研究背景与动机
- 问题:传统目标检测器(封闭集)需预定义所有类别,无法适应动态开放环境。现有研究多独立解决开放词汇检测(OVD)或开放世界检测(OWOD),未结合两者优势:
- OVD:通过文本-视觉嵌入匹配实现零样本泛化,但无法主动发现未知对象。
- OWOD:可主动检测未知对象并通过增量学习逐步优化,但缺乏零样本能力。
- 目标:提出统一框架 OW-OVD,兼具OVD的零样本泛化能力和OWOD的主动发现与持续学习能力。

核心方法
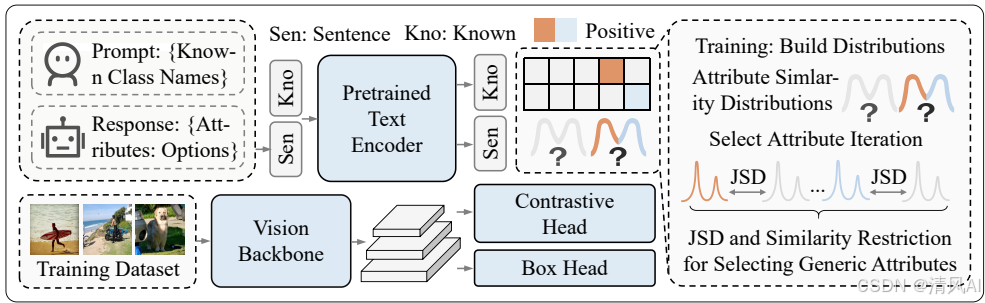
1. 模型架构
- 基于标准OVD检测器(YOLO-World),包含视觉编码器(提取图像特征)和文本编码器(生成类别/属性嵌入)。
- 训练流程分两步:
- 分布构建:计算属性与正/负样本区域的相似性分布。
- 属性选择:通过迭代选择最具泛化性的属性。


)







)








