【2025版】44、第十四节 机器终身学习 一 为什么今日的人工智能A_哔哩哔哩_bilibili
【2025版】42、第十三节 神经网络压缩 一 类神经网络剪枝PruA_哔哩哔哩_bilibili
【2025版】30、第九节 机器学习的可解释性 上 – 为什么神经网络可以正_哔哩哔哩_bilibili
目录
1. 终生学习
1.1 灾难性遗忘
1.2 终身学习评估方法
1.3 解决灾难性遗忘
2. 网络压缩
2.1 网络剪枝(减少连边 / 神经元)
2.2 知识蒸馏(学习老师的分布)
2.3 参数量化 (用更少的空间存储参数)
2.4 网络架构设计(改变结构优化参数)
2.5 动态计算(根据计算资源调整工作量)
3. 可解释性人工智能
3.1 局部可解释(为什么判断是一只猫?中间层得到了什么?)
3.2 全局可解释(什么样的图片叫做猫)
1. 终生学习
1. 模型学会解决一个task后 继续学习别的task(一个会多个task的模型)
2. 模型上线后 收到来自使用者的反馈 并且得到新的训练数据更新模型
1.1 灾难性遗忘
比如有task1 和 task2,如果最开始直接把task1 和 task2的目标和训练数据一起给模型 模型可以学得很好。但是如果先学task1,再学task2,task1的正确率会低很多(遗忘)
- 如果要重新学一遍task1 每次有新任务了就要把之前的重新学一遍 效率太低。
- 如果每个任务都分别一个模型:一是存储量会大很多,二是任务之间可能有共通之处,让一个模型学多个task会更有帮助。
1.2 终身学习评估方法
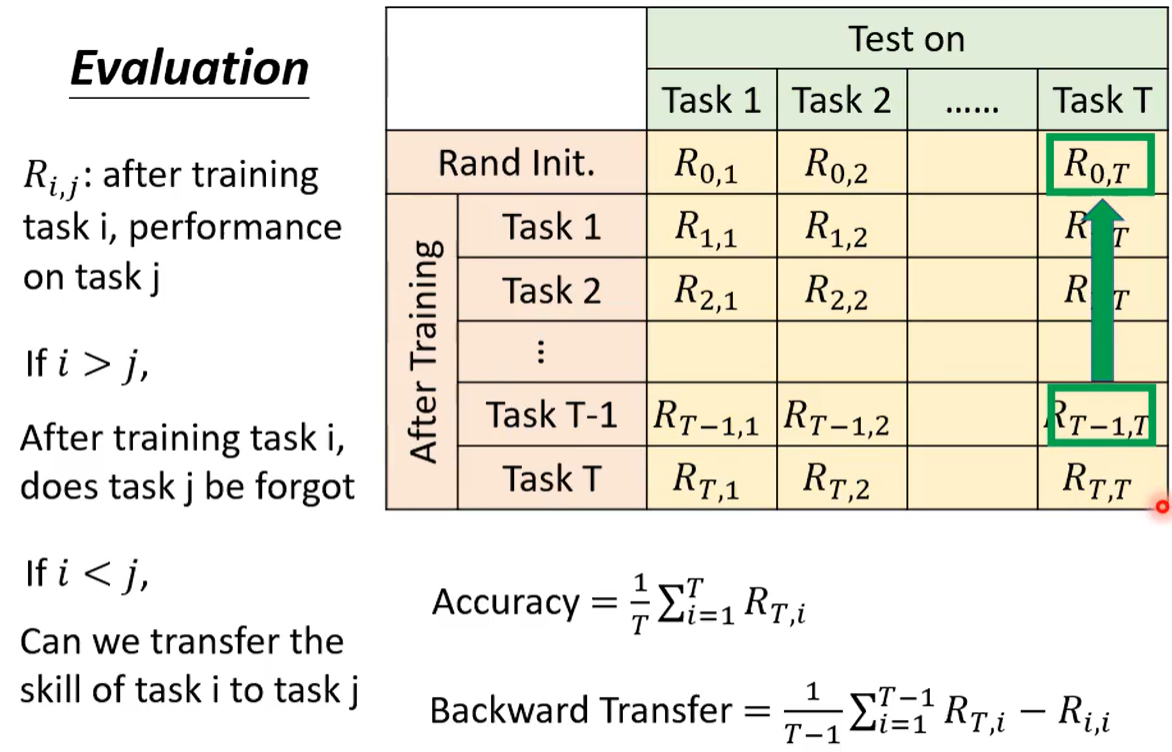
一个矩阵 Ri,j 代表学习 i 个任务后 在任务 j 的表现
j 在 i 前 可以看出 j 有没有被遗忘; j 在 i 后 可以看出 任务 i 能否迁移到任务 j
准确率则用 T 个任务都学完后的数据; 后向迁移为 所有模型(最终 - 刚学的时候)的均值
1.3 解决灾难性遗忘
遗忘的主要原因: 最适合 task2 的参数没那么使用与 task1。参数需要综合前后。
选择性的突触可塑性:尽量学对新任务比较重要的参数,对过去任务很重要的参数尽量不改变。
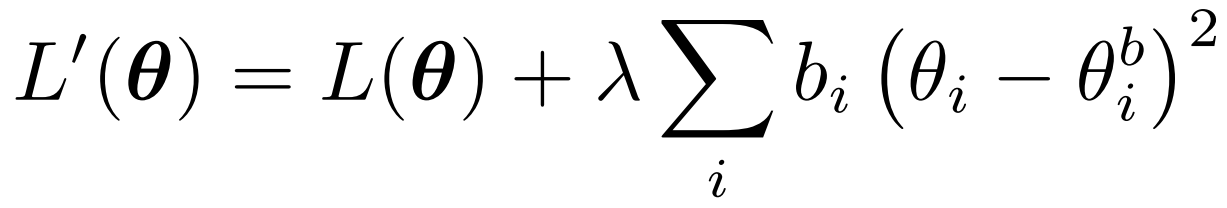
