前言:
1.训练在windows进行,因为电脑没有显卡,所以纯cpu训练,生成pt后转onnx
2.onnx转需要在Ubuntu虚拟机上运行
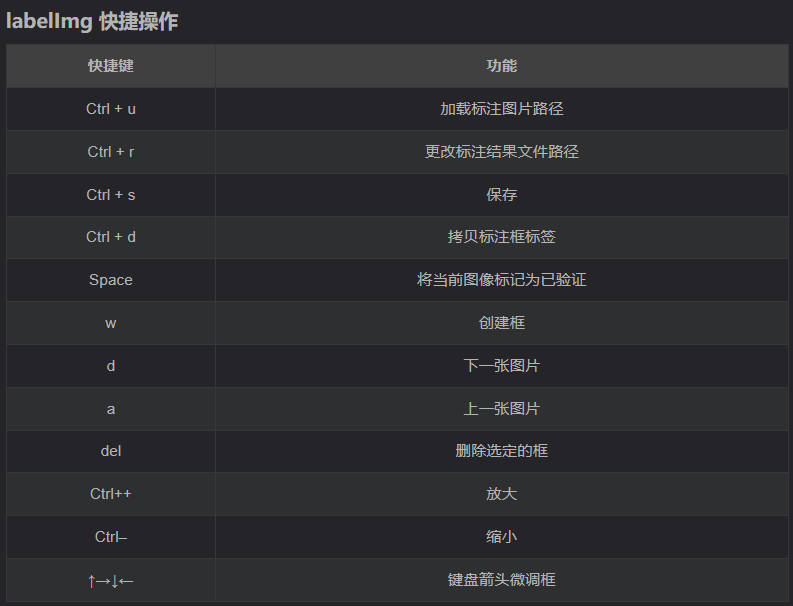
3.数据集标定快捷键
(模型训练时不需要)官方地址和下载pt权重:链接:https://github.com/ultralytics/ultralytics/tree/v8.0.4?tab=readme-ov-file
必须要下载模型,在源码页面找到模型点击下载,推荐下载yolov8n.pt
环境配置
参考链接:(32 封私信 / 80 条消息) yolov8环境配置加训练自己的数据集保姆级教程(2024) - 知乎
yolov8训练自己的目标检测数据集详细介绍版-腾讯云开发者社区-腾讯云
1.安装anaconda Index of /archive
打开anaconda prompt(管理员运行)
conda create -n yolov8 python=3.8 -y 创建环境,建议3.8
conda activate yolov8 激活环境
conda deactivate 退出环境
conda env remove --name yolov8
conda remove --name yolov8 --all 删除环境然后安装pytorch如果安装GPU版本可以用下面命令:pip install torch2.0.0+cu118 torchvision0.15.1+cu118 --extra-index-url https://download.pytorch.org/whl/cu118如果安装CPU版本pytorch可以用下面命令:conda install pytorch torchvision torchaudio cpuonly -c pytorch安装yolov8:pip install ultralytics测试 下载yolov8n.pt和随机图片yolo predict model=yolov8n.pt source=test.jpgpip install labelimg //安装labelimg,会自动安装pyqt5,或者在pycharm命令行安装和打开labelimg制作自己的数据集(本人是训练航空发动机划痕和缺陷)
1.新建文件夹
在data文件夹里面新建一个datasets再在里面新建四个文件夹分别是
Annotations(存放xml的文件夹)
images(用来存放原始的需要训练的数据集图片,图片格式为jpg格式)
ImageSets(用来存放将数据集划分后的用于训练、验证、测试的文件)
labels(存放yolo转换的txt文件)。
我用了两个分类
scratch (划痕)
fracture 断裂
使用说明:
(1)Open Dir就是打开需要标注的图片的文件夹,这里就选择images文件夹
(2)change save dir就是标注后保存标记文件的位置,选择需要保存标注信息的文件夹,这里就选择Annotations文件夹
(3)特别注意需要选择好所需要的标注文件的类型。有yolo(txt), pascalVOC (xml)两种类型。yolo需要txt文件格式的标注文件,但是这里我们选择pascalVOC,后面再将xml格式的标注文件转化为所需的txt格式。
(4)按W键或点击Create\nRectBox开始创建矩形框,把要进行识别训练的区域标记出来就行,选好框后我们选是什么类别(predefined_classes文件,在里面提前写好要训练的类型的原因),整张图片的所有目标都标记好了之后按Ctrl+S或点击Save保存 ,然后切换下一张继续,快捷键为按D键,每一张图片标记后都要保存,这个过程是一个比较繁琐的过程
2.标注
如何预设标签
1.找到anaconda安装的根目录:D:\anaconda
2.进入路径D:\anaconda\Lib\site-packages\labelImg
注意如果你安装其他环境需要对应自己环境,比如我的是py38环境里面则需进去D:\anaconda3\envs\yolov8\Lib\site-packages\labelImg。
3.在此路径里面创建data文件夹,并将自己的predefined_classes.txt文件放入到data文件夹中。
labelImg如何设置多个预设标签
labelImg如何设置多个预设标签_51CTO博客_labelimg标签怎么设置
划分数据集进行训练
博主建议将脚本放在ultralytics文件夹的同级下(我第一次操作没有放到同级目录,一样没问题)
因为在YOLOv8的项目中,存在一个ultralytics文件夹,而我们在配置环境的时候,又有名为ultralytics的环境包,二者存在歧义,导致我们在ultralytics文件夹中进行参数修改后却不生效的情况,(这时如果仍要通过命令行进行训练,必须要在环境配置文件中进行相应修改),比如更改激活函数后,发现得到的PT模型仍为最初的SiLU激活函数,这是因为命令行会优先调用环境配置文件中的参数,所以在ultralytics文件夹中修改激活函数后并不会生效(博主自己踩坑,请大家避免)。
