查看服务器上的硬盘:
lsblk -d -o NAME,SIZE,MODEL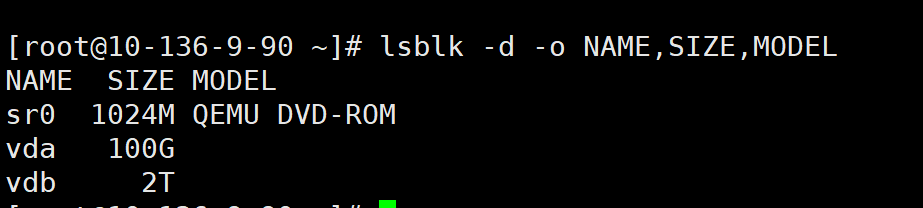
可以看到我的硬盘是除了vda系统盘以外,还有个vdb。
我们查看一下分区:
lsblk可以看到:vdb 1T disk (底下没有分区,也没有挂载)
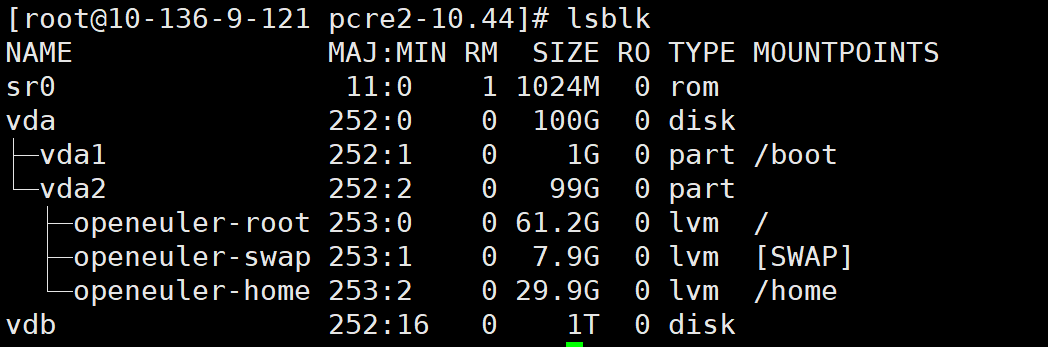
我们想要用起来这个硬盘,就要先分区并给他弄个挂载目录。
硬盘分区
在 Linux 下,所有硬盘、分区、甚至一些设备都是以 设备文件 的形式存在 /dev 目录下,所以你操作硬盘、分区时都要加上 /dev/。
所以我们要操作vdb盘,就要这样,会进入到分区工具中:
sudo fdisk /dev/vdb然后依次输入
g # 创建 GPT 分区表(硬盘大于 2T就必须创建。如果硬盘没2T就不用了)
n # 新建一个分区
# 回车使用默认分区号、起始扇区和结束扇区(默认覆盖整个硬盘)
p # 打印查看分区,确认 /dev/vdb1 已生成
w # 写入分区表并退出
n(新建分区)的时候,会有几个选项:
Command (m for help): n Partition number (1-128, default 1): 这是 fdisk 交互提示你选择新分区号。一般直接回车就行,它会直接默认将新分区命名为 /dev/vdb1
First sector (2048-4294967262, default 2048): 这是 fdisk 提示你选择新分区的起始扇区。一般也是直接回车就行,fdisk 会用默认值开始新分区。
Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-4294967262, default 4294967262):这是 fdisk 提示你选择新分区的结束扇区。一般我们就是 让这个分区占满整块硬盘,直接 回车 就行,fdisk 会用默认值。
挂载目录
格式化分区
sudo mkfs.ext4 /dev/vdb1 # 格式化分区挂载
sudo mkdir -p /data # 创建挂载目录
sudo mount /dev/vdb1 /data # 挂载挂载的意思就是,你对这个目录的操作,其实本质都是在挂载目录上操作。比如,我现在往/data目录存一个文件,文件其实是存在 vdb盘的 vdb1这个分区上的。
更换挂载
比如我现在要挂载到/data2这个目录,就直接执行挂载命令即可。
sudo mount /dev/vdb1 /data2查看挂载情况
df -h![]()
这个也行:
lsblk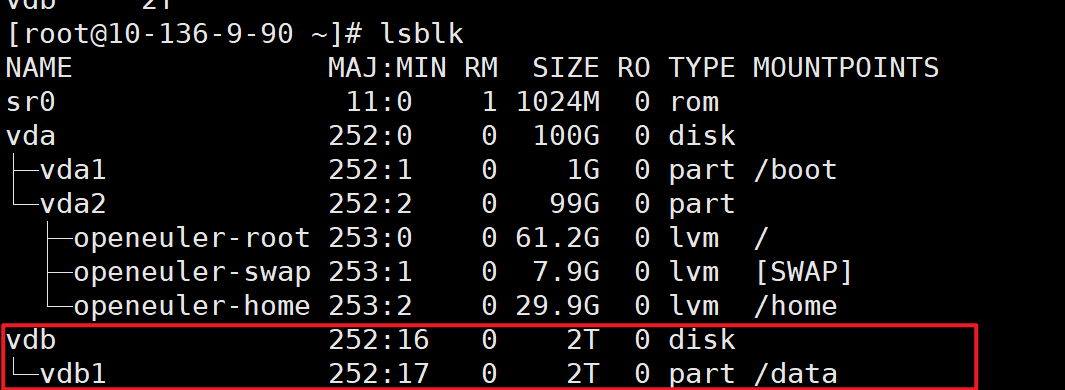
开启自动挂载
上述挂载操作是手动挂载的。重启服务器后挂载关系会消失。东西是不会丢,数据仍在 /dev/vdb1上。但是每次都得执行sudo mount /dev/vdb1 /data一下,才能到/data目录下正常访问。所以我们要配置一下开机自动挂载:
# 编辑 /etc/fstab
sudo vim /etc/fstab添加这一行:
/dev/vdb1 /data ext4 defaults 0 0
/dev/vdb1→ 硬盘分区/data→ 挂载点ext4→ 文件系统类型(格式化时用的)defaults→ 默认挂载选项0 0→ 不做 dump/backups,也不检查文件系统
保存后,可以测试:
sudo umount /data
sudo mount -amount -a 会根据 fstab 自动挂载所有配置的分区
然后用 lsblk检查一下即可。




》)
什么是IEC白皮书)









![[docker/大数据]Spark快速入门](http://pic.xiahunao.cn/[docker/大数据]Spark快速入门)



