文章目录
- 一、查询基础
- QuerySet 详解
- 一对多关联查询
- 多对多关联查询
- 二、N+1查询问题
- 问题分析
- 检测方法
- 解决方案
- 三、高级查询优化
- values()
- values_list()
- values()和values_list()对比
- Q() 对象复杂查询
- 查看生成的 SQL
- 四、项目实战
- 场景
- 实战
一、查询基础
QuerySet 详解
Django 中通过模型类的 Manager 构建 QuerySet 来检索数据库对象,其核心特性包括:
- 代表数据库中对象的集合
- 可通过过滤器缩小查询范围
- 具有惰性执行特性(仅在需要结果时才执行 SQL)
常用过滤器
all():返回所有对象filter(**kwargs):返回满足条件的对象exclude(** kwargs):返回不满足条件的对象get(**kwargs):返回单个匹配对象(无匹配或多匹配会抛异常)- 切片
# 切片操作示例:返回前5个对象(LIMIT 5)
Book.objects.all()[:5]
一对多关联查询
假设一个作者可以写多本书,但每本书只能属于一个作者。
from django.db import modelsclass Author(models.Model):first_name = models.CharField(max_length=100)last_name = models.CharField(max_length=100)def __str__(self):return f"{self.first_name} {self.last_name}"class Book(models.Model):title = models.CharField(max_length=100)publication_date = models.DateField()# 外键关联Author,级联删除,反向查询名为booksauthor = models.ForeignKey(Author, on_delete=models.CASCADE, related_name='books')def __str__(self):return self.title
正向查询(通过外键属性访问)
b = Book.objects.get(id=2)
b.author # 获取关联的Blog对象,查询数据库
b.author = some_body # 设置关联对象
b.save() # 保存更改
使用 select_related() 预加载关联对象,避免额外查询
b = Book.objects.select_related().get(id=2)
print(b.author) # 已预加载到缓存,使用缓存,不查询数据库
反向查询(通过关联管理器)
# 未定义related_name, 默认Manager名称为:<模型名称小写>_set
a = Author.objects.get(id=1)
a.book_set.all() # 返回所有关联的Book# 定义了related_name='books'
a.books.all() # 更直观的访问方式
关联对象操作方法如下。所有 “反向” 操作对数据库都是立刻生效,保存到数据库。
add(obj1, obj2):添加关联对象create(**kwargs):创建并关联新对象remove(obj1, obj2):移除关联对象clear():清空所有关联set(objs):替换关联集合
a = Author.objects.get(id=1)
a.books.set([b1, b2]) # b1 和 b2 都是 Book 实例
多对多关联查询
假设一个作者可以写多本书,一本书也可以有多个作者。