现在的参数为 θ 只考虑当前最新的参数的损失为 L(θ)
bi 为之前任务的重要性系数 θ_b 为之前的参数。 需要设定 λ和b 的系数。
GEM 梯度回合记忆:存下历史任务对应的梯度方向,用(当前任务梯度方向 + 历史梯度方向) 作为更新方向。
2. 网络压缩
不降低多少性能的情况下 减少网络参数。
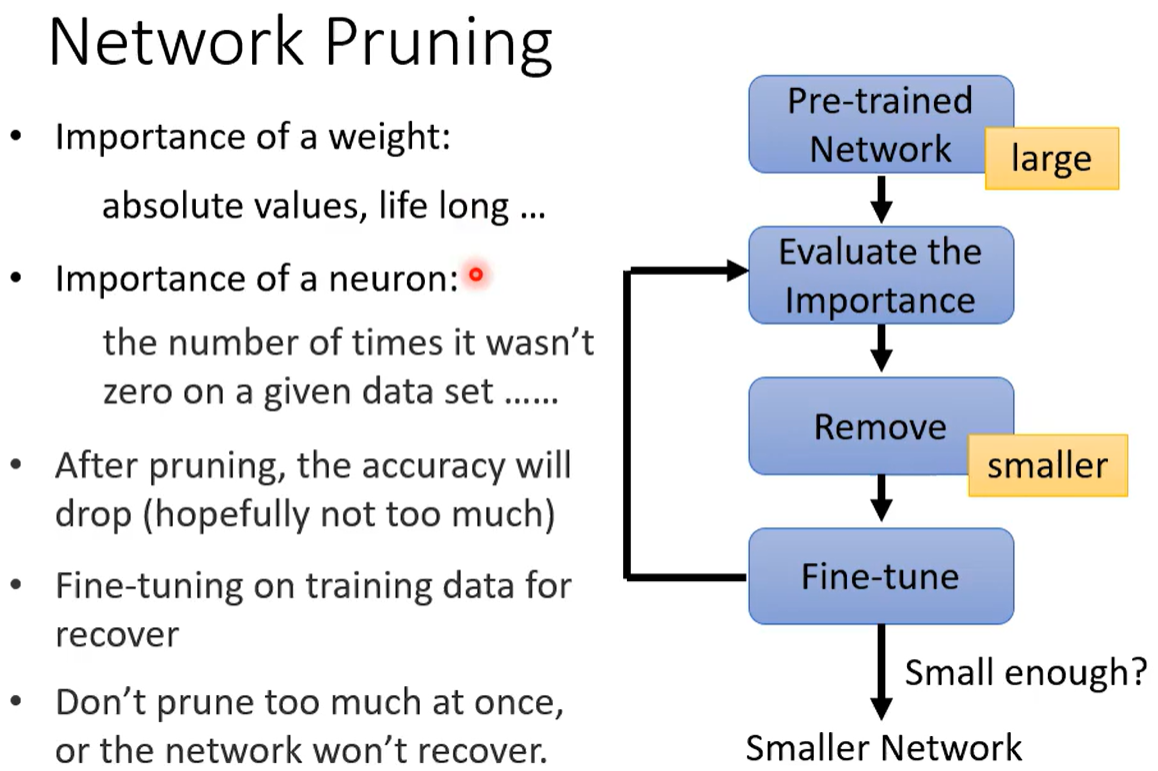
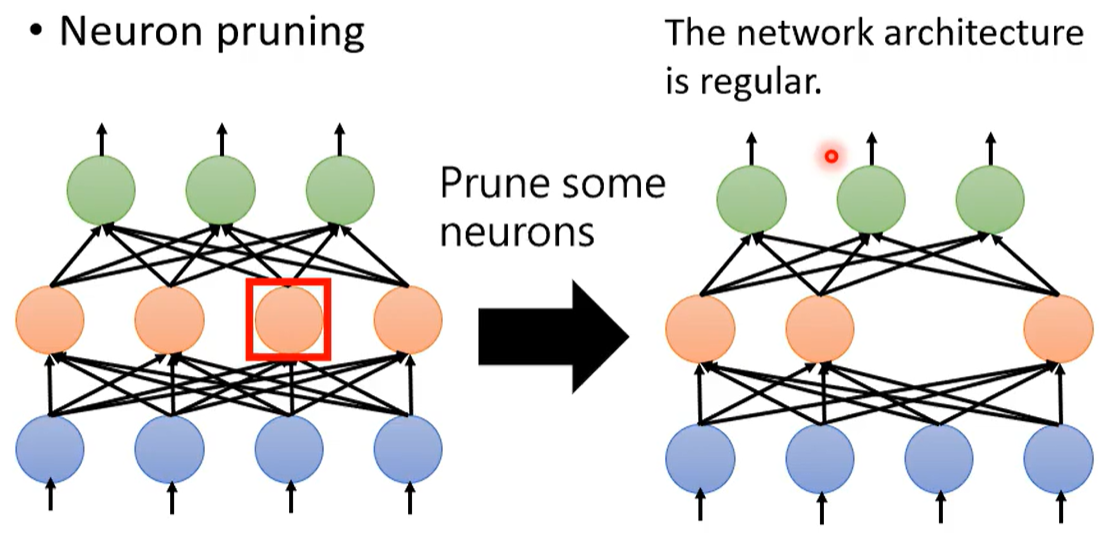
2.1 网络剪枝(减少连边 / 神经元)
- 评估网络中 神经元/权重的 重要性
- 剪枝掉10%(一小部分)不太重要的参数 (一下子剪枝太多会对正确率损坏太大)
- 微调保障准确率
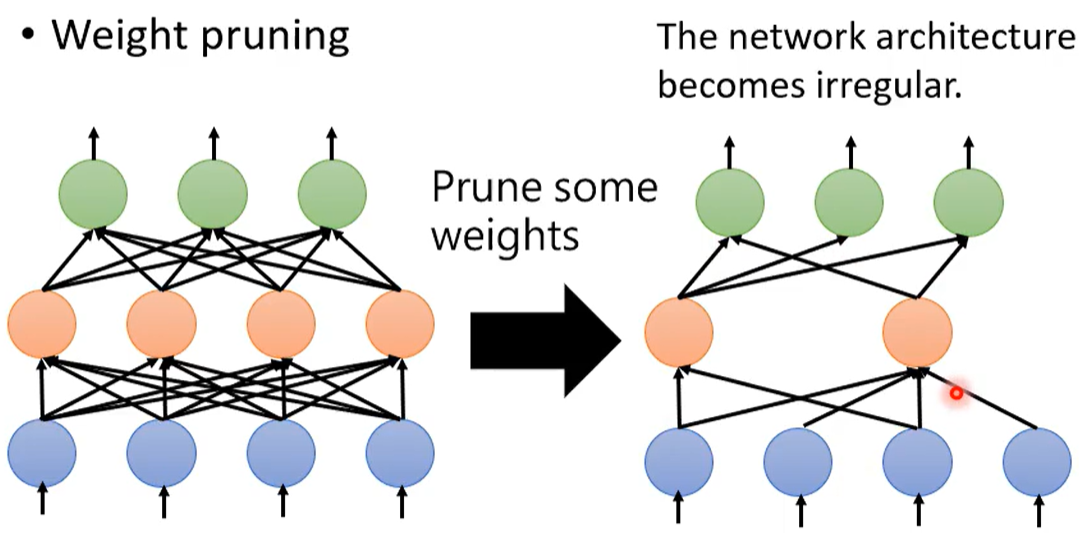
但是剪枝掉一些权重 会使得网络结构不规则。
在Pytorch中定义网络:每层几个神经元 多少 多长输入输出;GPU加速 把网络看做矩阵乘法。
网络不规则 会使得难以构建&训练网络。
删去权重 只是把权重调为零。但如果把剪掉的权重设为0 会使得网络没有真正减小。
相比而言 删去神经元会更方便一些。
