文章目录
- 前言
- 一、简介
- struct folio
- 二、page folios的好处
- 2.1 compound page
- 2.2 page cache
- 三、buffer_head、iomap与page folios
- 四、何时分配 Large Folio
- 五、folio结构体演变
- 六、内核主线folio的逐步使用
- 参考资料
前言
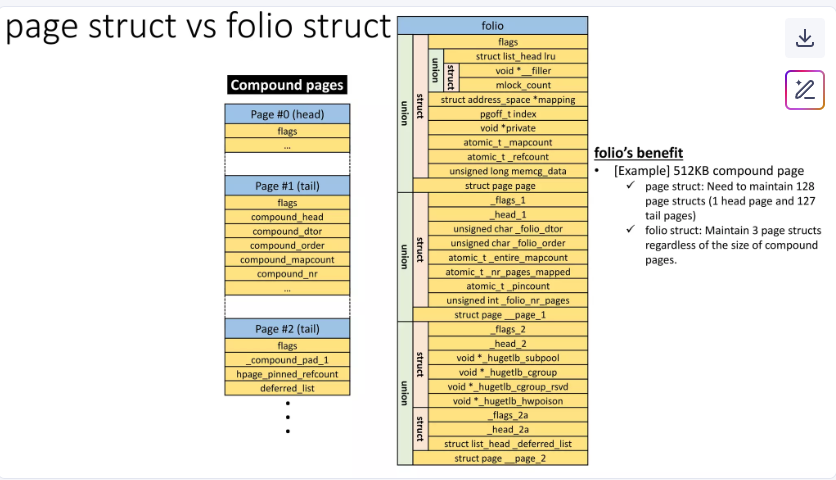
Linux 内核的内存管理子系统以“页”(page)为单位处理内存,这是一个由硬件决定的基本单位(通常为 4KB)。然而,这些“基础页”很小,因此内核经常需要以更大的单位处理内存。为此,它将一组物理上连续的页组合成“复合页”(compound pages),由一个“头页”(head page,即复合页中的第一个基础页)和若干“尾页”(tail pages)组成。这就导致一个情况:当内核代码接收到一个 struct page 指针时,通常无法知道它处理的是头页还是尾页,除非显式检查。
对于page: 4KB页的局限性
早期Linux内核在内存以兆字节(MB)计的系统上运行,使用4KB页是合理的。
如今,系统内存已达数十甚至上百GB,但4KB页大小基本未变。
后果:
内核需管理的页面数量剧增。
花费更多内存存储页表项(page table entries)。
链表更长,扫描开销更大。
缺页中断(page fault)次数显著增加。
事实证明,这种“确保这是头页”的检查在运行的内核中累积起来会带来一定的开销。struct page 的普遍使用也使得内核 API 不够清晰——很难知道某个给定函数是否能处理尾页。为了解决这个问题,内核开发人员 提出了“folio”(页片段)的概念,它类似于 struct page,但已知不是尾页。通过将内部函数改为使用 page folios。
在 Linux 5.16.0 内核版本发布中,引入了一种新的概念——page folios。page folios与复合页类似,但具有更清晰、更合理的语义设计。通过在内核的一些核心部分使用页片段,常见工作负载下的性能得到了提升。
本次发布包含了page folios的核心基础设施,并已将内核内存管理子系统和页缓存(page cache)的部分功能迁移到新机制上。未来的内核版本将进一步把一些文件系统改造为支持page folios,并引入支持多页的page folios功能,从而进一步提升系统性能和可维护性。
folio 是由 struct folio 表示的;它本质上是一个 compound page 的 head page 的别名。
在 Linux 5.16.0 内核版本发布中,当前只有readahead代码会进行大页(large folio)的分配,而文件系统的写路径仍然以基础页(base page)为单位进行。如果要对通过 readahead 得到的 folio 进行写入,会看到并使用这些 folio。不过,对文件的追加(append)将总是使用 base page。
一、简介
内存管理通常以“页”(page)为基本单位进行操作,每页通常包含 4,096 字节(即 4KB),但也可能更大。然而,内核已经扩展了“页”的概念,引入了“复合页”(compound pages),即一组连续的普通页。这种扩展使得“页”这一概念的定义变得有些模糊。

为此,Linux内核引入一个名为 page folios的新概念,旨在重新厘清内存管理中的这一混乱局面。
在最底层,页的概念是由硬件实现的。内存的跟踪管理——例如判断某块内存是否存在于物理内存(RAM)中——都是以页为粒度进行的。每种 CPU 架构可能支持有限的几种页大小,但必须选择一个“基础”页大小,而最普遍的选择仍是 4,096 字节——这与 30 年前第一个 Linux 内核发布时所采用的大小完全相同。
然而,内核常常需要以更大的内存块来操作。一个典型的例子是“大页”(huge pages)的管理,这类功能由硬件直接支持。例如,x86 架构可以支持 2MB 的大页,在合适场景下使用大页能带来显著的性能优势。
此外,内核还会在其他情况下分配多个连续的页,通常用于 DMA 缓冲区或其他需要物理上连续内存的场景。这种将多个页组合在一起的机制,在内核中被称为“复合页”(compound page)。虽然复合页解决了大块连续内存的管理问题,但其复杂的实现和模糊的接口也带来了维护和使用上的困难,这正是“page folios”试图改进的地方。
