
- 作者: Shuo Wang1,3^{1,3}1,3, Yongcai Wang1^{1}1, Wanting Li1^{1}1 , Xudong Cai1^{1}1, Yucheng Wang3^{3}3, Maiyue Chen3^{3}3, Kaihui Wang3^{3}3, Zhizhong Su3^{3}3, Deying Li1^{1}1, Zhaoxin Fan2^{2}2
- 单位:1^{1}1中国人民大学,2^{2}2北京微芯区块链与边缘计算研究院,3^{3}3地平线机器人
- 论文标题:Aux-Think: Exploring Reasoning Strategies for Data-Efficient Vision-Language Navigation
- 论文链接:https://arxiv.org/pdf/2505.11886
- 项目主页:https://horizonrobotics.github.io/robot_lab/aux-think/
- 代码链接:https://github.com/HorizonRobotics/robo_orchard_lab/tree/master/projects/aux_think
主要贡献
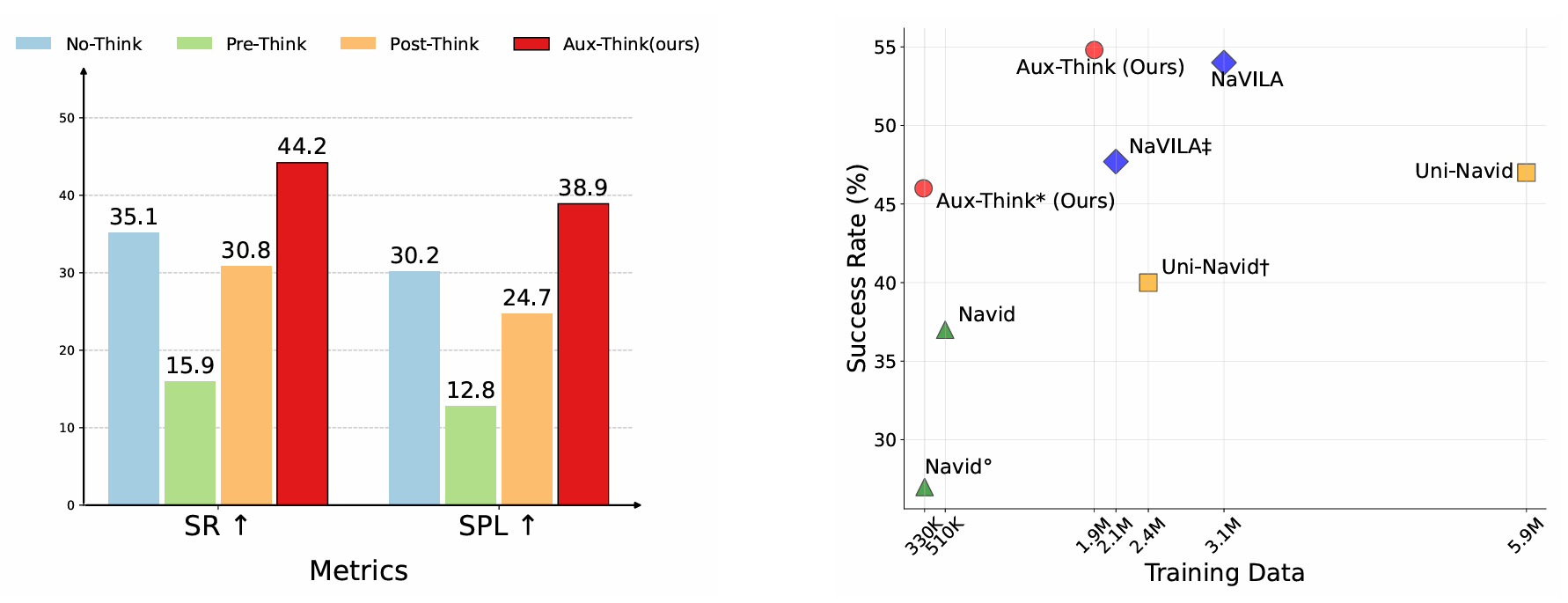
- 首次系统地比较了视觉语言导航(VLN)任务中不同推理策略的性能,揭示了推理时间推理崩塌(Inference-time Reasoning Collapse,IRC)问题,即在推理时引入显式推理会降低导航性能。
