1.总结
GR-3 是一个大规模的视觉 - 语言 - 动作(VLA)模型。它对新物体、新环境以及含抽象概念的新指令展现出较好的泛化能力。此外,GR-3 支持少量人类轨迹数据的高效微调,可快速且经济地适应新任务。GR-3 在处理长周期和灵巧性任务(包括需要双手操作和底盘移动的任务)上也展现出稳健且可靠的性能。
这些能力源自—种多样的训练方法,具体包括:利用大规模的视觉 - 语言数据联合训练、负责实验室采集的同学基于 VR 设备构建了人类轨迹数据进行有效地模仿学习。此外,我们还推出了一款双臂移动机器人 ByteMini。ByteMini 兼具灵巧性和可靠性,集成了 GR-3 后,能完成各式各样的复杂任务。
本报告介绍 GR-3——一种大规模视觉-语言-动作模型,具备以下特性:
- 严格遵循语言指令,并对新颖物体、环境及指令具有良好泛化能力;
- 仅需少量人类轨迹即可高效微调,实现快速场景迁移;
- 在长跨度、灵巧任务中保持高鲁棒性与高可靠性。

技术报告:字节跳动Seed
-
-
2. 简介
打造能够协助人类完成日常任务的智能通用机器人,是机器人研究中长期追求的愿景。真正的难题在于现实世界的巨大多样性:机器人策略必须具备强大的泛化能力,才能应对层出不穷的新场景。此外,许多日常任务天然具有长跨度、高复杂度的灵巧操作要求,这对策略的鲁棒性与可靠性提出了极高标准。
GR-3 以自然语言指令、环境观测和机器人状态为输入,端到端输出动作序列,控制双臂移动机器人。模型基于预训练 VLM,并通过流匹配预测动作。作者对网络架构进行了系统研究,提出一系列关键设计,显著提升了指令跟随与长跨度任务表现。为强化泛化能力,作者将机器人轨迹数据与覆盖多种视觉-语言任务的大规模数据协同训练,使 GR-3 不仅能处理全新类别的物体,还可理解尺寸、空间关系、常识知识等在机器人数据中缺失的抽象概念。
此外,GR-3 仅需通过 VR 设备收集的少量人类轨迹即可高效微调,实现低成本快速适配。作者同步推出 ByteMini——一款灵活可靠的双臂移动机器人,与 GR-3 结合后可在现实世界中完成多样复杂任务。
在三大挑战性场景的广泛实验中——可泛化抓取放置、长跨度桌面整理、灵巧布料操作——GR-3 全面超越当前最佳基线 π0。它对新类别物体和复杂语义展现优异泛化能力,仅用每条物体 10 条人类轨迹即可快速适配新物体;在长跨度与灵巧任务中亦表现稳健,桌面整理与布料操作均取得高平均任务进度。作者期望 GR-3 成为迈向日常生活通用机器人的关键一步。


-
-
3.模型结构
GR-3 是一个端到端的视觉-语言-动作(VLA)模型 πθ,用于控制带有移动底盘的双臂机器人。模型以自然语言指令 l、当前观测 和机器人状态
为条件,一次性生成长度为 k 的动作片段