在 Linux 内核中,每一个被管理的基础内存页(base page)都在系统的内存映射(memory map)中对应一个 struct page 结构。当一组基础页被组合成一个“复合页”(compound page)时,这组页中的第一个页(称为“头页”或 head page)的 struct page 会被特别标记,以明确表示它是一个复合页的起始页。该头页结构中的元数据描述的是整个复合页的信息。
其余的页(称为“尾页”或 tail pages)也会被标记为尾页,并且它们的 struct page 结构中包含一个指向对应头页结构的指针。多关于复合页组织方式的细节,可以参考相关技术文章:Linux内存管理之 compound pages
这种机制使得从一个尾页的结构快速定位到其所属复合页的头页变得非常容易。内核中的许多接口都利用了这一特性。然而,这也带来了一个根本性的模糊问题:如果一个函数接收了一个指向尾页 struct page 的指针,它到底应该对该尾页本身进行操作,还是应该对整个复合页进行操作?
函数接收 struct page 参数时,无法从类型区分其应操作 单个页 还是 整个复合页。*
正如 Matthew Wilcox 在 2020 年 12 月首次提出 page folio 系列补丁时所指出的:
一个接受 struct page 指针作为参数的函数,可能:
只接受头页或基础页,如果传入尾页就会触发 BUG;
能处理任意类型的页,但只操作 PAGE_SIZE(4KB)大小的数据;
如果传入的是头页,则操作 page_size()(可能是 2MB 等复合页大小)字节;但如果传入的是基础页或尾页,则只操作 PAGE_SIZE 字节;
无论传入的是头页还是尾页,都操作 page_size() 字节大小的数据。
而现实中,以上所有情况都存在。(其中 PAGE_SIZE 是基础页大小,而 page_size(page) 函数返回的是一个页——可能是复合页——的实际总大小。)
虽然目前尚未有大量已知的严重 bug 直接源于这一模糊的 API,但一个如此不清晰的接口设计,迟早可能导致问题。
为了解决这一混乱局面,Wilcox 提出了 page folio 的概念。所谓 page folio ,本质上就是一个保证不是尾页的 struct page 结构。任何接受 page folio 作为参数的函数,都可以明确地对整个页单元(即完整的复合页或单个页)进行操作,而不会产生歧义。随着内核函数逐步迁移到使用 page folio 作为参数,其语义将变得更加清晰:这类函数不应对尾页进行操作。
在 Wilcox 首次提交该补丁系列时,他还强调了另一个重要优势:性能和代码体积的优化。
任何可能接收到尾页指针、但又需要操作整个复合页的函数,通常必须先将尾页指针转换为头页指针,这通常通过调用如下函数实现:
struct page *compound_head(struct page *page);
这个函数本身开销不大(通常是内联函数),但在一次页面操作中可能被频繁调用多次。这不仅增加了内核代码体积(因为是内联展开),也累积了运行时开销。
而如果函数直接接收的是 page folio,那么它天然知道传入的不是尾页,因此完全不需要调用 compound_head()。这直接省去了大量的指针转换操作,从而节省了执行时间和内存占用。
page folio 的引入,不仅提升了内核内存管理接口的语义清晰度和安全性,还通过消除不必要的头页查找调用,带来了实际的性能和代码精简收益,是 Linux 内核内存管理子系统迈向更健壮、高效架构的重要一步。
struct folio
Linux 5.16 内核 page folio 本身被定义为一个简单的封装结构,把一些page里面常用字段,提取到了和page同等位置的union里面:
// v5.16/source/include/linux/mm_types.h/*** struct folio - Represents a contiguous set of bytes.* @flags: Identical to the page flags.* @lru: Least Recently Used list; tracks how recently this folio was used.* @mapping: The file this page belongs to, or refers to the anon_vma for* anonymous memory.* @index: Offset within the file, in units of pages. For anonymous memory,* this is the index from the beginning of the mmap.* @private: Filesystem per-folio data (see folio_attach_private()).