引入
基于Transformers的NLP解决方案的步骤如下:(以文本分类为例)
- 导入相关包,General,可以询问ai需要导什么包
- 加载数据集,Data_loader,Datasets
- 数据集划分,测试机,验证集,训练集,Datasets
- 数据集预处理,处理空的部分,Tokenizer+Datasets
- 创建模型,Model
- 设置评估函数,可以去hugging face上查看这个相应的评估指标有哪些,Evaluate
- 配置训练参数,训练批次,输出大小,日志打印频率,Training Argument
- 创建训练器,Trainer+Data Collator
- 模型训练,评估,预测,Trainer
- 如果只是想要用模型进行预测使用pipeline即可,不用子啊设置评估和训练函数了。Pipeline
显存优化分析
显存占用分析
-
模型权重
- 4Bytes*模型参数(因为每一个参数都是32bit的)
-
优化器状态
- 8Bytes*模型参数量,对于常用的AdamW优化器而言
-
梯度
- 4Bytes*模型参数量
-
前向激活值
- 取决于序列长度,隐层额外i都,Batch大小等多个因素
显存优化策略
使用hfl/chinese-macbert-large,330M进行测试
| 优化策略 | 优化对象 | 显存占用 | 训练时间 |
|---|---|---|---|
| Baseline(BS 32 ,MaxLength 128) | - | 15.2G | 64s |
+Gradient Accumulation (BS 1, GA 32)gradient_accumulation_steps=32 梯度累加 | 前向激活值,一次只计算一个批次是数据,为了防止效果变差,我们设置计算32个batch之后才进行参数优化 | 7.4G | 260s |
+Gradient Checkpoints (BS 1, GA 32)gradient_checkpointing=True梯度检查点 | 前向激活值 ,训练的过程中会存储很多没必要存储的信息,对于没有存储的激活值,可有在反向传播计算梯度的时候,让它重新计算即可。 | 7.2G | 422s |
+Adafactor Optiomizer(BS 1,GA32)optim="adafactor" adafactor优化器 | 优化器状态,默认的adaw优化器占用较大,可以用占用比较小的优化器 | 5.0G | 406s |
| +Freeze Model(BS 1,GA32) | 前向激活值/梯度,冻结一部分参数,只训练分类器部分,模型效果会变差 | 3.5G | 178s |
| +DataLength(BS1,GA32,MaxLength64) 在数据集中的maxlength处进行修改 | 前向激活值,缩短数据长度 | 3.4G | 126s |
其中对于这个+Freeze Model(BS 1,GA32作用就是冻结这个模型的bert部分,只训练这个模型的全连接层部分。
-
这是因为:
预训练模型(bert)已经学了很多中文知识,像「词典+语法」。
我们的任务只是影评情感二分类,不想让它从头再学中文,只想让它学「如何把已掌握的知识转成情感标签」。
所以把 bert 的大部分权重「冻住」,只训练后面新加的分类层,既省显存又省时间,还能防止过拟合。 -
具体操作
for name, param in model.bert.named_parameters():param.requires_grad = False model.bert 就是原始 BERT 的所有层 循环把每一层的权重 param 设置成 requires_grad=False → 不再更新(梯度不计算) 练时只有没被冻结的层(例如你后面接的 classifier 或 pooler)才会更新。
实战演练之命名实体识别
命名实体识别任务介绍
介绍
命名实体识别(Named Entity Recognition,简称NER)是指识别文本中具有特定意义的实体,
主要包括人名、地名、机构名、专有名词等。通常包括两部分:
(1)实体边界识别(从哪里到哪里是一个实体);(2)确定实体类别(人名、地名、机构名或其他)
eg 小明在北京上班
| 实体类别 | 实体 |
|---|---|
| 地点 | 北京 |
| 人物 | 小明 |
数据标注体系
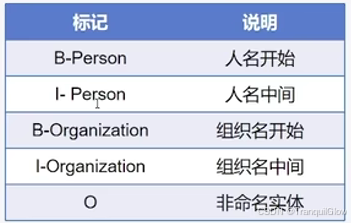
常见的数据标注有IOB1、IOB2、IOE1、IOE2、IOBES、BILOU
其中IOB2标注
- I表示实体内部,,O表示实体外部,B表示实体开始
- B/I-XXX,XXX表示具体的类别
IOBES标注
- I或者M表示实体内部,O表示实体外部,B表示实体开始,E表示实体结束,S表示一个词单独形成一个
命名实体
评估指标
Precision,Recall,f1

基于Transfromers的解决方案
- ModelForTokenClassification的源码分析,这个地方看不太懂,先放在这里
评估函数
-
需要额外安装seqeval
- pip install seqeval
- 安装过程中报错Microsoft Visual C++14.0 or greater is required.Getitwith
"Microsoft C++ Build Tools - 进入https://my.visualstudio.com,下载C++buildtools,安装
