摘要
【关键词】
第一章 绪论
1.1 研究背景及意义
1.2 国内外文献综述
1.2.1 国外研究结果
1.2.2 国内研究结果
1.3 本课题主要工作
第二章 相关工作介绍
2.1文本量化方法
2.2 CNN、LSTM模型
2.3评测准确率及收益率
第三章 开发技术介绍
3.1 系统开发平台
3.2平台开发相关技术
3.2.1 Python技术
3.2.2 Mysql数据库介绍
3.2.3 Mysql环境配置
3.2.4 B/S架构
3.2.5 Django框架
第四章 系统分析
4.1 可行性分析
4.1.1 技术可行性
4.1.2 操作可行性
3.1.3经济可行性
4.2性能需求分析
4.3非功能性需求
第五章 系统设计
6.1功能结构
6.2 数据库设计
6.2.1 数据库E/R图
6.2.2 数据库表
第六章 系统功能实现
6.1 用户登录
6.2用户管理
6.3 管理员管理
6.4股票列表
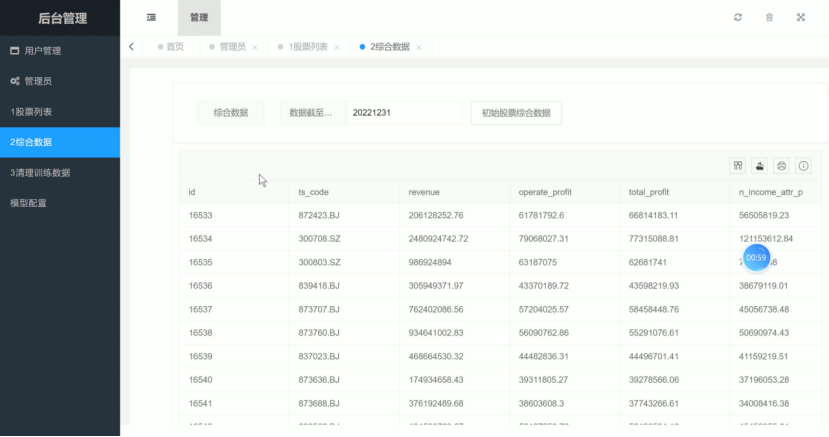
6.5 综合数据
6.6 模型配置
第七章 系统测试
第八章 总结
8.1 总结
8.2 展望
致 谢
参考文献
股市的涨跌变化及价格预测一直都是一个火热的话题,以往机器学习刚兴起时,便被用于股市预测的研究当中。而随后来机器学习纵向发展,引发了深度学习的出现及兴起,针对国内股市,量化交易较为火热,但在国内学术上此方面的研究还较少,于是本文提出并实现了结合及股市历史的CNN及LSTM预测模型,以深度学习方法来挖掘股市变化的规律,并分析是否能预测其变化。本研究主要内容有:(1)获取2019.01-2023.12的内容,及相关股票在该期间的历史数据,以此为基础构建出多种不同的训练集,如:CNN的新闻标题word2vec训练集、新闻关键词word2vec训练集、新闻关键词百度指数训练集、新闻倾向值及股市数据训练集;LSTM的股市数据训练集、百度指数加股市数据训练集、新闻倾向加股市历史训练集;(2)针对CNN的两类训练集,构建出文本量化预测模型和纯数值预测模型;LSTM构建出一种预测模型。对其分别从模型参数、学习率、训练次数、loss公式等方面进行优化,提高预测准确率和收益率;(3)依据集成学习方法,把本研究中所提出的模型构成一个集成模型,以得到一个总模型,并以十折十次交叉验证法测试所有模型的准确率及收益率。从研究结果来分析,深度学习结合和股市历史数据来预测股市未来变化有一定的准确性,为研究股市变化的内在规律提供了一定的帮助。
第一章 绪论
伴随科技发展,人们通过各种软件来进行股票交易,同时,在股市交易当中,出现了基本分析、技术分析、演化分析等分析方法。近年来,计算机领域快速发展,机器学习、深度学习等技术兴起,也使得量化投资变得越来越火热,人们相信他们能通过机器找出股市的内在关系并以此获利。
人们每天通过交易软件频繁地进行买入卖出,由此,股票价格也会一直在变化,并且会产生海量的交易数据。投资者在投资股票时,越来越把这些数据作为重要的参考依据,能用其画出各种各样的K线及结合各种理论来得出买入卖出点,这也即是技术分析。
新闻对股市有一定影响,尤其是,这是投资者了解所购股票的公司经营状况的主要手段,其能影响投资者的交易意愿。这些的报道往往包含有上市公司的战略决策、经营状况、财务报告等等,这些资讯对投资者选择投资时机及研究市场走势都起到了重要的作用,这也即是基本分析。
