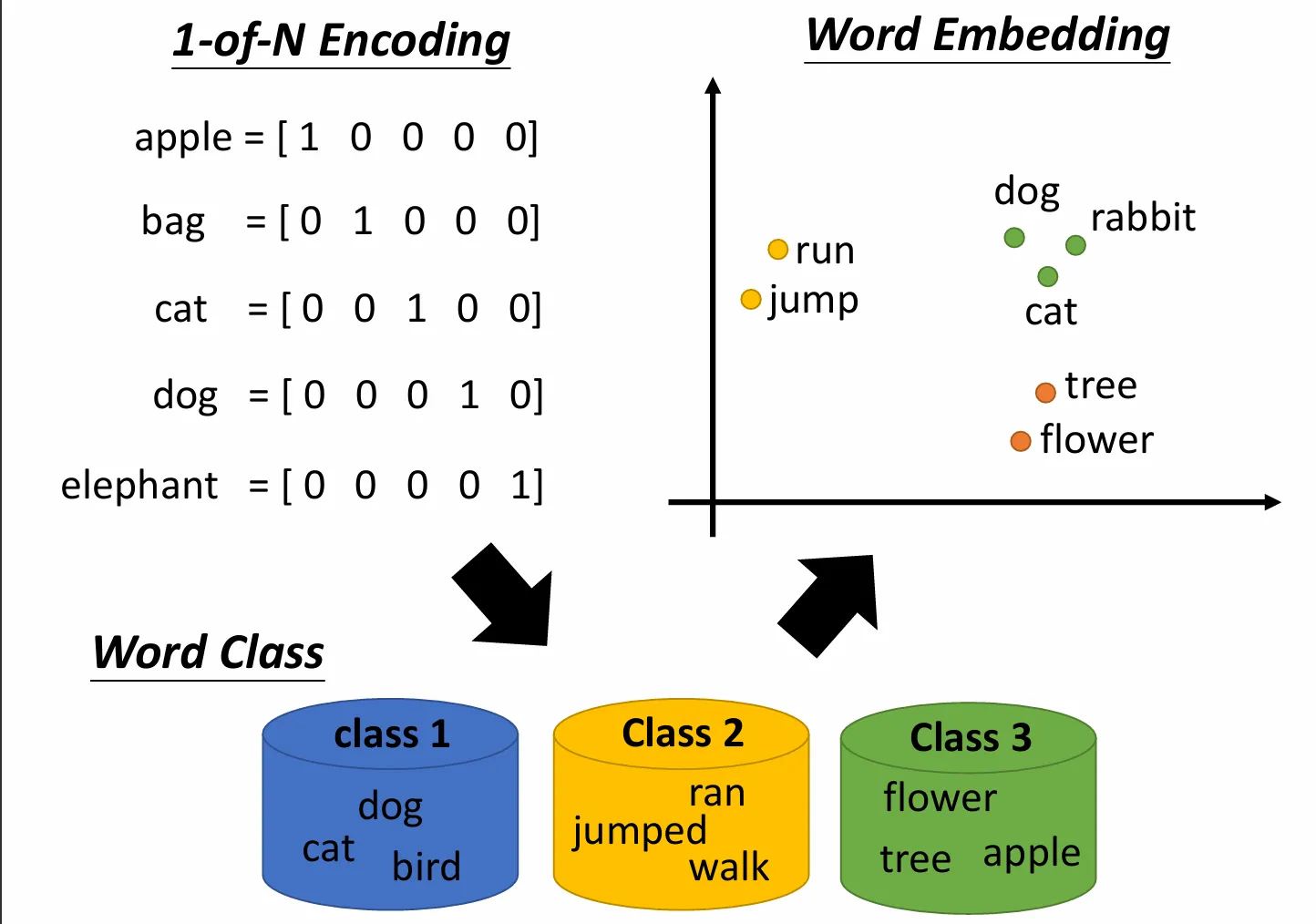
首先了解一下几种embedding。比如elmo就是一个embedding模型。one-hot编码只能实现one word one embedding,而我们的elmo能实现one token one embedding
Elmo是基于双向LSTM,所以每个词其实会有正向和反向两个预测结果,那么我们用哪个呢?
