第二章:LLM 交互层
在上一章中,我们学习了作为"项目总控"的管道协调器,它负责协调 RAG 系统中各个功能模块。
其中最重要的协调对象之一,便是负责与大型语言模型(LLM)进行智能交互的LLM 交互层!
LLM 交互层解决的核心问题
假设我们有一个需要调用多模态 AI “大脑” 来解答复杂问题的智能助手系统,将面临以下挑战:
多供应商支持:可能需要使用 OpenAI 的 GPT-4o、Google 的 Gemini 或 IBM 的 WatsonX 等不同厂商的模型差异化接口规范:不同 LLM 服务提供商具有各异的 API 格式要求密钥管理复杂性:每个服务需要独立的 API 密钥认证体系流量控制需求:需处理不同服务的速率限制(Rate Limiting)策略响应格式多样性:各厂商 API 返回的数据结构存在差异
若在主系统中直接处理这些差异,将导致代码臃肿和维护困难。这正是LLM 交互层要解决的核心架构问题。
LLM集成&处理,前文传送:
[AI-video] 数据模型与架构 | LLM集成
[BrowserOS] LLM供应商集成 | 更新系统 | Sparkle框架 | 自动化构建系统 | Generate Ninja
LLM 交互层:智能模型的万能翻译官与外交官
LLM 交互层如同连接 RAG 系统与各大 AI 模型的协议转换中枢,其核心价值在于:
| 功能角色 | 类比 | 技术实现 |
|---|---|---|
| 多协议转换器 | 语言翻译官 | 将统一输入转换为 OpenAI/Gemini/WatsonX 等各厂商 API 要求的格式 |
| 密钥外交官 | 安全通行证管理 | 通过环境变量隔离存储 API 密钥,动态注入认证信息 |
| 流量调度器 | 高速公路收费站 | 内置速率限制感知与自适应重试机制,防止触发 API 调用限制 |
| 数据整形师 | 格式标准化专家 | 将异构 API 响应转换为统一数据结构,支持 JSON 等结构化输出 |
如何使用 LLM 交互层
在RAG-Challenge-2项目中,通过APIProcessor类实现与各类 LLM 的交互。以下展示两种典型使用场景:
场景一:基础问答交互
from src.api_requests import APIProcessor# 初始化 OpenAI 处理器
llm_connector = APIProcessor("openai")# 执行问答交互
response = llm_connector.send_message(human_content="法国的首都是哪里?",system_content="你是一个知识丰富的助手"
)print(response) # 预期输出:"法国首都是巴黎"(或类似表述)
执行流程解析:
- 实例化
APIProcessor并指定服务商(“openai”) - 通过
send_message发送用户问题(human_content)与角色定义(system_content) - 交互层自动处理协议转换、密钥注入等底层细节
- 返回标准化响应内容
场景二:结构化数据获取
from src.api_requests import APIProcessor
from pydantic import BaseModel# 定义预期数据结构
class CapitalAnswer(BaseModel):city: str # 城市字段country: str # 国家字段# 初始化处理器
llm_connector = APIProcessor("openai")# 请求结构化响应
