文章结尾有CSDN官方提供的学长的联系方式!!
欢迎关注B站
从零开始构建一个基于GraphRAG的红楼梦项目 第三集
01 搭建后端服务
创建一个python文件server.py
完整源码放到文章最后了。
1.1 graphrag 相关导入
# GraphRAG 相关导入
from graphrag.query.context_builder.entity_extraction import EntityVectorStoreKey
from graphrag.query.indexer_adapters import (read_indexer_covariates,read_indexer_entities,read_indexer_relationships,read_indexer_reports,read_indexer_text_units,
)
from graphrag.query.input.loaders.dfs import store_entity_semantic_embeddings
from graphrag.query.llm.oai.chat_openai import ChatOpenAI
from graphrag.query.llm.oai.embedding import OpenAIEmbedding
from graphrag.query.llm.oai.typing import OpenaiApiType
from graphrag.query.question_gen.local_gen import LocalQuestionGen
from graphrag.query.structured_search.local_search.mixed_context import LocalSearchMixedContext
from graphrag.query.structured_search.local_search.search import LocalSearch
from graphrag.query.structured_search.global_search.community_context import GlobalCommunityContext
from graphrag.query.structured_search.global_search.search import GlobalSearch
from graphrag.vector_stores.lancedb import LanceDBVectorStore
1.2 相关配置
# 设置日志模版
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)# 设置常量和配置 INPUT_DIR根据自己的建立graphrag的文件夹路径进行修改
INPUT_DIR = "/Volumes/tesla/dev/rag/GraphRAG001/output/20250820-212616/artifacts"
LANCEDB_URI = f"{INPUT_DIR}/lancedb"
COMMUNITY_REPORT_TABLE = "create_final_community_reports"
ENTITY_TABLE = "create_final_nodes"
ENTITY_EMBEDDING_TABLE = "create_final_entities"
RELATIONSHIP_TABLE = "create_final_relationships"
COVARIATE_TABLE = "create_final_covariates"
TEXT_UNIT_TABLE = "create_final_text_units"
1.3 大模型相关配置
# 从环境变量中获取OpenAI API密钥
api_key = os.environ["OPENAI_API_KEY"]
API_BASE_URL = "https://api.siliconflow.cn/v1"
CHAT_MODEL = "Qwen/Qwen3-32B"
EMBEDDING_MODEL = "BAAI/bge-m3"
1.4 FastAPI 搭建服务接口
# GET请求接口,获取可用模型列表
@app.get("/v1/models")
async def list_models():logger.info("收到模型列表请求")current_time = int(time.time())models = [{"id": "graphrag-local-search:latest", "object": "model", "created": current_time - 100000, "owned_by": "graphrag"},{"id": "graphrag-global-search:latest", "object": "model", "created": current_time - 95000, "owned_by": "graphrag"},{"id": "full-model:latest", "object": "model", "created": current_time - 80000, "owned_by": "combined"}]response = {"object": "list","data": models}logger.info(f"发送模型列表: {response}")return JSONResponse(content=response)if __name__ == "__main__":logger.info(f"在端口 {PORT} 上启动服务器")# uvicorn是一个用于运行ASGI应用的轻量级、超快速的ASGI服务器实现# 用于部署基于FastAPI框架的异步PythonWeb应用程序uvicorn.run(app, host="0.0.0.0", port=PORT)
02 测试问答
创建test.py文件
import requests
import jsonurl = "http://localhost:8012/v1/chat/completions"
headers = {"Content-Type": "application/json"}# 1、测试全局搜索 graphrag-global-search:latest
global_data = {"model": "graphrag-global-search:latest","messages": [{"role": "user", "content": "这个故事的首要主题是什么?记住请使用中文进行回答,不要用英文。"}],"temperature": 0.7,# "stream": True,#True or False
}# 2、测试本地搜索 graphrag-local-search:latest
local_data = {"model": "graphrag-local-search:latest","messages": [{"role": "user", "content": "贾政是谁,他的主要关系是什么?记住请使用中文进行回答,不要用英文。"}],"temperature": 0.7,"stream": True, #True or False
}response = requests.post(url, headers=headers, data=json.dumps(global_data))