from django.db import modelsclass Author(models.Model):name = models.CharField(max_length=100)email = models.EmailField()def __str__(self):return self.nameclass Book(models.Model):title = models.CharField(max_length=200)publication_date = models.DateField()# 多对多关联Authorauthors = models.ManyToManyField(Author, related_name='books')def __str__(self):return self.title
正向与反向查询示例
# 正向查询
b = Book.objects.get(id=3)
b.authors.all() # 获取所有关联的Author
b.authors.count()
b.authors.filter(name__contains="张三")# 反向查询
a = Author.objects.get(id=5)
a.book_set.all() # 获取所有关联的Book
多对多关联中,add()、set() 和 remove() 可直接使用主键
a = Author.objects.get(id=5)
a.book_set.set([b1, b2])
# 等价于
a.book_set.set([b1.pk, b2.pk])
二、N+1查询问题
问题分析
N+1 查询是常见的性能问题,表现为主查询后执行 N 次额外查询。例如:
books = Book.objects.all()
for book in books:print(book.author.first_name)
以上代码会产生 1 次查询获取所有 Book,加上 N 次查询获取对应的 Author(N 为 Book 数量),共 N+1 次查询。
检测方法
- Django Debug Toolbar:直观显示请求中的 SQL 查询
- 日志记录:配置日志记录 SQL 语句
- 性能分析工具:如 Django Silk 分析查询性能
解决方案
方法 1:使用 select_related
适用于一对多(正向)和一对一关系,通过 SQL JOIN 预加载关联对象
- 语法:
select_related('related_field'),related_field是模型中定义的ForeignKey或OneToOneField字段
books = Book.objects.select_related('author').all()
for book in books:print(book.author.first_name) # 无额外查询
可结合 only() 选择需要的字段
books = Book.objects.select_related('author').only('title', 'author__name')
支持多级关联
# 加载书籍、作者及作者家乡信息
books = Book.objects.select_related('author__hometown').all()
for book in books:print(book.author.hometown.name) # 无额外查询
方法 2:使用 prefetch_related
适用于多对多和反向关系,通过批量查询后在 Python 中关联。适用场景:
- 多对多关系(ManyToManyField)
- 反向一对多关系
- 反向一对一关系
books = Book.objects.prefetch_related('authors').all()
for book in books:print(book.authors.all()) # 无额外查询
参考资料:Django 数据库访问优化
三、高级查询优化
values()
返回字典形式的查询集(返回一个 ValuesQuerySet 对象,其中每个元素是一个字典),适合提取特定字段
books = Book.objects.values('title', 'author')