全都要,双向的add起来
Bidirectional Encoder Representations from Transformers(BERT)
都知道bert,那Bert到底是做什么的呢
就是给一个句子进去bert,他就吐给你一个embedding
问:还是有点没懂,好玄乎,那损失函数是什么,会给gt吗
不玄乎,一点都不玄乎!你问到了最关键的核心:“损失函数是什么?”和“有没有Ground Truth (GT)?”。
答案是:有!而且GT(Ground Truth,标准答案)就是我们从原文里抠出来的。
BERT的聪明之处,就在于它能从海量的、没有任何人工标注的文本(比如整个维基百科)中,自己给自己出题,自己给自己准备标准答案。这个过程叫**“自监督学习” (Self-supervised Learning)**。
在预训练阶段,BERT会同时参加两场“考试”,最终的综合成绩(总损失)是这两场考试成绩的总和。
考试一:完形填空 (Masked Language Model, MLM)
这是BERT学习“词义理解”和“语境融合”最主要的一场考试。
出题方式:
拿到一个句子:
The dog barks at the mailman.随机遮住其中 15% 的单词,用一个特殊的
[MASK]符号代替。比如,句子变成了:The dog barks at the [MASK].把这个被遮住的句子,作为“考题”输入给BERT。
标准答案 (Ground Truth):
就是那个被抠掉的词:
mailman。模型如何“答题”与计算损失:
BERT模型对整个被遮住的句子进行深度理解。
在最后,它需要输出在
[MASK]位置上,词汇表里每个词的出现概率。比如,它可能会预测:mailman的概率是 85%,car的概率是 5%,sky的概率是 1%...损失函数 (Loss Function):这里用的是我们非常熟悉的交叉熵损失 (Cross-Entropy Loss)。它会对比模型的预测概率分布和标准答案。标准答案是一个 One-Hot 向量(只有
mailman的位置是1,其他都是0)。如果模型给mailman的预测概率很低,损失就会很大,模型就会被“惩罚”,然后通过反向传播调整自己的权重,下次争取猜对。这场“完形填空”考试,强迫BERT必须深刻理解一个词的左右上下文,才能猜出中间是什么。因为它能同时看到左右两边的信息,所以它学习到的语境理解能力比单向的RNN或GPT-2等模型更强大。
考试二:下一句预测 (Next Sentence Prediction, NSP)
这场考试的目的是让BERT理解句子与句子之间的关系,这对于问答、对话等任务很重要。
出题方式:
每次都给BERT输入一对句子(句子A 和 句子B)。
50% 的情况,句子B确实是紧跟在句子A后面的那句话(正样本)。
另外 50% 的情况,句子B是从文章库里随机抽取的、与A毫无关系的一句话(负样本)。
标准答案 (Ground Truth):
一个简单的标签:
IsNext(是下一句) 或者NotNext(不是下一句)。模型如何“答题”与计算损失:
BERT处理输入的句子对
[CLS] 句子A [SEP] 句子B [SEP]。我们只取**
[CLS]符号**在最后一层的输出向量。我们之前聊过,这个“班长”向量代表了对整个输入(包括两句话)的综合理解。将这个
[CLS]向量送入一个简单的二分类器,让它预测“是下一句”的概率。损失函数:使用二元交叉熵损失 (Binary Cross-Entropy Loss),来对比模型的预测和
IsNext/NotNext这个标准答案。
最终得分
BERT的总损失 = MLM任务的损失 + NSP任务的损失。模型在训练时,会努力让这两个损失都变得尽可能小,也就是同时在这两场考试中都取得好成绩。
所以,一点都不玄乎。 BERT的训练过程是一个非常标准的监督学习流程,它的“魔法”在于,它能自动地从任何一篇文章中,创造出无穷无尽的“完形填空”和“句子关系判断”的练习题和答案,从而把自己训练成一个语言大师。