print(response.json()['choices'][0]['message']['content'])2.1 测试结果
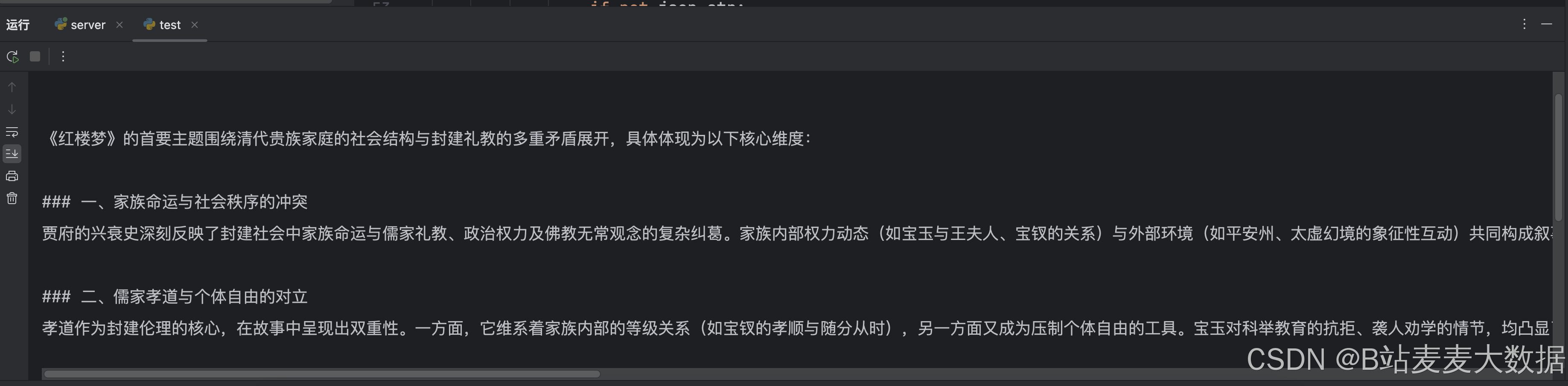
03 测试问答(流式)
创建test_stream.py文件
import requests
import jsonurl = "http://localhost:8012/v1/chat/completions"
headers = {"Content-Type": "application/json"}# 1、测试全局搜索 graphrag-global-search:latest
global_data = {"model": "graphrag-global-search:latest","messages": [{"role": "user", "content": "这个故事的首要主题是什么?记住请使用中文进行回答,不要用英文。"}],"temperature": 0.7,"stream": True
}# 2、测试本地搜索 graphrag-local-search:latest
local_data = {"model": "graphrag-local-search:latest","messages": [{"role": "user", "content": "贾政是谁,他的主要关系是什么?记住请使用中文进行回答,不要用英文。"}],"temperature": 0.7,"stream": False, #True or False
}# 3、测试全局和本地搜索 full-model:latest
full_data = {"model": "full-model:latest","messages": [{"role": "user", "content": "林黛玉是谁,他的主要关系是什么?记住请使用中文进行回答,不要用英文。"}],"temperature": 0.7,# "stream": True,#True or False
}# # 接收流式输出
try:with requests.post(url, stream=True, headers=headers, data=json.dumps(local_data)) as response:for line in response.iter_lines():# for line in response.iter_content(chunk_size=16):if line:json_str = line.decode('utf-8').strip("data: ")# 检查是否为空或不合法的字符串if not json_str:print("接收到空字符串,跳过...")continue# 处理流结束标记if json_str.strip() == '[DONE]':print("流式传输已成功完成")break# 确保字符串是有效的JSON格式if json_str.startswith('{') and json_str.endswith('}'):try:data = json.loads(json_str)# 检查content是否存在delta = data['choices'][0]['delta']if 'content' in delta:print(f"接收到JSON数据: {delta['content']}")else:print("接收到不包含内容的delta")# print(f"{data['choices'][0]['delta']['content']}")except json.JSONDecodeError as e:print(f"JSON解码失败: {e}")else:print(f"无效的JSON格式: {json_str}")
except Exception as e:print(f"发生错误: {e}")
3.1 测试结果

后端的完整代码
server.py
import os
import asyncio
import time
import uuid
import json
import re
import pandas as pd
import tiktoken
import logging
from fastapi import FastAPI, HTTPException, Request
from fastapi.responses import JSONResponse, StreamingResponse
from pydantic import BaseModel, Field
from typing import List, Optional, Dict, Any, Union
from contextlib import asynccontextmanager
import uvicorn# GraphRAG 相关导入
from graphrag.query.context_builder.entity_extraction import EntityVectorStoreKey
from graphrag.query.indexer_adapters import (read_indexer_covariates,read_indexer_entities,read_indexer_relationships,read_indexer_reports,read_indexer_text_units,
)
from graphrag.query.input.loaders.dfs import store_entity_semantic_embeddings
from graphrag.query.llm.oai.chat_openai import ChatOpenAI
from graphrag.query.llm.oai.embedding import OpenAIEmbedding
from graphrag.query.llm.oai.typing import OpenaiApiType
from graphrag.query.question_gen.local_gen import LocalQuestionGen
from graphrag.query.structured_search.local_search.mixed_context import LocalSearchMixedContext
from graphrag.query.structured_search.local_search.search import LocalSearch
from graphrag.query.structured_search.global_search.community_context import GlobalCommunityContext
from graphrag.query.structured_search.global_search.search import GlobalSearch
from graphrag.vector_stores.lancedb import LanceDBVectorStore# 设置日志模版
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)# 设置常量和配置 INPUT_DIR根据自己的建立graphrag的文件夹路径进行修改
INPUT_DIR = "/Volumes/tesla/dev/rag/GraphRAG001/output/20250820-212616/artifacts"
