> 💡 原创经验总结,禁止AI洗稿!转载需授权
> 声明:本文所有观点均基于多个领域的真实项目落地经验总结,数据说话,拒绝空谈!
目录
引言:时序数据库选型的“下半场”
一、维度一:架构哲学 —— 决定了你的“天花板”在哪里
二、维度二:数据生命周期管理 —— 从“边缘”到“云端”的价值闭环
2.1 端边协同能力:
2.2 数据模型与业务亲和度:
三、维度三:性能剖析 —— 超越TPS的“综合国力”竞赛
四、维度四:生态与开发者体验
4.1 查询语言
4.2 大数据生态集成
4.3 AI 原生集成(MCP)
4.4 原生API:为性能而生的开发者体验
结论:如何做出最适合你的选择?
引言:时序数据库选型的“下半场”
时序数据的洪流已成为数字世界的“新常态”。如果说TSDB选型的“上半场”是围绕写入吞-吐量(TPS)展开的“军备竞赛”,那么“下半场”则聚焦于一个更核心的问题:如何以体系化的能力,最低成本、最高效率地管理从边缘到云端的完整数据生命周期,并从中榨取最大价值?
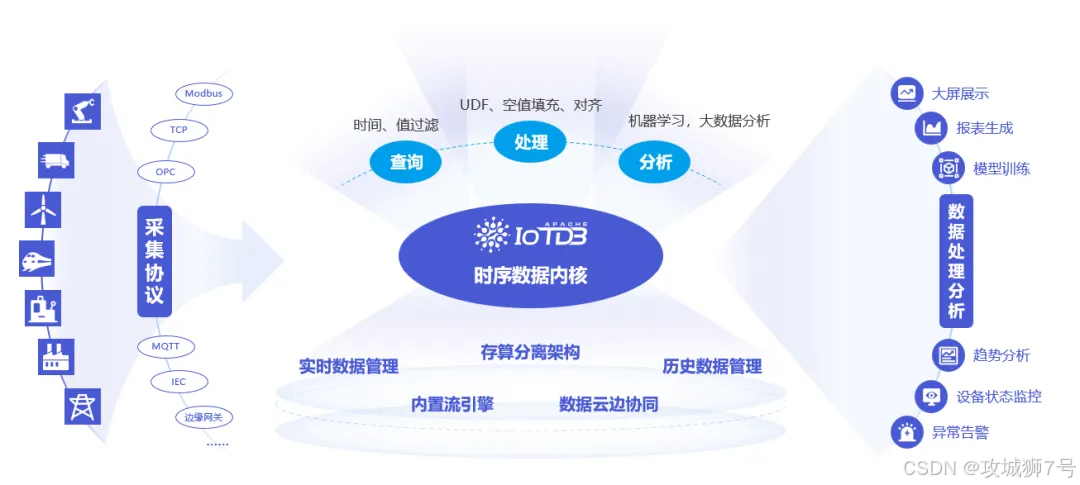

单一的性能指标已无法回答这个问题。我们需要一个全新的评估框架,从根源的架构哲学出发,审视每一款产品在不同维度上的设计取舍。为此,我们选择了四位极具代表性的“选手”,它们分别代表了四种不同的技术路线:
(1)Apache IoTDB:为大规模工业物联网(IIoT)而生的原生分布式架构。
(2)InfluxDB:市场占有率领先的通用型监控与时序应用标杆。
(3)TimescaleDB:根植于PostgreSQL生态的关系型扩展架构。
(4)VictoriaMetrics:以资源效率和Prometheus兼容性著称的监控优化型新锐。
本文将带领读者,从四个核心维度,穿越迷雾,洞悉本质。
一、维度一:架构哲学 —— 决定了你的“天花板”在哪里
架构是数据库的DNA,它从根本上决定了系统的扩展性、可靠性与运维复杂度。