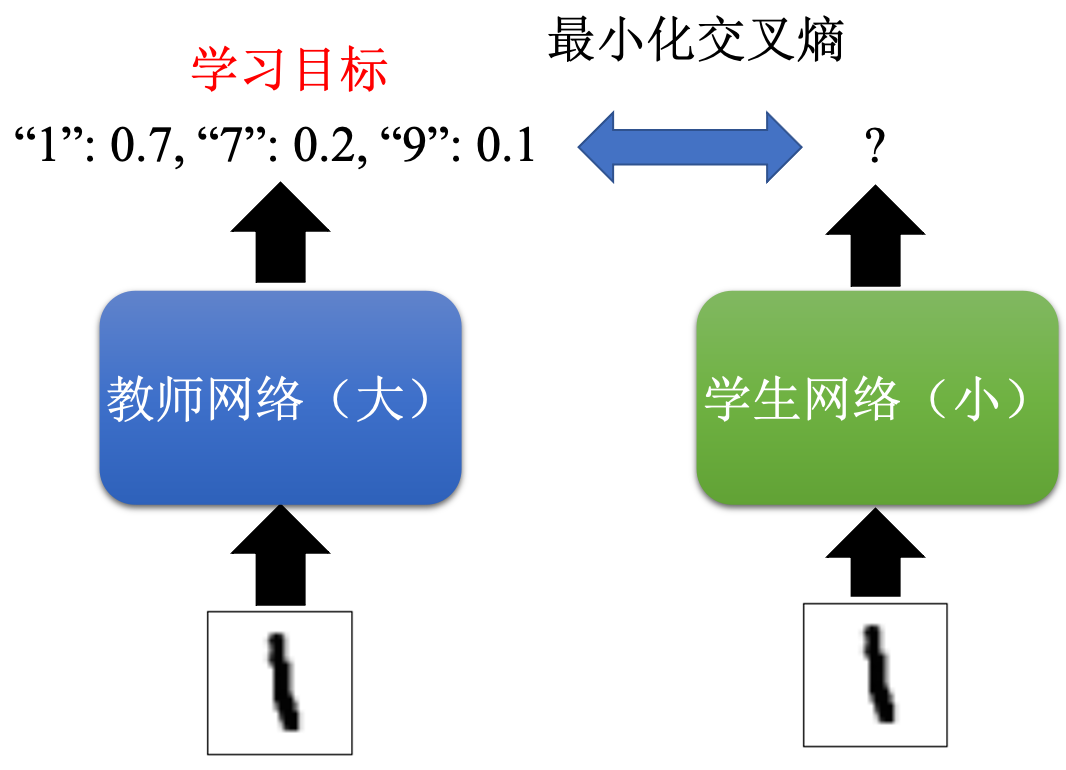
2.2 知识蒸馏(学习老师的分布)
比如手写数字 监督学习学这张图片是“1” 太难了(分布要是 “1”为1 其余都为0)
我先训练一个大网络作为老师网络(得到图片“1” 输出的分布) 学生小网络去学那个输出分布
大网络 可以通过集成学习 一些高质量分类器平均值
还可以帮助小网络学到 “1”比较像“7” 的知识
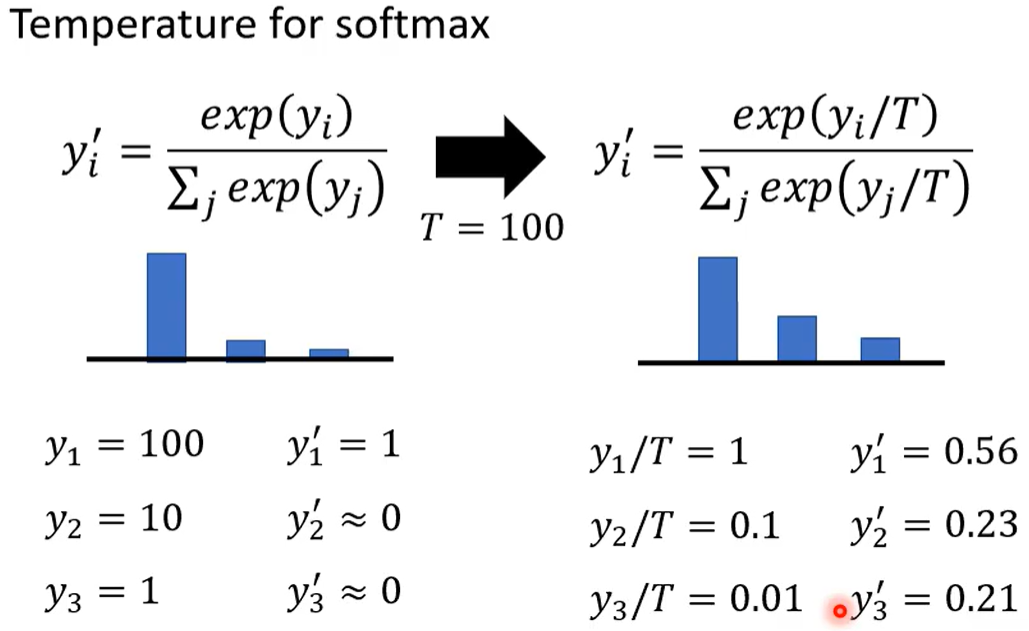
小技巧:在softmax除以温度
T=1时不变 大一些的T可以拉近e^y 之间的距离
不改变老师分类器的结果 但可以使训练更平滑
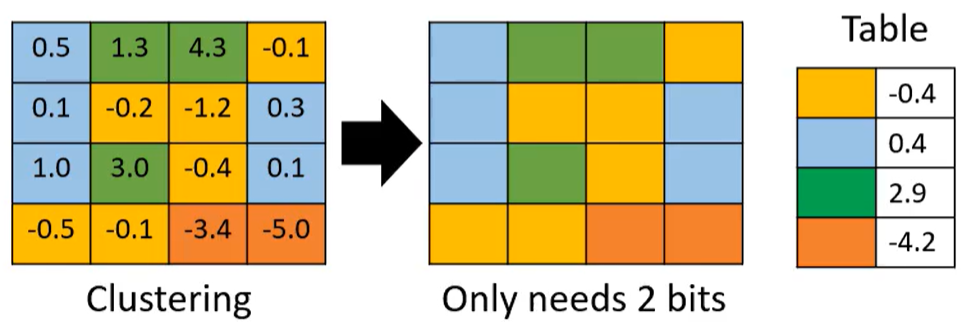
2.3 参数量化 (用更少的空间存储参数)
法1:权重聚类 聚类完把一个类别中的值设为他们的平均值(如下表中的颜色)
只需记录每个参数属于哪个类别群;每个群平均数是多少
本来存一个参数要8/16位 现在只需2位
还可以用 huffman编码 二值网络(参数只有±1) 等技巧压缩