* Used for swp_entry_t if folio_test_swapcache().* @_mapcount: Do not access this member directly. Use folio_mapcount() to* find out how many times this folio is mapped by userspace.* @_refcount: Do not access this member directly. Use folio_ref_count()* to find how many references there are to this folio.* @memcg_data: Memory Control Group data.** A folio is a physically, virtually and logically contiguous set* of bytes. It is a power-of-two in size, and it is aligned to that* same power-of-two. It is at least as large as %PAGE_SIZE. If it is* in the page cache, it is at a file offset which is a multiple of that* power-of-two. It may be mapped into userspace at an address which is* at an arbitrary page offset, but its kernel virtual address is aligned* to its size.*/
struct folio {/* private: don't document the anon union */union {struct {/* public: */unsigned long flags;struct list_head lru;struct address_space *mapping;pgoff_t index;void *private;atomic_t _mapcount;atomic_t _refcount;
#ifdef CONFIG_MEMCGunsigned long memcg_data;
#endif/* private: the union with struct page is transitional */};struct page page;};
};
// v5.16/source/include/linux/mm_types.hstruct page {unsigned long flags; /* Atomic flags, some possibly* updated asynchronously *//** Five words (20/40 bytes) are available in this union.* WARNING: bit 0 of the first word is used for PageTail(). That* means the other users of this union MUST NOT use the bit to* avoid collision and false-positive PageTail().*/union {struct { /* Page cache and anonymous pages *//*** @lru: Pageout list, eg. active_list protected by* lruvec->lru_lock. Sometimes used as a generic list* by the page owner.*/struct list_head lru;/* See page-flags.h for PAGE_MAPPING_FLAGS */struct address_space *mapping;pgoff_t index; /* Our offset within mapping. *//*** @private: Mapping-private opaque data.* Usually used for buffer_heads if PagePrivate.* Used for swp_entry_t if PageSwapCache.* Indicates order in the buddy system if PageBuddy.*/unsigned long private;};......