response_dict = llm_connector.send_message(human_content="法国的首都是哪里?",system_content="请以JSON格式返回首都信息",is_structured=True, # 启用结构化模式response_format=CapitalAnswer # 绑定数据模型
)print(response_dict) # 预期输出:{'city': '巴黎', 'country': '法国'}
关键技术亮点:
- 采用
pydantic.BaseModel定义数据契约 is_structured标志位触发JSON响应解析- 自动校验响应结构与数据模型的一致性
底层架构
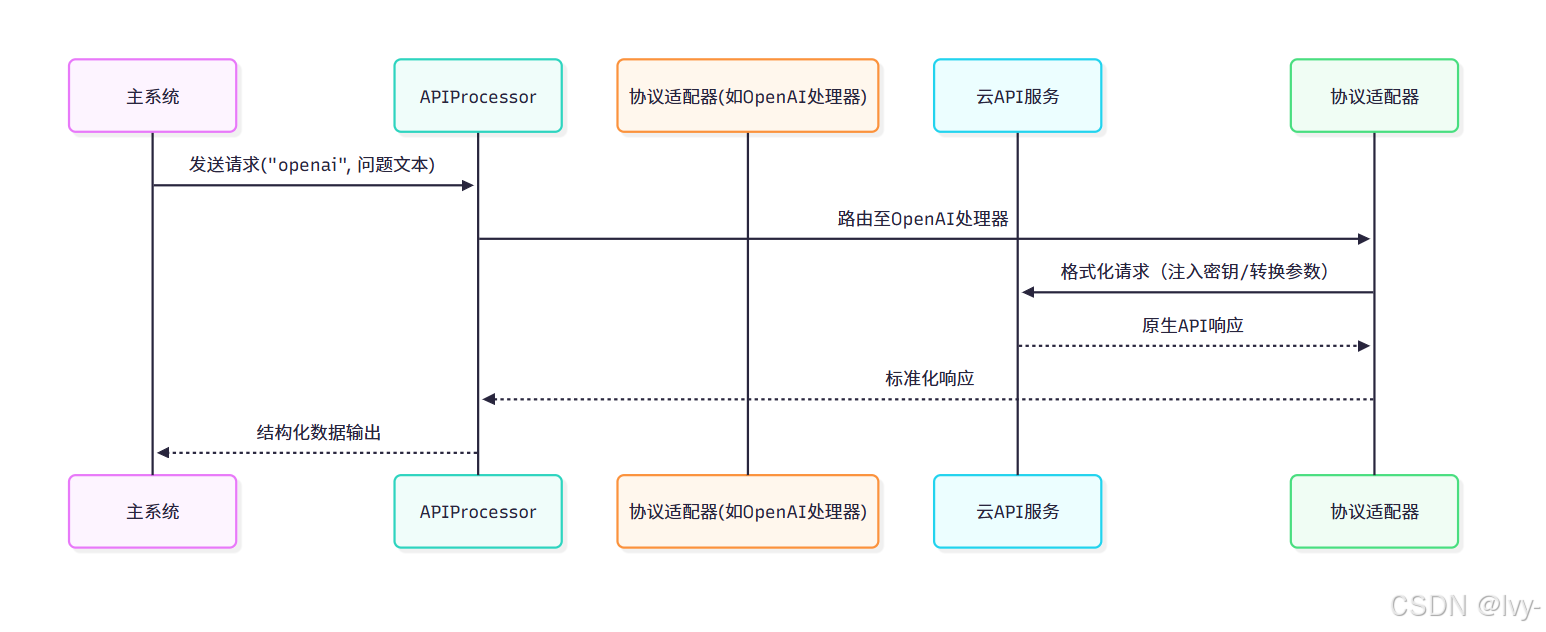
⭕适配器模式
APIProcessor类(位于src/api_requests.py)是交互层的核心实现,其设计采用"适配器模式"来兼容多厂商API。
前文传送:
10.STL中stack和queue的基本使用(附习题)

适配器模式就像电源转接头,让不兼容的接口能一起工作。如何实现的呢?再套一层😋
协议适配器工作流
核心组件实现
- 多厂商适配器基类
# 来源:src/api_requests.py(简化版)
import os
from dotenv import load_dotenv
from openai import OpenAIclass APIProcessor:"""统一交互入口"""def __init__(self, provider="openai"):self.provider = provider.lower()self.processor = self._init_processor() # 动态加载适配器def _init_processor(self):if self.provider == "openai":return BaseOpenaiProcessor()elif self.provider == "ibm":return BaseIBMAPIProcessor()# 支持其他厂商扩展...def send_message(self, **kwargs):"""消息转发入口"""return self.processor.send_message(**kwargs)class BaseOpenaiProcessor:"""OpenAI协议适配器"""def __init__(self):load_dotenv() # 加载环境变量self.llm = OpenAI(api_key=os.getenv("OPENAI_API_KEY")) # 密钥注入self.default_model = 'gpt-4o-mini-2024-07-18' # 默认模型版本def send_message(self, model=None, **kwargs):"""OpenAI专用请求封装"""params = {"model": model or self.default_model,"messages": [{"role": "system", "content": kwargs.get("system_content")},{"role": "user","content": kwargs.get("human_content")}]}# 执行API调用completion = self.llm.chat.completions.create(**params)return completion.choices[0].message.content # 响应解析
实现了一个支持多AI厂商API调用的适配器系统,核心是通过
统一接口屏蔽不同厂商API的差异。
核心组件
APIProcessor类(主入口)
- 初始化时通过
provider参数指定厂商(如openai/ibm) - 自动创建对应的厂商适配器实例(如