内容中通常包含大量有价值的信息,其与股市历史数据有一定的关联,应当用更为先进的方法来挖掘。在国内学术中,早在2012年便有人以机器学习方法去挖掘新闻中内容,证实新闻对股市有较强的影响[1]。而在国外,更早一点学者们便已对金融市场中的三种人工智能技术,即人工神经网络,专家系统和混合智能系统进行了比较研究, 表明这些人工智能方法的准确性优于以传统统计方法处理财务问题[2]。
在2023年10月,全球第一只应用人工智能、机器学习进行投资的ETF:AI-powered Equity ETF被推出。它利用了相关数学方法,每天24小时不停地去处理上百万条企业公告及新闻,以此不断优化自身的模型。但从下图1中可看出,该ETF从17年10月到18年4月仍出现了不少的大起大落,半年时间其股价总增长率为6.81%。而美股标准普尔500指数从2562.87上升到2670.29,增长率为4.19%,表明这AI-ETF整体上要好于市场,但其仍有不少错误的时候,仍需要进行一定的沉淀及发展。实际上在国内的众多量化投资平台上,也有多个不同的看似优秀的预测模型、交易策略,但往往这些模型的策略回测结果都很漂亮,但用于实战时却不尽人意。
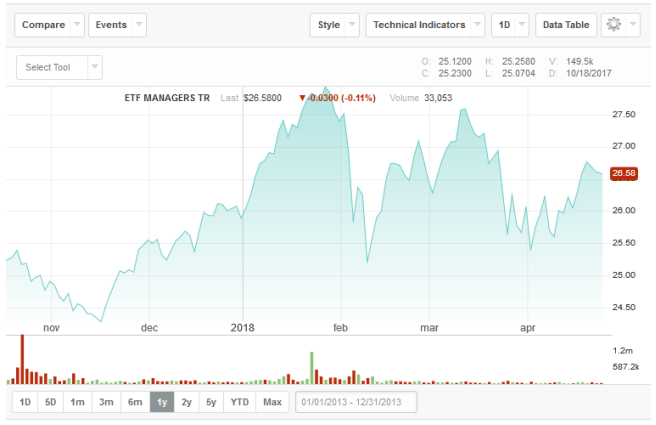
图1-1 AI-powered Equity ETF从2023/10/18-2023/04/23走势图,图片来源[3]
现在深度学习也已经被用于股市投资当中。深度学习神经网络是一个高度复杂的非线性人工智能系统,是对人脑抽象和具象能力的人工模拟,其具有自组织及自调整等能力,适合处理多影响因素、类随机的复杂非线性难题。同时,利用神经网络方法能把内容进行数值量化,化为一个个词语矩阵,现在已有较为成熟的方法,如:Word2Vec。由此,把新闻文本内容量化后,便可将其加入到深度学习神经网络中训练。
而CNN和LSTM作为新型神经网络,各自有其特性。CNN可训练新闻文本转换成数值矩阵后的数据集;而LSTM具备时序观念,可以依照时间序列实现多个输入输出,训练具有时序属性的数据,且其通过记忆门解决了梯度消失问题。
以此,通过结合与股市历史数据,把深度学习应用在股市变化的分析中,以对股市的变化进行预测,依据预测结果制定交易策略,计算收益率,分析内在规律,为以深度学习方法结合和股市历史应用于国内股市的预测分析提供一定的理论与实践价值。
Nassirtoussi AK等学者基于金融新闻的标题来预测外汇市场中金额的日内变动[4],其实现了一种多层算法:第一层为语义抽象层,解决了文本挖掘中共同参考的问题;第二层为情感积分层,提取情绪权重;第三层为同步目标特征减少(STFR)的动态模型创建算法,使用了机器学习中的三个算法,分别为SVM、K-NN和朴素贝叶斯方法,准确率颇高,在分析传统机器学习于股市预测中的应用有一定参考性。
而Maragoudakis M等学者使用了马尔科夫链蒙特卡罗(MCMC)贝叶斯推理方法[5],估计了通过树增强朴素贝叶斯(TAN)算法获得的网络结构的条件概率分布,来对股市进行预测。
而Vargas MR等人在2023年采用深度学习方法,以金融新闻标题和一套技术指标作为输入,对标准普尔500指数进行了当日涨跌预测[6]。其重点研究了卷积神经网络(CNN)和递归神经网络(RNN)的结构,构建了RCNN模型且与其它文献中的预测模型进行比较,研究结果显示CNN在捕捉文本语义方面优于RNN,而RNN在捕捉上下文信息和以复杂时间特征建模来进行股市预测中更优,并且RCNN模型要优于其它模型。