LANCEDB_URI = f"{INPUT_DIR}/lancedb"
COMMUNITY_REPORT_TABLE = "create_final_community_reports"
ENTITY_TABLE = "create_final_nodes"
ENTITY_EMBEDDING_TABLE = "create_final_entities"
RELATIONSHIP_TABLE = "create_final_relationships"
COVARIATE_TABLE = "create_final_covariates"
TEXT_UNIT_TABLE = "create_final_text_units"# community level in the Leiden community hierarchy from which we will load the community reports
# higher value means we use reports from more fine-grained communities (at the cost of higher computation cost)
COMMUNITY_LEVEL = 2
PORT = 8012# 从环境变量中获取OpenAI API密钥
api_key = os.environ["OPENAI_API_KEY"]
API_BASE_URL = "https://api.siliconflow.cn/v1"
CHAT_MODEL = "Qwen/Qwen3-32B"
EMBEDDING_MODEL = "BAAI/bge-m3"# 全局变量,用于存储搜索引擎和问题生成器
local_search_engine = None
global_search_engine = None
question_generator = None# 定义Message类型
class Message(BaseModel):role: strcontent: str# 定义ChatCompletionRequest类
class ChatCompletionRequest(BaseModel):model: strmessages: List[Message]temperature: Optional[float] = 1.0top_p: Optional[float] = 1.0n: Optional[int] = 1stream: Optional[bool] = Falsestop: Optional[Union[str, List[str]]] = Nonemax_tokens: Optional[int] = Nonepresence_penalty: Optional[float] = 0frequency_penalty: Optional[float] = 0logit_bias: Optional[Dict[str, float]] = Noneuser: Optional[str] = None# 定义ChatCompletionResponseChoice类
class ChatCompletionResponseChoice(BaseModel):index: intmessage: Messagefinish_reason: Optional[str] = None# 定义Usage类
class Usage(BaseModel):prompt_tokens: intcompletion_tokens: inttotal_tokens: int# 定义ChatCompletionResponse类
class ChatCompletionResponse(BaseModel):id: str = Field(default_factory=lambda: f"chatcmpl-{uuid.uuid4().hex}")object: str = "chat.completion"created: int = Field(default_factory=lambda: int(time.time()))model: strchoices: List[ChatCompletionResponseChoice]usage: Usagesystem_fingerprint: Optional[str] = None# 设置语言模型(LLM)、token编码器(TokenEncoder)和文本嵌入向量生成器(TextEmbedder)
async def setup_llm_and_embedder():logger.info("正在设置LLM和嵌入器")# 实例化一个ChatOpenAI客户端对象llm = ChatOpenAI(api_base=API_BASE_URL, # 请求的API服务地址api_key=api_key, # API Keymodel=CHAT_MODEL, # 本次使用的模型api_type=OpenaiApiType.OpenAI,)# 初始化token编码器token_encoder = tiktoken.get_encoding("cl100k_base")# 实例化OpenAIEmbeddings处理模型text_embedder = OpenAIEmbedding(# 调用本地大模型 通过Ollamaapi_base=API_BASE_URL, # 请求的API服务地址api_key=api_key, # API Keymodel=EMBEDDING_MODEL,deployment_name=EMBEDDING_MODEL,api_type=OpenaiApiType.OpenAI,max_retries=20,)logger.info("LLM和嵌入器设置完成")return llm, token_encoder, text_embedder# 加载上下文数据,包括实体、关系、报告、文本单元和协变量
async def load_context():logger.info("正在加载上下文数据")try:# 使用pandas库从指定的路径读取实体数据表ENTITY_TABLE,文件格式为Parquet,并将其加载为DataFrame,存储在变量entity_df中entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")# 读取实体嵌入向量数据表ENTITY_EMBEDDING_TABLE,并将其加载为DataFrame,存储在变量entity_embedding_df中entity_embedding_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet")# 将entity_df和entity_embedding_df传入,并基于COMMUNITY_LEVEL(社区级别)处理这些数据,返回处理后的实体数据entitiesentities = read_indexer_entities(entity_df, entity_embedding_df, COMMUNITY_LEVEL)# 创建一个LanceDBVectorStore的实例description_embedding_store,用于存储实体的描述嵌入向量# 这个实例与一个名为"entity_description_embeddings_xiyoujiqwen"的集合(collection)相关联description_embedding_store = LanceDBVectorStore(collection_name="entity_description_embeddings")# 通过调用connect方法,连接到指定的LanceDB数据库,使用的URI存储在LANCEDB_URI变量中description_embedding_store.connect(db_uri=LANCEDB_URI)# 将已处理的实体数据entities存储到description_embedding_store中,用于语义搜索或其他用途store_entity_semantic_embeddings(entities=entities, vectorstore=description_embedding_store)relationship_df = pd.read_parquet(f"{INPUT_DIR}/{RELATIONSHIP_TABLE}.parquet")relationships = read_indexer_relationships(relationship_df)report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")reports = read_indexer_reports(report_df, entity_df, COMMUNITY_LEVEL)text_unit_df = pd.read_parquet(f"{INPUT_DIR}/{TEXT_UNIT_TABLE}.parquet")text_units = read_indexer_text_units(text_unit_df)covariate_df = pd.read_parquet(f"{INPUT_DIR}/{COVARIATE_TABLE}.parquet")claims = read_indexer_covariates(covariate_df)logger.info(f"声明记录数: {len(claims)}")covariates = {"claims": claims}logger.info("上下文数据加载完成")return entities, relationships, reports, text_units, description_embedding_store, covariatesexcept Exception as e:logger.error(f"加载上下文数据时出错: {str(e)}")raise# 设置本地和全局搜索引擎、上下文构建器(ContextBuilder)、以及相关参数
async def setup_search_engines(llm, token_encoder, text_embedder, entities, relationships, reports, text_units,description_embedding_store, covariates):logger.info("正在设置搜索引擎")# 设置本地搜索引擎local_context_builder = LocalSearchMixedContext(community_reports=reports,text_units=text_units,entities=entities,relationships=relationships,covariates=covariates,entity_text_embeddings=description_embedding_store,embedding_vectorstore_key=EntityVectorStoreKey.ID,text_embedder=text_embedder,token_encoder=token_encoder,)local_context_params = {"text_unit_prop": 0.5,"community_prop": 0.1,"conversation_history_max_turns": 5,"conversation_history_user_turns_only": True,"top_k_mapped_entities": 10,"top_k_relationships": 10,"include_entity_rank": True,"include_relationship_weight": True,"include_community_rank": False,"return_candidate_context": False,"embedding_vectorstore_key": EntityVectorStoreKey.ID,# "max_tokens": 12_000,"max_tokens": 4096,}local_llm_params = {# "max_tokens": 2_000,"max_tokens": 4096,"temperature": 0.0,}local_search_engine = LocalSearch(llm=llm,context_builder=local_context_builder,token_encoder=token_encoder,llm_params=local_llm_params,context_builder_params=local_context_params,response_type="multiple paragraphs",)# 设置全局搜索引擎global_context_builder = GlobalCommunityContext(community_reports=reports,entities=entities,token_encoder=token_encoder,)global_context_builder_params = {"use_community_summary": False,"shuffle_data": True,"include_community_rank": True,"min_community_rank": 0,"community_rank_name": "rank","include_community_weight": True,"community_weight_name": "occurrence weight","normalize_community_weight": True,# "max_tokens": 12_000,"max_tokens": 4096,"context_name": "Reports",}map_llm_params = {"max_tokens": 1000,"temperature": 0.0,"response_format": {"type": "json_object"},}reduce_llm_params = {"max_tokens": 2000,"temperature": 0.0,}global_search_engine = GlobalSearch(llm=llm,context_builder=global_context_builder,token_encoder=token_encoder,# max_data_tokens=12_000,max_data_tokens=4096,map_llm_params=map_llm_params,reduce_llm_params=reduce_llm_params,allow_general_knowledge=False,json_mode=True,context_builder_params=global_context_builder_params,concurrent_coroutines=32,response_type="multiple paragraphs",)logger.info("搜索引擎设置完成")return local_search_engine, global_search_engine, local_context_builder, local_llm_params, local_context_params# 格式化响应,对输入的文本进行段落分隔、添加适当的换行符,以及在代码块中增加标记,以便生成更具可读性的输出