BaseOpenaiProcessor) - 提供统一的
send_message方法转发请求
BaseOpenaiProcessor类(厂商实现)
- 专属OpenAI的初始化流程:
- 加载环境变量获取API密钥
- 预置默认模型版本
- 请求处理逻辑:
- 组装符合OpenAI规范的请求结构
- 包含system/user角色的消息体
- 自动选择默认模型(可覆盖)
- 解析返回结果的第一条消息
设计特点
- 开闭原则:新增厂商只需添加新适配器类,无需修改主入口代码
- 环境隔离:各厂商的密钥管理和请求逻辑相互独立
- 默认配置:
内置常用模型版本降低调用复杂度
⭕调用示例
processor = APIProcessor("openai")
response = processor.send_message(system_content="你是一个翻译助手",human_content="Hello world"
)
- 高级功能实现
- 密钥安全管理:通过
.env文件隔离敏感信息,防止密钥硬编码 - 流量控制:集成
api_request_parallel_processor模块实现:- 自动重试机制(网络波动容错)
- 动态速率调节(基于API反馈实时调整QPS)
- 批量请求优化(提升吞吐量)
- 结构化校验:利用
pydantic模型实现响应数据的模式校验与自动修复
总结
LLM交互层作为RAG系统的"外交中枢",通过:
- 协议抽象:统一不同厂商API的调用差异
- 安全隔离:集中管理敏感认证信息
- 弹性通信:内置智能重试与流量整形
- 数据契约:强化结构化数据可靠性
(我们会发现,如果抽象的好的话,许多想实现的小功能,都有对应的库或者方案可以直接像适配器一样调用,我们只需要 改一些参数即可)
使上层业务逻辑能够专注于知识处理流程,而不必深陷多厂商API的兼容性泥潭。
这种分层设计显著提升了系统的可维护性与可扩展性。
下一章:文档解析器
第三章:文档解析器
在上一章中,我们了解了LLM交互层——与强大AI模型对话的通用翻译器。
但在系统能够提出智能问题并获得答案之前,它需要理解源文档中的信息。想象我们拥有一个装满珍贵书籍(PDF)的大型图书馆,但它们都是原始的纸质文档!我们无法搜索、用计算机轻松阅读或提取具体数据。
这正是文档解析器大显身手的时刻。
向量检索重要性在前文有提到:
[Andrej Karpathy] 大型语言模型作为新型操作系统
文档解析器解决的核心问题
假设我们有一批来自不同公司的PDF报告,这些报告包含丰富的信息:常规文本、详细表格和说明性图片。要构建能够回答"根据财务报告,X公司2023年的营收是多少?"这类问题的智能系统,首先需要读取并理解这些PDF文档。
PDF文档存在天然复杂性:
- 格式混杂性:混合文本、图像和表格的复杂排版
- 结构模糊性:简单复制粘贴可能导致结构丢失或表格错位
- 数据非标性:显示优化的布局不利于机器解析
文档解析器的核心使命是:
- 全要素提取:完整获取文本、表格和图像
- 语义结构理解:识别段落归属、表格边界和图片关联
- 数字格式重构:将异构数据转换为系统可处理的标准化格式
⭕文档解析器:智能数字档案员
文档解析器如同精通多模态的档案管理员。
当输入原始PDF时,它不仅拍摄页面快照,而是深度解析每个元素:
| 功能角色 | 技术实现 |
|---|---|
| 智能扫描仪 | 采用docling库实现PDF深度解析,支持OCR光学字符识别 |
| 数据萃取器 | 将复杂表格转换为Markdown结构化数据,保留表格行列关系 |
| 内容整合器 | 按页面组织文本块,识别标题层级,建立跨页面引用关系 |
| 数字归档系统 | 输出标准化JSON格式,支持后续向量化处理 |
