Milvus 介绍
Milvus 是一个开源的向量数据库,专为处理大规模、高维度向量数据而设计,广泛应用于人工智能、推荐系统、图像检索、自然语言处理等场景。它支持亿级向量的高效存储与快速检索,内置多种相似度搜索算法(如 HNSW、IVF、FLAT),并支持 GPU 加速,极大提升了检索性能。Milvus 提供易用的 API 接口,兼容多种数据格式,支持水平扩展,方便集成到各类 AI 应用中,是构建智能搜索系统的理想选择。
对 Milvus 进行可观测和监控是保障向量数据库稳定、高效运行的基础。通过实时监控系统资源使用、检索延迟、查询吞吐等关键性能指标,可以及时发现瓶颈、排查故障,确保向量检索任务的准确性与响应速度。同时,可观测性有助于预测容量需求、优化硬件资源配置,提升整体系统的可用性与弹性。它还支持自动化运维、问题追踪和性能调优,为构建智能应用提供稳定可靠的数据服务支撑。简而言之,完善的可观测体系是实现 Milvus 高性能、高可用及可扩展性的关键保障。
观测云
观测云是一款专为 IT 工程师打造的全链路可观测产品,它集成了基础设施监控、应用程序性能监控和日志管理,为整个技术栈提供实时可观察性。这款产品能够帮助工程师全面了解端到端的用户体验追踪,了解应用内函数的每一次调用,以及全面监控云时代的基础设施。此外,观测云还具备快速发现系统安全风险的能力,为数字化时代提供安全保障。
本实践 Milvus 组件主要部署在 K8s 环境,并通过观测云进行数据采集、分析和监控。
部署 DataKit
DataKit 是一个开源的、跨平台的数据收集和监控工具,由观测云开发并维护。它旨在帮助用户收集、处理和分析各种数据源,如日志、指标和事件,以便进行有效的监控和故障排查。DataKit 支持多种数据输入和输出格式,可以轻松集成到现有的监控系统中。