2.4 网络架构设计(改变结构优化参数)
深度可分离卷积
一般CNN 参数量为 K*K*I*O
深度卷积 每个滤波器对应一个通道,输入跟输出的通道数量相同。 K*K*I
点卷积 滤波器的核都是1*1 上只关注通道内,下只关注通道间。 1*1*I*O
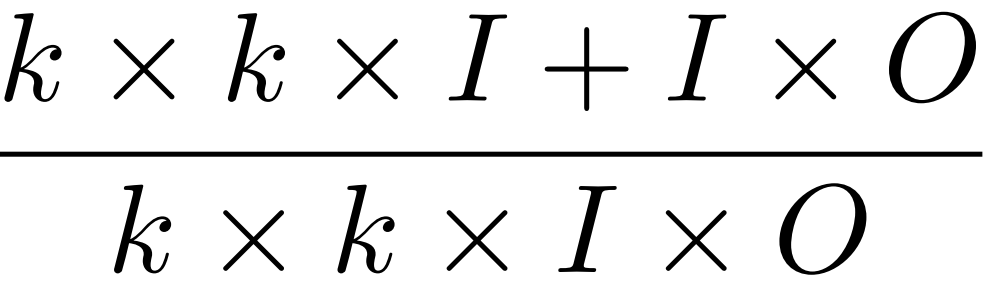
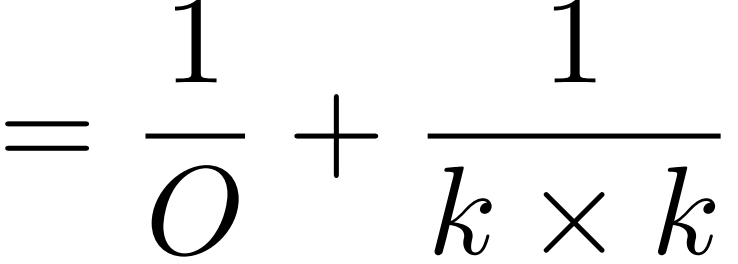
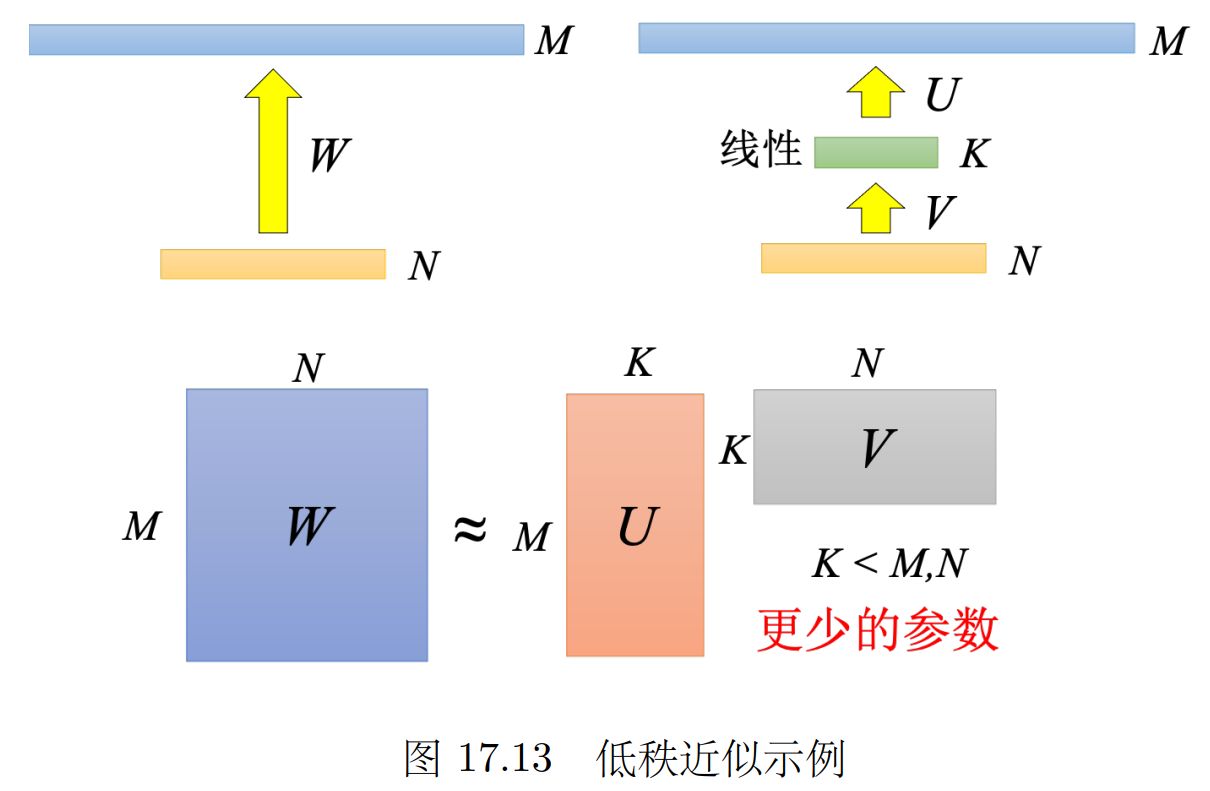
低秩近似 用矩阵乘法 m*n = m*k * k*n
2.5 动态计算(根据计算资源调整工作量)
计算资源多/问题难度大 就充分利用计算资源; 根据现有计算资源 自由调整对计算量的需求。
(就像手机的省电模式一样)
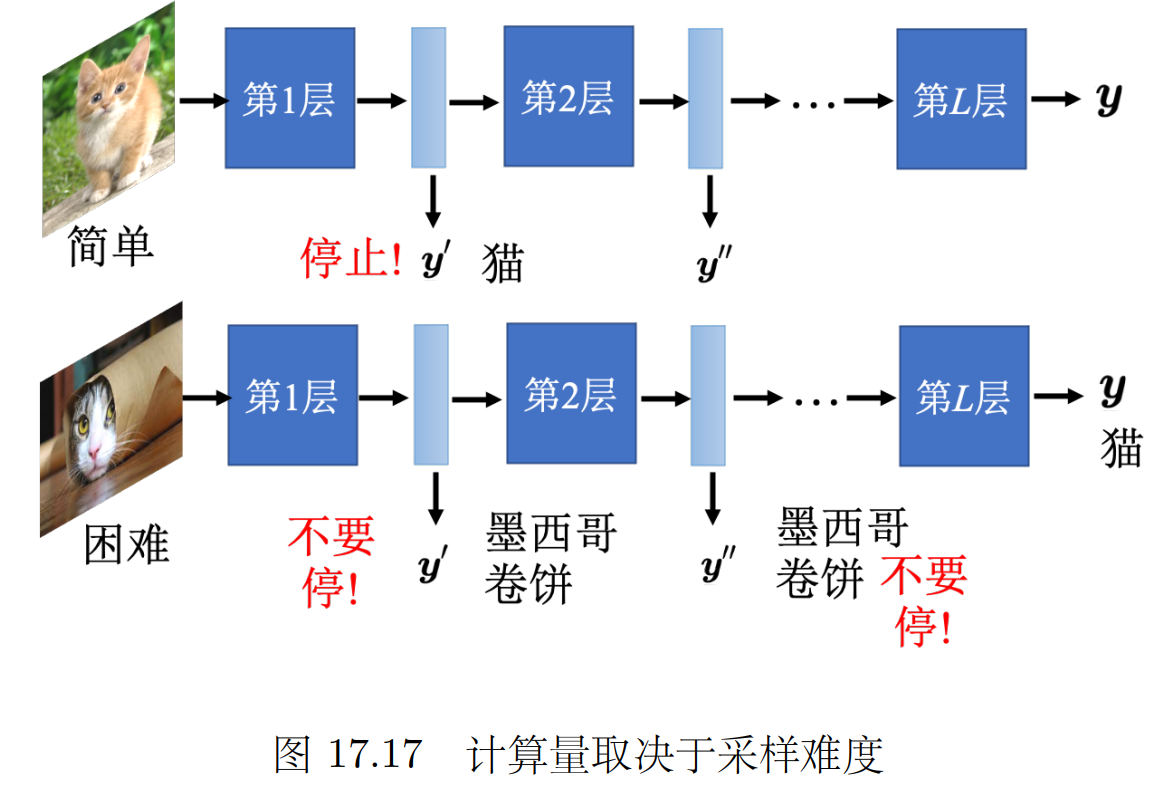
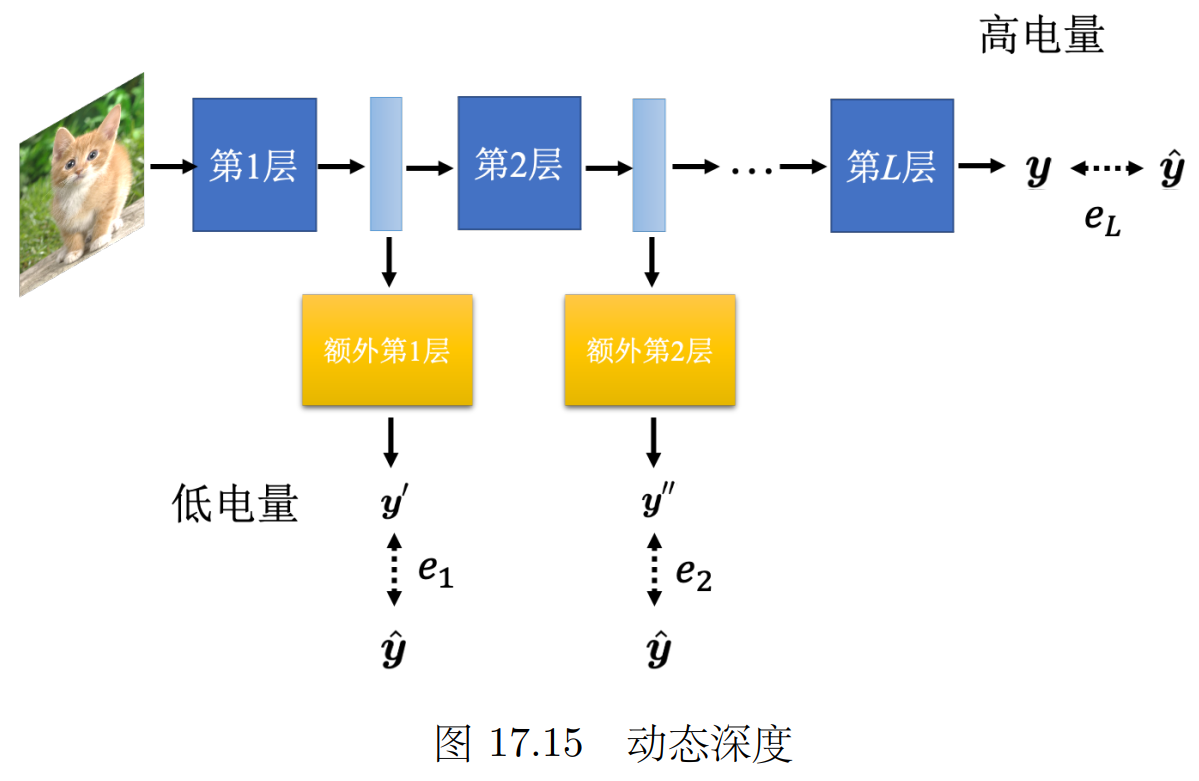
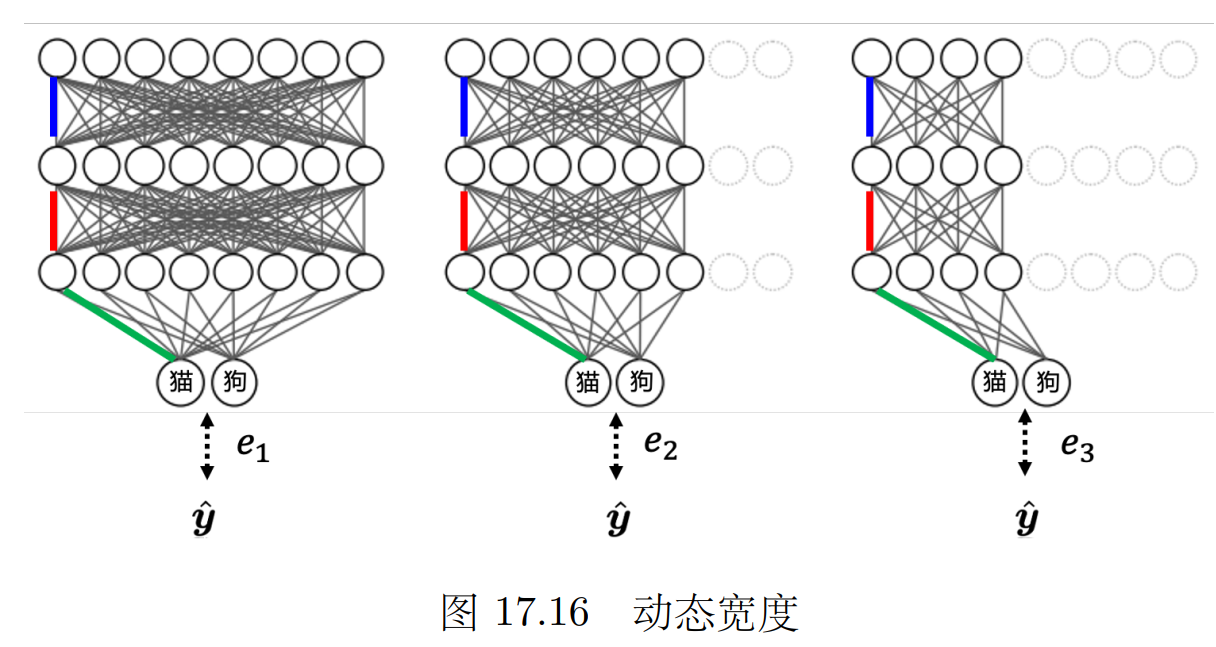
可以自行调整 神经网络的深度(几层)宽度(一层几个神经元)