也有学者使用高频盘中股票的收益率作为输入数据,研究了三种无监督特征提取方法(主成分分析,自动编码器和受限波尔兹曼机)对网络预测未来市场行为的整体能力的影响[7]。实证结果表明,深层神经网络可以从自回归模型的残差中提取附加信息,提高预测性能。
国外相关文献,多是以是美国的股票市场作为研究目标的。基于以中国为代表的发展中国家的股票市场,国外学者的研究中较少涉及。
国内学者们更加倾向以一部分新闻财经内容或评论来量化为特征向量去预测股市的涨跌。
孟雪井[8]等学者在2016年时选取了国内9大财经网站爬取新闻作文本挖掘,然后从中获取出关键的词语,随后以这些词语去关联百度指数作为特征向量,以随机森林算法去选择重要特征,再以KNN算法去预测股市大盘指数涨跌。
同在2016年,邹海林使用 Adaboost结合决策树算法训练涨跌预测模型,其使用最近邻回归k-NN方法对股市收盘指数和涨幅进行回归结果分析,并对各种 HICT 词特征选择方法实验结果进行比较[9]。其在文本词语的处理上做出了较多的研究,使文本预测股市应用有一定的进展。
另外,孙瑞奇分析了BP、RNN、LSTM三种神经网络的区别并以LSTM神经网络对美股进行短期预测的可行性并作出相应对比,研究预测模型准确性[10]。其对2013年至2015年的美股股指进行预测,误差均值在1%以内,而对中国的上证指数预测时,误差在8.66%左右,故其认为预测中国股市时,需加入一些内容作输入特征,才能有效把误差减小。
本课题的主要目的是预测股市中个股在未来交易日的涨跌情况,以获取收益,故希望能获得较高的预测准确率及收益率。
经过了解、思索以及结合股市预测这一主题后,决定选用CNN和LSTM这两种深度学习算法来研究预测情况。本文主要解决的问题包括把的标题和内容以机器学习、百度指数和倾向词典等方法量化,结合股市历史数据组合成各种不同的训练集,建立CNN对文本矩阵及数值的两种输入数据的预测模型和LSTM对文本量化值这一种数据的预测模型,预测出股市中单个股票的未来涨跌情况(收盘价格涨跌情况),并以此设定交易策略,获取收益(计算出收益率)。
对其分析得出和股市历史数据在深度学习应用下对国内股市预测所能提供的帮助,为对国内股市的研究预测提供一定的参考。
第二章 相关工作介绍
2.1文本量化方法
一般需要把文本量化为数值数据,才方便用于进行模型输入。而从Deep learning for stock market prediction from financial news articles[7]一文中了解到,对于新闻文本的量化处理有各种各样的方法,得到各种各样量化后的数据,如:单词嵌入向量、句子嵌入向量、事件嵌入向量、词袋、结构化事件元组等。
而在这里参考了多篇相关文献的常用方式,及针对国内股市这一问题背景,提出了四种文本量化方法。
一为量化新闻标题为词语向量;二为以TF-IDF方法提取出每篇新闻中的关键词,然后将其量化为词语向量;三为以TF-IDF方法提取出每篇新闻中的关键词,然后以相关权重计算方法,得出一定数量的新闻集关键词语,去获取百度指数,即把新闻集量化为百度指数;四为利用相关数学公式去处理新闻集中词语的词频,量化为涨跌倾向值。
2.2 CNN、LSTM模型