for book in books:print(book) # 输出示例
{'title': 'Book1', 'author': 'Author1'}
{'title': 'Book2', 'author': 'Author2'}
values_list()
返回元组形式的查询集(返回一个 ValuesListQuerySet 对象,其中每个元素是一个元组),内存占用更低
books = Book.objects.values_list('title', 'author')
for book in books:print(book)### 输出示例
('Book1', 'Author1')
('Book2', 'Author2')
使用 flat=True 获取单一字段值列表。如果有多个字段时,传入 flat 会报错。
titles = Book.objects.values_list('title', flat=True)
# <QuerySet ['红楼梦', '西游记', ...]>
使用 named=True ,结果返回 namedtuple()
books_info = Book.objects.values_list("id", "title", named=True)
# <QuerySet [Row(id=1, title='红楼梦'), ...]>
values()和values_list()对比
| 对比维度 | values() | values_list() |
|---|---|---|
| 返回值类型 | 返回一个包含字典的查询集,字典的键为字段名,值为字段对应的数据 | 返回一个包含元组的查询集,元组中的元素依次对应指定字段的值 |
| 内存占用 | 相对较高,因为字典需要存储键值对信息 | 通常更节省内存,元组是更轻量的数据结构,无需存储字段名 |
| 使用场景 | 适合需要通过字段名访问字段值的场景,例如需要明确知道每个值对应的字段时 | 适合仅需要获取字段值的场景,例如只需批量获取某个或某几个字段的具体数据时 |
Q() 对象复杂查询
Q() 对象用于构建复杂查询条件,支持逻辑运算
&:逻辑与(AND)|:逻辑或(OR)~:逻辑非(NOT)
from django.db.models import Q# 标题含Python或作者为John的书籍
books = Book.objects.filter(Q(title__icontains="Python") | Q(author="John")
)# 复杂组合条件
books = Book.objects.filter((Q(title__icontains="Python") | Q(title__icontains="Django")) &~Q(author="John")
)
查看生成的 SQL
调试时可查看 QuerySet 生成的 SQL
queryset = Book.objects.filter(author="John")
print(queryset.query) # 输出对应的SQL语句
四、项目实战
场景
Django+Vue 后台管理系统中,一般需要支持不同的数据权限
- 仅本人数据权限
- 本部门及以下数据权限
- 本部门数据权限
- 指定部门数据权限
- 全部数据权限
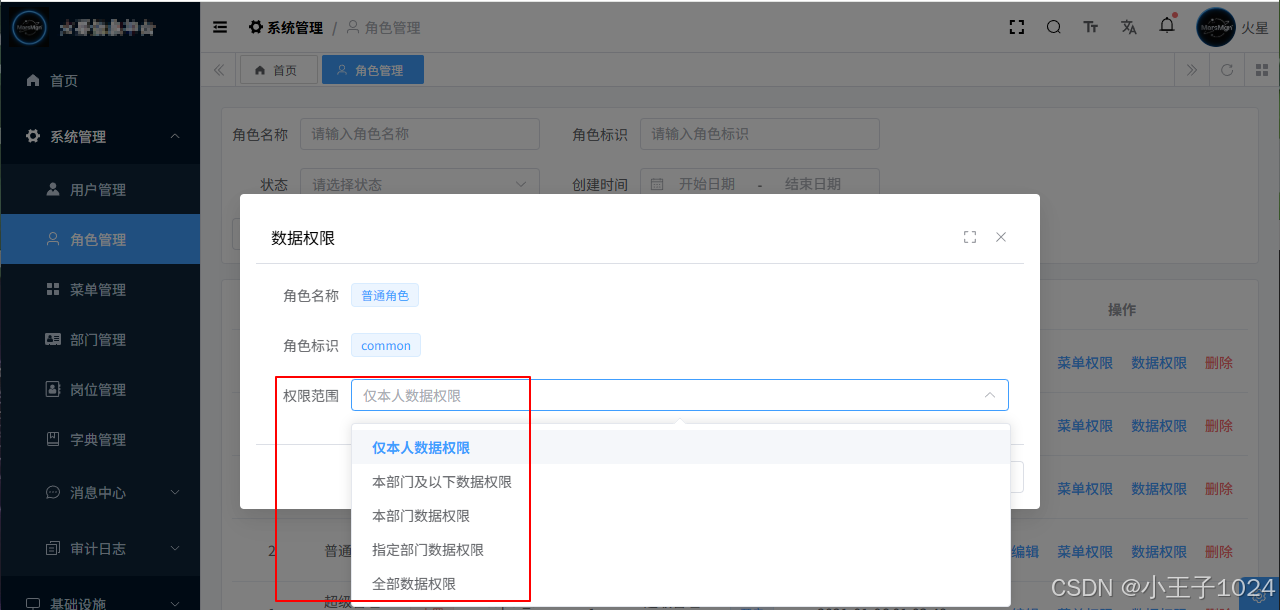
数据权限与功能权限(基于RBAC实现)的区别
- 功能权限:控制 “能做什么”(如新增、删除按钮的显示和执行)
- 数据权限:控制 “能看到什么数据”(如销售经理只能查看自己团队的数据)
实战
使用Q() 对象构建复杂查询,实现灵活的数据权限计算
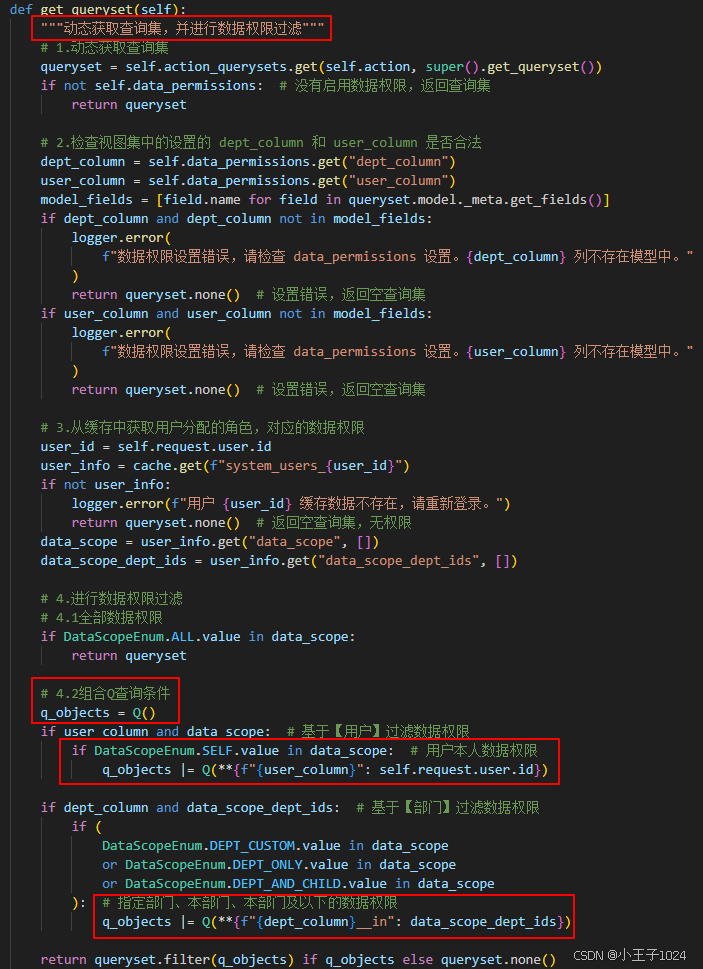
点击查看完整代码
您正在阅读的是《Django从入门到实战》专栏!关注不迷路~




- 标幺值计算与变压器建模)





)








