在本章里,你将学习如何与字符集合打交道。
与可以匹配任意单个字符的.字符(参见第2章)不同,字符集合能匹配特定的字符和字符区间。
3.1 匹配多个字符中的某一个
第2章介绍的.字符,可以匹配任意单个字符。
当时在最后一个例子里,我们使用了.a来匹配na和sa,使用了.来匹配n和s。现在,如果在那份文件清单里增加了一个名为ca1.xls的文件,而你仍只想找出na和sa,该怎么办?别忘了.也能匹配c,所以文件名ca1.xls也会被找出。
①看下面的例子
文本
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
正则表达式
.a.\.xls
结果
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
既然只想找出n和s,使用可以匹配任意字符的.显然不行——我们需要的不是匹配任意字符,而是只匹配n和s这两个字符。
在正则表达式里,我们可以使用元字符[和]来定义一个字符集合。只有该字符集合内的字符之一(但并非全部),才可以满足匹配条件。
--PostgreSQL
with t1 as (
select 'sales1.xls' txt union all
select 'orders3.xl' txt union all
select 'sales2.xls' txt union all
select 'sales3.xls' txt union all
select 'apac1.xls' txt union all
select 'europe2.xl' txt union all
select 'na1.xls' txt union all
select 'na2.xls' txt union all
select 'sa1.xls' txt union all
select 'ca1.xls' txt
)
select * from t1
where txt ~ '.a.\.xls'
下面这个例子与第2章的最后一个例子相似,但在这次的正则表达式里使用了一个字符集合。
②看下面这个例子:
文本
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
正则表达式
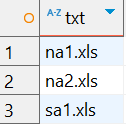
[ns]a.\.xls
结果
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
分析
这里使用的正则表达式以[ns]开头,这个集合将只会匹配字符n或s之一(但不匹配字符c或其他字符)。[和]不匹配任何字符,它们只负责定义一个字符集合。
接下来,正则表达式里的普通字符a匹配字符a,.匹配一个任意字符,\.匹配.字符本身,普通字符xls匹配字符串xls。
从结果上看,这个模式只匹配了3个文件名,与我们的预期完全一致。
注意 虽然结果正确,但模式[ns]a.\.xls并非完全正确。假如那份文件清单里还有一个名为usa1.xls的文件,它也会被匹配出来(开头的u会被忽略,匹配剩余的sal.xls)。这里涉及了位置匹配问题,我们将在第6章对此做专题讨论。
提示 正如看到的那样,对正则表达式进行测试是很有技巧的。验证某个模式能不能获得预期的匹配结果并不困难,但如何验证它不会匹配到你不想要的东西,可就没那么简单了。
with t1 as (
select 'sales1.xls' txt union all
select 'orders3.xl' txt union all
select 'sales2.xls' txt union all
select 'sales3.xls' txt union all
select 'apac1.xls' txt union all
select 'europe2.xl' txt union all
select 'na1.xls' txt union all
select 'na2.xls' txt union all
select 'sa1.xls' txt union all
select 'ca1.xls' txt
)
select * from t1
where txt ~ '[ns]a.\.xls'
字符集合,在不需要区分字母大小写(或者是只需匹配某个特定部分)的搜索操作里,比较常见。
③比如说:
文本
The phrase "regular expression" is often
abbreviated as RegEx or regex.
正则表达式
[Rr]eg[Ee]x
结果
The phrase "regular expression" is often
abbreviated as RegEx or regex.
分析
这里使用的模式包含两个字符集合:[Rr]负责匹配字母R和r,[Ee]负责匹配字母E和e。这个模式可以匹配RegEx和regex,但不匹配REGEX。
提示 如果你打算进行一次不需要区分字母大小写的匹配,不使用这个技巧也能达到目的。这种模式最适合用在从全局看需要区分字母大小写,但在某个局部不需要区分字母大小写的搜索操作里。
--PostgreSQL
--将RegEx、regex、Regex or regEx,全部识别出来,并替换为XXXXX
with t1 as (
select 'The phrase "regular expression" is often' txt
union all
select 'abbreviated as RegEx or regex.'