在这个基础之上,构建了一整套新的基础设施。例如,get_folio() 和 put_folio() 函数将像 get_page() 和 put_page() 一样管理对页片段的引用计数,但无需再调用 compound_head() 来处理尾页转换问题。在此基础上,还衍生出一系列更高层次的操作函数。
page folios带来的问题:
(1)迁移成本比较大,将内核中各个子系统逐步迁移到这一新类型上,将触及每一个文件系统,以及大量的设备驱动程序,将是一项巨大的工作。
(2)page 与 folio 类型将长期共存,代码中到处都是两者之间相互转换的代码。还要持续不断地添加新的 folio 操作接口,叠加在已有的 page 接口之上等等。
好处:
(1)“这种抽象对文件系统开发者来说是绝对必要的”,特别是当页缓存未来需要支持多种尺寸的复合页时。比如:文件系统(如 XFS)需要统一接口处理 多尺寸复合页。
(2)struct folio 提供更清晰的接口,避免头页/尾页的歧义。引入 struct folio 类型,仅表示 Head Page(或单页),彻底消除 Tail Page 的歧义。
(3)消除 compound_head() 开销:传统复合页操作需频繁调用 compound_head() 检查并转换 Tail Page,Folio 直接保证无 Tail Page,省去冗余检查。
在内核里面内核模块里面,很多内核函数传递进来的 page 参数总是需要判断是 head page 还是 tail page。由于没有上下文缓存,mm 路径上可能会存在太多重复的 compound_head 调用。
比如page_mapping:
// v5.15/source/mm/util.cstruct address_space *page_mapping(struct page *page)
{struct address_space *mapping;page = compound_head(page);/* This happens if someone calls flush_dcache_page on slab page */if (unlikely(PageSlab(page)))return NULL;if (unlikely(PageSwapCache(page))) {swp_entry_t entry;entry.val = page_private(page);return swap_address_space(entry);}mapping = page->mapping;if ((unsigned long)mapping & PAGE_MAPPING_ANON)return NULL;return (void *)((unsigned long)mapping & ~PAGE_MAPPING_FLAGS);
}
EXPORT_SYMBOL(page_mapping);
该函数需要先调用 compound_head(page) 判断是否为 tail page,再获取 mapping。
当切换到 folio 之后,page_mapping(page) 对应 folio_mapping(folio) ,而 folio 隐含着 folio 本身就是 head page,因此 compound_head(page) 的调用就省略了。
// v5.16/source/mm/util.c/*** folio_mapping - Find the mapping where this folio is stored.* @folio: The folio.** For folios which are in the page cache, return the mapping that this* page belongs to. Folios in the swap cache return the swap mapping* this page is stored in (which is different from the mapping for the* swap file or swap device where the data is stored).** You can call this for folios which aren't in the swap cache or page* cache and it will return NULL.*/
struct address_space *folio_mapping(struct folio *folio)
