第六章:信息检索器
在上一章中,我们成功完成了知识库摄入流程。这是巨大的进步~
我们精心准备了文档"块"(类似独立的索引卡),并将其存储在两套智能归档系统中:向量数据库(用于基于含义的搜索)和BM25索引(用于基于关键词的搜索)。我们的"数字图书馆"现已完美组织就绪,随时可被检索。
但当用户提出问题时会如何运作?例如,若用户询问:"公司Z在2023年关于营收和利润的关键财务结果是什么?"我们的系统可能有数千甚至数百万张索引卡。
它如何快速定位恰好包含答案的少数几张,而不被无关信息干扰?
这正是信息检索器的职责所在
信息检索器解决什么问题?
想象我们身处庞大的数字图书馆,需要快速查找特定信息。我们不想逐本阅读每本书籍,而是需要"超级管理员"或"搜索引擎"能立即指向最相关的页面或段落。
挑战在于:
- 理解问题:即使表述宽泛
- 扫描整个知识库:遍历所有存储块
- 寻找最佳匹配:识别最可能包含答案的块
- 快速响应:在秒级而非分钟级提供结果
信息检索器组件即扮演这种"超级管理员"或"搜索引擎"角色。
当问题输入时,它会查询我们已建立的知识库(向量和BM25),寻找可能包含答案的最相关文档块。该组件专为从海量数据中快速高效提取潜在答案而设计。
其核心角色可分解如下:
| 角色 | 类比 | 功能说明 |
|---|---|---|
| 超级管理员 | 快速定位正确书籍/页面 | 接收问题并搜索"基于含义"(向量)和"基于关键词"(BM25)的索引,寻找相关文档块 |
| 相关性评估器 | 判断哪些信息最有帮助 | 使用高级算法(如向量搜索的余弦相似度、关键词搜索的BM25评分)确定每个找到的块与原始问题的相关度 |
| 数据提取器 | 提取潜在答案 | 检索最相关块的实际文本,附带页码等辅助细节,供后续处理使用 |
如何使用信息检索器
流水线协调器控制整体流程,但在回答问题时主要依赖信息检索器。开发者不会直接从命令行调用InformationRetriever,它由更大的"问答流程"内部调用
不过我们可以观察其不同部分的编程用法。本项目提供三种主要检索器:
BM25Retriever:基于关键词搜索VectorRetriever:基于语义(含义)搜索HybridRetriever:混合检索,通常包含进阶重排序步骤
以下示例展示如何查找特定公司报告的财务信息。假设需要查找"公司A在2023年的营收增长数据":
首先确保数据库和原始文档路径已配置(main.py中由流水线协调器管理路径):
from pathlib import Path
from src.retrieval import BM25Retriever, VectorRetriever, HybridRetriever# 知识库存储路径(第五章创建)
vector_db_path = Path("data/vector_db")
bm25_db_path = Path("data/bm25_db")
documents_path = Path("data/debug/chunked_reports") # 预处理后的块# 目标公司
target_company = "ACME Corp"
# 用户问题
user_query = "ACME Corp在2023年的营收和利润是多少?"
说明:配置知识库(vector_db和bm25_db)及处理文档(chunked_reports)路径,定义目标公司和查询内容。
1. 使用BM25Retriever(关键词搜索)
该检索器擅长查找精确词汇或短语:
# 创建BM25检索器实例
bm25_retriever = BM25Retriever(bm25_db_dir=bm25_db_path, documents_dir=documents_path
)print(f"\n--- {target_company}的BM25检索结果 ---")
# 获取前3个相关块
bm25_results = bm25_retriever.retrieve_by_company_name(company_name=target_company, query=user_query, top_n=3
)for i, res in enumerate(bm25_results):print(f"结果{i+1}(第{res['page']}页): 相关性={res['distance']:.2f}")print(f"文本: {res['text'][:100]}...") # 显示前100字符
预期输出(简化):
--- ACME Corp的BM25检索结果 ---
结果1(第5页): 相关性=0.75
文本: ...2023年营收增长15%达5亿美元,净利润5000万美元...
结果2(第7页): 相关性=0.68
文本: ...财务表现亮点:2023年营收趋势与盈利能力...
结果3(第12页): 相关性=0.55
文本: ...2023财年及未来展望相关信息...
解析:创建BM25Retriever实例,指向BM25索引和文档块。
调用retrieve_by_company_name方法,传入公司名、查询内容和返回数量。该方法高效扫描BM25索引,返回关键词匹配度最高的块。
2. 使用VectorRetriever(语义搜索)
该检索器通过嵌入向量查找语义相似的块,即使不含相同词汇:
# 创建向量检索器实例
vector_retriever = VectorRetriever(vector_db_dir=vector_db_path, documents_dir=documents_path
)print(f"\n--- {target_company}的向量检索结果 ---")
# 获取前3个语义相关块
vector_results = vector_retriever.retrieve_by_company_name(company_name=target_company, query=user_query, top_n=3
)for i, res in enumerate(vector_results):print(f"结果{i+1}(第{res['page']}页): 向量距离={res['distance']:.2f}")print(f"文本: {res['text'][:100]}...")