,即
。
GR-3 采用混合 Transformer 架构。
- 首先,作者使用预训练的视觉-语言模型 Qwen2.5-VL-3B-Instruct 处理来自多台摄像头的图像观测与语言指令;
- 随后,由动作扩散 Transformer(DiT)预测动作片段。具体而言,GR-3 利用流匹配实现动作预测:流估计以当前机器人状态 st 以及 VLM 主干输出的 KV 缓存为条件。
- 长度为 k 的动作片段被表示为 k 个 token,并与机器人状态 token 拼接,构成动作 DiT 的输入序列。
- 流匹配的时间步通过自适应层归一化(AdaLN)注入。为了建模动作片段内部的时间依赖,动作 DiT 使用因果注意力掩码。
- 长度为 k 的动作片段被表示为 k 个 token,并与机器人状态 token 拼接,构成动作 DiT 的输入序列。
为保证推理速度,动作 DiT 的层数仅为 VLM 主干的一半,且仅复用主干后一半层级的 KV 缓存。整体模型参数量为 4 B。
在初期实验中,作者观察到训练过程经常出现不稳定。受 QK Norm 启发,作者在动作 DiT 的注意力与 FFN 内的线性层后额外引入 RMSNorm。该设计显著提升了整个训练的稳定性,并在下游实验中大幅增强了语言遵循能力,详见第 5 节。
-
-
4.训练策略
作者采用多种数据源混合训练 GR-3:机器人轨迹数据用于模仿学习,网页级视觉-语言数据用于协同训练,少量人类轨迹数据用于小样本泛化。
该训练方案使 GR-3 能够 1) 泛化到全新物体、环境与指令,2) 以低成本高效适配未见场景,3) 稳健地完成长跨度与灵巧任务。
4.1 基于机器人轨迹数据的模仿学习
作者采用模仿学习目标来训练 GR-3,通过最大化策略在一组专家演示 D 上的对数似然:
具体而言,训练时利用流匹配损失来监督动作预测:
其中 为流匹配时间步,t 表示回合中的时间戳;
为带噪动作块,
为随机噪声;
为流匹配的真实值。
作者将流匹配标签用于流预测。为了加速训练,作者在 VLM 主干的一次前向传播中,对多个采样的流匹配时间步同时计算流匹配损失。
-
在推理阶段,动作片段初始化为随机噪声 ,并用欧拉方法从
积分到
,即
,实验中设
。
-
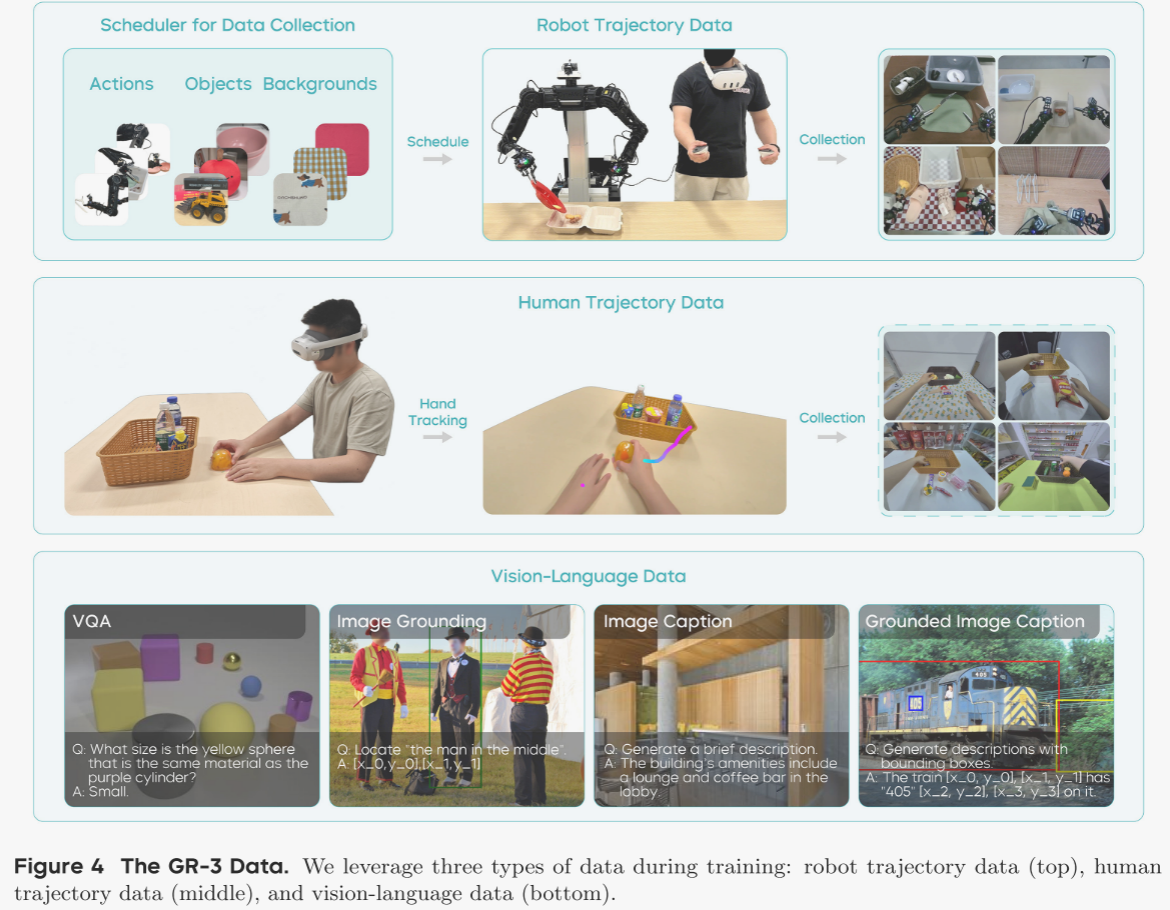
作者通过遥控操作采集真实机器人轨迹。为使采集过程更易控制并最大化数据多样性,作者开发了一套数据采集调度器(见图 4),在每次采集开始前向操作员提示:1)需执行的动作,2)物体组合,3)背景设置。系统生成新的配置后,操作员据此布置环境。该调度器的实现帮助作者有效管理整体数据分布,充分随机化采集数据,极大提升了数据集的丰富性与多样性。此外,采集后还会进行质量检查,剔除无效或低质量数据。