{struct address_space *mapping;/* This happens if someone calls flush_dcache_page on slab page */if (unlikely(folio_test_slab(folio)))return NULL;if (unlikely(folio_test_swapcache(folio)))return swap_address_space(folio_swap_entry(folio));mapping = folio->mapping;if ((unsigned long)mapping & PAGE_MAPPING_ANON)return NULL;return (void *)((unsigned long)mapping & ~PAGE_MAPPING_FLAGS);
}
EXPORT_SYMBOL(folio_mapping);
由于 folio 保证不是 tail page,因此无需 compound_head(),可直接访问。
mm 路径上到处是 compound_head 的调用。积少成多,不仅执行开销减少了,开发者也能得到提示,当前 folio 一定是 head page,减少判断分支。
二、page folios的好处
2.1 compound page
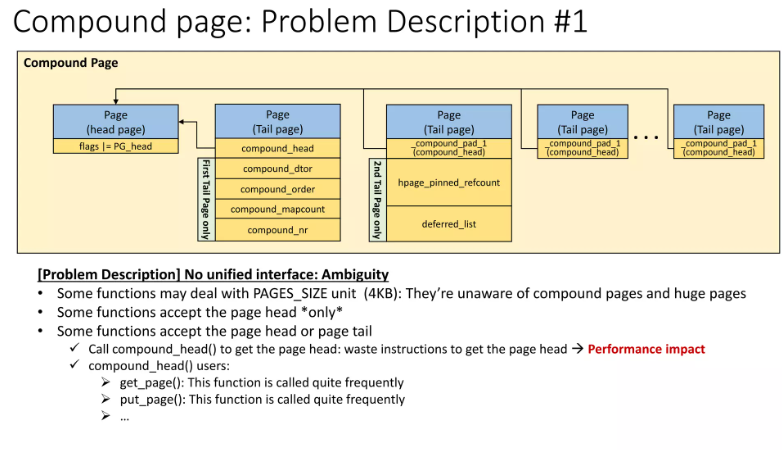
复合页包含头页(Head Page)和尾页(Tail Pages),尾页需要额外的 compound_head() 调用以定位头页,增加运行时开销。
任何可能接收到尾页指针、但又需要操作整个复合页的函数,通常必须先将尾页指针转换为头页指针,这通常通过调用如下函数实现:
struct page *compound_head(struct page *page);
这个函数本身开销不大(通常是内联函数),但在一次页面操作中可能被频繁调用多次。这不仅增加了内核代码体积(因为是内联展开),也累积了运行时开销。
Folio 的改进:
保证不包含尾页:struct folio 仅代表完整的内存单元(头页或单页),无需处理尾页的查找。
而如果函数直接接收的是 page folio,那么它天然知道传入的不是尾页,因此完全不需要调用 compound_head()。这直接省去了大量的指针转换操作,从而节省了执行时间和内存占用。
2.2 page cache
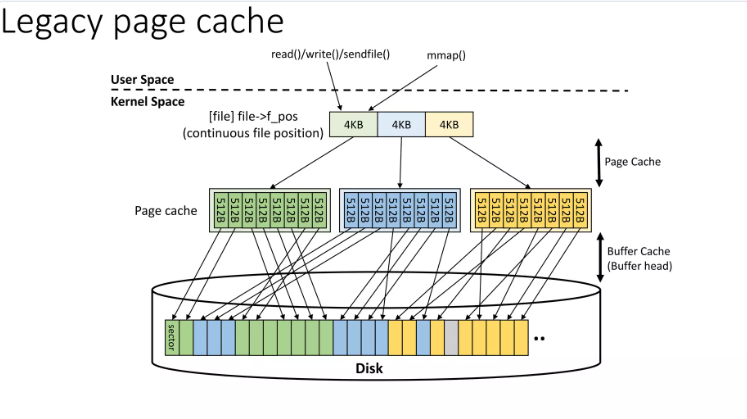
(1) legacy page cache:即 5.16.0以前的管理
$ grep -i active /proc/meminfo
Active: 12773136 kB
Inactive: 17503876 kB
Active(anon): 2128 kB
Inactive(anon): 3775856 kB
Active(file): 12771008 kB
Inactive(file): 13728020 kB
传统页缓存(legacy page cache)的问题,特别是在没有复合页(compound page)概念的情况下。主要问题包括:
- 页缓存占据了大部分内存页。
- 每个页缓存(作为单个基础页)都被添加到活跃/非活跃LRU列表中,导致LRU列表非常长。
- 长LRU列表导致锁竞争和缓存失效(cache misses)问题。
传统页缓存设计的核心问题是 粒度过细。
(2)引入 Page Folios
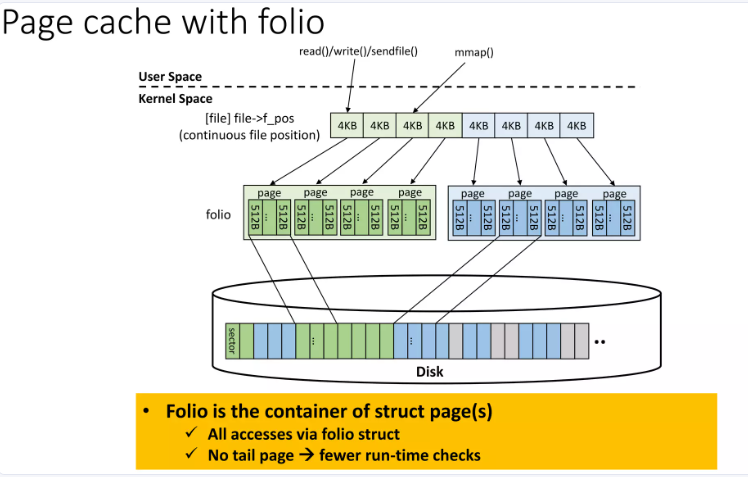
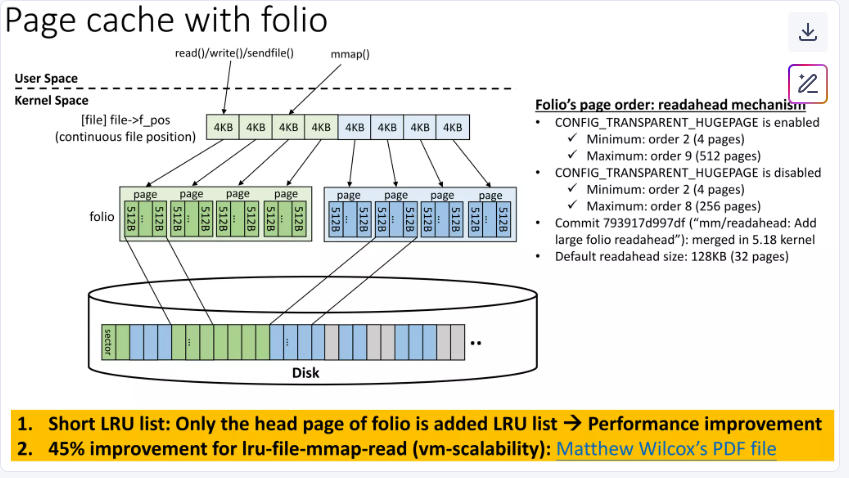
仅头页加入 LRU:每个 folio 作为一个完整单元,仅其头页(head page)加入 LRU 列表。
在folio模型中,一个folio可以包含多个连续的物理页(例如一个folio包含多个page)。当将folio添加到LRU链表时,整个folio作为一个条目加入- 只有folio的头页被加入LRU列表,而不是每个基础页单独加入。这样,LRU链表的长度大大缩短,从而减少了锁竞争和缓存未命中的问题。
具体来说,在folio实现中:
- 每个folio都有一个LRU链表节点(
struct list_head lru)。 - 当需要将folio加入LRU链表时(例如在
folio_add_lru()函数中),只有folio的头页被加入LRU列表。 - 当进行LRU链表扫描(如kswapd)时,每次处理一个folio(可能包含多个页),效率更高。
只有folio的头页被加入LRU列表。传统情况下,每个page独立加入LRU列表,导致列表过长,锁争用和缓存未命中。而folio将多个页合并为一个单元,只需添加头页到LRU列表,缩短列表长度,减少锁操作和缓存压力。
三、buffer_head、iomap与page folios
对于文件系统来说,尽可能不再使用旧的 buffer-head API,尽可能使用相对较新的 iomap 的基础设施。
(1)buffer_head