预期输出(简化):
--- ACME Corp的向量检索结果 ---
结果1(第5页): 向量距离=0.92
文本: ...去年达成重要财务里程碑,关键指标...
结果2(第7页): 向量距离=0.88
文本: ...截至2023年12月31日的财年收益摘要...
结果3(第10页): 向量距离=0.80
文本: ...年报亮点:经济表现与战略举措...
解析:创建VectorRetriever实例后,调用方法时会将用户查询转换为嵌入向量(使用LLM),在目标公司的FAISS向量库中查找数值"最接近"的块。
3. 使用HybridRetriever(混合重排序)
HybridRetriever结合两者优势,通常使用向量搜索初步检索,再通过LLM重排序提升精度:
# 创建混合检索器实例
hybrid_retriever = HybridRetriever(vector_db_dir=vector_db_path, documents_dir=documents_path
)print(f"\n--- {target_company}的混合检索结果 ---")
# 获取重排序后的前3结果
hybrid_results = hybrid_retriever.retrieve_by_company_name(company_name=target_company, query=user_query, top_n=3,llm_reranking_sample_size=10 # 获取10个初选结果再重排序
)for i, res in enumerate(hybrid_results):print(f"结果{i+1}(第{res['page']}页): 重排序得分={res['score']:.2f}")print(f"文本: {res['text'][:100]}...")
预期输出(简化):
--- ACME Corp的混合检索结果 ---
结果1(第5页): 重排序得分=0.98
文本: ...2023年营收增长15%达5亿美元,净利润5000万美元...
结果2(第7页): 重排序得分=0.95
文本: ...截至2023年12月31日的财年收益摘要...
结果3(第1页): 重排序得分=0.90
文本: ...2023财年表现概览与未来展望...
解析:HybridRetriever先用向量检索获取较多候选块(llm_reranking_sample_size控制数量),再通过LLMReranker(将在第七章详述)使用LLM评估相关性得分
最终返回精排结果。这种方法通常准确率最高。
底层原理:信息检索器工作机制
信息检索器通过协调src/retrieval.py中的组件实现其功能,本质上是专业化的搜索代理。
信息检索流程:
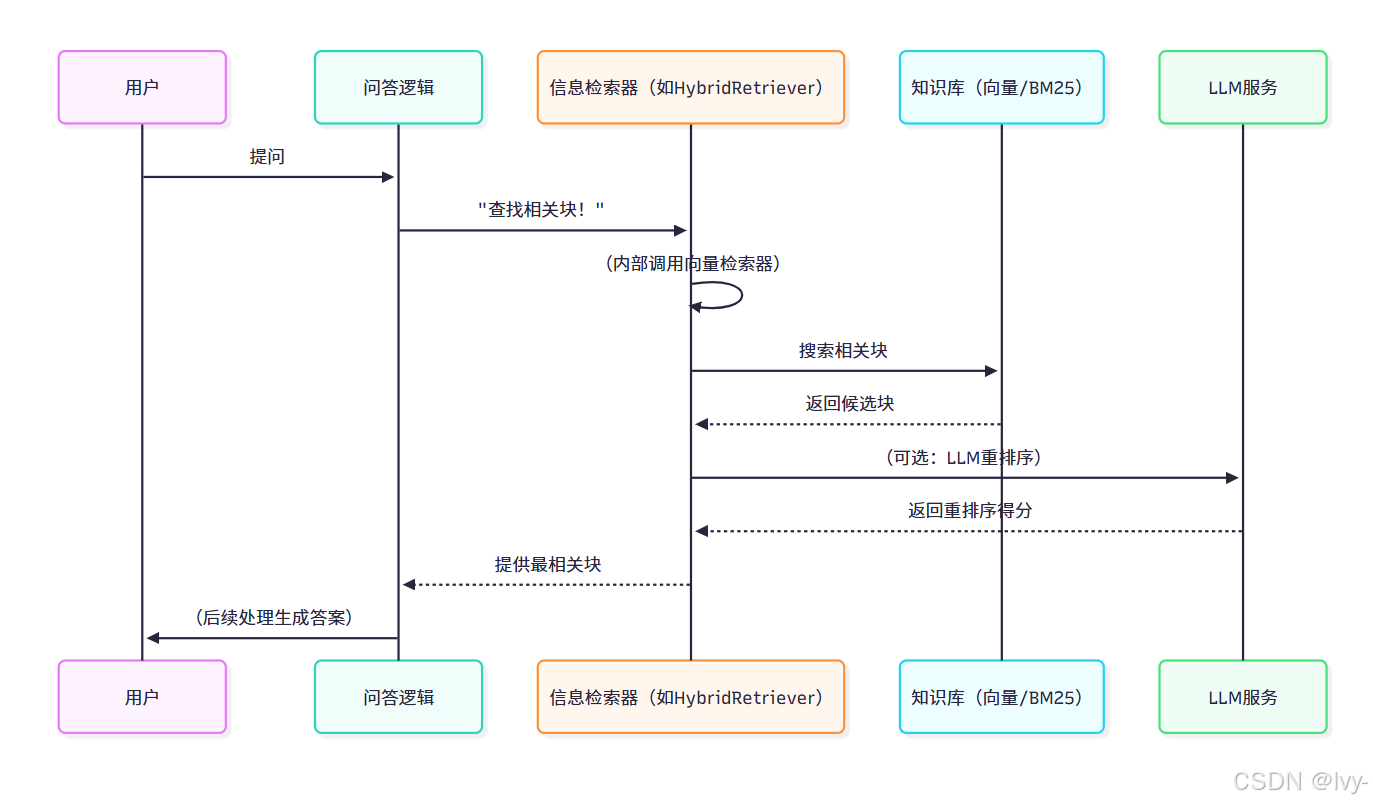
1. BM25Retriever 实现解析
该类处理基于关键词的检索:
# 来源:src/retrieval.py(简化版)
import pickle
from pathlib import Path
from rank_bm25 import BM25Okapi class BM25Retriever:def __init__(self, bm25_db_dir: Path, documents_dir: Path):self.bm25_db_dir = bm25_db_dir # BM25索引存储路径self.documents_dir = documents_dir # 文档块路径def retrieve_by_company_name(self, company_name: str, query: str, top_n: int = 3) -> list:# 查找目标公司文档document_path = next((p for p in self.documents_dir.glob("*.json") if company_name in str(p)), None)if not document_path: return []# 加载BM25索引bm25_path = self.bm25_db_dir / f"{document_path.stem}.pkl"with open(bm25_path, 'rb') as f:bm25_index = pickle.load(f)# 加载文档块with open(document_path, 'r', encoding='utf-8') as f:document = json.load(f)chunks = document["content"]["chunks"]# 分词查询并计算相关性tokenized_query = query.split()scores = bm25_index.get_scores(tokenized_query)# 取top_n结果top_indices = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)[:top_n]return [{"distance": round(scores[i],4),"page": chunks[i]["page"],"text": chunks[i]["text"]} for i in top_indices]