登录观测云控制台,在「集成」 - 「DataKit」选择对应安装方式。下载 datakit.yaml,拷贝第 3 步中 ENV_DATAWAY 键的值。
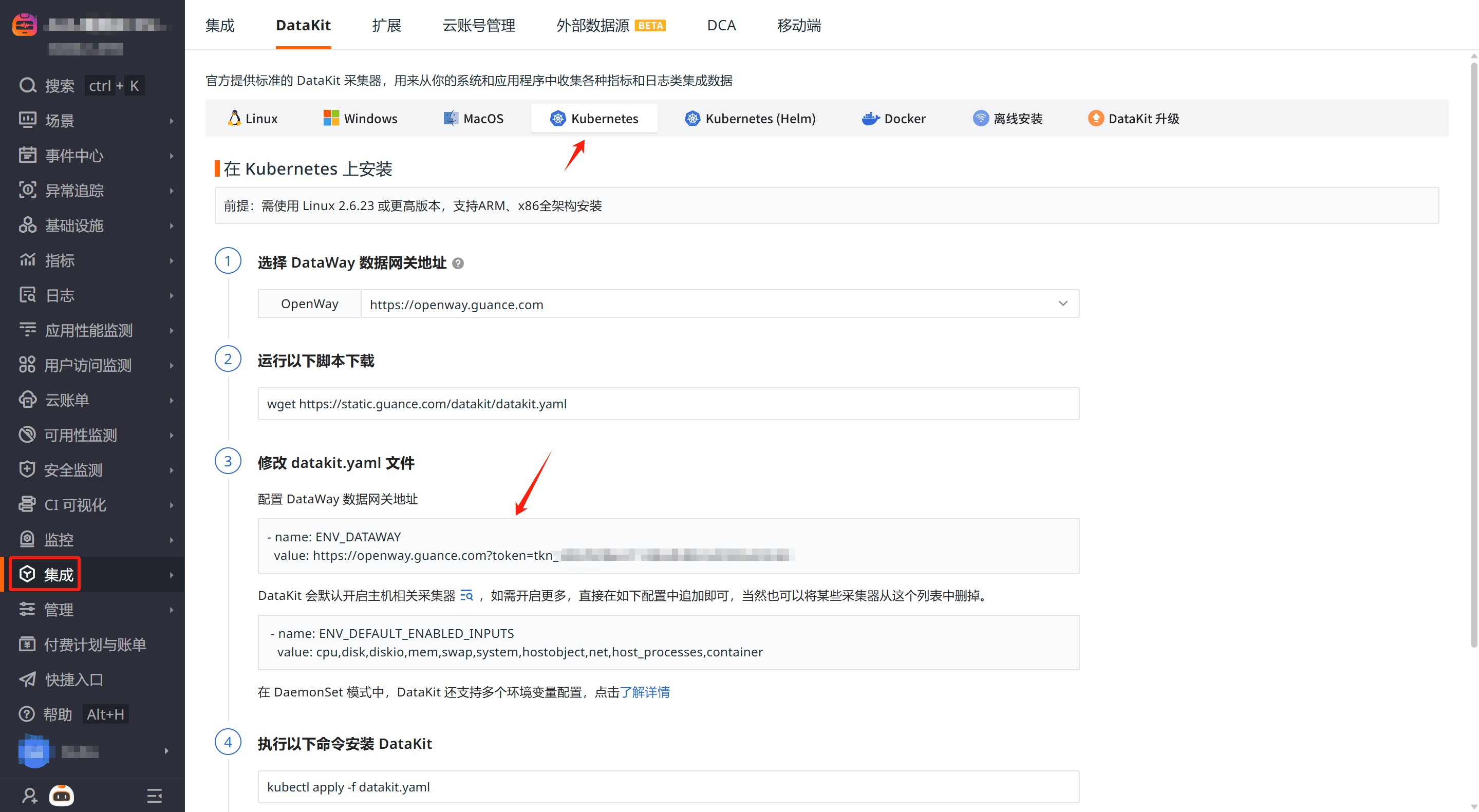
编辑 datakit.yaml,修改 DaemonSet 环境变量:
- 修改 ENV_DATAWAY 的值为上一步中拷贝的值;
- 修改 ENV_CLUSTER_NAME_K8S 的值为集群名称;
- 新增 ENV_NAMESPACE,值为集群名称;
执行以下命令部署 DataKit 并验证:
kubectl apply -f datakit.yaml
kubectl get pods -n datakit
采集器配置
前置条件
-
已经安装好 Milvus,本文测试的是 Helm 安装的 Milvus(v2.4.x),安装方式可参考:
Requirements for running Milvus on Kubernetes Milvus v2.4.x documentation -
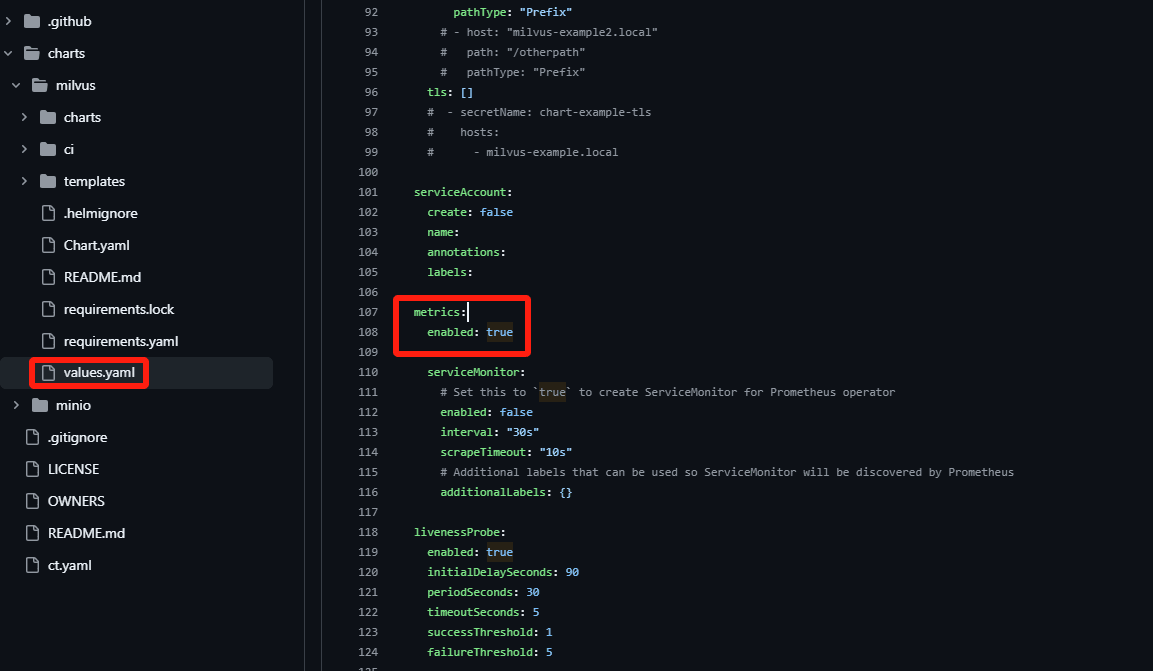
检查 value.yaml 中的指标暴露是否已经打开(默认是开启的)
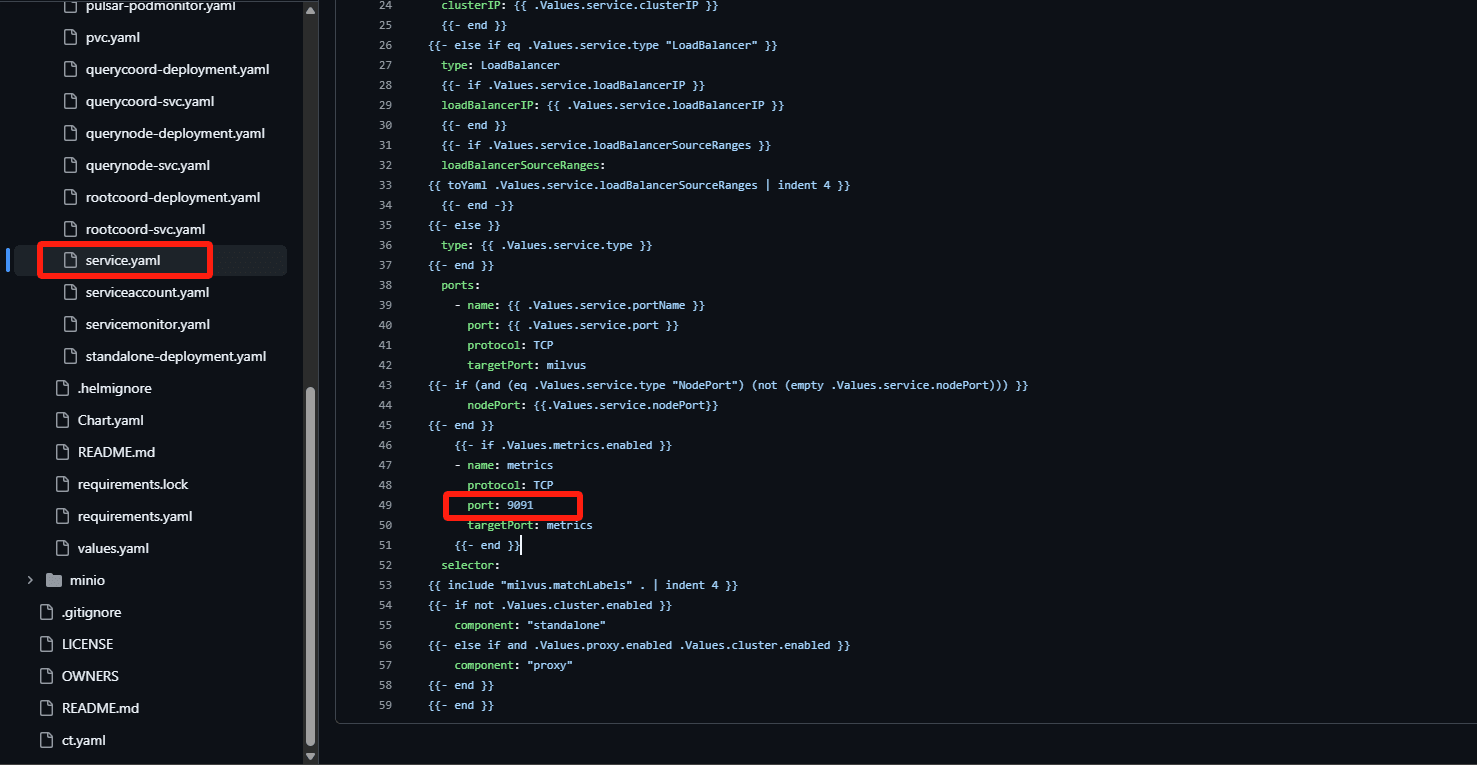
- 检查 service.yaml 中对应指标暴露的端口是否是 9091
- 以上操作完成后可以进入 milvus 集群中某一个容器,通过
curl http://localhost:9091/metrics命令检查是否有指标数据
配置采集器
- 开启 Kubernetes Prometheus Discovery 插件