先前研究指出,策略可能利用多视角的伪相关来预测动作,而非真正关注语言条件。为缓解这一问题,作者在动作维度中引入“任务状态”作为辅助监督。任务状态可取以下值:进行中(0)、已完成(1)、无效(-1)。“进行中”表示机器人正在执行任务;“已完成”表示任务成功结束;“无效”表示当前观测下指令不可行。例如,桌上没有刀时,“把刀放进编织篮”即为无效指令。
训练时,作者随机将语言指令替换为无效指令,并要求模型仅预测“无效”状态,而不监督动作片段的其他维度。此设计迫使动作 DiT 必须关注语言指令并判断任务状态,显著提升了语言遵循能力。
-
4.2 协同训练视觉-语言数据
为使 GR-3 具备遵循分布外(OOD)指令的泛化能力,作者将机器人轨迹数据与视觉-语言数据联合训练(见图 3)。机器人轨迹数据同时训练 VLM 主干与动作 DiT,采用流匹配损失;视觉-语言数据仅训练 VLM 主干,使用下一词预测损失。为简化实现,作者在 mini-batch 中以等权重动态混合两类数据,因此协同训练的总目标为下一词预测损失与流匹配损失之和。
通过视觉-语言协同训练,GR-3 能在零样本情况下有效泛化至未见物体,并理解复杂概念的新颖语义。作者从多个数据源精心构建了一套大规模视觉-语言数据集,涵盖图像描述、视觉问答、图像定位及交错式图像描述等任务(见图 4)。作者还设计了过滤与再标注流水线,以提升数据集质量,确保协同训练效果。
协同训练不仅帮助 GR-3 保留了预训练 VLM 的强视觉-语言能力,还使动作 DiT 能在动作预测中直接利用这些能力,从而显著提升下游操作任务的泛化表现。
-
4.3小样本泛化:基于人类轨迹数据
GR-3 作为通用视觉-语言-动作模型,可通过轻量微调迅速适配全新场景。然而,采集真实机器人轨迹既费时又昂贵。近年来,VR 设备与手部追踪技术的进步为直接从人类轨迹学习动作提供了契机。本报告中,作者将 GR-3 的高效微调能力延伸至更具挑战性的“极少人类轨迹小样本学习”场景。
具体而言,面对一个新场景,作者仅需利用 PICO 4 Ultra Enterprise 采集少量人类轨迹。借助 VR,人类轨迹的采集速度可达约 450 条/小时,远高于遥操作机器人轨迹的 250 条/小时,从而以更低成本实现快速迁移。
采集到的人类轨迹包含第一视角视频与手部轨迹。作者沿用机器人轨迹的标注流程,为人类轨迹补充语言指令。完成视觉-语言数据与机器人轨迹的第一阶段训练后,作者将人类轨迹纳入,并对三类数据共同训练。
与机器人轨迹不同,人类轨迹仅提供第一视角和手部轨迹,缺少腕部视角、关节状态与夹爪状态。对此,作者用空白图像填充缺失的腕部视角,并仅依据手部轨迹对人类数据进行训练。
-
-
