Google DeepMind 近期发布了关于递归混合(Mixture of Recursion)架构的研究论文,这一新型 Transformers 架构变体在学术界和工业界引起了广泛关注。该架构通过创新的设计理念,能够在保持模型性能的前提下显著降低推理延迟和模型规模。

本文将深入分析递归混合(MoR)与专家混合(MoE)两种架构在大语言模型中的技术特性差异,探讨各自的适用场景和实现机制,并从架构设计、参数效率、推理性能等多个维度进行全面对比。
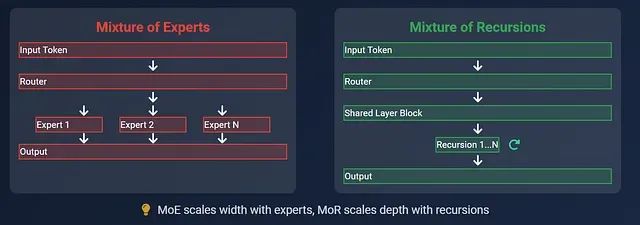
专家混合(Mixture of Experts)架构原理
专家混合架构将神经网络模型分解为共享基础层和多个专门化的专家模块,其中每个专家模块都是经过特定训练的小型前馈神经网络,负责处理特定类型的输入模式。
在推理过程中,当输入令牌通过模型时,路由机制会从众多专家中选择性激活少数几个(通常为2-4个,总专家数可能达64个或更多)来处理该令牌。这种设计使得不同令牌在模型中遵循不同的计算路径,从而实现了在不增加实际计算量的情况下扩大模型容量的目标。这一机制类似于在复杂任务中仅调用相关专业人员而非整个团队的协作模式。
递归混合(Mixture of Recursion)架构原理
递归混合架构采用了截然不同的设计思路,它使用一个相对较小的共享计算块(通常由几个 Transformer 层组成),通过多次迭代处理来实现深度计算。每个输入令牌根据其复杂程度自主决定所需的处理轮数。
在这种架构中,语义简单的令牌会在较少的迭代后提前退出处理流程,而复杂令牌则需要经过更多轮次的递归处理。与 MoE 通过增加模型宽度来提升容量不同,MoR 通过动态调整计算深度来优化性能。此外,该架构通过智能缓存机制仅保留迭代过程中的必要信息,显著降低了内存占用。整个系统中不存在多个专家模块,而是通过单一计算块的智能重用来实现高效计算。
基于以上架构原理,我们将从多个技术维度深入分析两种架构的具体差异:
架构设计对比分析
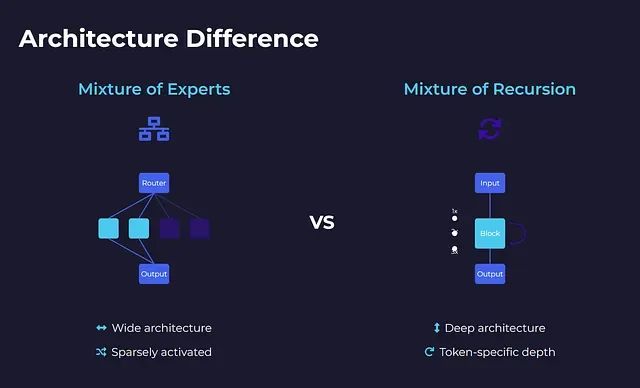
专家混合架构采用分布式专家系统的设计理念,整个模型可以视为一个大型智能交换网络。模型内部包含大量小型多层感知机专家模块,但在处理任何单一令牌时,仅有少数专家(通常2-4个)处于激活状态。路由器负责决策激活哪些专家,而其余专家保持空闲状态。每个令牌在网络中沿着独特的路径传播,激活不同的专家组合。这种设计实现了大规模稀疏激活模型——虽然总体规模庞大,但实际计算量保持高效。
递归混合架构则采用了相反的设计策略,整个模型仅包含一个小型 Transformer 计算块,所有令牌共享同一计算资源。令牌不是在不同专家间分流,而是在同一计算块中进行多轮迭代处理。迭代次数完全由令牌特性决定:简单令牌快速退出,复杂令牌进行深度处理。因此,模型呈现窄而深的特征,具备令牌特定的动态深度调整能力。
从系统架构角度来看,MoE 类似于配备多个专科医生的大型综合医院,患者根据病情被路由到相应的专科部门;而 MoR 则像一位经验丰富的全科医生,根据患者病情复杂程度进行相应次数的深入诊查——简单感冒一次诊断即可,复杂心脏疾病则需要多轮深度检查。