buffer_head用于将单个块映射到页内,并且是文件系统和块层I/O的基本单位。每个buffer_head通常对应一个4K的块,但文件系统可能使用更小的块大小,如1K或512字节。这种情况下,一个页(4K)可能包含多个buffer_head结构体,每个描述该页对应的不同磁盘块位置。这导致在处理多页读写时,每个页都需要通过get_block调用来获取磁盘偏移关系,增加了复杂性和开销。
buffer_head以块(block)为单位,通常为4KB或更小(如1KB/512B)。一个4KB页(page)可能包含多个buffer_head(最多8个),导致每个页的元数据管理复杂。
多页操作低效:
逐块操作:在读写多页(multi-page)数据时,需逐个调用get_block获取每个页的磁盘偏移,增加了I/O路径的开销,每次 I/O 触发多次 get_block() 翻译(页→磁盘块)。
与THP的冲突
透明大页(THP):THP将多个4KB页合并为2MB或1GB的大页,以减少页表项和TLB压力。然而,buffer_head的粒度无法直接适配THP,导致处理大页时仍需分解为多个小块操作,效率低下。
(2)iomap
iomap:iomap最初来自XFS,基于extent,天然支持多页操作。通过iomap,文件系统可以一次性获取所有页的磁盘偏移关系,而不需要逐页处理。这减少了I/O操作的次数和复杂度,提高了效率。此外,iomap使用字节作为单位,与page cache解耦,使得文件系统在处理数据大小时更加灵活,不需要依赖具体的页数。
元数据操作:iomap目前缺乏对元数据操作的辅助函数。文件系统(如XFS)需自行实现元数据映射,而无法完全依赖iomap。
向后兼容性:部分旧功能(如submit_bh)仍需buffer_head支持,导致iomap无法完全替代。
当前iomap缺乏某些buffer_head的功能,而folio的合并能够推动iomap的发展,使基于块的文件系统转换为使用iomap。
(3)folio
folio旨在简化内存管理,减少运行时检查,通过将多个物理页封装为一个逻辑单元来提高性能。Folio的引入有助于隔离文件系统与page cache,使得文件系统能够更高效地处理大页(如THP),从而提升I/O效率。XFS和AFS等基于iomap的文件系统已经率先采用folio,因为它们天然支持多页操作,这使得folio的合并对这些文件系统的优化尤为重要。
FS 开发者都希望 folio 被合入,他们可以方便地在 page cache 中使用更大的 page,这个做法可以使文件系统的 I/O 更有效率。
四、何时分配 Large Folio
(1)来自用户空间的提示(Hints from Userspace)
比如调用 madvise(MADV_HUGEPAGE) 来向内核表明希望使用大页。
MADV_HUGEPAGE 是当前最有效的用户空间提示(用于透明大页 THP),但仅适用于匿名内存(anon pages),不直接用于文件页缓存(page cache)。
(2)文件系统决策 (Filesystem Hints)
文件系统(如 ext4、XFS)知道文件的布局(如 extent 分配是否连续),但缺乏完整的访问模式信息。
文件系统可以建议大 folio(例如通过 iomap 接口),但最终决策权在通用页缓存层。
(3)Readahead 的激进策略 (Page Cache Readahead)
readahead 已成为决定大页分配的核心:
它根据访问模式(如顺序读、流式读)决定预读多少页。
同时,它也决定分配多大的folio(4KB基础页 or 2MB大页)。
覆盖了大部分顺序读场景(如大文件读取)。
(4)写入未缓存的文件区域 —— 仍使用基础页(Order-0 Pages)
(5)缺页 + MADV_HUGEPAGE → 分配PMD级大页(仅限匿名内存)
如果用户空间设置了 MADV_HUGEPAGE,缺页异常(page fault)会尝试分配 PMD-order(如 2MiB)的大 folio。
但仅适用于匿名内存(如 mmap(MAP_ANONYMOUS)),不适用于文件页缓存。
五、folio结构体演变
到了Linux6.2,struct folio结构体:
/*** struct folio - Represents a contiguous set of bytes.* @flags: Identical to the page flags.* @lru: Least Recently Used list; tracks how recently this folio was used.* @mlock_count: Number of times this folio has been pinned by mlock().* @mapping: The file this page belongs to, or refers to the anon_vma for* anonymous memory.* @index: Offset within the file, in units of pages. For anonymous memory,* this is the index from the beginning of the mmap.* @private: Filesystem per-folio data (see folio_attach_private()).* Used for swp_entry_t if folio_test_swapcache().* @_mapcount: Do not access this member directly. Use folio_mapcount() to* find out how many times this folio is mapped by userspace.* @_refcount: Do not access this member directly. Use folio_ref_count()* to find how many references there are to this folio.* @memcg_data: Memory Control Group data.* @_flags_1: For large folios, additional page flags.* @_head_1: Points to the folio. Do not use.* @_folio_dtor: Which destructor to use for this folio.* @_folio_order: Do not use directly, call folio_order().* @_compound_mapcount: Do not use directly, call folio_entire_mapcount().* @_subpages_mapcount: Do not use directly, call folio_mapcount().* @_pincount: Do not use directly, call folio_maybe_dma_pinned().* @_folio_nr_pages: Do not use directly, call folio_nr_pages().* @_flags_2: For alignment. Do not use.* @_head_2: Points to the folio. Do not use.* @_hugetlb_subpool: Do not use directly, use accessor in hugetlb.h.* @_hugetlb_cgroup: Do not use directly, use accessor in hugetlb_cgroup.h.* @_hugetlb_cgroup_rsvd: Do not use directly, use accessor in hugetlb_cgroup.h.* @_hugetlb_hwpoison: Do not use directly, call raw_hwp_list_head().** A folio is a physically, virtually and logically contiguous set* of bytes. It is a power-of-two in size, and it is aligned to that* same power-of-two. It is at least as large as %PAGE_SIZE. If it is* in the page cache, it is at a file offset which is a multiple of that* power-of-two. It may be mapped into userspace at an address which is* at an arbitrary page offset, but its kernel virtual address is aligned* to its size.*/
struct folio {/* private: don't document the anon union */union {struct {/* public: */unsigned long flags;union {struct list_head lru;/* private: avoid cluttering the output */struct {void *__filler;/* public: */unsigned int mlock_count;/* private: */};/* public: */};struct address_space *mapping;pgoff_t index;void *private;atomic_t _mapcount;atomic_t _refcount;
