目录
数据聚合
聚合的种类
DSL实现聚合
桶聚合
度量聚合
RestAPI实现聚合
多条件聚合
自动补全
拼音分词器
自定义分词器
自动补全查询
实现搜索框自动补全
数据同步
数据同步思路分析
实现elasticsearch与数据库数据同步
集群
搭建ES集群
集群脑裂问题
集群故障转移
集群分布式存储
集群分布式查询
数据聚合
聚合的种类
聚合可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
桶聚合:用来对文档做分组
TermAggregation:按照文档字段值分组
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
度量聚合:用以计算一些值,比如:最大值、最小值、平均值等
Avg:求平均值
Max:求最大值
Min:求最小值
Stats:同时求max、min、avg、sun等
管道聚合:其它聚合结果为基础做聚合
参与聚合的字段类型必须是:
keyword
数值
日期
布尔
DSL实现聚合
桶聚合

默认情况下,桶聚合会统计桶内的文档数量,记为_count,并且按照_count 降序排序。我们可以修改结果排序方式:

默认情况下,桶聚合是对索引库的所有文档做聚合,我们可以限定要聚合的文档范围,只要添加query条件即可:

度量聚合
例如,我们要求获取每个品牌的用户评分的min、max、avg等值.

RestAPI实现聚合
聚合请求的构造

聚合结果的解析

多条件聚合
多条件聚合构建
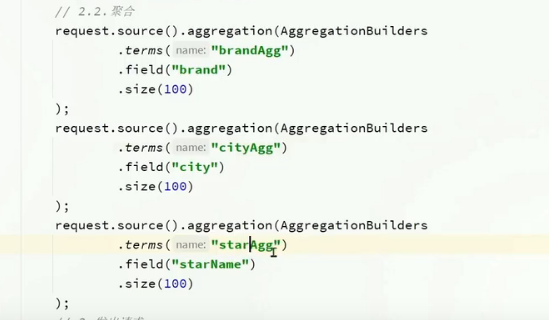
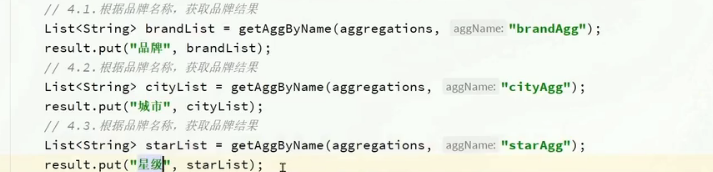
结果解析
自动补全
拼音分词器
使用拼音分词
要实现根据字母做补全,就必须对文档按照拼音分词。插件:infinilabs/analysis-pinyin: 🛵 This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
下载完将压缩包解压到es的plugins目录即可
自定义分词器
Elasticsearch 中分词器(Analyzer)的组成包含三部分:
-
Character Filters(字符过滤器)
-
在 Tokenizer 之前对原始文本进行预处理。
-
例如:删除特殊字符、替换字符(如将
&替换为and)。
-
-
Tokenizer(分词器)
-
将文本按照特定规则切割成词条(Term)。
-
例如:
-
keyword:不分词,将整个文本作为一个词条。 -
ik_smart:智能切分(粗粒度分词)。
-
-
-
Token Filters(词条过滤器)
-
对 Tokenizer 输出的词条进行进一步处理。
-
例如:大小写转换、同义词处理、拼音处理等。
-
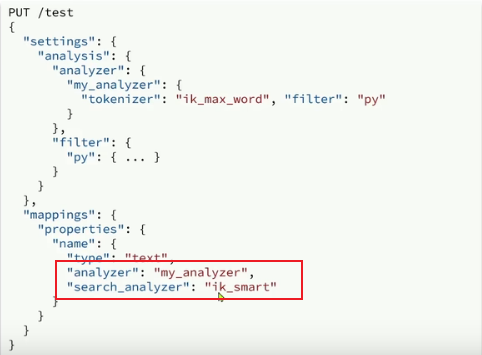
我们可以在创建索引库时,通过setting来配置自定义的analyzer(分词器):

自定义分词器配置

拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用。
因此字段在创建倒排索引时应该用my_analyzer分词器;字段在搜索时应该使用ik__smart分词器;
自动补全查询
es提供了Completion Suggerter查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
参与补全查询的字段必须是completion类型。

字段的内容一般是用来补全的多个词条形成的数组

查询语法

实现搜索框自动补全
1.修改索引库,设置自定义拼音分词器
2.修改索引库的name、all字段,使用自定义分词器
3.索引库添加一个新字段suggestion,类型为completion 字段,使用自定义分词器
4.给实体类添加suggestion字段,内容包含所需要补词的内容
5.重新导入数据
RestAPI实现自动补全