深度分析:
(1)Apache IoTDB 的选择最为“彻底”。它的设计前提就是“数据量和设备量一定会爆炸式增长”。其数据分片、多元共识协议、元数据管理等机制,都是为了确保系统在扩展到成百上千节点时,依然能保持高性能和高可用性。这是一种“着眼未来”的架构,尤其适合有大规模、长期数据管理需求的重工业、新能源、车联网等领域。
(2)InfluxDB 和 TimescaleDB 则代表了“务实演进”的路线。它们拥有极其出色的单机性能和用户体验,足以应对大量中小型应用。然而,当业务规模跨越某个阈值时,用户将面临一个艰难的选择:是投入巨大成本升级到闭源的企业版,还是自己动手搭建一套复杂的、需要专业团队维护的开源集群?
(3)VictoriaMetrics 则是一个“优等偏科生”。它精准地抓住了Prometheus在大规模场景下的性能痛点,通过优化的存储和索引,在监控数据处理上做到了极致。但如果你的需求超出了监控告警,需要进行复杂的跨设备分析、长周期趋势预测,它的能力可能会受到限制。
结论:架构哲学没有绝对的优劣,只有场景的匹配度。评估你的业务终局规模,是选择正确架构的第一步。
二、维度二:数据生命周期管理 —— 从“边缘”到“云端”的价值闭环
现代物联网应用的核心挑战之一,是如何高效管理跨越“端-边-云”的完整数据链路。
2.1 端边协同能力:
这是 Apache IoTDB 的绝对主场。它原生提供了轻量级的边缘端版本和强大的端云同步(Data Sync)工具。你可以在边缘网关或设备上部署一个IoTDB实例进行本地数据处理和缓存,再通过内置工具,将压缩后的`TsFile`文件高效、断点续传地同步至云端。这套机制是为弱网络、高延迟的工业环境“量身定制”的,能极大降低带宽成本和云端写入压力。
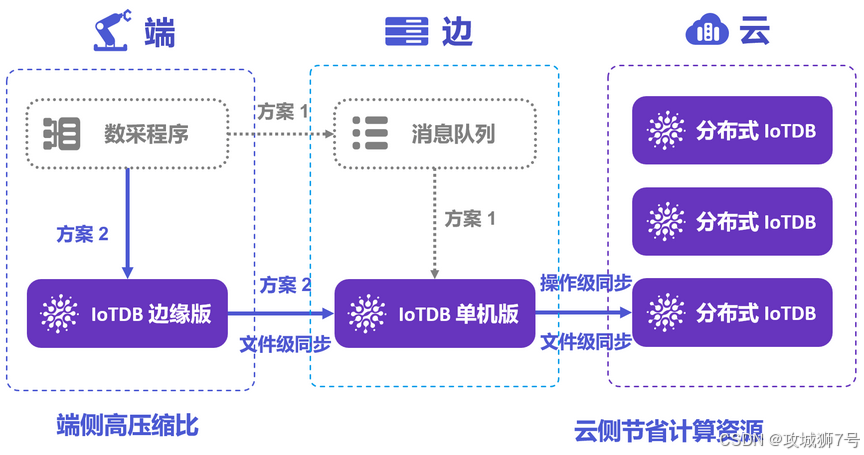
相比之下,其他三者在这一领域都需要依赖外部组件。InfluxDB 依赖Telegraf,VictoriaMetrics 依赖vmagent,它们都是优秀的采集代理,但在数据持久化、本地预聚合、复杂同步策略等方面,与一个原生的数据库引擎相比,能力和灵活性都较为有限。
2.2 数据模型与业务亲和度:
(1)IoTDB 的树状模型 (`root.group.device.sensor`) 与工业设备的物理层级结构天然同构。这种模型让数据组织非常直观,管理和查询都极为便利,开发体验极佳。
(2)InfluxDB 的 Tag-Value模型 和 VictoriaMetrics 的 Label模型 非常相似,它们在处理多维度的监控指标时极为灵活。但在描述固定的层级关系时,需要将层级信息打散到多个Tag/Label中,可能导致管理复杂化。
(3)TimescaleDB 则完全继承了 关系模型,对于习惯了SQL和范式设计的开发者来说最为友好,但也可能在处理超高基数(设备和测点数量爆炸)的场景时面临性能挑战。
三、维度三:性能剖析 —— 超越TPS的“综合国力”竞赛
我们参考了业界公认的TSBS(Time Series Benchmark Suite)等多方公开的性能评测数据,从三个关键维度进行对比。