- 提出了Aux-Think框架,该框架在训练时使用思维链(Chain-of-Thought,CoT)作为辅助监督信号,而在推理时直接预测动作,避免了推理错误对导航性能的影响,实现了在数据效率和成功率之间的最佳权衡。
- 发布了R2R-CoT-320k数据集,这是首个针对VLN任务的思维链标注数据集,包含超过32万条多样化的推理轨迹,为研究推理在VLN中的作用提供了丰富资源。
研究背景
- 视觉语言导航(VLN)是让机器人能够理解自然语言指令并在复杂真实环境中导航的关键任务。近年来,基于大型预训练模型(LLMs)和视觉语言模型(VLMs)的研究取得了显著进展,提高了模型的泛化能力和指令对齐能力。
- 然而,推理策略在导航任务中的作用尚未得到充分研究,尽管思维链(CoT)在静态任务(如视觉问答)中取得了成功,但其在VLN中的应用仍面临挑战。
方法
问题设定
论文研究了连续环境中的单目视觉语言导航(VLN-CE),目标是让智能体根据自然语言指令在逼真的室内环境中导航。该任务强调对未见环境的泛化能力,并支持正向和反向导航,全面测试空间推理和语言理解能力。在每个时间步,智能体接收以下输入:
- 自然语言指令(通常是一段短文本,指定导航目标);
- 当前视角的RGB图像;
- 历史观测(从所有历史帧中均匀采样的8帧,始终包括第一帧)。
智能体需要选择一个动作(例如前进、左转/右转特定角度或停止),目标是生成尽可能准确和高效的动作序列,直到到达目标位置。
R2R-CoT-320k 数据集构建
论文发布了R2R-CoT-320k数据集,首个针对VLN任务的思维链(CoT)标注数据集。该数据集基于R2R-CE基准构建,使用Habitat模拟器重建导航轨迹。