def format_response(response):# 使用正则表达式 \n{2, }将输入的response按照两个或更多的连续换行符进行分割。这样可以将文本分割成多个段落,每个段落由连续的非空行组成paragraphs = re.split(r'\n{2,}', response)# 空列表,用于存储格式化后的段落formatted_paragraphs = []# 遍历每个段落进行处理for para in paragraphs:# 检查段落中是否包含代码块标记if '```' in para:# 将段落按照```分割成多个部分,代码块和普通文本交替出现parts = para.split('```')for i, part in enumerate(parts):# 检查当前部分的索引是否为奇数,奇数部分代表代码块if i % 2 == 1: # 这是代码块# 将代码块部分用换行符和```包围,并去除多余的空白字符parts[i] = f"\n```\n{part.strip()}\n```\n"# 将分割后的部分重新组合成一个字符串para = ''.join(parts)else:# 否则,将句子中的句点后面的空格替换为换行符,以便句子之间有明确的分隔para = para.replace('. ', '.\n')# 将格式化后的段落添加到formatted_paragraphs列表# strip()方法用于移除字符串开头和结尾的空白字符(包括空格、制表符 \t、换行符 \n等)formatted_paragraphs.append(para.strip())# 将所有格式化后的段落用两个换行符连接起来,以形成一个具有清晰段落分隔的文本return '\n\n'.join(formatted_paragraphs)# 定义了一个异步函数 lifespan,它接收一个 FastAPI 应用实例 app 作为参数。这个函数将管理应用的生命周期,包括启动和关闭时的操作
# 函数在应用启动时执行一些初始化操作,如设置搜索引擎、加载上下文数据、以及初始化问题生成器
# 函数在应用关闭时执行一些清理操作
# @asynccontextmanager 装饰器用于创建一个异步上下文管理器,它允许你在 yield 之前和之后执行特定的代码块,分别表示启动和关闭时的操作
@asynccontextmanager
async def lifespan(app: FastAPI):# 启动时执行# 申明引用全局变量,在函数中被初始化,并在整个应用中使用global local_search_engine, global_search_engine, question_generatortry:logger.info("正在初始化搜索引擎和问题生成器...")# 调用setup_llm_and_embedder()函数以设置语言模型(LLM)、token编码器(TokenEncoder)和文本嵌入向量生成器(TextEmbedder)# await 关键字表示此调用是异步的,函数将在这个操作完成后继续执行llm, token_encoder, text_embedder = await setup_llm_and_embedder()# 调用load_context()函数加载实体、关系、报告、文本单元、描述嵌入存储和协变量等数据,这些数据将用于构建搜索引擎和问题生成器entities, relationships, reports, text_units, description_embedding_store, covariates = await load_context()# 调用setup_search_engines()函数设置本地和全局搜索引擎、上下文构建器(ContextBuilder)、以及相关参数local_search_engine, global_search_engine, local_context_builder, local_llm_params, local_context_params = await setup_search_engines(llm, token_encoder, text_embedder, entities, relationships, reports, text_units,description_embedding_store, covariates)# 使用LocalQuestionGen类创建一个本地问题生成器question_generator,将前面初始化的各种组件传递给它question_generator = LocalQuestionGen(llm=llm,context_builder=local_context_builder,token_encoder=token_encoder,llm_params=local_llm_params,context_builder_params=local_context_params,)logger.info("初始化完成")except Exception as e:logger.error(f"初始化过程中出错: {str(e)}")# raise 关键字重新抛出异常,以确保程序不会在错误状态下继续运行raise# yield 关键字将控制权交还给FastAPI框架,使应用开始运行# 分隔了启动和关闭的逻辑。在yield 之前的代码在应用启动时运行,yield 之后的代码在应用关闭时运行yield# 关闭时执行logger.info("正在关闭...")# lifespan 参数用于在应用程序生命周期的开始和结束时执行一些初始化或清理工作
app = FastAPI(lifespan=lifespan)# 执行全模型搜索,包括本地检索、全局检索
async def full_model_search(prompt: str):local_result = await local_search_engine.asearch(prompt)global_result = await global_search_engine.asearch(prompt)# 格式化结果formatted_result = "#综合搜索结果:\n\n"formatted_result += "##本地检索结果:\n"formatted_result += format_response(local_result.response) + "\n\n"formatted_result += "##全局检索结果:\n"formatted_result += format_response(global_result.response) + "\n\n"return formatted_result# POST请求接口,与大模型进行知识问答
@app.post("/v1/chat/completions")