-
evaluate.load(“seqeval”)
代码实战演练
数据集:peoples_daily_ner
预训练模型:hfl/chinese-macbert-base
代码如下所示:
导入相关包,加载数据集
导包
import evaluate
from datasets import load_dataset
from transformers import AutoTokenizer,AutoModelForTokenClassification,TrainingArguments,Trainer,DataCollatorForTokenClassification导入训练集
ner_datasets = load_dataset("peoples_daily_ner",cache_dir="./data" ,trust_remote_code=True)
ner_datasets查看训练集第0个数据
ner_datasets["train"][0]
查看训练集数据的特征,包括模型是什么类型的数据,以及数据标注体系
ner_datasets["train"].features获取模型的标注类型
label_list = ner_datasets["train"].features["ner_tags"].feature.names
label_list
数据集预处理
使用模型为:hfl/chinese-macbert-base
由于模型中的tokens是已经划分好了, 直接用tokenizer进行分词的话,它会将每一个划分好的词,当成一个句子
tokenizer = AutoTokenizer.from_pretrained("hfl/chinese-macbert-base")
tokenizer(ner_datasets["train"][0]["tokens"])
我们可以使用is_split_into_words=True 来讲这个不要当成一个句子
tokenizer(ner_datasets["train"][0]["tokens"],is_split_into_words=True)
一个单词可能被 tokenizer 拆成好几块积木(sub-word),我们要保证同一块原单词的每一块积木都贴上同一个标签
返回的字典里多了一组 “word_ids()” 索引,告诉你每块积木属于原列表里的第几个单词。
还有一个问题就是英文中可能会出现分词现象,一个单词被拆分成了多个,所以我们要写代码,进行判断哪些id是属于一个单词的。例如下面这个
res = tokenizer("interesting word")
res就会讲这个interestion划分为id,但是interesting并不是单独一个,而是多个值
res.word_ids(),这个word_ids可以用来判断这些id哪些是一组的。
具体实现如下所示:(这段代码的功能就类似于:给一串已经被切成小积木的乐高贴标签的过程)
假设原始数据如下:
| 原始 tokens(已分词) | ner_tags(标签) |
|---|---|
| [“我”, “去”, “北京”] | [O, O, B-LOC] |
-
O表示“不是实体” -
B-LOC表示“地点实体的开头”
# 借助word_ids 实现标签映射
def process_function(examples):tokenized_exmaples = tokenizer(examples["tokens"], max_length=128, truncation=True, is_split_into_words=True)labels = []# 遍历这个标签for i, label in enumerate(examples["ner_tags"]):# word_ids() 返回 [None, 0, 1, 2, 2, None],0 → 原词列表第 0 个词“我”,2 → 原词列表第 2 个词“北京”(被拆成两块积木,都标 2)word_ids = tokenized_exmaples.word_ids(batch_index=i)label_ids = []for word_id in word_ids: # 逐块积木if word_id is None: # [CLS]、[SEP]、PADlabel_ids.append(-100)else:# word_id=0 → 原词0 → label[0]=O# word_id=1 → 原词1 → label[1]=O# word_id=2 → 原词2 → label[2]=B-LOClabel_ids.append(label[word_id])# 执行上述循环后,label_ids = [-100, O, O, B-LOC, B-LOC, -100],实际代码里 O 和 B-LOC 会被替换成数字 id,如 0 和 1labels.append(label_ids)tokenized_exmaples["labels"] = labelsreturn tokenized_exmaplestokenized_datasets = ner_datasets.map(process_function, batched=True)
tokenized_datasets
print(tokenized_datasets["train"][0])
创建评估函数
-
predictions:模型猜的 数字标签 id(一排排学号)