实现了一个基于BM25算法的文档检索工具,专门用于根据公司名称和查询词检索相关文档片段。
核心类说明
BM25Retriever类包含两个关键参数:
bm25_db_dir:存储预先构建好的BM25检索索引的目录documents_dir:存放原始文档数据的目录
检索流程
检索方法retrieve_by_company_name执行以下操作:
- 通过公司名称定位对应文档文件(查找.json文件)
- 加载该文档对应的BM25预训练索引(.pkl文件)
读取原始文档的分块内容(chunks字段)- 对查询语句进行
简单分词处理 - 计算查询词与所有文档块的相关性得分
- 返回得分最高的
top_n个结果,包含:- 相关性分数(保留4位小数)
- 所在页码
- 文本内容
特点:
- 采用BM25算法进行相关性排序(经典信息检索算法)
- 使用
pickle格式存储预计算索引 - 结果按相关性降序排列
- 默认返回最相关的3个结果片段
应用场景:
适用于企业文档管理系统,比如根据公司名称快速查找年报/财报中与特定查询词相关的内容片段。
流程:定位目标公司文档→加载对应BM25索引→分词查询→计算相关性得分→返回前N结果。
🎢Pickle格式
是Python特有的数据序列化方式,能将任何对象(如列表、字典、类实例等)转换为二进制数据保存或传输,使用时再还原回原对象。类似“打包”和“拆包”的过程。
同二进制的protobuf传送:ProtoBuf专栏
2. VectorRetriever 实现解析
该类处理基于语义的检索:
# 来源:src/retrieval.py(简化版)
import faiss
from openai import OpenAI
import numpy as npclass VectorRetriever:def __init__(self, vector_db_dir: Path, documents_dir: Path):self.vector_db_dir = vector_db_dirself.documents_dir = documents_dirself.llm = OpenAI(api_key=os.getenv("OPENAI_API_KEY")) # 嵌入模型连接def retrieve_by_company_name(self, company_name: str, query: str, top_n: int = 3) -> list:# 加载目标公司向量库target_report = next((r for r in self._load_dbs() if company_name in r["name"]), None)if not target_report: return []# 生成查询嵌入query_embedding = self.llm.embeddings.create(input=query, model="text-embedding-3-large").data[0].embeddingquery_embedding = np.array(query_embedding, dtype=np.float32).reshape(1, -1)# FAISS向量搜索distances, indices = target_report["vector_db"].search(query_embedding, top_n)return [{"distance": round(distances[0][i],4),"page": target_report["document"]["content"]["chunks"][indices[0][i]]["page"],"text": target_report["document"]["content"]["chunks"][indices[0][i]]["text"]} for i in range(top_n)]
实现了一个基于向量检索的文档查询系统,专门针对公司报告进行语义搜索。
核心逻辑分解
初始化阶段
VectorRetriever类初始化时设置两个路径:向量数据库目录和文档目录
同时创建OpenAI嵌入模型连接用于文本向量化。
检索流程
- 通过公司名称定位目标报告库,在预加载的数据库列表中匹配包含指定公司名的报告
- 将用户查询文本通过OpenAI的