创建 Configmap 并挂载为 DataKit kubernetesprometheus 采集器的配置文件即可开启采集,插件通过角色、命名空间、标签自动发现采集端点。注意在 [inputs.kubernetesprometheus.instances.custom.tags] 中配置 Kubernetes 集群名作为指标标签,其他标签将根据配置自动取值。标签用于区分不同集群、实例、关联基础设施指标。插件配置举例如下:
apiVersion: v1
kind: ConfigMap
metadata:name: datakit-confnamespace: datakit
data:kubernetesprometheus.conf: |-[inputs.kubernetesprometheus]node_local = true[[inputs.kubernetesprometheus.instances]]role = "pod"# milvus-cluster of namespacenamespaces = ["milvus-cluster"]selector = "app.kubernetes.io/name=milvus"scrape = "true"scheme = "http"port = "9091"path = "/metrics"# 采集器采集频率scrape_interval = "60s" [inputs.kubernetesprometheus.instances.custom]measurement = "milvus"job_as_measurement = false[inputs.kubernetesprometheus.instances.custom.tags]cluster_name_k8s = "k8s_saas"instance = "__kubernetes_mate_instance"pod_name = "__kubernetes_pod_name"pod_namespace = "__kubernetes_pod_namespace"node_name = "__kubernetes_pod_node_name"