- 每个样本包含当前视角、历史视觉上下文、对应指令和真实动作。使用Qwen-2.5-VL-72B模型为每个导航样本生成详细的CoT标注。
- CoT标注的格式为带有
<think>和<answer>标签的推理轨迹,以符合近期推理模型的标准。
系统性研究推理策略对VLN的影响
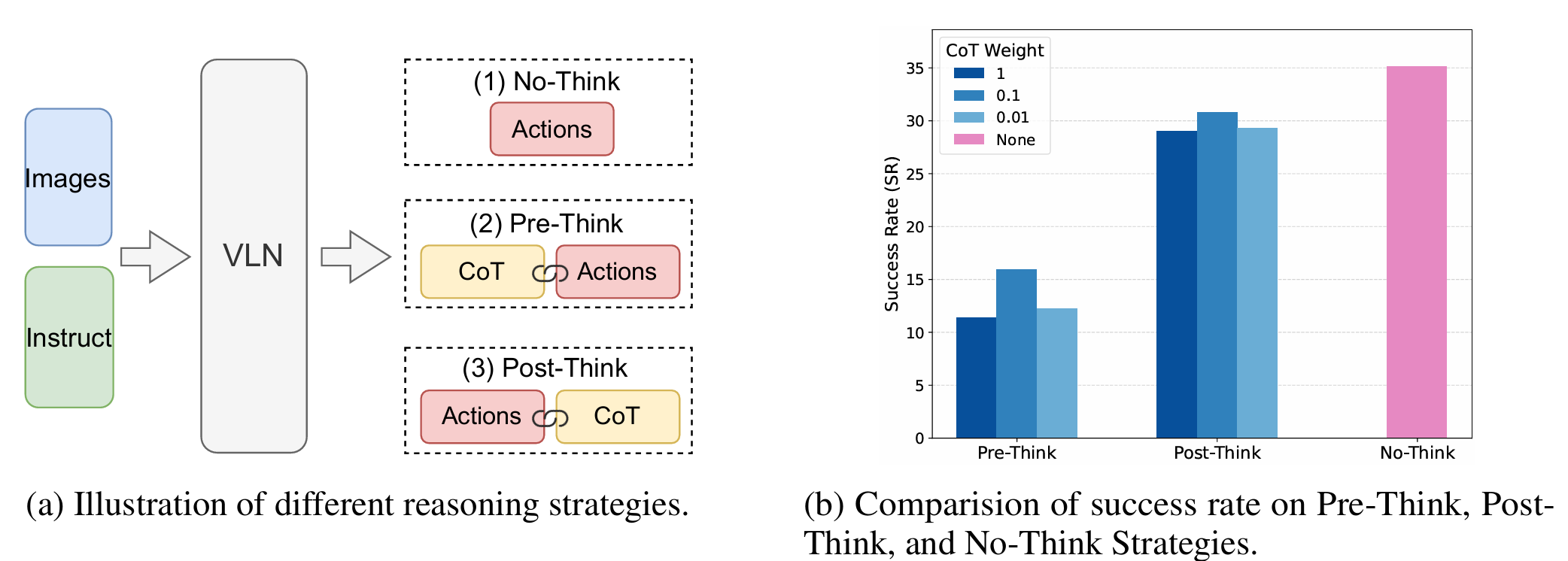
本文系统地研究了三种推理策略对VLN的影响:
- No-Think(无思考):智能体直接根据当前观测和指令预测下一个动作,不进行中间推理。
- Pre-Think(先思考):智能体首先根据指令和当前观测生成显式推理轨迹,然后基于推理结果预测动作。
- Post-Think(后思考):智能体首先预测动作,然后生成解释决策的推理轨迹。
通过实验发现,Pre-Think和Post-Think策略的表现显著低于No-Think策略,这表明在动态环境中,推理时间推理(CoT)是不可靠的。本文将这种现象称为“推理时间推理崩塌”(IRC)。此外,文章还发现,在训练时适度降低CoT部分的损失权重可以略微提升性能,这表明在训练时对推理的重视程度是一个关键因素。
Aux-Think:推理感知协同训练策略
为了解决CoT训练对VLN的挑战,提出了Aux-Think框架。该框架在训练时仅使用CoT作为辅助监督信号,而在推理时直接预测动作,避免了推理错误对导航性能的影响。具体来说,Aux-Think框架包括以下三个任务:
- 基于CoT的推理:训练模型根据指令、当前观测和历史观测生成CoT轨迹,以加强语言、视觉和动作之间的联系。
- 基于指令的推理:训练模型根据一系列视觉观测重构对应的指令,提供额外的语义监督。
- 递推水平动作规划:作为主要任务,模型根据指令、当前观测和导航历史预测接下来的n个动作,鼓励短期预测并保持对新观测的反应能力。
在训练过程中,通过改变提示(prompt)在不同任务之间切换。最终的损失函数是上述三个任务损失的总和。在推理时,仅激活动作预测部分,模型直接预测接下来的n个动作并执行第一个动作,确保快速、反应式的导航,避免推理开销。
实验结果
实验设置
- 在VLN-CE基准(R2R-CE和RxR-CE)上进行评估,遵循标准的VLN-CE设置。所有方法都在R2R的val-unseen分割和RxR的val-unseen分割上进行评估。
- 评估指标包括导航成功率(SR)、路径长度加权成功率(SPL)、导航误差等。
实现细节
- 使用NVILA-lite 8B作为基础预训练模型,该模型包括一个视觉编码器(SigLIP)、一个投影器和一个语言模型(Qwen 2)。
- 通过监督微调从NVILA-lite的第二阶段开始训练VLN模型,总共训练了一个epoch(约60小时),学习率为1e-5。
- 动作空间设计为四个类别:前进、左转、右转和停止,其中前进动作包括25cm、50cm和75cm的步长,转向动作的旋转角度为15°、30°和45°。
在VLN-CE基准上的比较
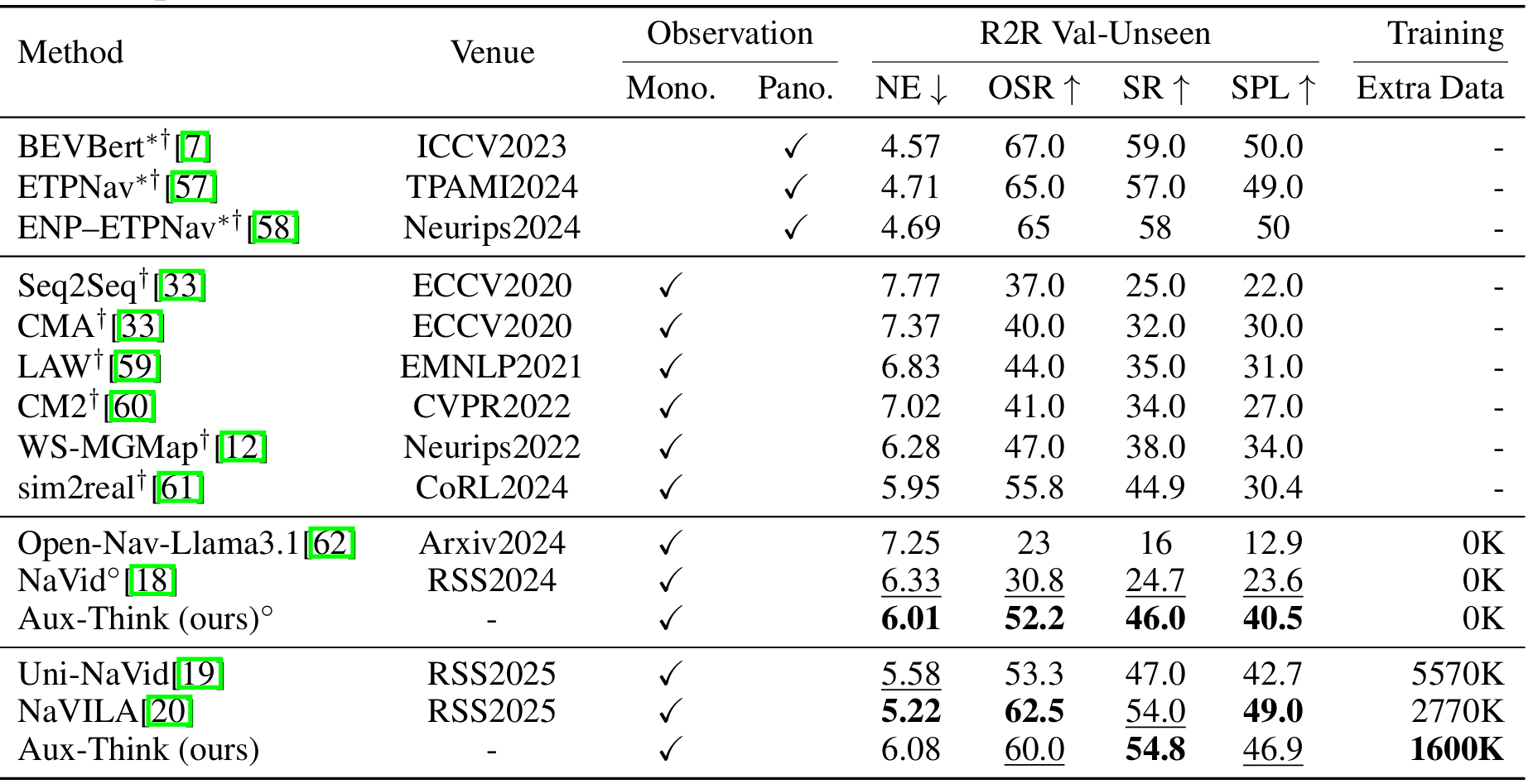
