当我们谈论数据库索引时,选择合适的数据结构至关重要。不同的数据结构在性能、复杂度以及适用场景上都有所不同。本文将通过对比二叉树、红黑树和B树,探讨它们如何影响数据库索引的表现。
一、二叉树
特性
- 定义:每个节点最多有两个子节点。
- 应用场景:适合于小规模或静态数据集的快速查找。
缺点
如果使用自增ID作为索引键值构建二叉查找树(BST),随着数据量的增长,特别是当插入顺序是递增或递减时,这棵树会退化成链表形式。在这种情况下,查找效率会降至O(n),并且每次查找都会触发一次磁盘IO操作,这对于大型数据库来说是非常不利的。
二、红黑树
特性
- 定义:红黑树是一种自平衡二叉搜索树,通过特定规则保持树的近似平衡,确保最坏情况下的时间复杂度为O(log n)。
- 优点:即使在频繁更新的情况下也能维持较高的查找效率。
局限性
尽管红黑树解决了二叉查找树可能退化的问题,但由于其本质仍然是二叉树,在大数据量下树的高度仍然较高,导致查询路径较长。此外,维护平衡状态需要额外的操作,增加了实现的复杂性。
三、B树 :面向磁盘优化的多路搜索树 📊
引入原因
为了克服上述两种树形结构的局限性,特别是在处理大规模数据时减少磁盘访问次数的需求,B树被设计出来。它允许每个节点存储多个关键字,并拥有多个子节点,从而有效地降低了树的高度。
特性
- 定义:B树是一种多路搜索树,特别适用于读写相对较大的数据块,如磁盘存储。