)
select txt,regexp_replace(txt,'[Rr]eg[Ee]x','XXXXX','g')
from t1
where regexp_replace(txt,'[Rr]eg[Ee]x','XXXXX','g')

3.2 利用字符集合区间
我们再来仔细看看,那个从一份文件清单里找出特定文件的例子。
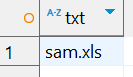
我们刚才使用的模式[ns]a.\.xls还存在另外一个问题。如果那份文件清单里有一个名为sam.xls的文件,结果会怎样?显然,因为.可以匹配所有的字符,而不是仅限于数字,所以文件sam.xls也会出现在匹配结果里。
这个问题可以用一个包含全部数字的字符集合来解决。
①看如下例子:
文本
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
sam.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
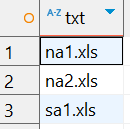
正则表达式
[ns]a[0123456789]\.xls
结果
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
sam.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
分析
在这个例子里,我们改用了另外一个模式,这个模式的匹配对象是:第一个字符必须是n或s,第二个字符必须是a,第三个字符可以是任何一个数字(因为我们使用了字符集合[0123456789])。注意,文件名sam.xls没有出现在匹配结果里,这是因为m与我们给定的字符集合(10个数字)不相匹配。
with t1 as (
select 'sales1.xls' txt union all
select 'orders3.xl' txt union all
select 'sales2.xls' txt union all
select 'sales3.xls' txt union all
select 'apac1.xls' txt union all
select 'europe2.xl' txt union all
select 'na1.xls' txt union all
select 'na2.xls' txt union all
select 'sa1.xls' txt union all
select 'ca1.xls' txt
)
select * from t1
where txt ~ '[ns]a[0123456789]\.xls'
在使用正则表达式的时候,会频繁地用到一些字符区间(0~9、A~Z等)。为了简化字符区间的定义,正则表达式提供了一个特殊的元字符:可以用-(连字符)来定义字符区间。
②下面还是刚才那个例子,但我们这次使用了字符区间:
文本
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
sam.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
正则表达式
[ns]a[0-9]\.xls
结果
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
sam.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
分析
模式[0-9]的功能与[0123456789]完全等价,所以这次的匹配结果与刚才那个例子一模一样。
字符区间并不仅限于数字,以下这些都是合法的字符区间。
A-Z,匹配从A到Z的所有大写字母。
a-z,匹配从a到z的所有小写字母。
A-F,匹配从A到F的所有大写字母。
A-z,匹配从ASCII字符A到ASCII字符z的所有字母。这个模式一般不常用,因为它还包含[和^等在ASCII字符表里排列在Z和a之间的字符。
字符区间的首、尾字符可以是ASCII字符表里的任意字符。但在实际工作中,最常用的字符区间还是数字字符区间和字母字符区间。
提示 在定义一个字符区间的时候,一定要避免让这个区间的尾字符小于它的首字符。例如[3-1],这种区间是没有意义的,而且往往会让整个模式失效。
注意 -(连字符)是一个特殊的元字符,它只有出现在[和]之间的时候才是元字符。在字符集合以外的地方,-只是一个普通字符,只能与-本身相匹配。因此,在正则表达式里,-字符不需要被转义。
在同一个字符集合里可以给出多个字符区间。比如说,下面这个模式可以匹配任何一个字母(无论大小写)或数字,但除此以外的其他字符(既不是数字也不是字母的字符)都不匹配:
[A-Za-z0-9]
这个模式是下面这个字符集合的简写形式:
[ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789]
如你所见,字符范围使得正则表达式的语法变得简洁多了。
with t1 as (
select 'sales1.xls' txt union all
select 'orders3.xl' txt union all
select 'sales2.xls' txt union all
select 'sales3.xls' txt union all
select 'apac1.xls' txt union all
select 'europe2.xl' txt union all