我们平时是 只把神经网络的最后一层的输出当作最后的结果。
可以把每一层神经网络的输出都可以当成最后的分类结果,根据计算资源计算到哪一层。
让标准答案跟每一个额外层的输出越接近越好,把所有的输出跟标准答案的交叉熵都加起来得到 L
![]()
3. 可解释性人工智能
为什么需要可解释性:
1.机器学习模型往往是一个黑盒子,无法解释这个黑盒子中是如何通过输入得到输出的。但模型的安全性在行业落地时十分重要,医疗诊断不给出诊断理由,自动驾驶不给出操作理由,很难相信。
2.知道模型错在什么样的地方,为什么犯错,可以有更好的、更有效率的方法来提升模型
线性模型 可解释性强 但功能比较有限;模型越强越难解释(二者需要平衡)
决策树 每个节点向左/向右 直到叶子结点。具有一些可解释性,但特征变多,变复杂到随机森林之类又变得比较难解释。
我们期望的可解释是什么样的?就像人脑也是一个黑盒,但我们可以相信另一个人的判断。
心理学实验:想要插队,相比直接说,和前面的人说“我赶时间”别人接受的程度会提高很多。
相似的,机器学习好的解释就是人能接受的解释。
3.1 局部可解释(为什么判断是一只猫?中间层得到了什么?)