5.硬件和系统
5.1 ByteMini机器人
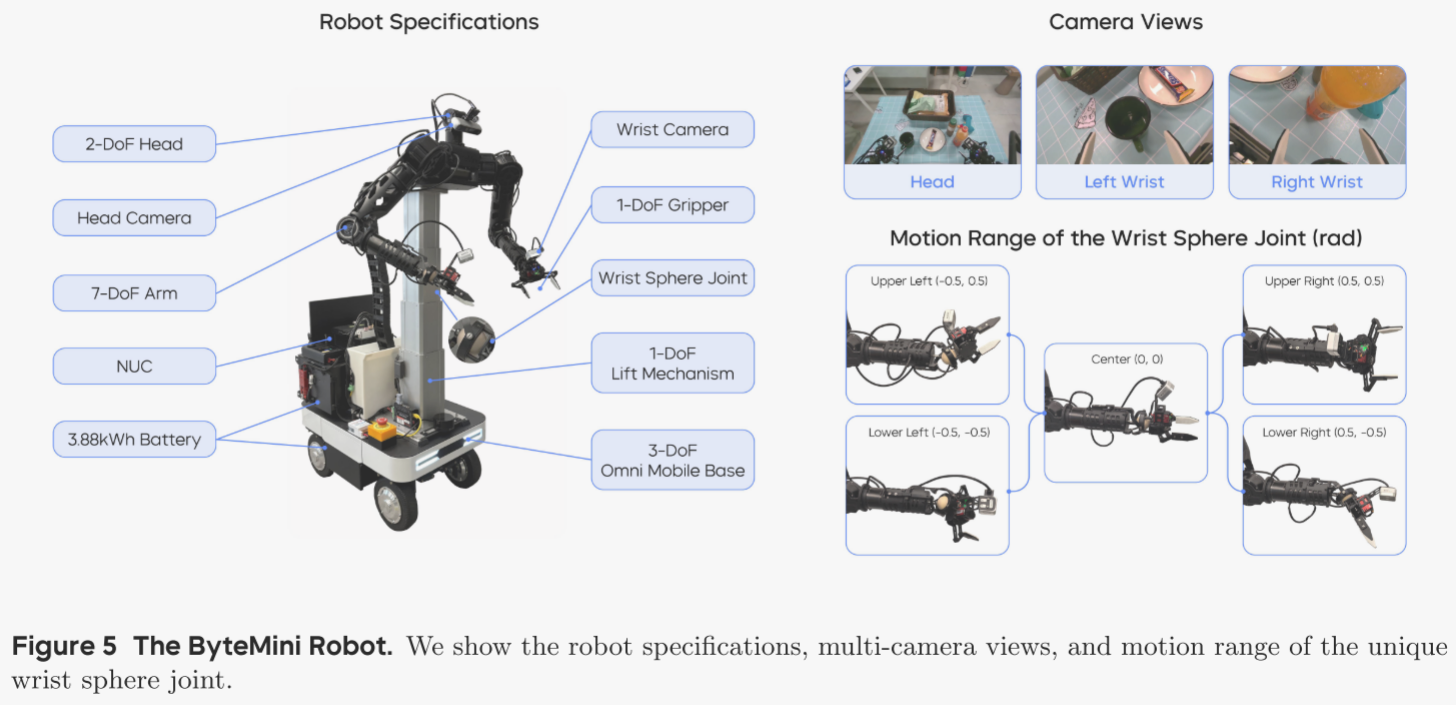
ByteMini 机器人(见图 5)被用于数据采集与策略部署。这台 22 自由度的双臂移动机器人围绕三大核心目标设计:灵活操作、高可靠性与人机友好。
灵活操作
两条 7 自由度的机械臂采用无偏置构型,并在腕部引入独特的球形关节,实现接近人手的灵巧度。紧凑的球形腕部突破了传统 SRS 构型腕部体积过大、在狭窄空间内操作受限的瓶颈。肘关节经过专门设计,可实现 2.53 rad 的大范围内收,使双臂能够在机器人胸前的有限空间内完成精细作业。
高可靠性
数据采集与策略部署的高负荷运行要求 ByteMini 具备极高的稳定性与一致性。作者采用集成升降机构的万向移动底盘,确保空间机动与垂直高度调节的平稳可靠。为进一步提升可靠性并保证动作一致性,臂部执行器基于准直驱(QDD)原理设计,兼具高透明度与稳定性。
人机友好
为提升易用性,作者在机器人上集成了便携屏幕与 NUC 计算单元,并由双锂电池供电,在多种场景下可连续运行超过 10 小时。ByteMini 还配备无线急停按钮,可在紧急情况下迅速切断动作。头部与双腕均安装 RGB-D 相机,腕部相机可在精细操作时提供近距离视野。
-
5.2 系统与控制
全身柔顺控制
作者采用全身柔顺控制框架,将所有自由度视作一个整体,把任意遥操作的人体运动重映射为机器人可行运动。可操作度优化、奇异点规避以及关节物理限位被统一纳入实时最优控制问题,以最大化机器人的灵巧性。该框架能在广阔工作空间内为多种长跨度操作任务生成流畅、连续的运动,从而为策略训练提供高质量的示范轨迹。柔顺力控制器支持高动态运动及与环境的物理交互,既提升了安全性,也提高了数据采集效率。
全身遥操作
在遥操作采集阶段,作者通过 Meta VR Quest 实现全身重映射,使操作者直观、友好地将人体动作直接映射到机器人末端执行器。操作者可以同时控制机械臂、升降机构、夹爪和移动底盘,从而在现实世界中为复杂长跨度任务提供无缝的数据采集体验。
策略部署的轨迹优化
在策略部署阶段,作者使用 GR-3 预测的动作片段控制机器人 19 个自由度(不含升降机构与头部的 3 个自由度)。作者引入纯跟踪算法并结合轨迹优化,以提升 GR-3 生成轨迹的稳定性与平滑度。实时参数化优化最小化加加速度,确保各航点之间以及整条轨迹之间的无缝衔接。
-
-
6. 实验
作者在真实世界中开展了大量实验,以全面评估 GR-3 的表现,并围绕四个核心问题展开:
1. GR-3 能否严格遵循包括训练阶段未见在内的所有指令?
2. GR-3 是否具备泛化到分布外场景(新物体、新环境、新指令)的能力?