之后会在py相关专栏,探索这个库(🕳+1)
如何使用文档解析器
通过管道协调器触发文档解析流程:
python main.py parse-pdfs
核心代码逻辑如下:
# 来源:src/pipeline.py(简化版)
from src.pdf_parsing import PDFParserclass Pipeline:def parse_pdf_reports(self):"""PDF解析总控方法"""pdf_dir = self.paths.raw_reports_path # 原始PDF存储路径output_dir = self.paths.parsed_reports_path # 解析结果输出路径parser = PDFParser(output_dir=output_dir,csv_metadata_path=self.paths.subset_path # 可选元数据关联)parser.parse_and_export(doc_dir=pdf_dir) # 启动解析流程
执行流程解析:
- 路径初始化:通过
_initialize_paths方法建立输入/输出目录结构 - 解析器配置:加载
docling文档转换器,启用表格检测和OCR功能([11]) - 批量处理:遍历指定目录下的所有PDF文件进行异步解析([18])
- 结果序列化:将结构化数据保存为JSON文件,保留原始文档SHA1哈希作为文件名
输出示例(data/debug/parsed_reports/xxx.json):
{"metainfo": {"sha1_name": "f5d2...a89c","pages_amount": 42,"company_name": "TechCorp"},"content": [{"page": 1,"blocks": [{"type": "heading", "text": "2023年度财务报告"},{"type": "paragraph", "text": "本年度总收入..."}]}],"tables": [{"table_id": 0,"markdown": "| 季度 | 营收(百万) |\n|------|-------------|\n| Q1 | 120 |","page": 5}]
}
底层架构
文档解析器采用分层处理架构:
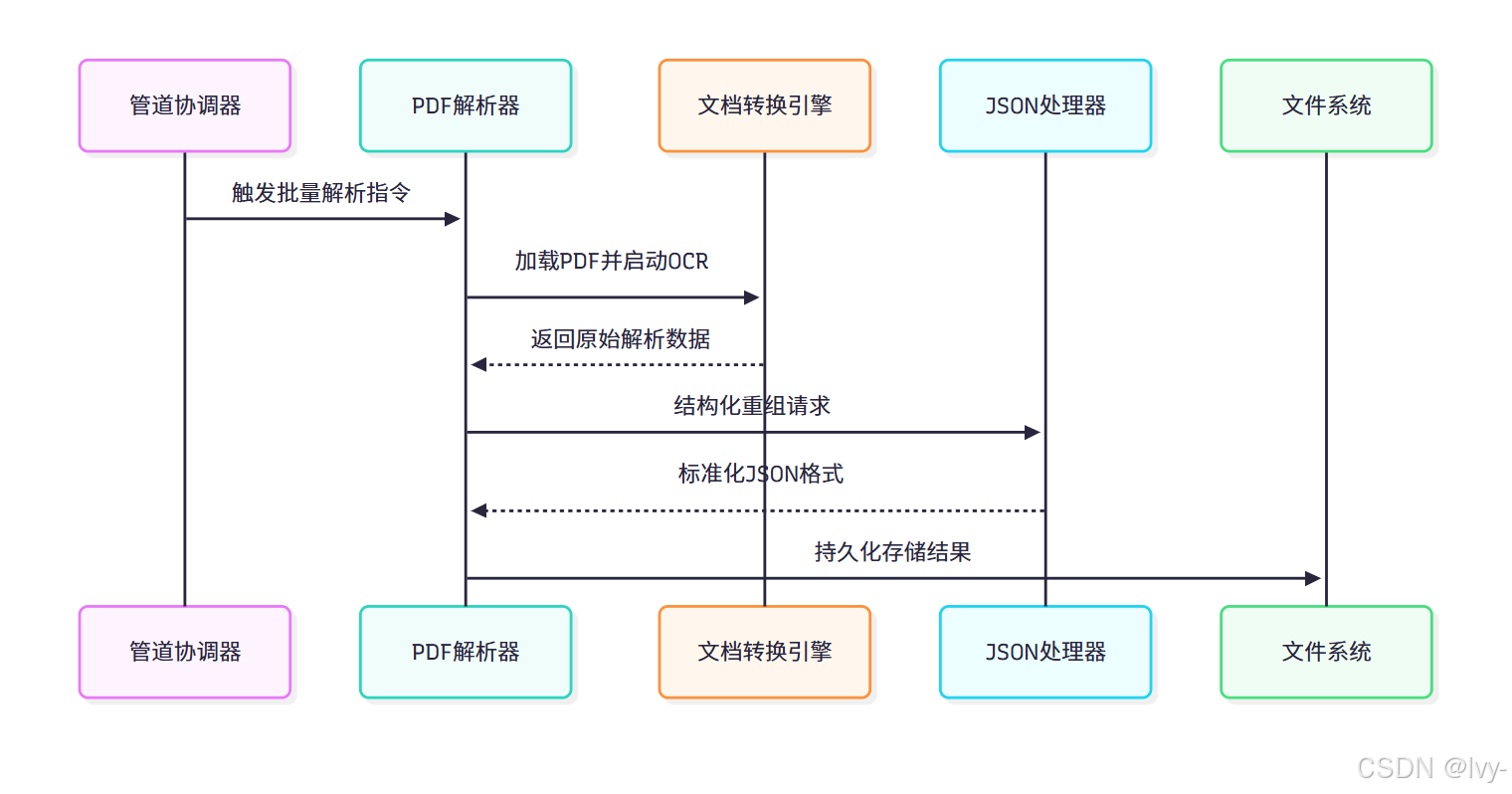
核心组件详解:
1. PDFParser 类
class PDFParser:def __init__(self, output_dir: Path, csv_metadata_path: Path = None):self.doc_converter = self._create_document_converter() # 初始化转换引擎self.metadata_lookup = self._parse_csv_metadata(csv_metadata_path) # 加载元数据def _create_document_converter(self):"""配置文档转换引擎"""return DocumentConverter(enable_ocr=True, # 启用图像文字识别table_detection_mode=2 # 增强表格检测)
2. ⭕文档转换引擎
- 基于
docling库实现多线程解析 - 支持PDF/Word格式转换
- 表格检测采用CNN神经网络识别表格边界
CNN神经网络
一种模仿人眼视觉原理的深度学习模型,通过局部感知和层次化提取特征(如边缘→纹理→物体部分→整体),自动识别图像中的模式。
CNN神经网络识别表格边界,就像用放大镜扫描表格图片,通过局部感知自动找到横竖线条的交汇处,最终框出表格的外框和内部格子。