async def chat_completions(request: ChatCompletionRequest):if not local_search_engine or not global_search_engine:logger.error("搜索引擎未初始化")raise HTTPException(status_code=500, detail="搜索引擎未初始化")try:logger.info(f"收到聊天完成请求: {request}")prompt = request.messages[-1].contentlogger.info(f"处理提示: {prompt}")# 根据模型选择使用不同的搜索方法if request.model == "graphrag-global-search:latest":result = await global_search_engine.asearch(prompt)formatted_response = format_response(result.response)elif request.model == "full-model:latest":formatted_response = await full_model_search(prompt)elif request.model == "graphrag-local-search:latest": # 默认使用本地搜索result = await local_search_engine.asearch(prompt)formatted_response = format_response(result.response)logger.info(f"格式化的搜索结果:\n {formatted_response}")# 流式响应和非流式响应的处理保持不变if request.stream:# 定义一个异步生成器函数,用于生成流式数据async def generate_stream():# 为每个流式数据片段生成一个唯一的chunk_idchunk_id = f"chatcmpl-{uuid.uuid4().hex}"# 将格式化后的响应按行分割lines = formatted_response.split('\n')# 历每一行,并构建响应片段for i, line in enumerate(lines):# 创建一个字典,表示流式数据的一个片段chunk = {"id": chunk_id,"object": "chat.completion.chunk","created": int(time.time()),"model": request.model,"choices": [{"index": 0,"delta": {"content": line + '\n'}, # if i > 0 else {"role": "assistant", "content": ""},"finish_reason": None}]}# 将片段转换为JSON格式并生成yield f"data: {json.dumps(chunk)}\n"# 每次生成数据后,异步等待0.5秒await asyncio.sleep(0.5)# 生成最后一个片段,表示流式响应的结束final_chunk = {"id": chunk_id,"object": "chat.completion.chunk","created": int(time.time()),"model": request.model,"choices": [{"index": 0,"delta": {},"finish_reason": "stop"}]}yield f"data: {json.dumps(final_chunk)}\n"yield "data: [DONE]\n"# 返回StreamingResponse对象,流式传输数据,media_type设置为text/event-stream以符合SSE(Server-SentEvents) 格式return StreamingResponse(generate_stream(), media_type="text/event-stream")# 非流式响应处理else:response = ChatCompletionResponse(model=request.model,choices=[ChatCompletionResponseChoice(index=0,message=Message(role="assistant", content=formatted_response),finish_reason="stop")],# 使用情况usage=Usage(# 提示文本的tokens数量prompt_tokens=len(prompt.split()),# 完成文本的tokens数量completion_tokens=len(formatted_response.split()),# 总tokens数量total_tokens=len(prompt.split()) + len(formatted_response.split())))logger.info(f"发送响应: \n\n{response}")# 返回JSONResponse对象,其中content是将response对象转换为字典的结果return JSONResponse(content=response.dict())except Exception as e:logger.error(f"处理聊天完成时出错:\n\n {str(e)}")raise HTTPException(status_code=500, detail=str(e))# GET请求接口,获取可用模型列表
@app.get("/v1/models")
async def list_models():logger.info("收到模型列表请求")current_time = int(time.time())models = [{"id": "graphrag-local-search:latest", "object": "model", "created": current_time - 100000, "owned_by": "graphrag"},{"id": "graphrag-global-search:latest", "object": "model", "created": current_time - 95000, "owned_by": "graphrag"},{"id": "full-model:latest", "object": "model", "created": current_time - 80000, "owned_by": "combined"}]response = {"object": "list","data": models}logger.info(f"发送模型列表: {response}")return JSONResponse(content=response)if __name__ == "__main__":logger.info(f"在端口 {PORT} 上启动服务器")# uvicorn是一个用于运行ASGI应用的轻量级、超快速的ASGI服务器实现# 用于部署基于FastAPI框架的异步PythonWeb应用程序uvicorn.run(app, host="0.0.0.0", port=PORT)适配CmBacktrace错误追踪)






)



和移动网络(蜂窝数据)的环境下,使用安卓平板,通过USB数据线(而不是Wi-Fi)来控制电脑(版本2))