哪些部分(token 片段 像素)判断出来是一只猫?如何知道一个部分的重要性?
如果我们改造或删除某一个部分以后,网络的输出有了巨大的变化 就说明很重要。(梯度)
梯度大的地方标白 构成的图:显著图。

下方是原始显著图 有羚羊轮廓但如何使得显著图的效果更好呢?(降低噪声点影响)

在图片上面加上各种不同的噪音,接着在每一张图片上计算显著图,再平均起来
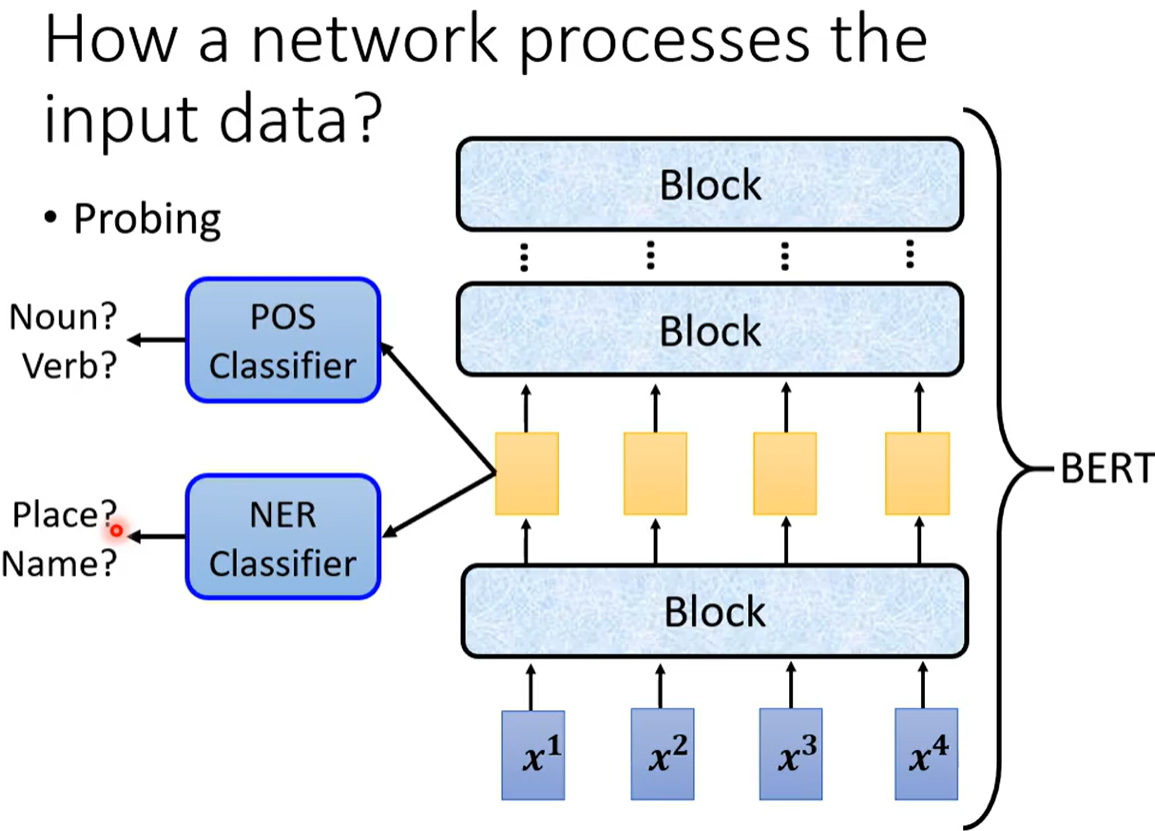
网络是如何去处理这个输入的?
可以将隐藏层(中间层)网络的输出可视化 或者看其中有没有和任务相关信息。
probing探针 插入network 把中间层的内容拎出来 看是否可以复现原任务。
例1. BERT 的某一层到底学到了什么 POS词性分类问题 NER命名实体分类问题
把BERT 某一层的embedding 丢给一个POS分类器(分类器本身强度 不能太好也不能太差),