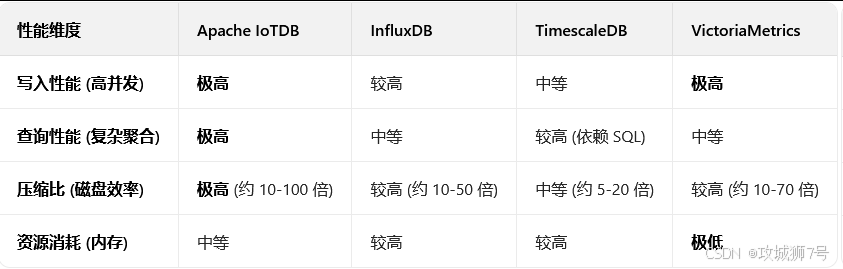
深度分析:
(1)写入性能:VictoriaMetrics 和 IoTDB 在高并发写入上通常表现最为出色。VictoriaMetrics得益于其精简的架构,而IoTDB则依靠其为乱序、高频写入优化的`IoTLSM`引擎。InfluxDB同样强大,但内存消耗相对更高。TimescaleDB由于需要维护更重的事务和索引,写入性能相对前三者稍弱。
(2)查询性能:这是 IoTDB 和 TimescaleDB 的优势领域。IoTDB的`TsFile`格式包含了丰富的元数据和索引,使其在执行跨设备、跨时间的复杂聚合查询时性能卓越。TimescaleDB则可以利用PostgreSQL强大的查询优化器和丰富的SQL函数,处理复杂的分析任务。而InfluxDB和VictoriaMetrics在简单的、基于时间的范围查询上极快,但在复杂的分析查询上则相对受限。
(3)资源效率:VictoriaMetrics在内存和CPU使用上堪称典范,做到了极致的高效。而 IoTDB 则在磁盘压缩比上拥有断层式优势,其自研的`TsFile`格式和多种时序专用编码压缩算法,使其能以极低的成本存储海量历史数据,这对于需要长期保存数据的工业场景至关重要。
四、维度四:生态与开发者体验
4.1 查询语言
类SQL阵营:IoTDB 和 TimescaleDB 提供了对开发者最友好的类SQL查询语言。学习成本极低,能快速上手,并与现有的BI、数据分析工具无缝对接。
DSL阵营:InfluxDB 的InfluxQL/Flux和 VictoriaMetrics 的MetricsQL(兼容PromQL)是功能强大的领域特定语言。它们在各自的领域内表达能力很强,但需要专门的学习过程。
4.2 大数据生态集成
在这方面,Apache IoTDB 作为Apache基金会的顶级项目,拥有天然的优势。它与 Apache Spark、Flink、Hadoop 等生态系统深度集成,提供了原生的Connector,可以非常方便地构建“存储+计算”一体化的数据平台。
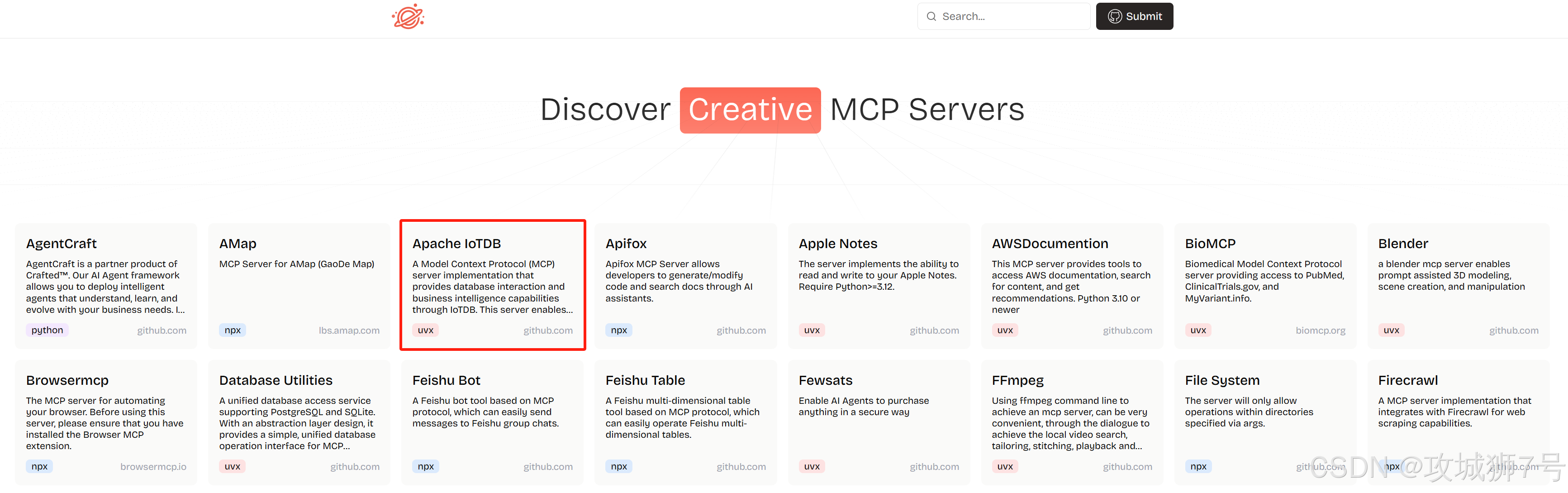
4.3 AI 原生集成(MCP)
基于 Model Context Protocol 的 IoTDB MCP Server,让大模型以自然语言直接调用数据库的查询与元数据工具,统一“工具调用”方式,显著降低学习与集成成本。
对开发者:无需手写复杂 SQL/SDK,NL→Tool 自动化;访问凭证由 Server 侧统一托管,提升安全性与可审计性。
对生态:可与常见 MCP 客户端快速对接,将 AI 助手无缝接入企业时序数据与业务流程。
趋势判断:MCP 正在把 TSDB 带入“AI 原生”时代,建议尽早开展试点,积极拥抱 AI 赋能的数据智能新范式。
4.4 原生API:为性能而生的开发者体验
除了对开发者极其友好的类SQL接口,IoTDB 还提供了很多不同编程语言的API供各种开发者使用,大大降低开发人员成本。