3.最重要的一点:要改激活函数为ReLU(问deepseek说可以不用改,我也没改),
改激活函数流程如下:把ultralytics/nn/modules/conv.py中的Conv类进行修改,将
default_act = nn.SiLU() # default activation改为
default_act = nn.ReLU() # default activation
对数据集进行划分
import os
import shutil
import randomdef make_yolo_dataset(images_folder, labels_folder, output_folder, train_ratio=0.8):# 创建目标文件夹images_train_folder = os.path.join(output_folder, 'images/train')images_val_folder = os.path.join(output_folder, 'images/val')labels_train_folder = os.path.join(output_folder, 'labels/train')labels_val_folder = os.path.join(output_folder, 'labels/val')os.makedirs(images_train_folder, exist_ok=True)os.makedirs(images_val_folder, exist_ok=True)os.makedirs(labels_train_folder, exist_ok=True)os.makedirs(labels_val_folder, exist_ok=True)# 获取图片和标签的文件名(不包含扩展名)image_files = [f for f in os.listdir(images_folder) if f.endswith('.jpg')]label_files = [f for f in os.listdir(labels_folder) if f.endswith('.txt')]image_base_names = set(os.path.splitext(f)[0] for f in image_files)label_base_names = set(os.path.splitext(f)[0] for f in label_files)# 找出图片和标签都存在的文件名matched_files = list(image_base_names & label_base_names)# 打乱顺序并划分为训练集和验证集random.shuffle(matched_files)split_idx = int(len(matched_files) * train_ratio)train_files = matched_files[:split_idx]val_files = matched_files[split_idx:]# 移动文件到对应文件夹for base_name in train_files:img_src = os.path.join(images_folder, f"{base_name}.jpg")lbl_src = os.path.join(labels_folder, f"{base_name}.txt")img_dst = os.path.join(images_train_folder, f"{base_name}.jpg")lbl_dst = os.path.join(labels_train_folder, f"{base_name}.txt")shutil.copyfile(img_src, img_dst)shutil.copyfile(lbl_src, lbl_dst)for base_name in val_files:img_src = os.path.join(images_folder, f"{base_name}.jpg")lbl_src = os.path.join(labels_folder, f"{base_name}.txt")img_dst = os.path.join(images_val_folder, f"{base_name}.jpg")lbl_dst = os.path.join(labels_val_folder, f"{base_name}.txt")shutil.copyfile(img_src, img_dst)shutil.copyfile(lbl_src, lbl_dst)print("数据集划分完成!")# 使用示例
images_folder = r'E:\Projects\ultralytics_yolov8-main\data\images' # 原始图片文件夹路径
labels_folder = r'E:\Projects\ultralytics_yolov8-main\data\Annotations' # 原始标签文件夹路径