CNN(卷积神经网络):
CNN一般用来处理图像任务,其卷积、池化操作能够提取出图像中各种不同的特征,并最终通过全连接网络实现信息的汇总及输出。在文本处理中,由于句子长度较短,且能独立表达意思,使得CNN也能较好地处理这些文本内容[11]。
CNN模型在结构上一般包括有4个部分,下图2-1为处理词向量训练集的CNN基本模型结构:
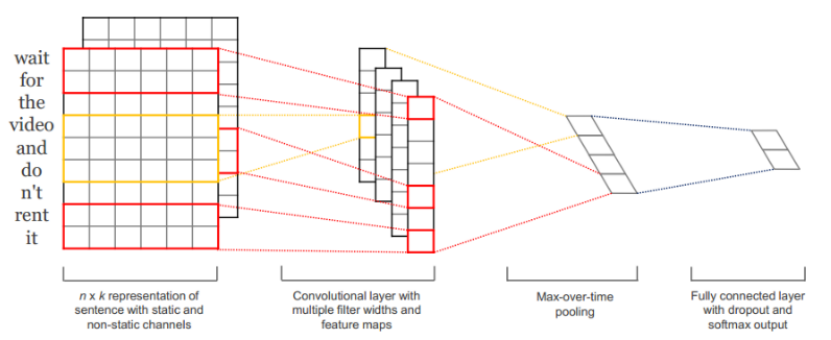
图2-1 处理词向量的CNN模型基本结构,图片来源[11]
1、输入层:
在文本处理中,输入层是文本词语对应的词向量从上到下排列的矩阵,假设文本m个词,词向量长度为l,那么这个矩阵就是m*l(可看作一副为m*l大小的图像)。对于未知词语,其向量可用相关默认值来填充。
2、卷积层:
卷积层通过卷积操作得到若干个特征图,卷积窗口的大小为n*l,其中n表示词语的个数,而l表示词向量的维数。通过这样的卷积操作,将得到若干个列数为1的特征图(一般同时会有多个不同大小的卷积窗口,来提取出不同的特征)。
3、池化层:
接下来的池化层,一般使用取最大值(其代表着最重要的信号)的方法来处理特征图,故也称最大池化层。这种池化方式可以解决可变长度的句子的输入问题,最终池化层的输出为各个特征图的最大值们,即一个一维的向量。
4、全连接+softmax层:
池化层的一维向量的输出通过全连接的方式,连接一个Softmax层,来获得输出(通常反映着最终类别上的概率分布)。
在此中间,卷积层和池化层可拥有多层,这些卷积池化层可以是同级的,即使用多个不同大小的卷积核及池化层去卷积并池化数据,获得多种不同的特征并拼接起来,再进行下一层处理;或是在一次卷积池化结束后,对得到的特征图再进行卷积池化,即特征多次提取,缩减单元数。
参考基于卷积神经网络的互联网短文本分类方法[12]一文中的流程模型图,及基于文本量化情况、输入数据集结构,构建了两种CNN预测模型。分别处理文本型(词向量)数据集(新闻标题训练集和新闻关键词训练集)和数值型数据集(新闻百度指数数据集和新闻涨跌倾向数值及股市历史数据集)。
同时,从卷积层数量、卷积窗口大小、多重卷积、特征拼接、全连接层数量等方面进行调优。
LSTM(长短时序记忆网络)
实际上LSTM的发展是有一个演变过程的,其演变顺序为BP神经网络(反向传播神经网络)-> RNN(循环神经网络)-> LSTM(长短时序记忆网络)。在每一个演变阶段,其保留前一阶段的特性同时还会针对于各种缺陷进行改进,于是本实验中直接采用LSTM应用于股票预测,LSTM的基本结构[10]可见图2-2。
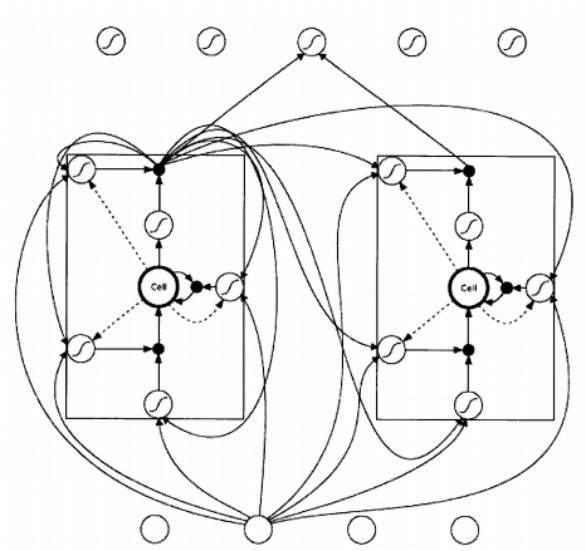
图2-2 LSTM基本结构,图片来源[10]
传统BP神经网络模型是由输入层、隐藏层和输出层组成,其中隐藏层包含一层或多层。数据从输入层输入,然后通过全连接向隐藏层传递下去,最后传导到输出层,其通过一层层反馈传递修正权值,从而调整整个神经网路。而其不足在于,其在训练的过程中并未体现先后时序关系,所以每次神经元权值的修正均只是基于单条数据的影响,没有时序概念。这在股票价格预测中理论上具有极大的缺陷。
随后因相关应用需要,RNN出现,其通过添加跨越时间点的自连接隐藏层而具有对时间进行显式建模的能力。即隐藏层的反馈,除了进入输出端,还进入了下一时间步的隐藏层,从而影响下一个时间步上的各个权值。而其主要缺陷在于随着神经网络层数的增加,会出现梯度消失的问题。