-
labels:真正的 数字标签 id(一排排正确答案学号)
-
label_list:把数字翻译成文字标签的小词典
例:label_list = [“O”, “B-PER”, “I-PER”, “B-LOC”, “I-LOC”]- 其中这个
[label_list[p] for p, l in zip(prediction, label) if l != -100] -
- 取一对
(p, l) - 如果
l不是 -100(不是特殊符号) - 就把
p转成文字标签label_list[p]存进列表
- 取一对
- 其中这个
# seqeval 是专门给序列标注任务打分的裁判,支持 BIO / IOB2 等格式。
seqeval = evaluate.load("seqeval_metric.py")
seqevalimport numpy as np
def eval_metric(pred):predictions, labels = predpredictions = np.argmax(predictions, axis=-1) #每个位置取分数最高的索引,得到“预测标签 id”。# 将id转换为原始的字符串类型的标签true_predictions = [[label_list[p] for p, l in zip(prediction, label) if l != -100]for prediction, label in zip(predictions, labels) ]true_labels = [[label_list[l] for p, l in zip(prediction, label) if l != -100]for prediction, label in zip(predictions, labels) ]result = seqeval.compute(predictions=true_predictions, references=true_labels, mode="strict", scheme="IOB2")return {"f1": result["overall_f1"]}
创建训练器
args = TrainingArguments(output_dir="models_for_ner",per_device_train_batch_size=64,per_device_eval_batch_size=128,eval_strategy="epoch",save_strategy="epoch",metric_for_best_model="f1",load_best_model_at_end=True,logging_steps=50,num_train_epochs=1
)trainer = Trainer(model=model,args=args,tokenizer=tokenizer,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["validation"],compute_metrics=eval_metric,data_collator=DataCollatorForTokenClassification(tokenizer=tokenizer)
)
模型训练
trainer.train()
trainer.evaluate(eval_dataset=tokenized_datasets["test"])
模型预测
from transformers import pipeline# 使用pipeline进行推理,要指定id2label
model.config.id2label = {idx: label for idx, label in enumerate(label_list)}
model.config# 如果模型是基于GPU训练的,那么推理时要指定device
# 对于NER任务,可以指定aggregation_strategy为simple,得到具体的实体的结果,而不是token的结果
ner_pipe = pipeline("token-classification", model=model, tokenizer=tokenizer, device=0, aggregation_strategy="simple")res = ner_pipe("小明在北京上班")
res# 根据start和end取实际的结果
ner_result = {}
x = "小明在北京上班"
for r in res:if r["entity_group"] not in ner_result:ner_result[r["entity_group"]] = []ner_result[r["entity_group"]].append(x[r["start"]: r["end"]])ner_result
后续
后续博主讲的课还包括机器阅读理解,多项选择,文本相似度,检索机器人,文本摘要,生成对话机器人等实战演练课程。由于我没有做这些实验的需求,后续的实验演练课程笔记就不再做了。
我只通过这个命名实体的识别来了解这个Transformer模型实验的大致流程即可。后续如果有这些方面的实验需要去做,可以通过继续学习相关视频知识
Flink的机制)
)
http参数过滤)


:SPI(串行外设接口))
)
)





)
适配CmBacktrace错误追踪)