结果解析

数据同步
数据同步问题分析
es中酒店数据来自于mysql数据库,因此mysql数据发生改变时,es也必须跟着改变,这个就是es与mysql之间的数据同步。
数据同步思路分析
方案一:同步调用
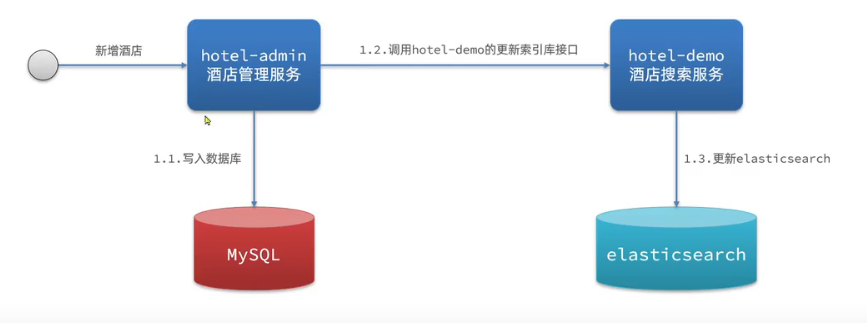
优点:实现简单,粗暴
缺点:耦合度高
方案二:异步通知
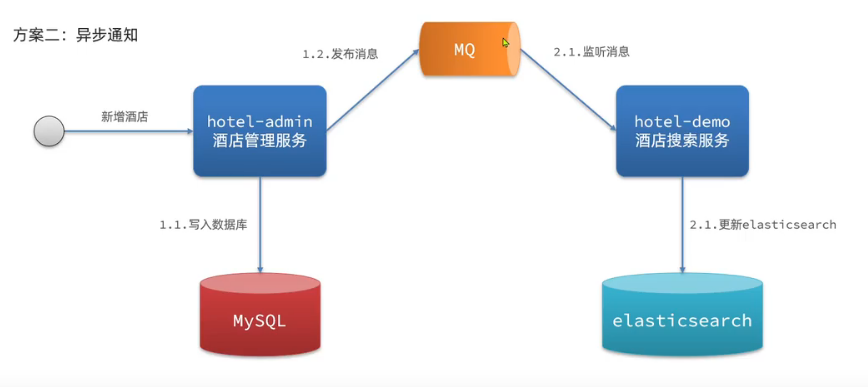
优点:低耦合,实现难度一般
缺点:依赖mq的可靠性
方案三:监听binlog
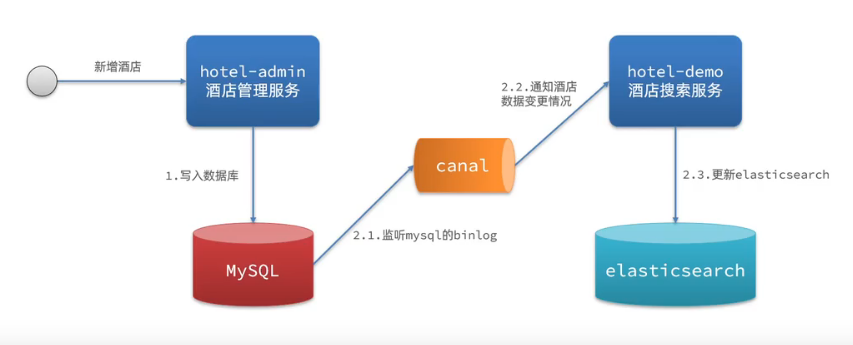
优点:完全接触服务间耦合
缺点:开启binlog增加数据库负担、实现复杂度高
实现elasticsearch与数据库数据同步
利用MQ实现mysql与es数据同步
步骤:
导入数据
声明exchange、queue、RoutingKey
完成数据库中增、删、改业务并完成消息发送
完成消息监听并且更新es中数据
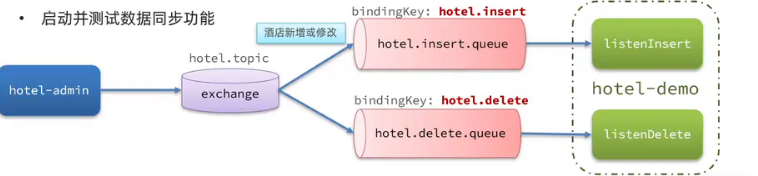
导入MQ依赖
配置MQ
集群
ES集群结构
单机的es做数据存储,必然面临两个问题:海量的数据存储问题、单点故障问题。
海量数据存储问题:将索引库从逻辑上拆分为N个分片,存储到多个节点
单点故障问题:将分片数据在不同节点备份
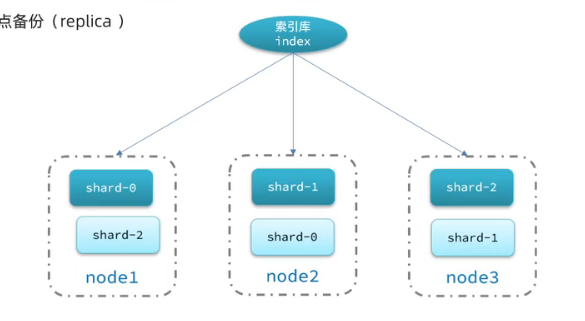
搭建ES集群
利用docker容器模拟3个es的节点。


)

)



文件语法详解)





)