output_folder = r'E:\Projects\ultralytics_yolov8-main\data\ImageSets' # 存放结果数据集的文件夹路径
make_yolo_dataset(images_folder, labels_folder, output_folder)开始训练模型
在yolov8根目录下(也就是官方源码的ultralytics-main目录下)创建一个新的data.yaml文件,也可以是其他名字的例如mydata.yaml文件,文件名可以变但是后缀需要为.yaml,内容如下
train: E:\Projects\ultralytics_yolov8-main\data\ImageSets\images\train # train images (relative to 'path') 128 images
val: E:\Projects\ultralytics_yolov8-main\data\ImageSets\images\val # val images (relative to 'path') 128 images
test: E:\Projects\ultralytics_yolov8-main\data\ImageSets\images\testnc: 2# Classes
names: ['scratch','fracture']训练模型
这是使用官方提供的预训练权重进行训练,使用yolov8n.pt,也可以使用yolov8s.pt,模型大小n
新建个train.py文件
from ultralytics import YOLO
#多线程添加代码
if __name__ == '__main__': model = YOLO('yolov8n.yaml').load('yolov8n.pt')# # 训练模型 GPU#results = model.train(data='data.yaml', epochs=100, imgsz=640, device=0, workers=2, batch=16, optimizer='SGD', amp=False)# 训练模型 CPUresults = model.train(data='data.yaml', epochs=100, imgsz=640, device='cpu', workers=2, batch=16, optimizer='SGD',amp=False)epochs是训练轮数,可以由少变多看训练效果,workers和batch根据电脑性能来,如果运行不起来则相应降低,最好为2的n次方。
也可以使用命令行执行训练 yolo task=detect mode=train model=yolov8n.yaml pretrained=yolov8n.pt data=data.yaml epochs=100 imgsz=640 device=0 workers=2 batch=16 训练完成后会在源码目录runs里面有模型生成,可以进去weights文件夹找到best.pt或者last.pt模型
查看模型激活函数方法如下所示:
from ultralytics import YOLO# 加载自定义训练的模型
model = YOLO("runs/detect/train/weights/best.pt")# 打印模型结构(查找激活函数)
print(model.model)首先罗列一下官网提供的全部参数:Model Training with Ultralytics YOLO - Ultralytics YOLO Docs
一些比较常用的传参:
| key | 解释 |
| model | 传入的model.yaml文件或者model.pt文件,用于构建网络和初始化,不同点在于只传入yaml文件的话参数会随机初始化 |
| data | 训练数据集的配置yaml文件 |
| epochs | 训练轮次,默认100 |
| patience | 早停训练观察的轮次,默认50,如果50轮没有精度提升,模型会直接停止训练 |
| batch | 训练批次,默认16 |
| imgsz | 训练图片大小,默认640 |
| save | 保存训练过程和训练权重,默认开启 |
| save_period | 训练过程中每x个轮次保存一次训练模型,默认-1(不开启) |
| cache | 是否采用ram进行数据载入,设置True会加快训练速度,但是这个参数非常吃内存,一般服务器才会设置 |
| device | 要运行的设备,即cuda device =0或Device =0,1,2,3或device = cpu |
| workers | 载入数据的线程数。windows一般为4,服务器可以大点,windows上这个参数可能会导致线程报错,发现有关线程报错,可以尝试减少这个参数,这个参数默认为8,大部分都是需要减少的 |
| project | 项目文件夹的名,默认为runs |
| name | 用于保存训练文件夹名,默认exp,依次累加 |
| exist_ok | 是否覆盖现有保存文件夹,默认Flase |
| pretrained | 是否加载预训练权重,默认Flase |