为 DataKit 挂载配置文件的方式如下:
- mountPath: /usr/local/datakit/conf.d/kubernetesprometheus/kubernetesprometheus.confname: datakit-confsubPath: kubernetesprometheus.confreadOnly: true
关键指标
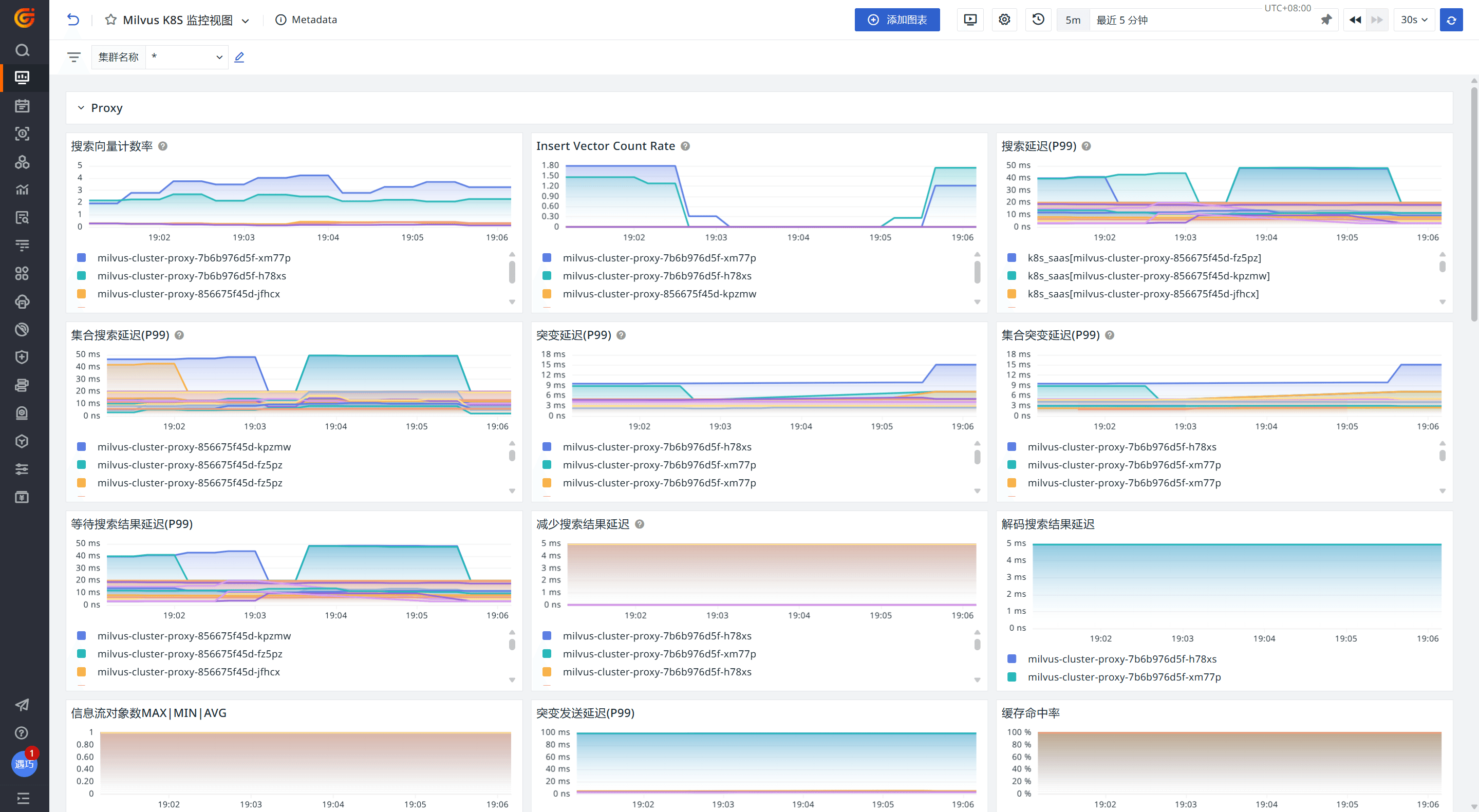
Proxy
| 指标 | 指标说明 |
|---|---|
milvus_proxy_search_vectors_count | 累计查询的向量数。 |
milvus_proxy_insert_vectors_count | 插入向量的累计数量。 |
milvus_proxy_sq_latency | 搜索和查询请求的延迟。 |
milvus_proxy_mutation_latency | 突变请求的延迟。 |
milvus_proxy_req_count | 所有类型接收请求的数量。 |
milvus_proxy_cache_hit_count | 每次缓存读取操作的命中和失败率的统计。 |
Query Node
| 指标 | 指标说明 |
|---|---|
milvus_querynode_sq_req_count | 搜索和查询请求的累计数量。 |
milvus_querynode_sq_req_latency | 查询节点的查询请求延迟。 |
milvus_querynode_entity_num | 每个查询节点上可查询和可搜索的实体数量。 |
milvus_querynode_segment_num | 每个查询节点加载的 segment 数量。 |