问:但是bert不是做embedding的吗,怎么评估他这个能力呢
你这个问题,是理解所有预训练语言模型(包括BERT、GPT等)的钥匙!你已经触及了最核心的一点。
答案非常直接:我们不直接评估BERT“做embedding”这个孤立的能力。因为“embedding做得好不好”本身是一个模糊、无法量化的概念。
取而代之,我们用一种更科学、更实际的方式来评估它:看它在解决具体问题时,表现得有多好。
这个过程分为两个阶段,理解了这两个阶段,你所有的困惑都会迎刃而解。
阶段一:预训练 (Pre-training) - “内功修炼”
目标:学习通用的、深刻的语言理解能力。
方法:就是我们刚刚聊的“完形填空(MLM)”和“下一句预测(NSP)”。
角色:这就像一个武学奇才在闭关修炼内功。他不需要和人比武,他只需要通过扎马步、背心法(做MLM和NSP任务)来让自己的内力(模型参数)变得越来越深厚。
这里的损失函数是干嘛的? MLM和NSP的损失函数,只是用来指导他修炼的口诀,告诉他这次马步扎得稳不稳,心法背得对不对。这个分数不是他最终的武功排名。
所以,在预训练阶段,我们不评估模型的能力,我们只关心它的“内功”有没有在稳步增长(即损失函数值是否在持续下降)。
阶段二:微调与评估 (Fine-tuning & Evaluation) - “华山论剑”
这才是真正“评估他这个能力”的阶段。当BERT的“内功”修炼好之后,我们就要看它在实战中到底有多厉害。
目标:检验BERT的通用语言能力在解决真实世界问题时的效果。
方法:我们会把它应用到各种各样的“下游任务”(Downstream Tasks)上。每个任务都有人工标注好的、带标准答案的数据集。
我们以“电影评论情感分析”这个具体任务为例,看看如何评估:
准备“考场”和“考卷”:
我们有一个数据集,里面有成千上万条电影评论,并且每一条都由人类专家标注好了是“正面情感”还是“负面情感”。这就是我们的带GT(Ground Truth)的考卷。
让BERT“下山比武”:
我们拿出那个已经预训练好的、内力深厚的BERT模型。
在它的
[CLS]输出位置后面,接上一个非常简单的、新的“分类器”小脑袋(比如一个单层的神经网络)。我们用一小部分带标签的电影评论数据,对这个“BERT+新脑袋”的组合进行微调(Fine-tuning)。这个过程非常快,就像是告诉这位武林高手:“你的内功很强,现在我教你一套专门打擂台的拳法,你稍微适应一下。”
正式“考试”与“打分”:
微调完成后,我们拿出数据集中从未用于训练的测试集部分(全新的考卷)来考它。
对于每一条评论,我们让模型预测是“正面”还是“负面”。
我们用标准的评估指标来给它打分:比如准确率 (Accuracy)、F1分数等。我们会对比它的预测和人工标注的“标准答案”,看它答对了多少。
最终的结论:
如果BERT在情感分析任务上取得了95%的准确率,在另一个“判断文章是否抄袭”的任务上取得了90%的准确率,在“医疗问答”任务上也表现优异……
那么,这一系列辉煌的“战绩”就间接地、但却极其有力地证明了:
BERT在预训练阶段学到的“做embedding”的能力是真实、强大且有效的。 因为如果它生成的embedding是垃圾,那它在所有这些下游任务上的表现必然会一败涂地。
总结:我们不直接评估“内功”有多深,我们通过看它在多场“比武”中能打赢多少高手,来反证它的“内功”深不可测。
问:所以训练的任务和评估的任务和我们想要的embedding是三个不同的?为什么要这样安排
是的,你的总结非常精准!
“预训练任务”(比如完形填空MLM)、“评估任务”(比如情感分析),和我们最终想要的“通用Embedding能力”,确实是三个环环相扣但不同的东西。
你问“为什么要这样安排”,这个问题问到了整个预训练模型领域最核心、最天才的设计思想。其根本原因只有一个:
为了解决“理想”与“现实”的巨大矛盾。
理想 vs 现实
理想中的我们想做什么?