text-embedding-3-large模型转换为1536维向量 - 使用FAISS库在目标公司的向量数据库中进行最近
邻搜索,找出与查询最相似的top_n个文本片段
1536维向量
是由1536个数字组成的有序列表,用于在高维空间中精确表示数据(如文本、图像等),每个数字对应一个特征维度。
返回结果
结构化返回包含三个字段的列表:
- 匹配度分数(
欧式距离) - 原文所在页码
- 匹配的文本内容
欧式距离就是日常生活中两点之间的直线距离,比如地图上两个地点的最短路径长度。
技术特点
- 采用稠密向量检索(Dense Retrieval)替代传统关键词匹配
- 向量维度适配text-embedding-3-large模型的1536维输出
- 距离计算使用FAISS优化的L2距离(欧式距离)
应用场景
当用户需要查询某公司报告中与特定问题相关的内容时(如"苹果公司的碳排放政策"),系统会返回报告中最相关的文本段落及其位置信息。
流程:加载向量库→转换查询为嵌入向量→执行FAISS相似性搜索→返回最邻近结果。
3. HybridRetriever 实现解析
该类结合向量检索与LLM重排序:
# 来源:src/retrieval.py(简化版)
from src.reranking import LLMReranker class HybridRetriever:def __init__(self, vector_db_dir: Path, documents_dir: Path):self.vector_retriever = VectorRetriever(vector_db_dir, documents_dir)self.reranker = LLMReranker() # 第七章详解def retrieve_by_company_name(self, company_name: str, query: str, top_n: int = 6) -> list:# 初步获取更多候选结果vector_results = self.vector_retriever.retrieve_by_company_name(company_name, query, top_n=28)# LLM精细重排序reranked_results = self.reranker.rerank_documents(query, vector_results)return reranked_results[:top_n]
实现了一个混合检索系统,结合向量检索和LLM(大语言模型)重排序技术,用于根据公司名称和查询文本获取最相关的文档。
核心组件
HybridRetriever类包含两个主要组件:
vector_retriever:基于向量的文档检索器,负责初步筛选相关文档reranker:LLM重排序器,对初步结果进行精细化排序
工作流程
初始化时指定向量数据库目录和文档目录,创建向量检索器和LLM重排序器实例
retrieve_by_company_name方法执行以下操作:
- 使用向量检索器获取28个初步候选结果(参数
top_n=28) - 调用LLM重排序器对这些结果进行精细化重新排序
- 返回最终前6个(默认值)最相关的结果
参数说明
company_name:目标公司名称query:用户查询文本top_n:最终返回的结果数量(默认6个)
技术特点
该方法采用了两阶段检索策略:
- 宽泛召回:先获取较多候选结果(28个)
- 精准排序:用LLM对结果进行质量重排
这种设计平衡了召回率和精确度。
流程:向量检索扩大候选池→LLM评估每个块与问题的深层关联→返回精排结果。
结论
信息检索器是RAG系统的核心搜索引擎,通过结合关键词匹配(BM25)和语义理解(向量)两种检索方式,高效定位知识库中的相关文档块。
特别是采用HybridRetriever进行智能重排序后,系统能确保提取最精准的信息来解答用户问题。该组件在用户问题与文档潜在答案之间架起了关键桥梁。
在掌握如何查找相关信息后,下一步是确保获取最优信息并按相关性精确排序。
有时初步检索会返回多个候选结果,我们需要更智能的方式来排序。
下一章:LLM重排序





 ✨ | AutoTextEffect(自动打字机))
![[RAG] LLM 交互层 | 适配器模式 | 文档解析器(`docling`库, CNN, OCR, OpenCV)](http://pic.xiahunao.cn/[RAG] LLM 交互层 | 适配器模式 | 文档解析器(`docling`库, CNN, OCR, OpenCV))




:多叉树)
中的节能控制(一))





![[Mysql] Connector / C++ 使用](http://pic.xiahunao.cn/[Mysql] Connector / C++ 使用)