Data Node
| 指标 | 指标说明 |
|---|---|
milvus_datanode_msg_rows_count | 数据节点消费的流消息的行数。目前数据节点统计的流消息仅包括插入和删除消息。 |
milvus_datanode_flushed_data_size | 每个刷写消息的大小。目前数据节点统计的流消息仅包括插入和删除消息。 |
milvus_datanode_unflushed_segment_num | 每个数据节点上创建的未刷写 segment 的数量。 |
milvus_datanode_compaction_latency | 每个数据节点执行合并任务所花费的时间。 |
Query Coord
| 指标 | 指标说明 |
|---|---|
milvus_querycoord_collection_num | 当前被 Milvus 加载的集合数量。 |
Root Coord
| 指标 | 指标说明 |
|---|---|
milvus_rootcoord_ddl_req_count | 包括 CreateCollection、DescribeCollection 等在内的所有 DDL 请求的总数。 |
milvus_rootcoord_ddl_req_latency | 所有类型 DDL 请求的延迟。 |
milvus_rootcoord_id_alloc_count | root coord 分配的 ID 的累计数量。 |
Index Node
| 指标 | 指标说明 |
|---|---|
milvus_indexnode_build_index_latency | 用于构建索引的时间。 |
场景视图
登录观测云控制台,点击「场景」 -「新建仪表板」,输入 “Milvus”, 选择 “Milvus K8S 监控视图”,点击 “确定” 即可添加视图。