| optimizer | 优化器选择,默认SGD,可选[SGD、Adam、AdamW、RMSProP] |
| verbose | 是否打印详细输出 |
| seed | 随机种子,用于复现模型,默认0 |
| deterministic | 设置为True,保证实验的可复现性 |
| single_cls | 将多类数据训练为单类,把所有数据当作单类训练,默认Flase |
| image_weights | 使用加权图像选择进行训练,默认Flase |
| rect | 使用矩形训练,和矩形推理同理,默认False |
| cos_lr | 使用余弦学习率调度,默认Flase |
| close_mosaic | 最后x个轮次禁用马赛克增强,默认10 |
| resume | 断点训练,默认Flase |
| lr0 | 初始化学习率,默认0.01 |
| lrf | 最终学习率,默认0.01 |
| label_smoothing | 标签平滑参数,默认0.0 |
| dropout | 使用dropout正则化(仅对训练进行分类),默认0.0 |
模型测试
找到之前训练的结果保存路径,创建一个predict.py文件,内容如下
from ultralytics import YOLO
# 加载训练好的模型,改为自己的路径
model = YOLO('runs/detect/train/weights/best.pt')
# 修改为自己的图像或者文件夹的路径
source = 'test.jpg' #修改为自己的图片路径及文件名
# 运行推理,并附加参数
model.predict(source, save=True)模型转换
参考链接:【YOLOv8部署至RK3588】模型训练→转换RKNN→开发板部署_yolov8转rknn-CSDN博客
需要以下工具:ultralytics_yolov8、rknn_model_zoo、rknn-toolkit2,现在详细介绍这三者的关系。
以上三个文件均与模型训练无关,而是用于模型转换的,其中,ultralytics_yolov8文件不是必需的,但最好还是下载一份,原因后面会讲;在此,先将以上三个文件的链接放在这:
ultralytics_yolov8:https://github.com/airockchip/ultralytics_yolov8
rknn_model_zoo:https://github.com/airockchip/rknn_model_zoo
rknn-toolkit2:https://github.com/airockchip/rknn-toolkit2
另外说一下这三个文件的版本,全用最新的,rknn_model_zoo用v2.3.2,rknn-toolkit2也用v2.3.2,ultralytics_yolov8只有一个main版本,直接用即可
转换步骤:
1.修改ultralytics_yolov8项目中的ultralytics/cfg/default.yaml,将其中的model参数路径改成你训练得到的的best.pt模型路径
在虚拟环境下,装转换需要的环境
cd ultralytics-main
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -e .
pip install onnx新建一个脚本文件:运行后会在 runs\detect\train\weights下生成best.onnx文件
#这里好像是后期转换rknn,需要导出这样的
from ultralytics import YOLO# Load a model
model = YOLO(r'E:\Projects\ultralytics_yolov8-main\data\runs\detect\train\weights\best.pt')
# Export the model
model.export(format='rknn',opset=12)#后期直接用onnx,好像用下面的
from ultralytics import YOLO# Load a model
model = YOLO(r'E:\Projects\ultralytics_yolov8-main\data\runs\detect\train\weights\best.pt')# 2. 导出为 ONNX
model.export(format="onnx", opset=12, dynamic=False, simplify=True, imgsz=640)
print("ONNX 模型导出完成!")同时生成onnx文件,这样生成的模型output是4维的,后面可以直接转换成rknn。
如果不在rk3588上用,只用onnx文件,之前测试和使用的模型是output都是三维的,所以上面的代码是可以生成两种不同的额模型
onnx转rknn需要再Ubuntu虚拟机下转换,篇幅限制,下节再讲
?/替换模型,一般除了注意输入输出一致,还有其他要修改的吗?)



:解密 SPI—— 从定义到核心特性)



)







)