- 优点:通过扩展节点的宽度而非深度,显著减少了查找路径长度,提高了整体性能。
- 缺点:虽然B树有更宽的横轴(即每页可以存储更多的索引),但由于每页同时存储了数据和索引,因此一页能存储的数据量不如专门用于存储索引的页多。
四、B+树 :进一步优化以适应数据库需求
B+树的优势
- 定义:B+树是B树的一种变体,所有数据记录都存储在叶子节点中,非叶子节点仅存储索引信息。
- 优点:
- 更高的扇出:由于非叶子节点只存储索引,因此可以存储更多的索引信息,进一步降低树的高度。
- 更适合范围查询:所有叶子节点【终端节点】通过双向链表相连,使得范围查询变得非常高效。
- 更好的磁盘利用:非叶子节点仅存储索引,这意味着每页可以容纳更多的索引条目,从而减少磁盘I/O操作次数。
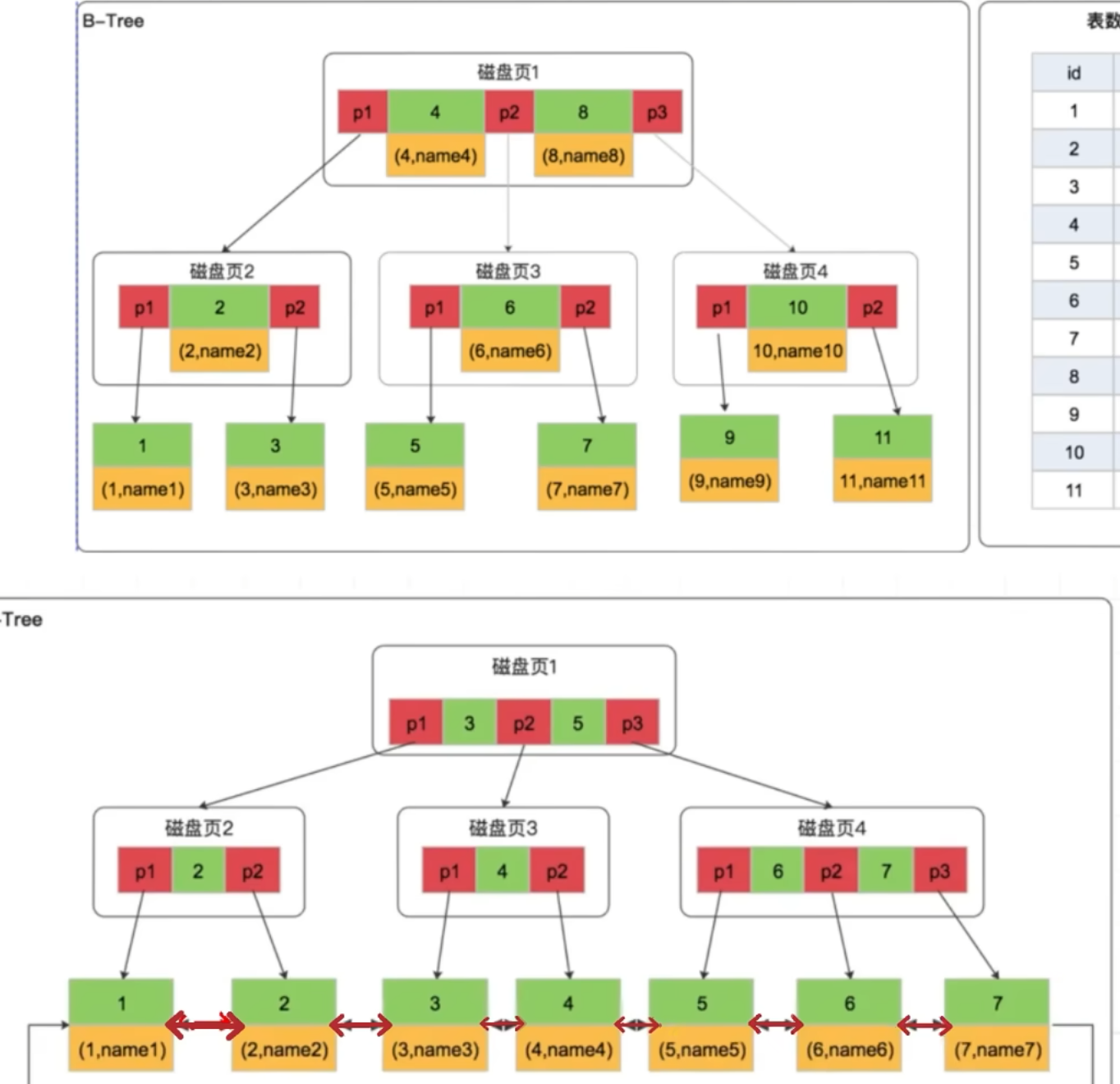
B+树在索引中的应用
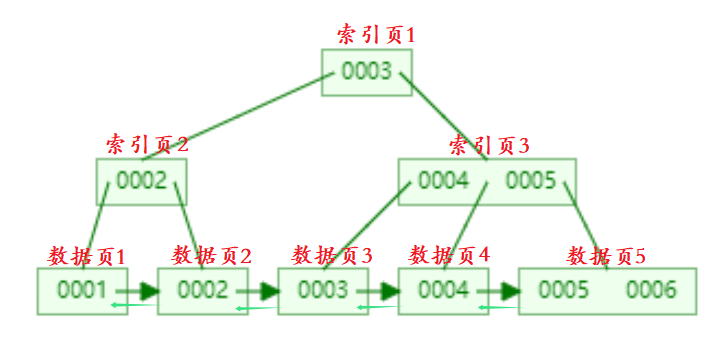
查找4为例:
- 判断B+树根节点的索引记录,3<4,那么访问右子树,到索引页3;
- 在索引页3中判断id大小,找到与4相同的索引记录,最后加载对应的数据页。


![微积分[4]|高等数学发展简史(两万字长文)](http://pic.xiahunao.cn/微积分[4]|高等数学发展简史(两万字长文))




自定义生物群系)
如何设置环境变量)






 -- 核心模块篇)



