目录
回顾:从 "人为中心" 的数仓,到大数据与云数仓的进化
AI Agent 成为数据的 "新用户"
Agentic Data Stack 如何打破低效与内耗
企业数智化的新范式
案例与趋势展望
所有软件都会被 Agent 改写一遍
经过半个世纪的数据仓库发展历程,企业数智化转型正迎来一次根本性的范式变革。从 Inmon 的"主题域"到 Kimball 的"雪花模型",从 Teradata 的 MPP 架构到 Snowflake 的云原生方案,这些技术演进始终围绕着一个核心:服务于人类决策者。报表、仪表盘、SQL 查询等工具,本质上都是为辅助人类决策而设计的。
随着 AI Agent 时代的开启,这一传统逻辑正在被重塑。Agent 已从被动工具进化为具备环境感知、业务理解和自主决策能力的"数字员工"。当数据的主要使用者从分析师转变为 Agent 时,企业数智化的用户边界被彻底打破。"人机决策支持系统"(DSS)模式正逐步向"Agent 驱动的智能交互"转变。
过去,企业常在数据建设中陷入形式主义:无休止的数据建模、报表开发和技术堆叠造成巨大内耗。而当 Agent 成为核心驱动力后,数智化转型的焦点将从"工具竞赛"回归到"价值创造"。这不仅是技术演进的必然结果,更是企业生存法则的根本转变。
回顾:从 "人为中心" 的数仓,到大数据与云数仓的进化
企业的数据体系的建立可以追溯到上世纪七十年代,那时,Bill Inmon 提出了 "面向主题、集成、时变、不可更新" 的数据仓库定义,确立了以人为中心的决策支持系统(DSS)雏形。几十年间,企业围绕 "如何让人做出更好决策" 这一核心目标,不断迭代着数据仓库的形态。
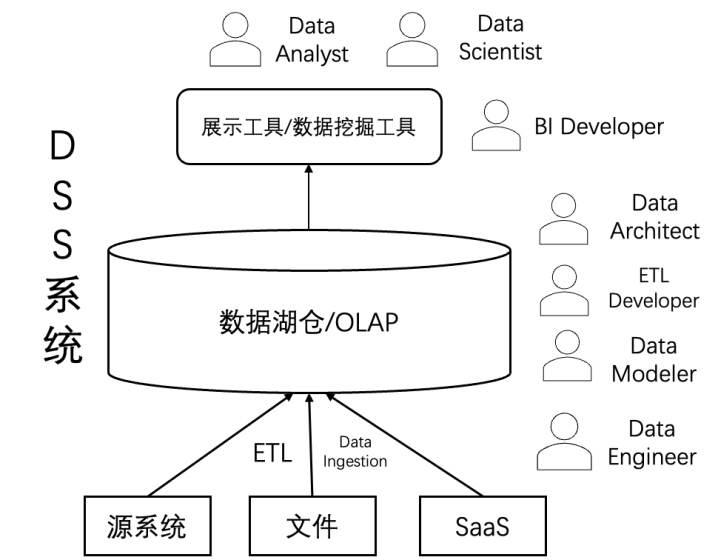
进入八十年代,Teradata 以 MPP 架构横空出世,在海量数据并行处理方面实现突破,成为数据仓库的代名词。九十年代,Kimball 的维度建模与雪花模型大行其道,BI 报表工具逐渐成熟,数据仓库真正走进企业管理层的日常。无论是复杂 SQL,还是 OLAP 报表,本质上都是为了让人更快理解数据、辅助决策。
时间快进到 2010 年后,大数据与云计算兴起。Hadoop、Spark、Hive 等技术,推动企业以更低成本处理 PB 级数据;Snowflake、BigQuery 等云数仓则借助分离存储与计算的架构,为 BI 工程师带来了前所未有的弹性与便捷。再加上 Fivetran、DBT 等新数据栈工具,数据开发与分析的效率显著提升。
但无论是本地 MPP,还是云数仓,或者新数据栈(New DataStack) ,它们都有一个共同点:数据的终点站依然是人。工程师要建模,分析师要写 SQL,管理层要看报表。所有技术演进,归根结底,都是在回答一个问题:如何帮助人更好地看清数据背后的规律。
正因如此,当下的格局看似繁荣,却也显露出隐忧:数据系统复杂度与成本越来越高,但它们的价值依旧依赖 "人肉解读"。这一点,正在成为未来新一轮技术变革的突破口。
AI Agent 成为数据的 "新用户"
如果说过去半个世纪的数据体系都在服务人类,那么正在发生的最大转变就是:数据的消费者不再只是人,而是 AI Agent。
所谓 Agent,并不是简单的 "聊天机器人",而是一类能够感知环境、理解语义、自动执行任务的智能体。它们不仅能回答问题,更能主动完成目标。例如,一个市场部门的 Campaign Agent,可以自动拉取广告投放数据,整合多渠道表现,实时调整预算;一个客服部门的 Support Agent,可以接入企业知识库,带着上下文记忆回答客户问题;在金融场景中,Risk Agent 甚至能自动解析订单、实时触发风控策略。
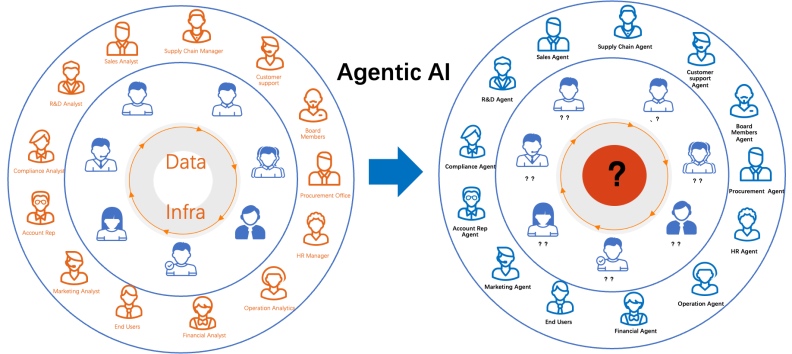