3. GR-3 能否基于极少的人类轨迹完成小样本学习,并迁移到机器人本体?
4. GR-3 是否能学习到稳健策略,从而胜任长跨度且灵巧的复杂任务?
实验选取三项任务:可泛化抓取-放置、长跨度桌面整理、灵巧布料悬挂。更多视频演示请见项目主页。作者将 GR-3 与当前最佳方法 π0 对比,按照 π0 官方 GitHub 仓库的指引,对其在三大任务上分别进行微调。
6.1 可泛化抓取-放置
为评估 GR-3 在分布外场景的泛化能力,作者设置了聚焦泛化的抓取-放置任务。共采集 3.5 万条机器人轨迹,涵盖 101 种物体,总时长 69 小时。轨迹以“将 A 放入 B”形式标注,A 为物体类别,B 为容器。基线模型仅用这些机器人轨迹进行微调;GR-3 则同时用机器人轨迹与视觉-语言数据协同训练。训练期间,作者对机器人轨迹图像施加光度增强,以提升对变化环境的鲁棒性。作者还对比了“GR-3 无协同训练”这一变体,仅用机器人轨迹训练,以评估协同训练的具体贡献。
评估设置
作者在四种场景中进行评测:
1) 基础场景:环境与物体均在训练中见过,共 54 种物体,用于检验基本指令遵循能力。
2) 未见环境:使用与基础场景相同的 54 种物体,但置于四个训练时未见的环境(收银台、会议室、办公桌、休息室)中,物体摆放保持一致。
3) 未见指令:给出需要复杂概念理解的指令,如“把左边的可乐放进纸盒”“把带触手的动物放进纸盒”。
4) 未见物体:使用 45 种在机器人轨迹中未出现的新物体。
评测指标
作者采用指令遵循率(IF)与成功率两个指标。
- 指令遵循率:若机器人正确接近指令指定的物体,则视为成功。
- 成功率:若机器人最终把目标物体放入容器,则视为成功。
两者得分越高,代表相应能力越强。
基础指令遵循
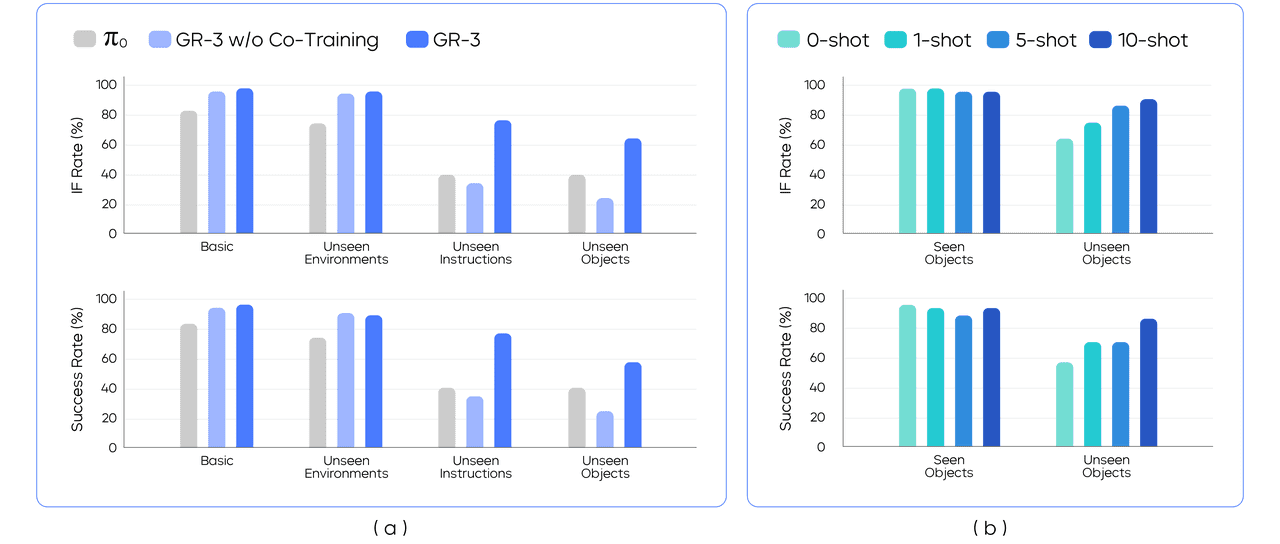
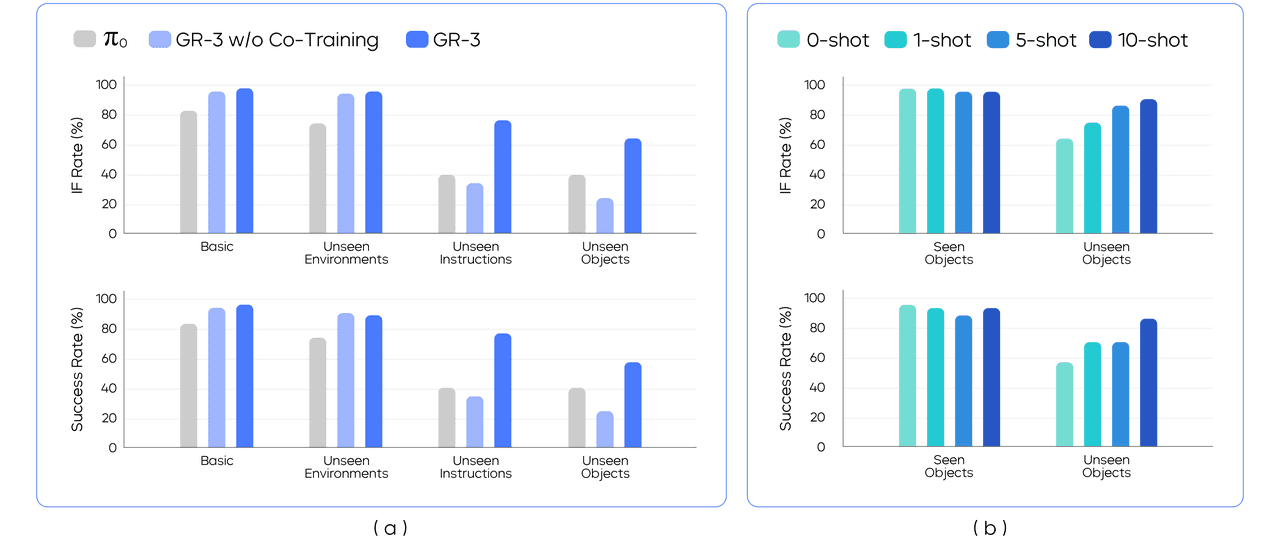
在“基础”与“未见环境”两种设定中,作者将 54 个已见物体划分为 9 个 mini-batch,每批 6 个物体。在每次 rollout 时,依据给定指令让模型从 6 个候选中挑选 1 个物体。为保证不同模型结果可比,作者使用预捕获的摆放模板固定物体位置,确保同一 mini-batch 的物体布局在评测期间完全一致。图 7(a) 显示,GR-3 在两种设定下的指令遵循率和成功率均超越 π0;基础与未见环境间的性能差异很小,表明 GR-3 对环境变化具备鲁棒性。此外,GR-3 与“无协同训练”版本在这两设定下差异不显著,说明协同训练对已知物体表现无负面影响。
可泛化指令遵循