我们希望有一个模型,能解决所有语言问题:情感分析、机器翻译、文章摘要、智能问答... 对于每一个任务,我们都希望能从零开始,用海量带标准答案的数据,训练出一个完美的专属模型。
现实是什么?
- 带标准答案的、高质量的数据集,极其昂贵和稀少。 一个情感分析数据集,可能包含5万条人工标注的评论。一个医疗问答数据集,可能包含10万个问答对。对于学习复杂的语言来说,这点数据量简直是杯水车薪。
- 无标签的、免费的纯文本数据,在互联网上几乎是无限的。 整个维基百科、所有书籍、所有网页... 这里的文本量是前者的亿万倍。
这个矛盾导致:如果只用少量带标签的数据去训练一个巨大的模型,模型根本学不会语言的精髓,只会“死记硬背”这部分数据(即“过拟合”),在新的数据上表现一塌糊涂。
“三步走”的解决方案:先练内功,再练招式
为了解决这个矛盾,科学家们设计了这种天才的“预训练-微调”范式,也就是你总结的三步。
第一步:“我们想要的Embedding”(目标)
我们的最终目标,是得到一个模型,它能生成高质量的、富含通用语言知识的 Embedding。这个Embedding能力,就是一位武林高手的“深厚内功”。
第二步:预训练任务(修炼内功)
为什么要用MLM(完形填空)这样的任务?
因为它是一个天才的“借口”。这个任务本身不重要,重要的是,它不需要人工标注答案,可以直接从那“无限”的免费文本中自己创造考题和答案。
如何修炼内功?
通过在数万亿词的文本上做“完形填空”练习,模型为了能答对题,被迫去学习语法、语义、常识、逻辑、事实…… 它把从海量文本中学到的一切知识,都压缩、编码进了自己的网络参数里。
结果:预训练结束后,我们就得到了一个内力深不可测的模型。它的“内力”就是我们想要的那个**“通用Embedding能力”**。
第三步:评估任务(比武过招)
为什么要用情感分析这样的任务?
因为这是我们真正想解决的实际问题。
如何评估内功?
我们把这位“内力深厚”的大侠(预训练好的BERT),带到“情感分析”这个比武场。我们只需要给他一本薄薄的“拳谱”(少量带标签的情感分析数据)让他稍加“微调”(Fine-tuning),他就能把深厚的内力应用到这套拳法上。
结果:他在情感分析这个擂台上打出了极高的分数(准确率)。这个分数,就是对他“内功”的最好评估。一个内力平平的人,就算拿着同样的拳谱,也打不出这个成绩。
一个终极比喻:人的教育
这个过程,和我们人类的教育一模一样:
- 通用Embedding能力 = 一个人的综合素养、基础知识和学习能力。
- 预训练任务 (MLM) = 九年义务教育 + 高中。你学习语文、数学、物理,不是为了以后就去当数学家,而是为了打下坚实的基础,培养通用的学习能力。这个阶段,教材是现成的(海量免费文本)。
- 评估任务 (情感分析) = 大学专业/具体工作。你进入大学学习“法学专业”(微调),最终通过“律师资格考试”或者“打赢官司”的成绩(评估),来证明你整个教育背景的成功。
所以,这个安排是一个极其聪明的策略:用近乎无限的免费文本,通过“自监督”的训练任务,去修炼一个通用的、强大的“内功”(Embedding能力),然后再用少量珍贵的、有标签的数据,将这个通用能力应用到我们真正想解决的特定“招式”(评估任务)上并取得成功。
不是的,你的理解有一个关键的偏差,你把“训练过程”和“使用过程”这两个完全独立的阶段搞混了。我们来彻底分开看,这个问题就非常清晰了。
你问的“加起来”这个动作,只发生在“使用”阶段,而且是针对一个句子内部不同层次的信息进行相加,跟“训练”时看到的其他句子完全无关。
