000步训练后,对应的时间步数分别为999、749、499和249。
4.5 Multi-step generator simulation to avoid training/inference mismatch
以往的多步生成器通常被训练用于去噪含噪真实图像[23,24,27]。然而在推理过程中,除了从纯噪声开始的第一步外,生成器的输入都来自前一步生成器的采样步骤xˆti。这种训练与推理的不匹配会严重影响质量(图4)。我们通过用当前学生生成器运行若干步骤后产生的含噪合成图像xtix_{ti}xti替代训练时的含噪真实图像来解决这个问题,其推理流程与第4.4节所述相似。
 这种方法具有可处理性,因为与教师扩散模型不同,我们的生成器仅运行少量步骤。随后生成器对这些模拟图像进行去噪处理,并通过提出的损失函数对输出进行监督。使用含噪合成图像避免了训练与推理的不匹配问题,从而提升了整体性能。
这种方法具有可处理性,因为与教师扩散模型不同,我们的生成器仅运行少量步骤。随后生成器对这些模拟图像进行去噪处理,并通过提出的损失函数对输出进行监督。使用含噪合成图像避免了训练与推理的不匹配问题,从而提升了整体性能。
同期研究Imagine Flash[60]提出了类似技术方案。该团队的逆向蒸馏算法与我们的思路一致,都希望通过在训练阶段使用学生模型生成的图像作为后续采样步骤的输入,来缩小训练集与测试集之间的差距。但他们的方法未能彻底解决数据不匹配问题——由于回归损失函数中的教师模型从未接触过合成图像,导致训练-测试鸿沟持续存在。这种误差会沿着采样路径不断累积。相比之下,我们提出的分布匹配损失函数完全独立于学生模型的输入参数,从而有效缓解了这一缺陷。
4.6 Putting everything together
DMD2突破了DMD [22]对预计算噪声-图像配对的严苛要求。该方法进一步整合了生成对抗网络(GAN)的优势,并支持多步骤生成器的构建。如图3所示,DMD2以预训练的扩散模型为起点,交替优化生成器Gθ以最小化原始分布匹配目标和GAN目标,并µfakeµ_{fake}µfake使用去噪分数匹配目标对假数据进行优化,同时采用GAN分类损失来优化伪分数估计器。为确保在线优化过程中伪分数估计的准确性和稳定性,我们将其更新频率设置得比生成器更高(5步对比1步)。
5 Experiments
我们通过多个基准测试评估DMD2方法,包括在ImageNet-64×64数据集[61]上进行类别条件图像生成,以及使用多种教师模型[1,57]在COCO 2014数据集[62]上进行文本到图像合成。采用Fréchet Inception Distance (FID)[59]衡量图像质量与多样性,并用CLIP分数[63]评估文本到图像的对齐效果。
针对SDXL模型,我们额外报告了补丁FID [27,64]指标——该指标通过299x中心裁剪补丁对图像进行FID计算,用于评估高分辨率细节表现。最后通过人工评估将本方法与现有前沿技术进行对比。综合评估结果表明,采用本方法训练的蒸馏模型不仅超越了先前研究,甚至能与教师模型的性能相媲美。详细的训练和评估流程详见附录。
5.1 Class-conditional Image Generation
表1展示了我们在ImageNet-64×64数据集上对模型的性能对比。通过单次前向传播,我们的方法不仅显著超越了现有的蒸馏技术,甚至在使用ODE采样器[52]时还超越了教师模型。这一卓越表现主要归功于两个关键改进:首先移除了DMD的回归损失(第4.1和4.2节),消除了ODE采样器带来的性能上限限制;其次引入了额外的GAN项(第4.3节),有效缓解了教师扩散模型评分近似误差带来的负面影响。

5.2 Text-to-Image Synthesis
我们在零样本COCO 2014数据集[62]上评估了DMD2的文本到图像生成性能。生成器分别通过蒸馏SDXL [57]和SD v1.5 [1]进行训练,使用来自LAION-Aesthetics [58]的300万条提示子集。此外,我们从LAIONAesthetic中收集了50万张图像作为GAN判别器的训练数据。表2总结了SDXL模型的蒸馏结果。

我们的四步生成器能够产出高质量且多样化的样本,FID达到了19.32,CLIP 得分为0.322。在图像质量与提示一致性方面,我们的模型与教师扩散模型形成竞争。为验证方法的有效性,我们通过大量用户研究将模型输出与教师模型及现有蒸馏方法进行对比。实验采用PartiPrompts [69]数据集中的128个提示子集,并遵循LADD [24]方法进行评估。
每次对比时,我们随机选取五位评审员,让他们分别选出视觉效果更佳的图像及最符合文本提示的图像。具体评估细则详见附录H。如图5所示,我们的模型在用户偏好度上显著优于基线方法。值得注意的是,在24%的样本中,我们的模型在图像质量上超越了教师模型,同时保持了相当的提示一致性,且仅需25×次前向传播(4次对比100次)。定性对比结果见图6。SDv1.5的测试数据详见附录A表5。同样地,使用DMD2训练的一步法模型表现超越所有传统扩散加速方法,FID分数达到8.35,较原始DMD方法[22]提升3.14分。我们的结果也优于采用50步PNDM采样器[49]的教师模型。