模型规模与参数效率分析
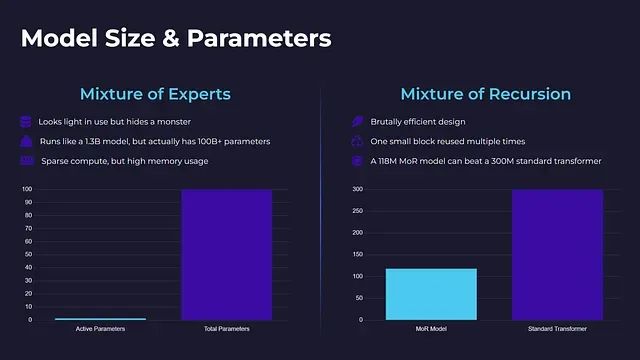
专家混合架构在运行时表现出轻量化特征,但其背后隐藏着巨大的参数规模。一个在推理时表现如同1.3B参数模型的MoE系统,实际上可能在所有专家模块中总计包含超过100B个参数。虽然单次推理仅激活其中一小部分,但所有专家模块都需要完整的存储、加载和训练支持。
这种设计带来了计算稀疏性与内存密集性并存的特点。在训练过程中,所有专家模块都需要接收梯度更新,包括那些很少被激活的专家。如何在众多专家间实现负载均衡成为了比预期更加复杂的工程挑战。
相比之下,递归混合架构展现出极高的参数效率。通过在多个处理步骤中重复使用单一计算块,该架构避免了参数数量的爆炸性增长,也无需管理复杂的专家模块集合。实验数据表明,一个118M参数的MoR模型在少样本学习任务中的性能可以超越300M参数的标准Transformer模型,这种优势并非来自更大的模型规模,而是源于更智能的计算资源利用策略。
当内存容量、存储空间或部署成本成为关键考虑因素时,MoR架构相比MoE具有显著优势。
推理延迟性能评估
在实际部署环境中,推理延迟性能成为衡量架构实用性的关键指标。
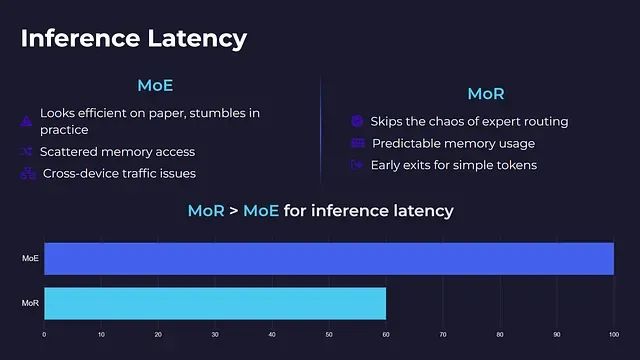
专家混合架构虽然在理论分析中表现出良好的计算效率,但在实际实现中往往面临性能瓶颈。每个令牌仅激活少数专家的策略虽然减少了计算量,但同时引入了内存访问模式分散、计算负载不均衡以及跨设备通信开销等问题。
对于基础设施水平未达到Google或Microsoft等科技巨头标准的部署环境,延迟、网络拥塞和系统复杂性往往会抵消稀疏计算带来的性能收益。MoE架构并非即插即用的解决方案,需要针对特定硬件环境进行深度优化。
递归混合架构有效避免了上述复杂性问题。由于不存在专家路由机制和跨设备通信需求,每个令牌在同一小型计算块中进行迭代处理,并自主决定退出时机。这种设计确保了内存访问的可预测性、支持早期退出机制,并在各种硬件环境下保持稳定的运行时性能,即使在中等性能的GPU上也能良好运行。部署MoR架构无需超算集群支持。
从推理延迟角度分析,MoR架构明显优于MoE架构。
训练稳定性与收敛特性
专家混合架构在训练过程中容易出现专家崩溃现象,这是该架构面临的主要技术挑战之一。在训练进程中,模型可能过度依赖少数几个专家模块,而忽视其他专家的能力发展。部分专家模块可能无法接收到足够的梯度信号,导致学习停滞,最终拖累整体模型性能。
解决专家崩溃问题需要引入额外的损失函数项、熵正则化机制以及精心设计的负载均衡策略。虽然这些技术手段可以缓解问题,但增加了训练流程的复杂性和脆弱性。
递归混合架构从根本上避免了专家不均衡问题。由于不存在多个专家模块,所有令牌共享相同的权重参数,通过干净的重用机制实现高效训练,显著提升了训练过程的稳定性。
然而,MoR架构也有其特定的调优挑战:如何确定每个令牌的最优迭代次数。迭代次数过少会导致处理深度不足,过多则造成计算资源浪费。MoR通过专家选择路由和令牌选择路由两种策略来平衡这一问题,且无需额外的损失函数技巧。