LSTM应运而生,它主要是给每个单元增加了记忆单元,这些记忆单元的入口主要由三个门控制着,分别是输入门、忘记门和输出门,操作功能有保存、写入和读取。这些门都是逻辑单元,用选择性记忆反馈的误差函数来随着梯度下降修正参数,根据反馈的权值修正数来选择性遗忘和部分或全部接受,这样就不会每个神经元都得到修改了,从而使梯度不会多次消失,这样前面几层的权值也可以得到相应的修改,同时使误差函数随梯度下降得更快。
调整LSTM隐藏层数、记忆单元门控遗忘概率,能使模型获得更好的效果。
集成模型:
最后对于所提出的所有模型,结合集成学习方法,将它们组成一个集成模型,主要使用结合策略中的学习法,来生成最终模型。
2.3评测准确率及收益率
利用各模型对于个股的涨跌进行预测,以预测结果为依据,来按照同样的交易策略进行交易,计算出预测的准确率及收益率。
其中使用十折十次交叉验证法来评测模型在准确率、收益率上的效果。十折十次交叉验证法,即在十折交叉验证(数据处理形式如图2-3)基础上,对于每一折的数据进行十次训练得到十次预测结果。这样一来,即一个模型对于一个数据集需进行10*10次训练,得到上百次预测结果、准确率及收益率。
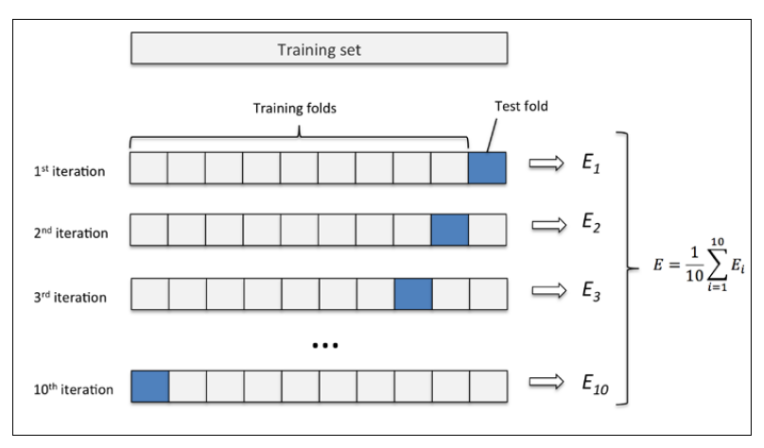
图2-3 十折交叉验证法,图片来源[13]
通过这种做法,能得出各模型的泛化结果,较好地评测各模型的真实效果。
第三章 开发技术介绍
此系统的关键技术和架构,Python技术、B/S结构、Django框架和Mysql数据库,是本系统的关键开发技术,对系统的整体、数据库、功能模块、系统页面以及系统程序等设计进行了详细的研究与规划。
3.1 系统开发平台
在该在线股票量化分析系统中,Eclipse能给用户提供更多的方便,其特点一是方便查询股票信息,方便快捷;二是有非常大的信息储存量,主要功能是用在对数据库中查询和编程。其功能有比较灵活的数据应用,只需利用小部分代码就能实现非常强大的功能。因此,利用Eclipse 技术进行系统代码管理是该系统数据库的首选。
3.2平台开发相关技术
3.2.1 Python技术
Python 是一个高层次的脚本语言结合了解释性、编译性、互动性和面向对象的。Python 的设计,相比其他语言经常使用英文关键字和其他语言的一些标点符号,它具有比其他语言更有特色语法结构,具有很强的可读性。
解释型语言:类似于PHP和Perl语言,这意味着开发过程中没有了编译这个环节。
交互式语言:可以在一个 Python 提示符 >>> 后直接执行代码。
面向对象语言:Python支持面向对象的风格或代码封装在对象的编程技术。
3.2.2 Mysql数据库介绍
利用Mysql的数据独立性、安全性等特点,在软件项目中对数据进行操作,可以保证数据准确无误,并降低了程序员的应用开发时间。
Mysql的特点是支持多线程,能方便的对系统资源充分利用,有效提高速度,还提供多种方式途径来对数据库进行连接;Mysql的功能相对弱小、规模也小,但本系统要求不高,Mysql完全可以满足本系统使用。
利用Mysql建立系统数据库,不仅有利于数据处理业务的早期整合,还能利于发展后两种数据扩展的操作。
3.2.3 Mysql环境配置