如果分类器分类的正确率高 代表包含词性信息 否则不包含词性信息。
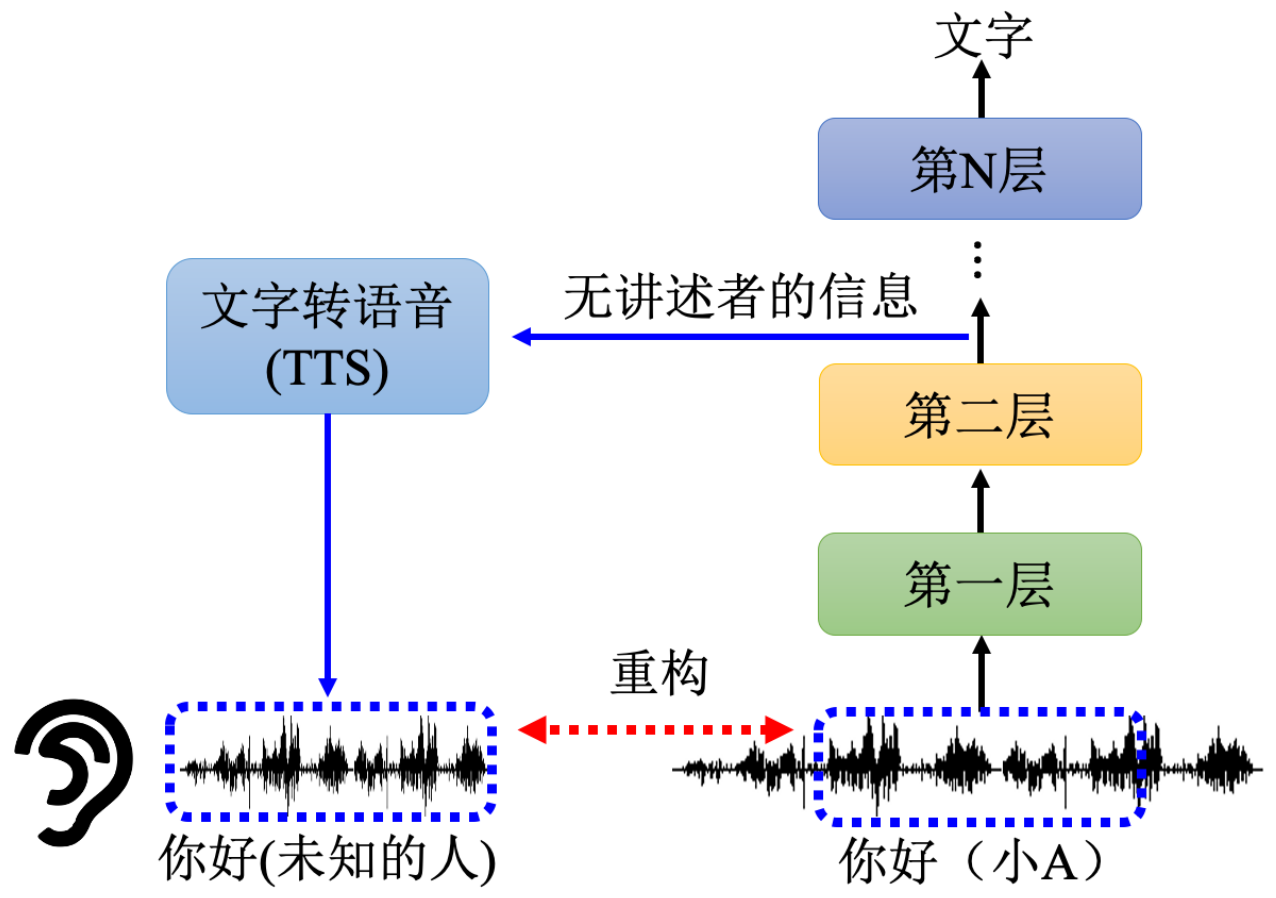
例2. 音频转文字 中间层拿出来给TTS 看能否重构出原音频
(一定要包含原音频的信息 才会成功重构)
3.2 全局可解释(什么样的图片叫做猫)
想知道某个滤波器主要是检测哪个部分的?检测到什么了什么部分说明是猫?
可以用梯度上升找使得这个滤波器得分最高的X 的样子。
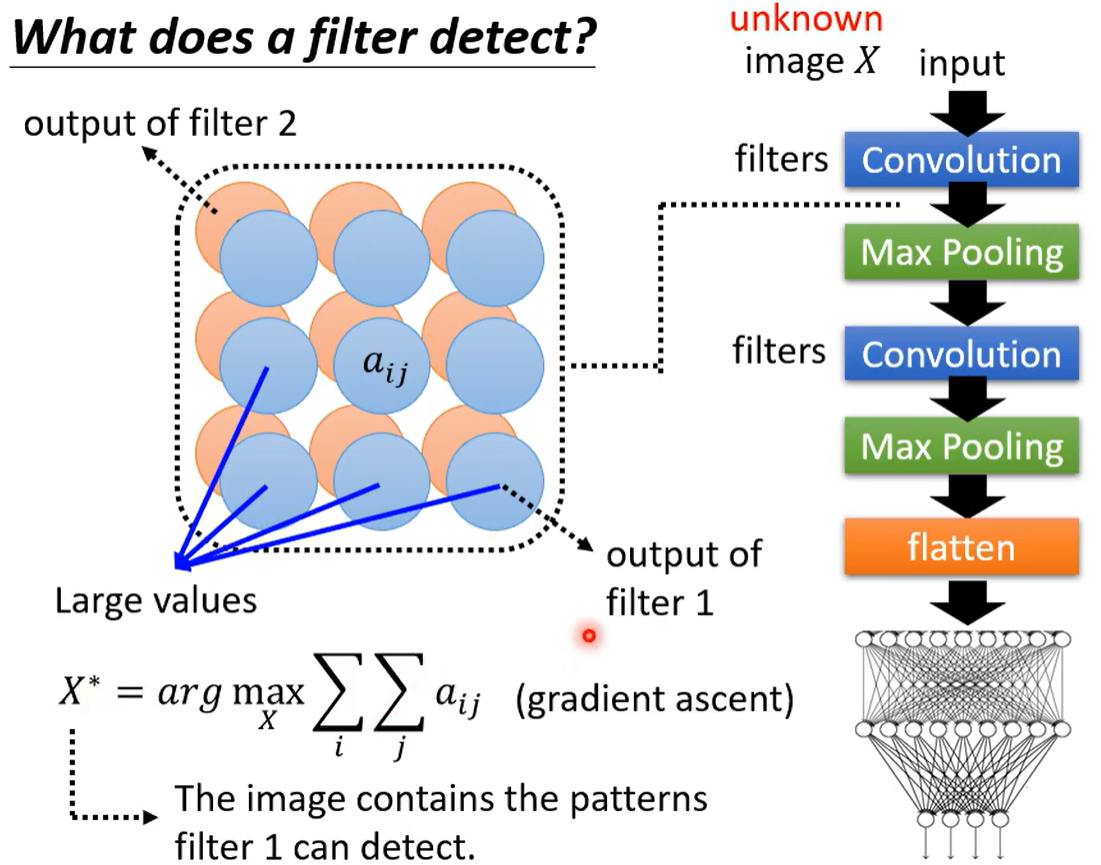
但是直接输出得分最高的图像(机器心目中最像的图像)人眼不一定会认为
因为图像需要一些噪声 才能帮助看到所有的物体(一定鲁棒性)
如果想让图片生成人所希望看到的 还需要进行一些正则化/GAN 之类的操作 减少无关量+生成更接近人心目中的图像
















)