在“未见指令”设定中,作者测试模型对尺寸、空间关系、常识等抽象概念的理解能力。示例指令包括“把可乐旁边的那罐雪碧放进纸盒”“把最大的物体放进纸盒”“把海洋动物放进纸盒”等,这些指令在机器人轨迹数据中从未出现,需要模型进行复杂语义推理。
在“未见物体”设定中,作者将 45 个未见物体划分为 9 个 mini-batch,每批 5 个物体,即每次 rollout 需从 5 个候选中选 1 个。该设定尤为苛刻:45 个物体中超过 70 % 属于训练时未见的类别。图 7(a) 显示,GR-3 在这两项设定中大幅领先 π0,成功率分别由 40 % 提升至 77.1 %(未见指令)和 57.8 %(未见物体)。与“无协同训练”版本相比,GR-3 亦显著提升,表明视觉-语言协同训练为泛化能力带来关键增益。VLA 模型将大规模视觉-语言知识有效迁移到策略学习,实现对新场景的零样本泛化。仅使用机器人轨迹训练的 GR-3 甚至低于 π0 基线,作者推测 π0 的优势源于其大规模跨本体预训练。
基于人类轨迹的小样本泛化
作者进一步利用 VR 采集的人类轨迹评估小样本泛化能力,挑战在于:1) 需跨本体学习;2) 数据极度稀缺。具体而言,作者在“未见物体”设定中,为 45 个新物体各采集 10 条以内人类轨迹,总计 450 条,总时长约 30 分钟。作者以已训练于机器人轨迹和视觉-语言数据的检查点为起点,增量训练 GR-3:在保留原有数据的同时加入人类轨迹,再协同训练 20 k 步。
作者在 1-shot、5-shot、10-shot 三种小样本设定下,分别评测已知与未知物体(图 7(b))。与零样本基线相比,随着人类轨迹增多,未见物体的指令遵循率和成功率持续提升;仅 10 条人类轨迹即可将成功率从 57.8 % 提高到 86.7 %。同时,已知物体性能无明显下降,表明这一微调策略兼具样本高效与成本低廉,为将预训练 VLA 模型迁移至下游新场景提供了可行路径。
-
6.2 长期工作台总线
长跨度桌面整理
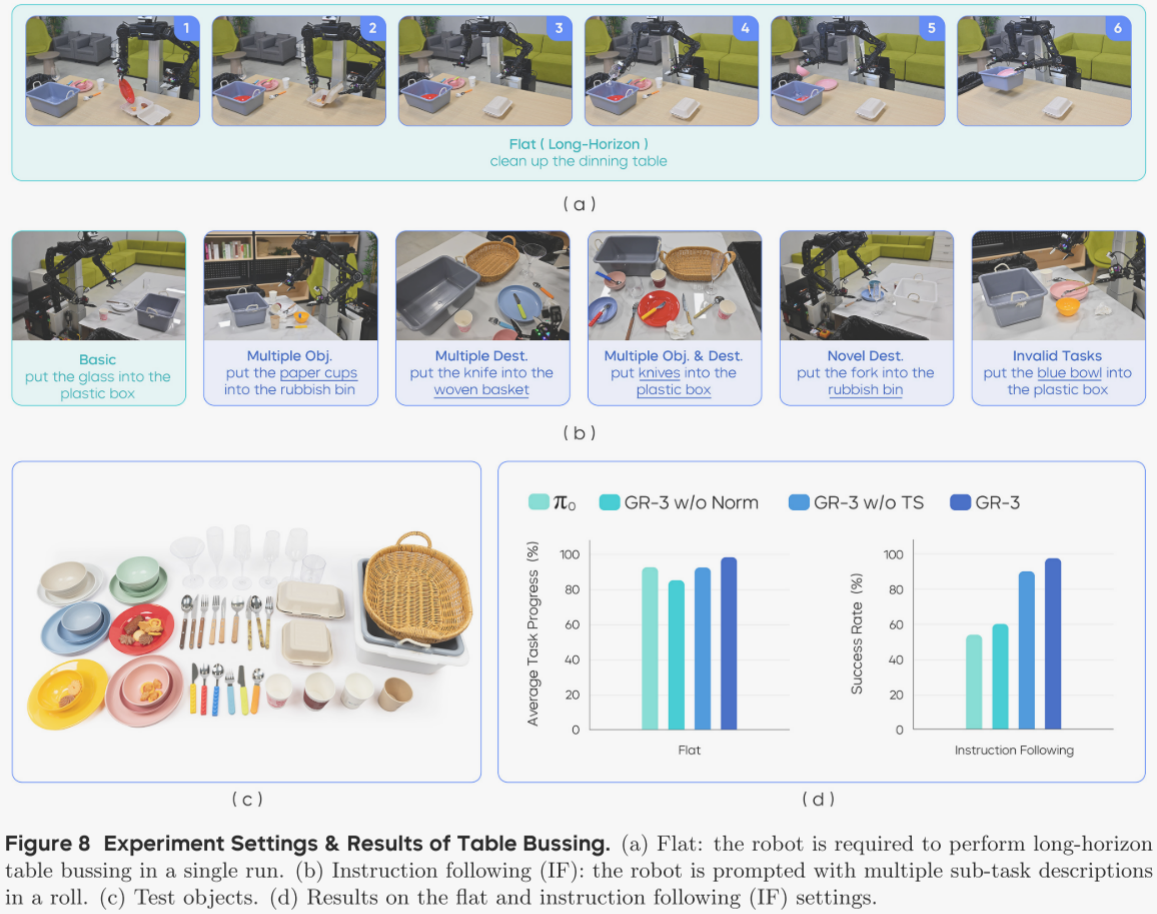
作者通过桌面整理任务检验 GR-3 在长跨度操作中的鲁棒性(图 8)。在该任务中,机器人需清理布满餐具、食物、外带盒及塑料整理箱的餐桌。为完成整项作业,机器人必须:1) 将食物打包进外带盒;2) 将所有餐具投入整理箱;3) 把垃圾全部扔进垃圾桶。由于操作区域广阔,机器人需驱动底盘在餐桌、外带盒与整理箱之间往返(图 8(a))。作者在“平铺任务”与“指令跟随”两种设定下进行评测。
平铺任务设定
机器人仅收到一条概括指令——“清理餐桌”——即需在单次运行中自主完成全部子任务(图 8(a))。该设定用于评估模型在长跨度任务中的鲁棒性。作者以“平均任务进度”作为指标,计算成功完成的子任务数占总子任务数的比例;数值为 1.0 表示完全成功,中间值表示部分完成。作者在此设定下共测试了五组不同物体配置。