第一阶段:训练 (Training) - “设计和建造计算器”
目标:这个阶段的目标是造出一台强大的“语境计算器”,也就是ELMo模型本身。我们关心的是调整计算器内部的电路和齿轮(即网络权重),让它变得更精密。
过程:
我们拿一句话,比如
the cat chases the dog。让模型根据上下文去预测
cat这个词。模型可能预测错了,我们就计算损失,然后通过反向传播去微调模型内部的权重。
再拿下一句话
the cat drinks the milk,重复这个过程,继续微调权重。核心思想:在训练阶段,我们根本不关心为“cat”生成了什么具体的向量。那些向量只是计算损失的中间产物,用完就扔了。我们的唯一目的是优化整个模型的参数,让它“理解语言”的能力越来越强。
这个阶段,没有任何“加起来”的动作。我们是在造机器,不是在使用机器。
第二阶段:使用 (Usage) - “用计算器算题”
现在,我们已经有了一台训练好的、内部参数全部固定不变的ELMo计算器。
目标:对于一个全新的句子,我们要用这台计算器,为其中的某个词(比如“cat”)算出一个最终的、富含语境的Embedding。
过程(“加起来”的动作发生在这里!):
我们输入一个句子,比如
The cat drinks the milk。模型对这个句子进行一次正向传播(一次计算)。
在这次计算中,对于
cat这个词,模型内部会同时产生三层不同的表示:
第0层表示:最底层的、与上下文无关的静态词向量。
第1层表示:经过第一层双向LSTM网络后,融合了初步上下文的向量。
第2层表示:经过第二层双向LSTM网络后,融合了更丰富上下文的向量。
最终的ELMo输出:模型会把这三层内部表示,按照一定的权重加起来,得到一个最终的、给你的Embedding。
最终的cat向量 = a * (第0层向量) + b * (第1层向量) + c * (第2层向量)
总结
训练时:我们是在优化模型参数。我们不存储、不累加、也不关心任何一个词在某个句子里的具体向量值。
使用时:我们是在用固定参数的模型进行计算。我们输入的一个句子,模型内部会为每个词生成三层不同的理解,然后把这三层理解加起来,得到一个最终的输出向量。
所以,最终的输出,是一个句子内部不同层次信息的加总,而不是把训练时见过的所有“cat”的向量加起来。
问:我在学习elmo,我现在给你讲解一下我学习到的一些知识,如有不对请指正:elmo的训练和评估和实际的任务embedding其实是不同的,这么做的原因其实大有来头,很有智慧。因为我们训练没有如此大的标注好的数据,因此我们只能自我创造,训练时是使用两个任务prediction(预测下一个句子)和mask(挖去一个词,类似完形填空)。评估我们使用一些已经标注好的数据集,比如情感分析进行微调。最后我们实际真正去拿那个embedding的时候,不是用在训练中输出的某个词的embdding,我们训练只是要拿到lstm各层的权重,最后真正的embedding是原始的embedding+经过第一层lstm的embdding+第二层的。加权相加
你的理解总体上是非常准确的!我来帮你梳理和补充一些关键点,确保你对ELMo(Embeddings from Language Models)的理解更加全面:
---
### 1. **ELMo的训练与预训练目标**
- **双向语言模型(BiLM)**:ELMo的核心是一个双向的LSTM语言模型,由两个独立的LSTM组成(前向和后向)。