select 'na1.xls' txt union all
select 'na2.xls' txt union all
select 'sa1.xls' txt union all
select 'ca1.xls' txt
)
select * from t1
where txt ~ '[ns]a[0-9]\.xls'
下面是另一个例子,这次要查找的是RGB值(用一个十六进制数字给出的红、绿、蓝三基色的组合值,计算机可以根据RGB值把有关的文字或图象显示为由这三种颜色按给定比例调和出来的色彩)。
在网页里,RGB值是以#开头,类似000000(黑色)、ffffff(白色)、ff0000(红色)这样,6位a~f的字母或数字结尾的形式。RGB值用大写或小写字母给出均可,所以FF00ff(品红色)也是合法的RGB值。
③下面是取自CSS文件中的一个例子:
文本
div {background-color: #fefbd8;
}
h1 {background-color: #0000ff;
}
div {background-color: #d0f4e6;
}
span {background-color: #f08970;
}
正则表达式
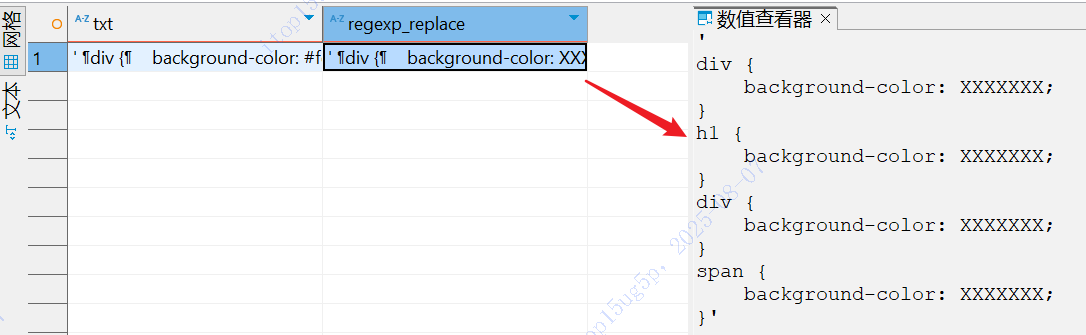
#[0-9A-Fa-f][0-9A-Fa-f][0-9A-Fa-f][0-9A-Fa-f][0-9A-Fa-f][0-9A-Fa-f]
结果
div {
background-color: #fefbd8;
}
h1 {
background-color: #0000ff;
}
div {
background-color: #d0f4e6;
}
span {
background-color: #f08970;
}
分析
这里使用的模式以普通字符#开头,随后是6个同样的[0-9A-Fa-f]字符集合。这将匹配一个由字符#开头,然后是6个数字或字母A到F(大小写均可)的字符串。
--PostgreSQL
--将所有RGB值,全部识别出来,并替换为XXXXX
with t1 as (
select '
div {background-color: #fefbd8;
}
h1 {background-color: #0000ff;
}
div {background-color: #d0f4e6;
}
span {background-color: #f08970;
}' txt
)
select txt
,regexp_replace(txt,'#[0-9A-Fa-f][0-9A-Fa-f][0-9A-Fa-f][0-9A-Fa-f][0-9A-Fa-f][0-9A-Fa-f]','XXXXXXX','g')
from t1
3.3 排除
字符集合,通常用来指定一组必须匹配其中之一的字符。但在某些场合,我们需要反过来做,即指定一组不需要匹配的字符。换句话说,就是排除字符集合所指定的那些字符。
不用逐个列出你要匹配的字符(如果只是要把一小部分字符排除在外的话,这种写法就太冗长了),可以使用元字符^来排除某个字符集合。
①下面来看一个例子:
文本
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
sam.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
正则表达式
[ns]a[^0-9]\.xls
结果
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
sam.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
分析
这个例子里使用的模式与前面的例子里使用的模式刚好相反。前面[0-9]只匹配数字,而这里[^0-9]匹配的是任何不是数字的字符,也就是说,[ns]a[^0-9]\.xls将匹配sam.xls,但不匹配na1.xls、na2.xls或sa1.xls。
注意 ^的效果将作用于给定字符集合里的所有字符或字符区间,而不是仅限于紧跟在^字符后面的那一个字符或字符区间。
--PostgreSQL
with t1 as (
select 'sales1.xls' txt union all
select 'orders3.xl' txt union all
select 'sales2.xls' txt union all
select 'sales3.xls' txt union all
select 'apac1.xls' txt union all
select 'europe2.xl' txt union all
select 'sam.xls' txt union all
select 'na1.xls' txt union all
select 'na2.xls' txt union all
select 'sa1.xls' txt union all
select 'ca1.xls' txt
)
select * from t1
where txt ~ '[ns]a[^0-9]\.xls'
3.4 小结
元字符[和]用来定义一个字符集合,其含义是必须匹配该集合里的字符之一(各个字符之间是OR的关系,而不是AND的关系)。
定义一个字符集合的具体做法有两种:
一是把所有的字符都列举出来。
二是利用元字符-以字符区间的方式给出。
可以用元字符^排除字符集合,强制匹配指定字符集合之外的字符。



)
)