指令跟随(IF)设定
为了进一步检验模型对子指令的遵循能力,作者依次给出多条子任务描述,例如“将纸杯扔进垃圾桶”。每次子任务均从机器人“原位”开始。作者以“平均子任务成功率”作为指标。IF 设定共含六类测试场景(图 8(b)):
- 基础:物体布局与训练数据几乎一致。
- 多实例:在场景中加入某类物体的多个实例,并指令机器人将该类全部实例投入整理箱或垃圾桶。
- 多目的地:额外放置一个编织篮,要求机器人把餐具投入篮子或整理箱。
- 多实例 & 多目的地:综合前两设定,让机器人把某类全部实例移至两个目的地之一。
- 新目的地:要求把物体移至训练时未与之配对的目的地,例如“把叉子扔进垃圾桶”。
- 无效任务:现实应用中,机器人可能收到无法完成的复杂指令。若桌上无蓝碗,则“把蓝碗放入塑料盒”即为无效。作者期望策略能拒绝执行此类错误指令。在该测试中,若模型在 10 秒内不操作任何物体即判为成功。
实现细节
作者共采集约 101 小时的机器人轨迹。基线模型 π0 仅在这些轨迹上微调。GR-3 则同时利用机器人轨迹与视觉-语言数据协同训练。作者还测试两个消融版本:
- GR-3 w/o Norm:移除 DiT 块注意力与 FFN 中的 RMSNorm。
- GR-3 w/o TS:训练时不引入任务状态。
两种设定分别训练“平铺版”与“IF 版”。平铺版在训练时随机使用整体任务或子任务作为语言指令;IF 版仅使用子任务指令。
结果
图 8(d) 显示,GR-3 在两项设定下均优于 π0,尤其在 IF 设定中成功率从 53.8 % 提升至 97.5 %。π0 虽能完成长跨度整理,但指令遵循薄弱,在分布外情境下尤为明显:无法区分刀叉,在新目的地测试中将物体投入训练时常见容器,而非按指令操作。相反,GR-3 在六类测试场景中均能严格遵循指令,可泛化到多实例与多目的地场景,并在无效任务中正确拒绝执行。
移除 RMSNorm 会显著削弱性能,尤其在 IF 设定下:GR-3 w/o Norm 指令遵循能力大幅下降,无法泛化到新目的地,凸显 RMSNorm 在提升指令遵循中的关键作用。去除任务状态同样导致 IF 性能下降,表明任务状态能有效帮助 VLA 模型执行指令。
-
6.3 灵巧布料操作
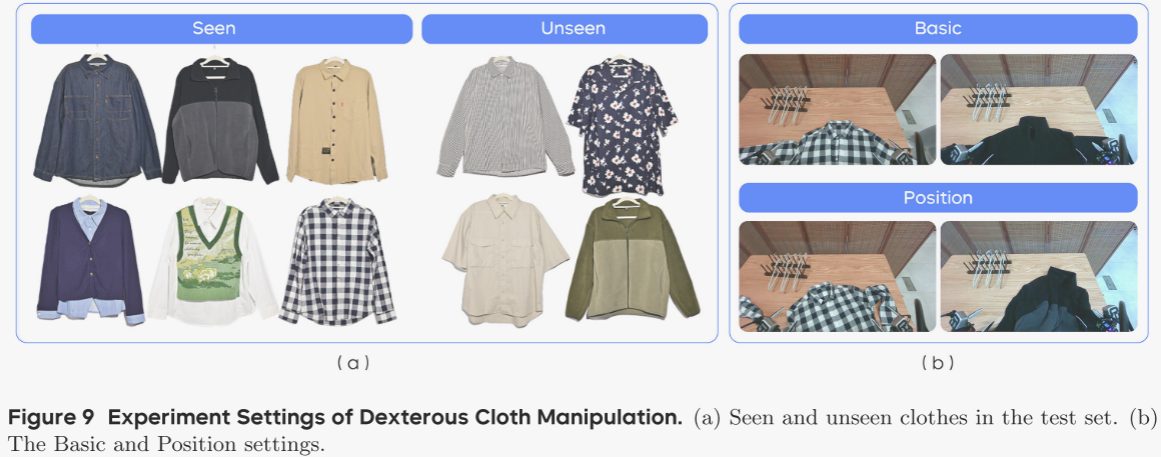
本实验评估 GR-3 对可变形物体的灵巧操控能力,具体任务为:使用衣夹把衣服挂到晾衣架上(图 2)。机器人需依次完成:1) 抓取衣夹;2) 将衣服套上衣夹;3) 把衣服连同衣夹挂到晾衣架。最后一步中,机器人需旋转底盘,从桌面前移到晾衣架旁完成挂衣。作者共采集 116 小时机器人轨迹训练 π0;GR-3 则在此基础上与视觉-语言数据协同训练。作者在三种设定下评测:基础(Basic)、位置扰动(Position)、未见实例(Unseen Instances)。