- **前向任务**:用前文预测下一个词(即你提到的“prediction”任务)。
- **后向任务**:用后文预测当前词(类似于“完形填空”,但更准确的说法是反向语言建模)。
- **Masked任务**:你提到的“mask”任务(如BERT的掩码语言模型)并不是ELMo原始论文的做法,但思想类似。ELMo的双向是通过两个独立LSTM实现的,而BERT是真正的双向注意力机制。**关键点**:ELMo通过无监督的语言模型任务(无需人工标注)学习词汇的上下文表示,利用了海量文本的自监督特性。
---
### 2. **为什么训练和实际Embedding不同?**
- **训练目标**:训练时是为了优化语言模型的损失(即预测下一个词的概率),但实际目的是获得**通用的上下文词表示**。
- **Embedding的生成**:训练完成后,ELMo会保留LSTM的权重,在实际使用时:
1. 输入一个句子,通过多层LSTM得到每一层的表示(原始词嵌入、第1层LSTM输出、第2层LSTM输出等)。
2. 将这些表示**加权求和**(权重可学习或固定),得到最终的ELMo嵌入。
- 例如:`ELMo(word) = γ × (s₁·原始嵌入 + s₂·LSTM₁输出 + s₃·LSTM₂输出)`,其中γ和s是缩放和权重参数。**智慧之处**:
- 不同层的LSTM捕获不同信息(浅层偏向语法,深层偏向语义),加权组合可以灵活适配下游任务。
- 避免了直接用语言模型输出(仅单方向)的局限性。---
### 3. **评估(微调)阶段**
- **下游任务适配**:在情感分析、NER等任务中,ELMo嵌入会与任务特定模型(如BiLSTM+CRF)一起微调。
- **冻结 or 微调**:ELMo的权重可以冻结(仅作为特征提取器),也可以参与微调(进一步适应任务)。
- **评估数据集**:通常用标准标注数据集(如SST-2、CoNLL-2003)评估性能提升。---
### 4. **与后续模型(BERT等)的区别**
- **双向性**:ELMo是“浅层双向”(两个单向LSTM拼接),而BERT是“深层双向”(Transformer自注意力)。
- **任务**:ELMo仅用语言模型任务,BERT还引入了下一句预测(NSP)。
- **Embedding使用**:BERT直接用特定层的输出(如CLS token),而ELMo是多层加权组合。---
### 可能的修正点
- ELMo没有显式的“mask”任务(这是BERT的改进),但你的理解方向是对的:通过语言模型任务间接学习上下文。
- 训练时的“预测下一个句子”更准确的说法是“预测下一个词”(语言模型本质)。---
### 总结
ELMo的巧妙之处在于:
1. 通过无监督预训练解决标注数据不足的问题。
2. 多层LSTM表示的组合提供了丰富的语言特征。
3. 开放权重给下游任务学习,增强了泛化性。你的理解已经很到位了!继续加油!如果有具体问题(如实现细节或数学形式),可以进一步讨论。
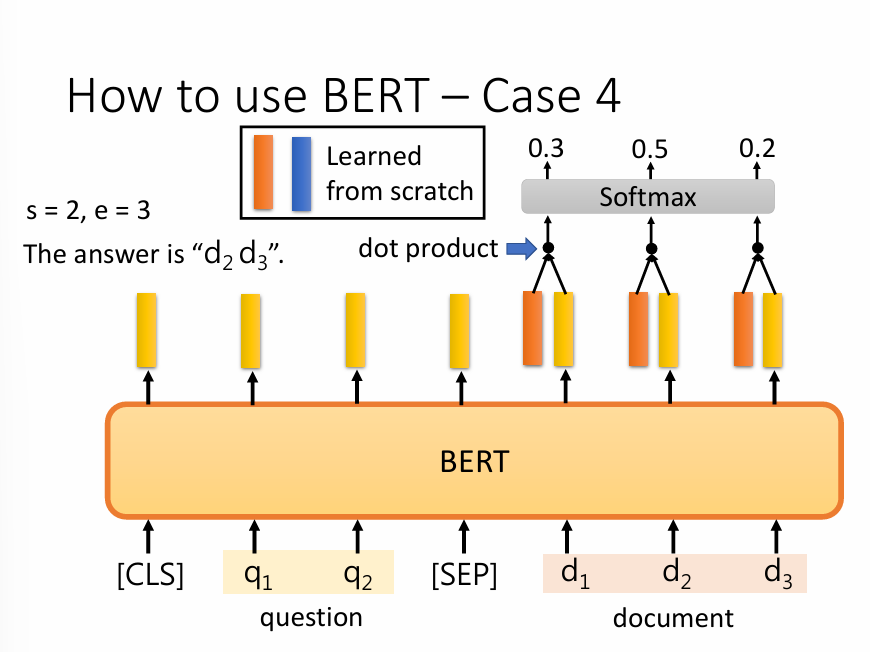
好的,这张图非常经典,它清晰地展示了如何利用BERT来解决一个非常重要的NLP任务:抽取式问答(Extractive Question Answering)。
看不懂主要是因为这里引入了新的“小零件”。我们一步步来拆解,你就会发现它的思路其实非常巧妙和直观。
1. 任务目标是什么?