#ifdef CONFIG_MEMCGunsigned long memcg_data;
#endif/* private: the union with struct page is transitional */};struct page page;};union {struct {unsigned long _flags_1;unsigned long _head_1;unsigned char _folio_dtor;unsigned char _folio_order;atomic_t _compound_mapcount;atomic_t _subpages_mapcount;atomic_t _pincount;
#ifdef CONFIG_64BITunsigned int _folio_nr_pages;
#endif};struct page __page_1;};union {struct {unsigned long _flags_2;unsigned long _head_2;void *_hugetlb_subpool;void *_hugetlb_cgroup;void *_hugetlb_cgroup_rsvd;void *_hugetlb_hwpoison;};struct page __page_2;};
};
如下图所示:
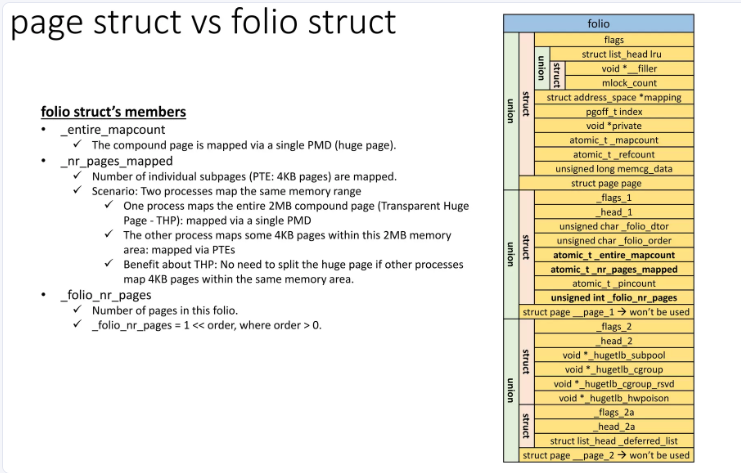
字段说明:



与compound pages的比较:

六、内核主线folio的逐步使用
Linux 5.16.0:引入page folios。
Linux 5.18.0:
(1)Memory management folio patches (get_user_pages, vmscan, start on the page cache, make readahead use large folios)
(2)Filesystem conversions to folio structures
Linux 5.19.0:
(1)conversion from alloc_pages_vma() to vma_alloc_folio(), finish converting shrink_page_list() to folios, start converting shmem from pages to folios
(2)Convert aops->read_page to aops->read_folio
Linux 6.0.0:
(1)Finish the conversion from alloc_pages_vma() to vma_alloc_folio(), finish converting shrink_page_list() to folio, start converting shmem from pages to folios
(2)Convert the swap code to be more folio-based
Linux 6.1.0:
Folio changes: this round has focused on shmem
Linux 6.2.0:
(1)Convert migrate_pages()/unmap_and_move() to use folios
(2)Begin converting hugetlb code to folios
(3)Convert core hugetlb functions to folios
…
参考资料
https://lwn.net/Articles/849538/
https://www.infoq.cn/article/kCRXZhKLOZ9lYJzaasZ0
https://zhuanlan.zhihu.com/p/1902473318315058208
https://www.infradead.org/~willy/linux/2022-06_LCNA_Folios.pdf
https://www.slideshare.net/slideshow/memory-management-with-page-folios/258148418
](http://pic.xiahunao.cn/[优选算法专题一双指针——两数之和](双指针和哈希表))

是如何影响系统性能的?)


)



免安装中文版)


:无界面 TCP 通信服最小实现)
实战应用:从微调到部署全流程)

 --运算符重载)