监控器(告警)
观测云内置了监控器模板,可以选择从模版创建监控器,并开启适合业务的监控器以及时通知相关成员关注问题,触发条件、频率等信息可以依据实际业务进行调整。
登录观测云控制台,点击「监控」 -「新建监控器」,输入 “Milvus”, 选择对应的监控器,点击 “确定” 即可添加。
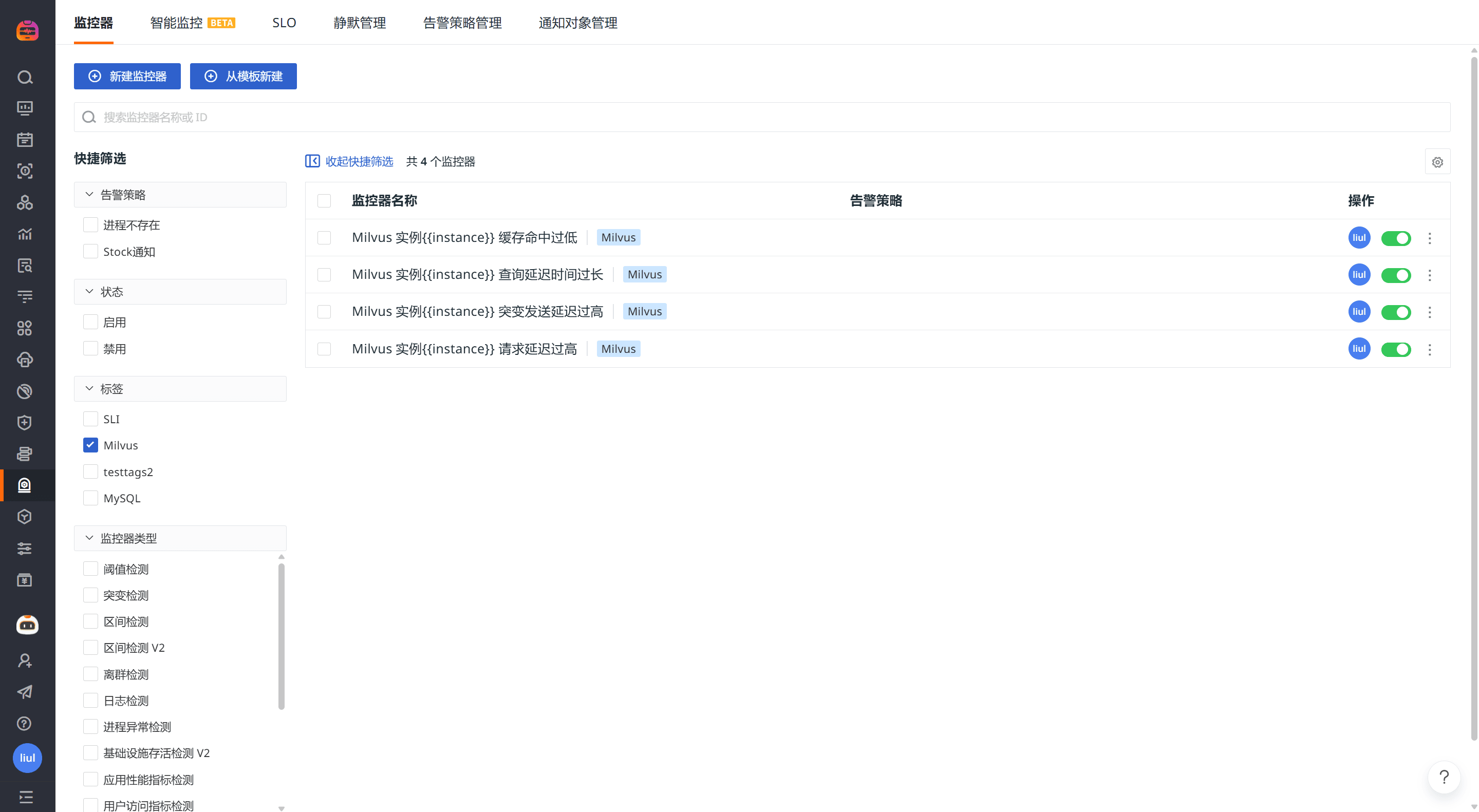
| 监控器名称 | 告警提示 |
|---|---|
| Milvus 实例{{instance}} 缓存命中过低 | 用于监控Milvus缓存机制的命中效率,有助于分析性能优化空间 |
| Milvus 实例{{instance}} 查询延迟时间过长 | 用于监控搜索请求的整体响应开销,帮助定位性能瓶颈 |
| Milvus 实例{{instance}} 突变发送延迟过高 | 用于监控写请求的发送延迟,判断写路径是否存在拥塞或异常 |
| Milvus 实例{{instance}} 请求延迟过高 | 用于监控延迟是否集中或存在长尾问题 |
总结
Milvus 作为一款专为大规模、高维度向量数据设计的开源向量数据库,通过观测云平台统一采集并监控其关键性能指标,对于保障系统高性能、高可用及弹性扩展至关重要。实时监控检索延迟、查询吞吐、缓存命中率、内存与 CPU 使用率等核心指标,能够全面洞察向量检索行为与资源负载。这些数据的持续追踪不仅帮助优化索引与缓存策略、提升检索效率,还能精准识别性能瓶颈,实现故障的提前预警与分钟级根因定位,确保 AI 应用在亿级向量场景下依旧稳定、可靠、高效运行。
)



和移动网络(蜂窝数据)的环境下,使用安卓平板,通过USB数据线(而不是Wi-Fi)来控制电脑(版本2))









)


get报错注入 过滤select和union ‘闭合)