本系统的数据使用的是Mysql,所以要将Mysql安装到指定目录,如果下载的是非安装的Mysql压缩包,直接解压到指定目录就可以了。然后点击C:\Program Files\Mysql\bin\winMysqladmin.exe这个文件其中C:\Program Files\Mysql是Mysql安装目录。输入winMysqladmin的初始用户、密码(注:这不是Mysql里的用户、密码)随便填不必在意,确定之后右下角任务的启动栏会出现一个红绿灯的图标,红灯亮代表服务停止,绿灯亮代表服务正常,左击这个图标->winnt->install the service 安装此服务,再左击这个图标->winnt->start the service 启动Mysql服务。
修改Mysql数据库的root密码。用cmd进入命令行模式输入如下命令:
cd C:\Program Files\Mysql\bin
Mysqladmin -u root -p password 123
回车出现Enter password: ,这是要输入原密码. 刚安装时密码为空,所以直接回车,此时Mysql 中账号 root 的密码被改为 123 安装完毕。
3.2.4 B/S架构
B/S结构是目前使用最多的结构模式,它可以使得系统的开发更加的简单,好操作,而且还可以对其进行维护。使用该结构时只需要在计算机中安装数据库,和一些很常用的浏览器就可以了。浏览器就会与数据库进行信息的连接,可以实现很多的功能,B/S结构是可以直接进行使用的,而且B/S结构在使用中极大的减少了工作的维护。基于B/S的软件,所有的数据库之间都是相互独立的,因此是非常安全的。因为基于B/S结构可以清楚的看到系统正在处理的业务,并且能够及时的让管理人员做出决策,这样就可以避免学校的损失。B/S结构的基本特点是集中式的管理模式,用户使用系统生成数据后,这些数据就可以存储到系统的数据库中,方便日后能够用到,这样就可以满足人们的所有的需求。
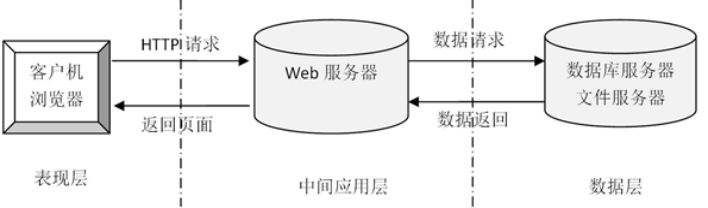
图2-1 B/S模式三层结构图
3.2.5 Django框架
Django是一种开源的大而且全的Web应用框架,是由python语言来编写的。他采用了MVC模式,Django最初是被开发来用于管理劳伦斯出版集团下的一些以新闻为主内容的网站。一款CMS(内容管理系统)软件。并于 2005 年 7 月在 BSD 许可证下发布。这套框架是以比利时的吉普赛爵士吉他手 Django Reinhardt 来命名的。
Django是Python语言中的一个web框架,并遵循MVC设计。Python语言中主流的web框架有Django、Tornado、Flask 等多种,Django相较与其它WEB框架,其优势为:大而全,框架本身集成了ORM、模型绑定、模板引擎、缓存、文件管理、认证权限Session等功能,是一个全能型框架,拥有自己的Admin数据管理后台,第三方工具齐全,性能折中。Django的主要目的是简便、快速的开发数据库驱动的网站。
)

![crew AI笔记[3] - 设计理念](http://pic.xiahunao.cn/crew AI笔记[3] - 设计理念)
)
)
](http://pic.xiahunao.cn/使用 Conda 安装 xinference[all](详细版))

:脱围机制一)


)