5.3 Ablation Studies
表3展示了我们在ImageNet数据集上对所提方法不同组件的消融实验。若直接从原始DMD方法中移除ODE回归损失,由于训练不稳定导致FID值下降至3.48。但通过引入我们的双时间尺度更新规则,这一性能下滑得到有效缓解,在无需额外构建数据集的情况下达到了与DMD基线相当的水平。加入生成对抗网络(GAN)损失项后,FID值进一步提升了1.1分。综合方案的表现明显优于单独使用GAN(未结合分布匹配目标),而将双时间尺度更新规则添加到纯GAN模型中也未能带来改善,这充分证明了在统一框架下融合分布匹配与GAN的有效性。

在表4中,我们通过消融实验验证了生成对抗网络(GAN)项(第4.3节)、分布匹配目标函数(公式2)以及反向模拟(第4.4节)对SDXL模型四步生成器的影响。

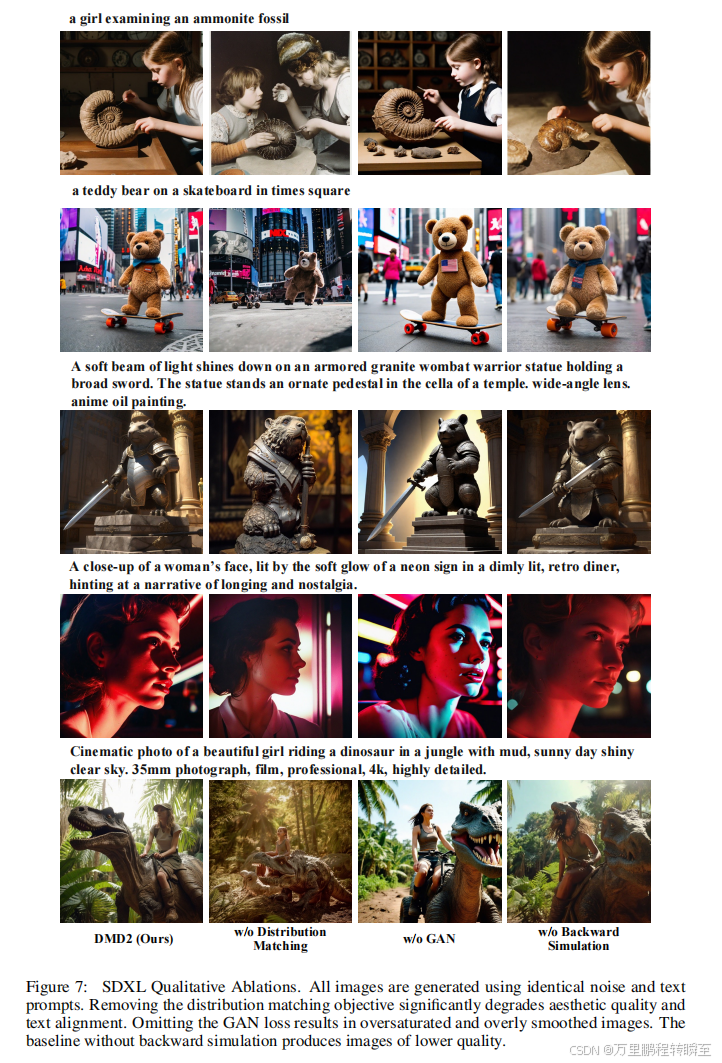
如图7所示,当移除GAN损失时,基线模型生成的图像出现过饱和和平滑过度现象(见图7第三列)。类似地,若剔除分布匹配目标函数(公式2),我们的方法将退化为纯GAN方法,这种纯GAN方法在训练稳定性方面存在明显缺陷[70,71]。此外,纯GAN方法还缺乏整合无分类器引导机制的天然途径[72],而该机制对于高质量文本到图像合成至关重要[1,2]。因此,虽然基于生成对抗网络(GAN)的方法通过精准匹配真实分布获得了最低的FID值,但在文本对齐和美学质量方面表现明显逊色(图7第二列)。同样地,如退化补丁FID分数所示,省略反向模拟会导致图像质量下降。
6 Limitations
虽然我们的蒸馏生成器在图像质量与文本对齐方面表现优异,但相较于教师模型,其图像多样性略有不足(详见附录B)。此外,我们的生成器仍需经过四个步骤才能达到最大SDXL模型的质量水平。这些局限性虽非本模型独有,却凸显了改进方向。与多数传统蒸馏方法类似,我们在训练中采用固定引导尺度,限制了用户操作的灵活性。引入可变引导尺度[13,31]或将成为未来研究的重要方向。值得注意的是,当前方法主要针对分布匹配进行优化,若能融入人类反馈或其他奖励函数,性能将有更显著提升[17,73]。最后需要指出的是,大规模生成模型的训练过程计算量极大,这使得大多数研究者难以开展相关工作。
)


)



![[Godot入门大全]目录](http://pic.xiahunao.cn/[Godot入门大全]目录)
)






异常)
:人工智能、机器学习与深度学习)