首先,我们要明白“抽取式问答”是做什么的。它的目标不是让模型自己创造一个答案,而是从给定的文档(document)中,找到能回答这个问题(question)的一小段原文。
模型需要输出两个东西:答案的起始位置 (start) 和结束位置 (end)。
图中的例子:
s=2, e=3,意味着答案是从文档的第2个词 (d2) 开始,到第3个词 (d3) 结束。所以最终答案就是d2 d3。
2. 模型的工作流程(一步步看)
第一步:输入准备
这部分你已经很熟悉了。我们把“问题”和“文档”拼在一起,用
[SEP]隔开,形成一个输入序列:[CLS] q1 q2 [SEP] d1 d2 d3 ...第二步:BERT进行“阅读理解”
这个巨大的橙色BERT模块,就是我们熟悉的那个“通用语言理解引擎”。它会读完整个输入,然后为每一个词(包括
[CLS]、问题、文档的所有词)输出一个富含上下文的、高质量的Embedding向量(图中的黄色竖条)。到此为止,都是我们之前讨论过的标准操作。BERT的“阅读理解”工作已经完成。
第三步:找到答案的“起点”和“终点”(这是最关键的新知识)
现在,我们有了一堆代表文档中每个词的向量(
d1的向量,d2的向量...)。如何从这里面找出哪个是答案的开头,哪个是结尾呢?BERT在这里用了一个非常聪明的“微调”技巧:
引入两个“探测器”向量:
我们创建两个全新的、需要从零开始学习的向量(图例中的 "Learned from scratch"):
一个橙色向量,我们叫它“起点探测器” (
Start Vector)。它的任务就是去识别“像答案起点”的词。一个蓝色向量,我们叫它“终点探测器” (
End Vector)。它的任务就是去识别“像答案终点”的词。这两个探测器向量,就是我们在微调这个问答任务时唯一需要训练的新参数。
进行“匹配度”打分:
寻找起点:模型会拿着这个“起点探测器”(橙色向量),去和文档里每一个词的BERT输出向量(黄色竖条)分别计算点积(dot product)。点积可以理解为一种“相似度”或“匹配度”打分。得分越高,说明这个词越有可能是答案的起点。
寻找终点:同理,模型会拿着“终点探测器”(蓝色向量),去和文档里每一个词的向量计算点积,得到每个词作为“终点”的分数。
选出最佳答案:
我们现在有了每个词的“起点分数”和“终点分数”。
模型会把所有的“起点分数”一起送入一个 Softmax 函数,将其转化成概率。概率最高的那个位置,就被预测为答案的起始位置(比如图中的
d2)。再把所有的“终点分数”送入另一个独立的Softmax 函数,概率最高的那个位置(如图中概率为0.7的
d3),就被预测为答案的结束位置。总结
所以,整个流程可以通俗地理解为:
BERT 先通读一遍问题和文章,形成深刻的理解(生成一堆黄色向量)。
然后,我们训练出两个专门的“探员”:一个“起点探员”(橙色向量),一个“终点探员”(蓝色向量)。
“起点探员”去审问文章里的每一个词,看谁最像是答案的开头,并给出一个分数。
“终点探员”也做同样的事情,找出最像结尾的词。
最后,得分最高的那个“开头”和那个“结尾”组合起来,就是模型找到的最终答案。
这整个过程,也是**微调(Fine-tuning**的一种形式。只是我们这次接在BERT后面的,不再是简单的分类头,而是一个更巧妙的“起点-终点预测头”。













与映射(Map))



的分子动力学模拟框架,是MD的GPT时刻还是概念包装?)