设定
- 基础:使用训练中见过的 6 件衣服,摆放方式与训练数据一致。
- 位置扰动:将衣服旋转并揉皱(图 9(b)),评估模型对复杂布料布局的鲁棒性。
- 未见实例:使用训练中未见的 4 件衣服(图 9(a))。训练时均为长袖,测试集中两件为短袖,考验模型对新颖款式与袖长的泛化能力。
评测指标
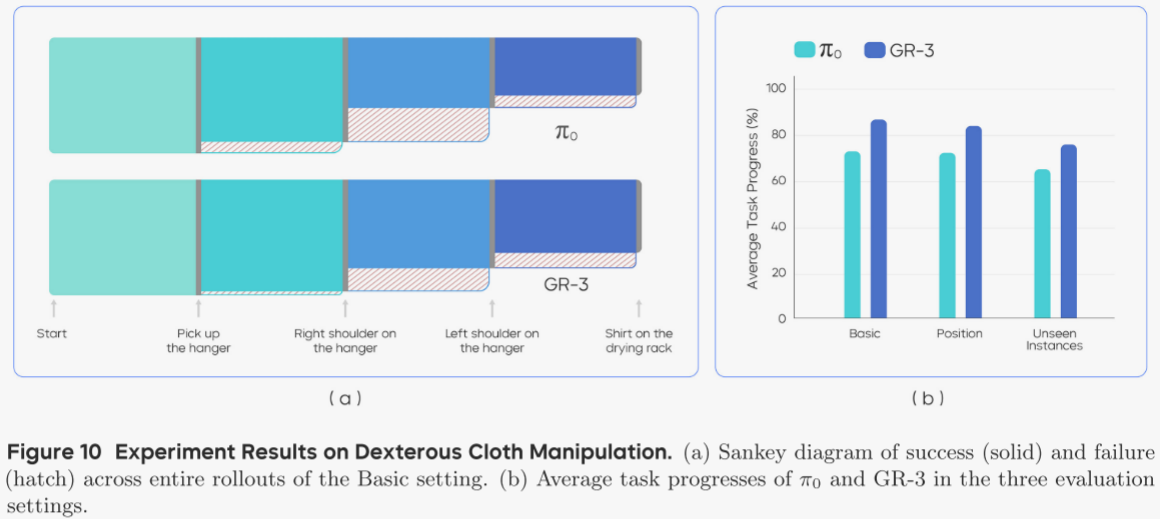
作者以“平均任务进度”为指标。完整挂衣成功得 1.0,任务被细分为 4 个关键里程碑:
1) 抓取衣夹;
2) 右肩套上衣夹;
3) 左肩套上衣夹;
4) 把衣服挂到晾衣架(图 10(a))。
每个里程碑贡献相应分数,累加得到总进度。
结果
图 10 显示,GR-3 在三种设定下均优于 π0:
- 基础:86.7 %
- 位置扰动:83.9 % 表明其擅长复杂灵巧任务,且对布料位置变化鲁棒。
- 未见实例:75.8 % 表明模型可泛化至未见款式与袖长。
进一步分析 rollout 流程,图 10(a) 给出基础设定下 4 个里程碑的桑基图。左右模型共同的最难点是“左肩套上衣夹”:机器人需先拉出在衣夹后方的左领口,再完成抓取,且需同时握住衣夹。另一常见失败模式是衣夹在左肩操作过程中滑落,导致最后一步失败。
-
-
7. 总结
局限与未来工作
尽管 GR-3 在挑战性任务中表现强劲,仍存在不足:面对包含全新概念或物体的未见指令时,模型会出错;对于形状前所未见的物体,抓取亦显吃力。作者计划通过扩大模型规模与训练数据量,持续提升模型对新场景的适应能力。此外,与所有模仿学习方法类似,GR-3 在 rollout 时可能陷入分布外状态且无法自行恢复。未来,作者拟引入强化学习(RL),以进一步提高复杂与灵巧任务的鲁棒性,突破模仿学习的性能上限。
结论
本报告介绍了 GR-3——一个强大的视觉-语言-动作(VLA)模型,可输出动作控制双臂移动机器人。作者系统研究了网络架构,并构建了涵盖以下要素的综合训练方案:与大规模视觉-语言数据协同训练、基于少量人类轨迹的高效小样本学习,以及基于机器人轨迹的有效模仿学习。在三大挑战性任务上的大量真实世界实验表明,GR-3 能够理解包含抽象概念的复杂指令,有效泛化至全新物体与环境,仅需极少人类轨迹即可快速适应,并在长跨度与灵巧任务中表现出卓越的稳健性与可靠性。作者希望 GR-3 能成为迈向通用机器人的重要一步,使其能够在现实世界中协助人类完成多样化任务。




 和迭代器详解:常见面试陷阱与深入理解)


)





的两种高效方法)