路由机制技术实现
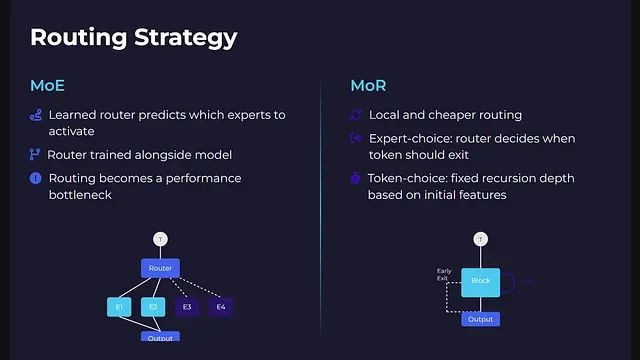
专家混合架构采用基于学习的路由机制,路由器通过分析令牌嵌入向量来预测应该激活哪些专家模块。这种路由决策与整个模型一同进行端到端训练。系统需要确保没有专家模块被过度使用,同时防止路由器陷入固定的激活模式。
在大规模MoE模型中,特别是涉及跨设备路由时,路由机制往往成为系统性能的瓶颈。
递归混合架构的路由机制更加本地化且计算开销更低。该架构支持两种路由模式:专家选择路由模式下,路由在每个递归步骤中决定令牌是否继续处理或退出流程;令牌选择路由模式下,每个令牌在处理开始时根据其初始特征被分配固定的递归深度。
MoR中的路由重点不在于选择处理单元,而在于确定在同一计算块中的停留时间。由于无需令牌间或设备间的通信协调,整个计算图保持了更好的简洁性和优化空间。
硬件适配与部署考量
专家混合架构主要面向大规模计算环境设计。要充分发挥其效率优势,需要GPU间高速互连、跨加速器智能分片以及硬件级稀疏张量运算支持。该架构并非即插即用解决方案,大多数开源深度学习框架无法提供开箱即用的大规模MoE支持。对于拥有顶级基础设施的科技公司,MoE架构展现出良好的性能表现。
然而,对于在个人工作站或边缘设备上进行推理的场景,MoE架构的部署难度极高。
递归混合架构在部署方面表现出更好的灵活性。该架构基于标准Transformer结构,仅在核心计算块外增加迭代控制逻辑。开发者可以使用标准的PyTorch或JAX原语进行实现。由于采用共享权重和简单的令牌级控制流,MoR架构能够以最小的修改集成到现有的模型服务管道中。
应用场景与技术选型
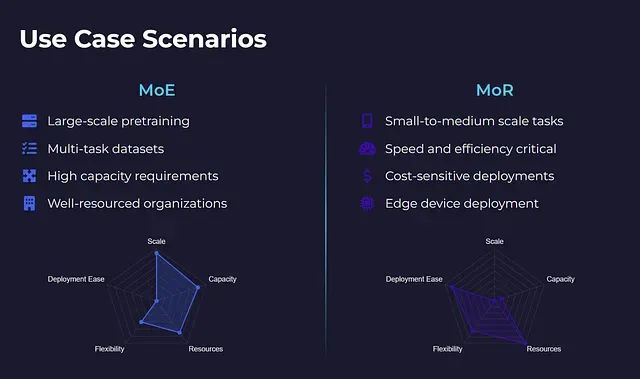
专家混合架构适用于从零开始训练大规模模型、处理多任务数据集,以及在不进行全密集计算的前提下追求高模型容量的场景。该架构在大规模预训练任务中表现出色,但除非具备充足的计算和工程资源,否则将在系统复杂性、内存需求和延迟优化方面面临显著挑战。
递归混合架构更适合对推理速度、计算效率和部署成本敏感的中小规模应用场景。该架构在模型微调、少样本学习以及边缘计算或消费级硬件部署方面具有明显优势。此外,MoR架构具备良好的缩放特性,这是MoE架构的薄弱环节。
总结
从技术发展趋势来看,专家混合架构通过部署大量专家模块来解决复杂问题,但在每次推理中仅激活其中一小部分;而递归混合架构则通过单一计算单元的反复迭代,在每次处理中都变得更加智能。
对于致力于构建大规模商业化语言模型平台的组织,专家混合架构的复杂性投入可能是值得的。而对于需要在实际设备上快速部署高效模型的应用场景,递归混合架构能够以更低的技术债务实现目标。
两种架构代表了大语言模型发展的不同技术路径,各自在特定场景下展现出独特的技术优势。选择哪种架构应基于具体的应用需求、资源约束和技术能力进行综合考量。
https://avoid.overfit.cn/post/c95f03d8ad3049ada1c41e71094e2fd5
作者:Mehul Gupta

)














如何进行MySQL的全局变量设置?)