现在以极致性能而生的原生Java API为例,以下是一个极具代表性的`Tablet`批量写入示例,它完美诠释了IoTDB在IoT场景下的数据处理哲学:
// 推荐使用连接池管理会话SessionPool pool = new SessionPool.Builder().host("127.0.0.1").port(6667).user("root").password("root").maxSize(3).build();// 1. 定义设备与测点结构 (Schema)List<MeasurementSchema> schemaList = new ArrayList<>();schemaList.add(new MeasurementSchema("temperature", TSDataType.DOUBLE, TSEncoding.GORILLA));schemaList.add(new MeasurementSchema("status", TSDataType.BOOLEAN, TSEncoding.PLAIN));// 2. 创建Tablet,并指定设备ID和SchemaTablet tablet = new Tablet("root.factory.workshop1.device01", schemaList, 100);// 3. 批量添加数据行long timestamp = System.currentTimeMillis();for (long row = 0; row < 100; row++) {int rowIndex = tablet.rowSize++;tablet.addTimestamp(rowIndex, timestamp + row);// 添加温度值 (DOUBLE)tablet.addValue("temperature", rowIndex, ThreadLocalRandom.current().nextDouble(20, 30));// 添加状态值 (BOOLEAN)tablet.addValue("status", rowIndex, row % 2 == 0);}// 4. 一次性写入Tabletpool.insertTablet(tablet);pool.close();代码解读:
这段代码展示了向单个设备(`root.factory.workshop1.device01`)一次性写入100条记录(包含温度和状态两个测点)的典型场景。
(1)`SessionPool`:首先,我们使用连接池来高效管理连接,这是生产环境的最佳实践。
(2) `MeasurementSchema`:我们为设备定义了数据结构,包括测点名称、数据类型,甚至可以指定高效的压缩编码(如`GORILLA`)。
(3)`Tablet`:这是性能的关键。`Tablet` 是一个内存中的数据结构,可以看作一张“数据表”。我们将多行数据先缓存到`Tablet`中。
(4)`insertTablet`:最后,通过一次网络调用,将整个`Tablet`批量发送到数据库。这种方式极大地减少了网络开销和服务器负载,相比于逐条写入,性能有数量级的提升。
这种“一次定义、批量写入”的模式,正是IoTDB能够实现超高性能写入的核心所在,也体现了其对开发者体验的深刻理解——在提供便捷性的同时,也为追求性能的开发者敞开了高效的大门。
结论:如何做出最适合你的选择?
综合以上分析,我们可以得出一个清晰的选型决策矩阵:
如果你正在构建一个大规模、长周期的工业物联网平台(如车联网、智慧能源、高端制造),对系统的扩展性、边云协同能力和长期存储成本有极致要求,那么 Apache IoTDB 无疑是你的首选。它在这些“硬核”指标上的优势是体系化的、难以被替代的。
如果你的主要场景是IT基础设施或应用的监控,特别是已经在使用或熟悉Prometheus生态,且对资源效率和高基数指标处理非常敏感,那么 VictoriaMetrics 将是一个极具吸引力的选择。
如果你的团队技术栈深度绑定PostgreSQL,或你的业务需要大量复杂的关系查询与时序查询混合分析,那么 TimescaleDB 可以让你在不离开熟悉环境的前提下,平滑地获得时序能力。
如果你需要快速启动一个中小型监控或通用IoT项目,希望拥有成熟的社区和丰富的第三方工具支持,InfluxDB 依然是一个强大而稳健的“万金油”选项。
最终,用对工具,才能真正释放沉睡在海量时序数据中的巨大价值。
> 👉 下载 Apache IoTDB 开源版体验:`https://iotdb.apache.org/zh/Download/`
> 👉 企业级支持与更强功能: `https://timecho.com`
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!

——PyTorch vs. TensorFlow详解)




)
)





)


详细讲解C++List的使用及模拟实现)
)