在这样的模式下,传统数据仓库和 BI 工具的 "人为中心" 逻辑正在发生根本性动摇。过去,人需要明确问题、查询数据、再生成结论;而 Agent 的工作模式则是相反的:它能够主动感知业务变化,推送可能的风险与机会,甚至在得到授权后直接执行动作。换句话说,从 "拉取式" 数据查询,到 "推送式" 智能响应,数据的使用范式发生了颠覆。
这种转变不仅仅体现在交互层面,更深刻地改变了系统设计的边界。过去的 DSS 架构是为分析师建模、为工程师开发而设计;而现在,当 "用户" 是 Agent 时,数据系统必须具备新的特征:数据与语义结合,而不是单纯的字段与数值;事件驱动与意图驱动,而不是僵化的批处理调度;跨系统的自动协作,而不是孤立的工具链。
更重要的是,Agent 的到来意味着企业数智化的角色分工被重新定义。分析师、报表开发人员的工作方式会发生变化,他们不再是 "数据的最终搬运工",而更可能成为 Agent 的设计者、监督者与价值验证者。管理层也将逐渐习惯从 Agent 获取洞察,而不是等待数据部门提供报表。
从 "人" 到 "Agent" 的跨越,看似技术演进,实则是 企业数智化认知边界的改变。谁能更好地适应这一变化,谁就能率先构建起面向未来的数据竞争力。
Agentic Data Stack 如何打破低效与内耗
在很多企业里,数智化建设往往伴随着沉重的 "隐形成本"。业务部门频繁提出新需求,数据团队则陷入无休止的建模、报表、ETL 调整之中。看似每一环都在运转,但真正交付到决策层的价值却有限。典型的现象包括:
- 建模过度:为了适配复杂的报表和分析需求,数据仓库被分割为原子层、汇总层、指标层,层层堆叠,维护成本高昂。
- 治理滞后:数据目录、血缘关系、质量校验,往往要在数据仓库落地之后再做补救,结果就是治理流程与业务需求总是脱节。
- 人力内耗:无数分析师在写重复的 SQL、改动相似的报表,却很难沉淀出通用的方法论。
- 变更脆弱:一旦上游表结构发生变化,整个数据链条就像多米诺骨牌一样倒下,补救成本巨大。
这正是过去数智化转型中最容易陷入的 "内卷" 陷阱:拼命堆叠系统和人力,却难以形成规模化效能。 Agentic Data Stack 的提出,正是针对这种困境。它带来几个关键性的改变:
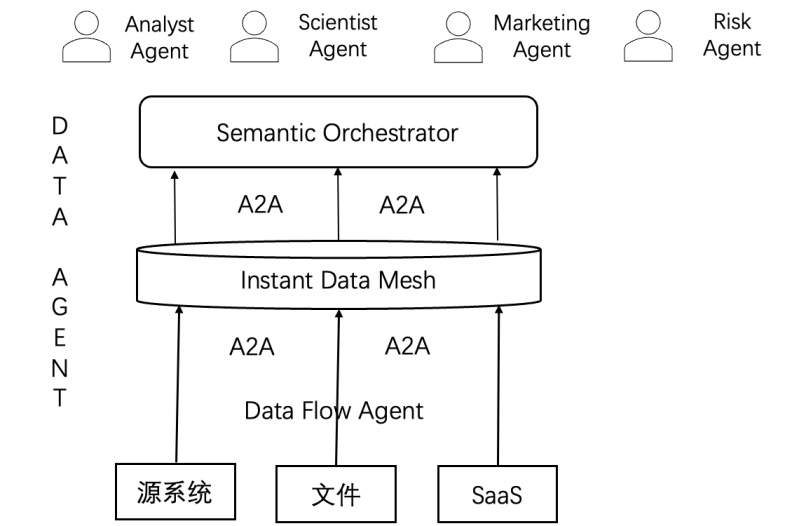
- Data Flow Agent:不再依赖人工调度,而是通过事件触发与意图驱动,自动发现和编排数据流。数据结构的变化不再需要 "人肉修复",而是由 Agent 感知并自适应调整。
- CDU(Contextual Data Unit):数据与语义绑定,每条数据都自带上下文解释,减少了额外的数据治理开销,也降低了 Agent 使用数据时的歧义。
- Semantic Orchestrator:取代传统 BI 报表作为中枢,它不是生成图表的工具,而是 Agent 与数据之间的 "翻译官",通过自然语言和语义推理协调不同 Agent 的需求。
这种新范式的核心不在于 "更强的算力" 或 "更复杂的模型",而在于降低人力介入,提升系统自适应能力。企业不必再耗费巨资去养一支只会修复链路的团队,而是将注意力放在 Agent 的应用价值和业务创新上。
因此,Agentic Data Stack 不是简单的技术升级,而是一种从根本上减少内耗、提升 ROI 的重构。它让企业把精力从 "维护系统" 转向 "创造价值",也让数智化建设真正走出 "重复劳动" 的泥潭。
企业数智化的新范式
当数据的最终用户从人类转向 Agent,企业数智化转型所依赖的逻辑也必须随之改变。这不仅是一场技术革新,更是一种系统性的范式转变。