3. JsonReportProcessor 类
class JsonReportProcessor:def assemble_tables(self, tables_raw_data, data):"""表格结构化处理"""for table in tables_raw_data:# 转换复杂表格为Markdowntable_md = self._table_to_md(table)# 建立表格与页面的映射关系yield {"table_id": idx,"markdown": table_md,"page_ref": data['tables'][idx]['prov'][0]['page_no']}
关键技术突破:
- 版面分析算法:采用计算机视觉技术识别
文档元素空间关系 - 增量式OCR:仅在检测到图像文本时
触发识别,优化处理速度 - 表格重建引擎:通过
行列检测算法还原复杂合并单元格
增量式OCR
一种动态识别技术,仅对文档中新修改或新增的部分进行文字识别,避免全量重复处理,类似"只扫描最新添加的笔迹"。
行列检测算法是一种用于在图像中识别并定位表格、表单等行列结构的计算机视觉技术。其核心思想是通过分析图像中的水平或垂直线条分布,将像素按行或列分组,从而提取结构化数据。
行列检测算法
通过边缘检测或投影分析找到密集的水平/垂直直线群,根据直线聚类结果划分行列区域。
常用霍夫变换或投影直方图峰值检测实现。
代码(Python+OpenCV)
import cv2
import numpy as npdef detect_grid(image_path):# 读取图像并转为灰度img = cv2.imread(image_path)gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 二值化处理_, thresh = cv2.threshold(gray, 240, 255, cv2.THRESH_BINARY_INV)# 霍夫线变换检测直线lines = cv2.HoughLinesP(thresh, 1, np.pi/180, 100, minLineLength=100, maxLineGap=10)# 绘制检测结果for line in lines:x1,y1,x2,y2 = line[0]cv2.line(img, (x1,y1), (x2,y2), (0,255,0), 2)return img
使用示例:
result = detect_grid("table.png")
cv2.imwrite("result.jpg", result)
应用场景:
- 文档扫描中的表格识别
- 票据数据提取
- 答题卡自动阅卷
- 财务报表数字化
霍夫变换
通过投票机制在图像中找出直线、圆等几何形状的方法,比如让所有可能的直线“投票”给最可能存在的形状。
投影直方图峰值检测
将图像像素按方向(如水平/垂直)投影统计,通过找直方图的最高点定位目标位置(如文字行或物体边缘)。
详见之后的opencv专栏~
总结
文档解析器作为RAG系统的数据入口,通过:
- 多模态解析:融合文本、图像和表格处理能力
- 智能重构:将印刷文档转化为机器可读的语义网络
- 弹性扩展:支持插件式集成新文档格式
为后续的向量化存储和语义检索奠定了高质量数据基础。这种精细化的预处理机制,使得原始文档中的隐性知识得以显性化表达,极大提升了系统的事实性回答能力。
下一章:文档准备与格式化




:多叉树)
中的节能控制(一))





![[Mysql] Connector / C++ 使用](http://pic.xiahunao.cn/[Mysql] Connector / C++ 使用)





)