- 在R2R-CE数据集的val-unseen分割上,Aux-Think在不使用额外数据时取得了46.0%的成功率,在使用1600K额外数据时取得了54.8%的成功率,均优于其他基于大型模型的方法。
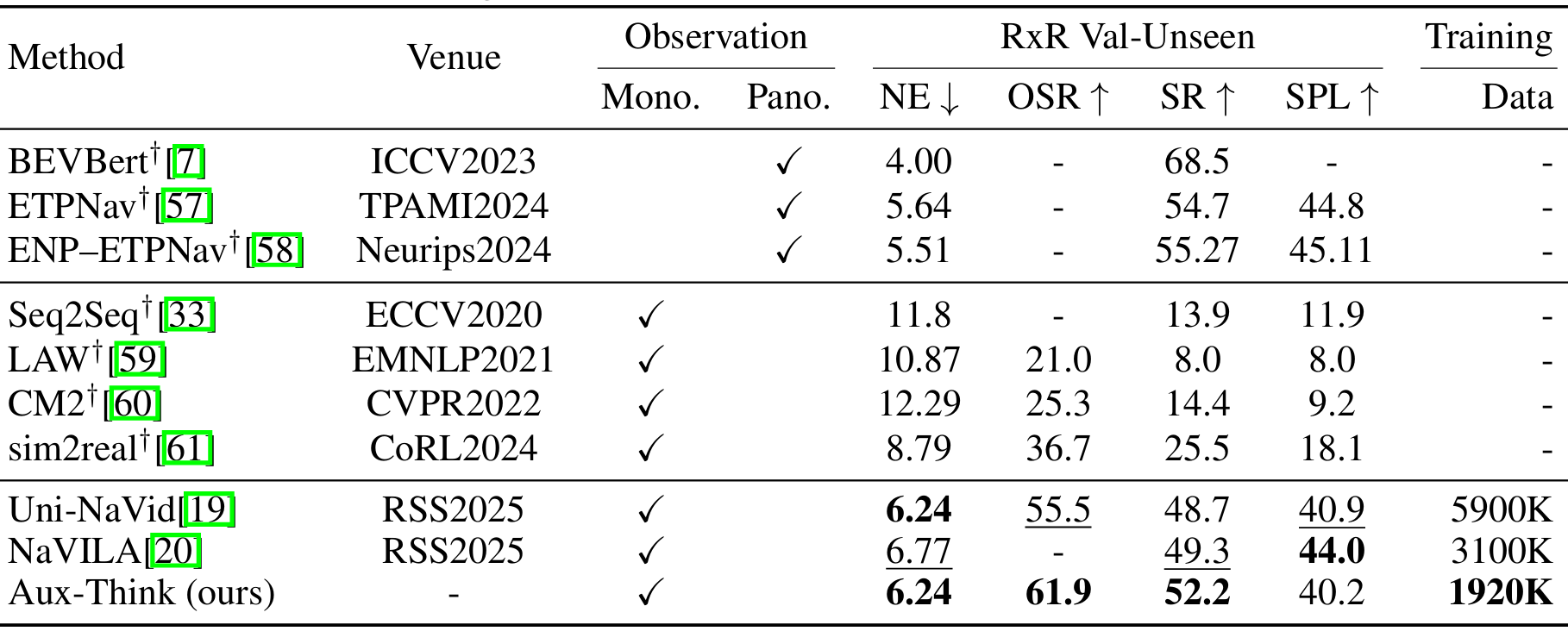
- 在RxR-CE数据集的val-unseen分割上,Aux-Think在成功率上超过了Uni-NaVid和NaVILA,同时使用的训练数据更少(1920K vs. 5900K和3100K)。
- 这些结果表明,Aux-Think在有限数据下通过多级推理监督信号实现了更好的泛化能力。
不同推理策略的比较
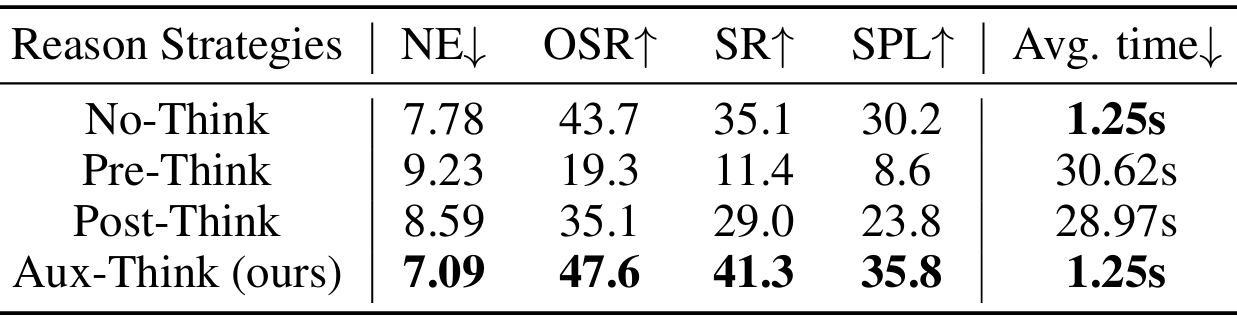
本文在R2R-CE数据集上比较了不同推理策略的性能。
- 结果表明,Pre-Think和Post-Think策略的成功率显著低于No-Think策略。
- Pre-Think策略由于动作预测依赖于生成的CoT,因此低质量或学习不佳的CoT会直接影响动作的准确性。
- Post-Think策略虽然在一定程度上缓解了这个问题,但次优的CoT表示仍然会降低整体性能。
- 相比之下,Aux-Think通过将CoT和动作学习解耦,并将CoT知识隐式地内化到特征中,从而避免了推理错误对导航性能的影响。
消融研究
不同辅助任务和递推水平动作规划的影响
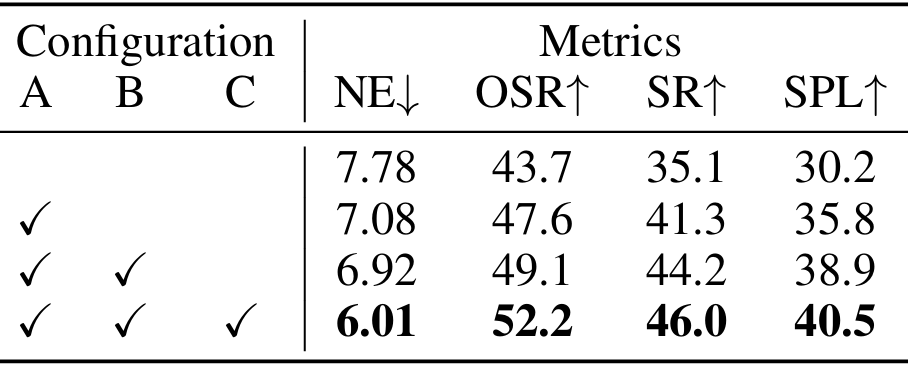
- 引入CoT推理可以显著提升模型性能。
- 进一步添加非CoT推理可以进一步增强性能。
- 完整的模型(包含递推水平动作规划)在SPL和SR等指标上取得了最佳结果,表明长期规划与隐式推理相结合可以产生最稳健的行为。