在组织层面:数智化已经不再是 IT 部门的 "专属项目"。过去,IT 部门负责搭建数仓、开发报表,业务部门被动使用成果,双方常常因需求与交付周期产生摩擦。而在 Agent 驱动的架构下,业务部门能够直接依赖自身业务 AI Agent 获取洞察甚至执行操作。例如,财务人员无需等待报表出炉,就能通过 Finance Agent 进行模拟和预测;市场人员借助 Campaign Agent 自动完成投放优化。未来,企业内部的治理格局也会发生调整,"数据官(CDO)" 与 "AI 官(CAIO)" 可能并行出现,前者确保数据资产质量,后者负责智能体的落地与协作。
在技术层面:企业数智化不再是 "拼平台" 的游戏。过去几年,许多企业陷入了 "研发 / 外包越多越先进" 的误区,结果是系统冗杂、维护成本高昂。Agentic Data Stack 的兴起,意味着技术堆叠将被简化,数据流转更敏捷,治理成本更低。竞争焦点也会从 "多少工具" 转向 "如何让 Agent 更高效地理解和使用数据"。这让数智化从 "人力驱动的劳动密集型工程",转向 "智能驱动的资本高效型工程"。
在商业层面:数智化的价值逻辑也会发生质变。过去,企业数智化的主旋律是 "降本增效",更多是为了提高效率、降低人力成本。而在 Agent 驱动的格局下,企业能够利用智能体快速测试新业务模式,主动捕捉市场机会,从而创造新的收入来源。换句话说,数智化从 "成本中心" 转向了 "创新引擎"。这对于中小企业尤为重要:不需要像大厂一样搭建庞大数据团队,也能通过 Agent 低门槛启动转型,获得接近甚至超越行业巨头的敏捷性。
这种新范式的出现,标志着企业数智化已经走出过去的 "堆叠和内耗",迈向一个以智能体协同、敏捷响应、价值导向为核心的阶段。谁能率先理解并实践这一逻辑,谁就能在未来的竞争中占据主动。
案例与趋势展望
当前,AI Agent 在企业数智化中的应用仍处于探索阶段,离全面替代传统数仓和 BI 系统还有相当距离。但这并不妨碍一些具体场景率先落地。
例如,在数据集成与调度领域,WhaleStudio Pro 基于 SeaTunnel+DolphinScheduler 已经可以实现自动生成 ETL 流程。过去,解决异构数据同步问题,工程师需要手工编写抽取、转换、加载脚本,再由调度系统编排任务;而现在,业务人员一句话就可以让 Agent 系统能自动生成数据同步任务和相关调度任务,大幅提高了研发效率。这类 "半自动化的数据流 Agent" 已经初步展现了生产力价值。
类似的探索也出现在金融风控、智能客服等场景,但大多还停留在试点阶段,距离大规模生产环境仍需验证。未来 3-5 年,随着 Agent 协议与工具链逐步完善,更多的企业数据系统会融入 Agent 元素,从而逐步迈向 Agentic Data Stack 的形态。
因此,可以说:Agent 驱动的数据架构尚在路上,但它所带来的价值导向和设计理念,已经开始改变企业数智化的落地方式。
所有软件都会被 Agent 改写一遍
回顾数据仓库半个世纪的发展,它始终是围绕 "人" 的决策需求而设计的。然而,随着 AI Agent 的崛起,这一逻辑正在被彻底改写。数据系统的 "用户" 正在从分析师、报表开发人员,转向能够感知、理解、执行的智能体。
这意味着,企业数智化的边界正在被重新定义:系统不再是被动地支撑人,而是主动地驱动业务。与此同时,企业也必须走出过去那种层层叠叠、重复建设的惯性,把精力集中在如何让 Agent 更快、更好地产生价值。
真正的挑战不在于数据仓库是否会消失,而在于企业是否能顺应范式的转变。未来已来,当 Agent 成为数据的主要消费者,数智化的核心竞争力将不再是堆叠多少工具,而是谁能最先掌握语义与智能的结合点。
你所在的企业,准备好迎接 Agent 这个新用户了吗?















 在Window 系统的默认安装配置)


,js(基本类型、运算符典例))
)