递推水平动作规划中步数的影响
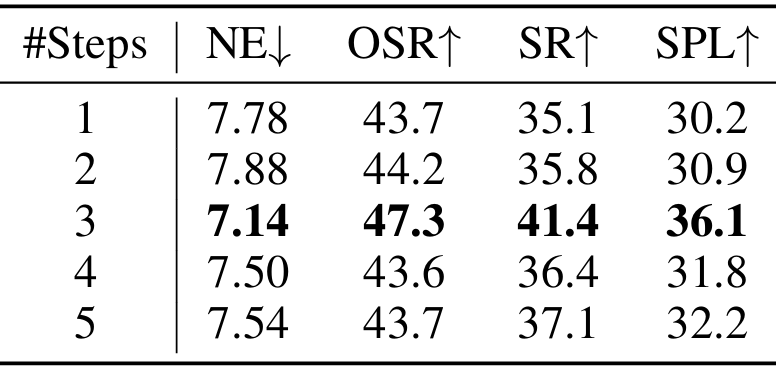
- 当预测步数为3时,模型取得了最佳性能。增加预测步数会导致性能下降,这可能是由于单目观测的感知范围有限,缺乏额外的全局知识,使得长水平预测更具挑战性,可能导致模型生成次优或坍塌的导航策略。
结论与未来工作
- 结论:
- 通过系统研究VLN中的推理策略,发现了推理时间推理崩塌问题,并提出了Aux-Think框架来解决这一问题。
- 该框架通过在训练时使用CoT作为辅助监督信号,在推理时直接预测动作,实现了在数据效率和导航性能之间的良好平衡。R2R-CoT-320k数据集的发布也为相关研究提供了重要资源。
- 未来工作:
- 目前的研究在受控的、广泛采用的设置下评估了Aux-Think的数据效率,未来可以扩展到更大的导航数据集,并引入更丰富的输入(如深度、全景、定位等)。
- 此外,本文尚未找到一种有效的方法通过强化学习同时提高CoT和动作质量,未来可以探索使用轻量级VLMs(如SmolVLM2)进行更可扩展的策略学习。













![[激光原理与应用-252]:理论 - 几何光学 - 传统透镜焦距固定,但近年出现的可变形透镜(如液态透镜、弹性膜透镜)可通过改变自身形状动态调整焦距。](http://pic.xiahunao.cn/[激光原理与应用-252]:理论 - 几何光学 - 传统透镜焦距固定,但近年出现的可变形透镜(如液态透镜、弹性膜透镜)可通过改变自身形状动态调整焦距。)


)



