一、安装基础环境
# 1、创建环境
conda create -n suna python==3.11.7# 2、激活虚拟环境
conda activate suna# 3、安装jupyter和ipykernel
pip install jupyter ipykernel# 4、将虚拟环境添加到jupyter
# python -m ipykernel install --user --name=myenv --display-name="Python (myenv)"
python -m ipykernel install --user --name=suna二、安装suna环境
切换到源码路径下
cd /Users/dcs/study/Suna修改后项目源码/suna/backend然后使用pip install,安装Suna项目依赖
pip install -r requirements.txt安装完成后,我们进入项目前端文件夹(frontend)
然后使用npm install安装前端依赖,
cd /Users/dcs/study/Suna修改后项目源码/suna/frontendnpm install
三、配置Suna项目后端
Suna的后端配置总共需要完成以下四步,主要是进行此前介绍的部分核心组件的配置,
- 配置1、tavily API-KEY:开启网络搜索功能
- 配置2、firecrawl API-KEY:开启网络爬虫功能
- 配置3、Daytona:开启沙盒环境功能
- 配置4、supabase:开启完整后端支持
配置1、tavily API-KEY:开启网络搜索功能
第一步需要获取搜索引擎tavily的API KEY,我们需要登录tavily官网( Tavily),完成注册并获取API-KEY,

然后进入Suna项目的后端(backend)文件夹,用文本编辑器打开.env文件,该文件是后端配置文件,

然后将刚刚复制的API-KEY写入TAVILY_API_KEY中,记得要随时保存。
配置2、firecrawl API-KEY:开启网络爬虫功能
接下来继续获取网络爬虫firecrawl的API KEY,同样需要登录firecrawl官网( Firecrawl),完成注册后在dashboard页面复制API-KEY

然后同样是在.env文件中写入FIRECRAWL_API_KEY。
配置3、Daytona:开启沙盒环境功能
继续设置沙盒环境工具Daytona,Daytona的设置稍微比较复杂,我们需要先进入Daytona官网( Daytona - Secure Infrastructure for Running AI-Generated Code)并进行注册;
然后Daytona需要搭配一个Suna镜像才能顺利运行,因此我们需要点击左侧的Image(镜像)选项,然后点击右上角的Create Image(创建镜像),然后输入既定的Image Name和Entrypoint,然后点击创建。这段文本较为复杂,大家可以领取文字版课件后直接复制。

- Image name: kortix/suna:0.1.2
- Entrypoint: /usr/bin/supervisord -n -c /etc/supervisor/conf.d/supervisord.conf
然后等待镜像导入完成即可。

接下来点击左侧Keys选项并创建API-Key

最后,将创建好的Daytona API-KEY写入.env配置文件。到这里,第三项配置就完成了。
配置4、supabase:开启完整后端支持
配置后端服务工具supabase。还是一样,需要登录supabase官网,并根据引导完成注册和项目创建,
例如这里我创建了一个名为test的项目

然后在项目主页左侧选择Project setting,然后点击Data API,往下翻找到schemas选项,确保选择了如图所示的三种格式。

然后在当前页面往上翻,找到如图所示三项核心信息,并分别复制填入.env文件中箭头所示这三个变量里。

然后保存.env文件并退出。
接下来回到后端文件夹的命令行中,输入如下三项命令,第一条命令是是登陆supabase,输入后会自动弹出确认登陆的网页;
npx supabase login npx supabase link --project-ref <your-project-ref> npx supabase db push

如果需要输入验证码,从自动打开的网页里面复制。

输入账号密码即可。第二条link命令是在本地设置默认项目,需要关联到supabase对应的项目ID;
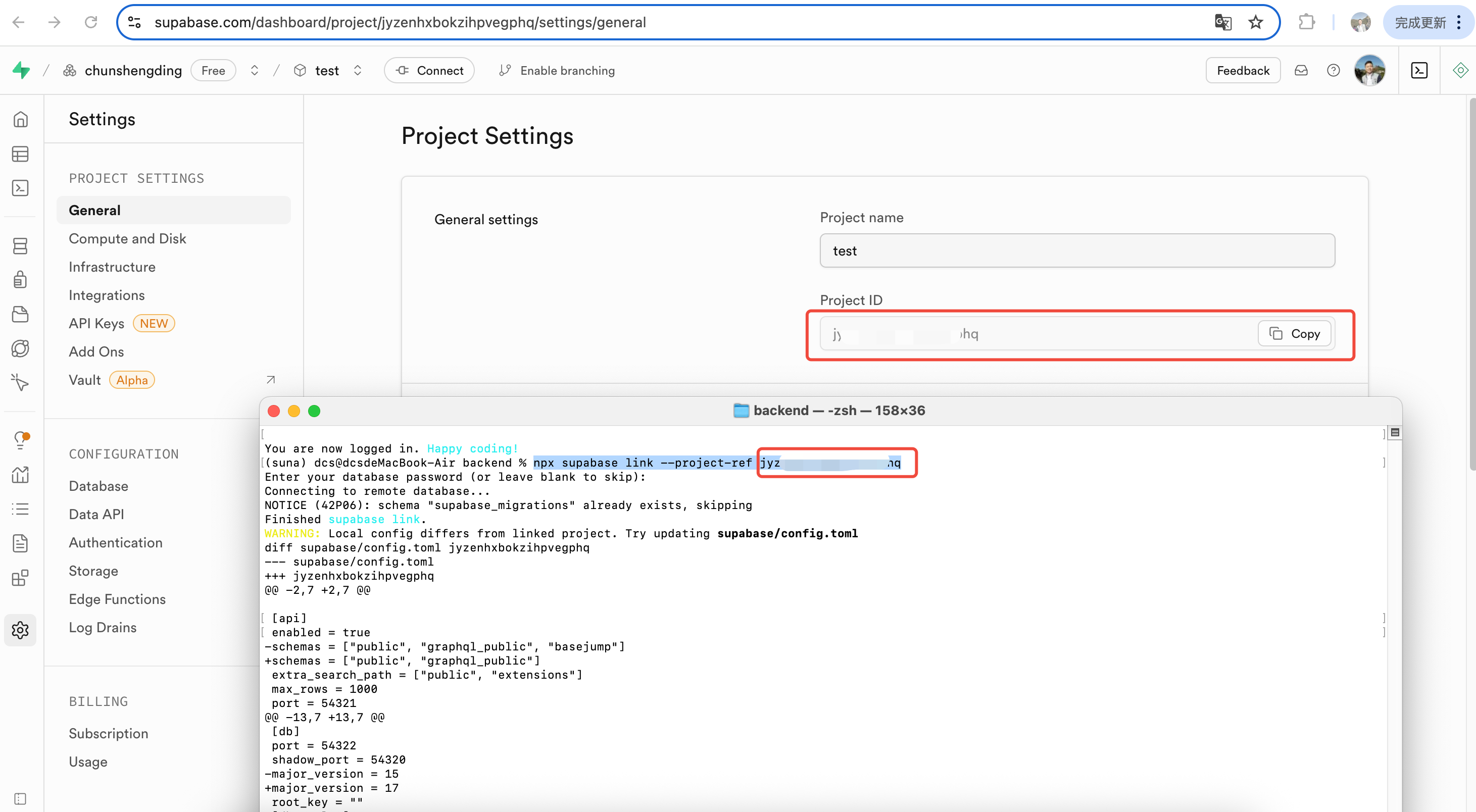
而第三条push命令则是将本地数据表格式同步到关联的项目中。
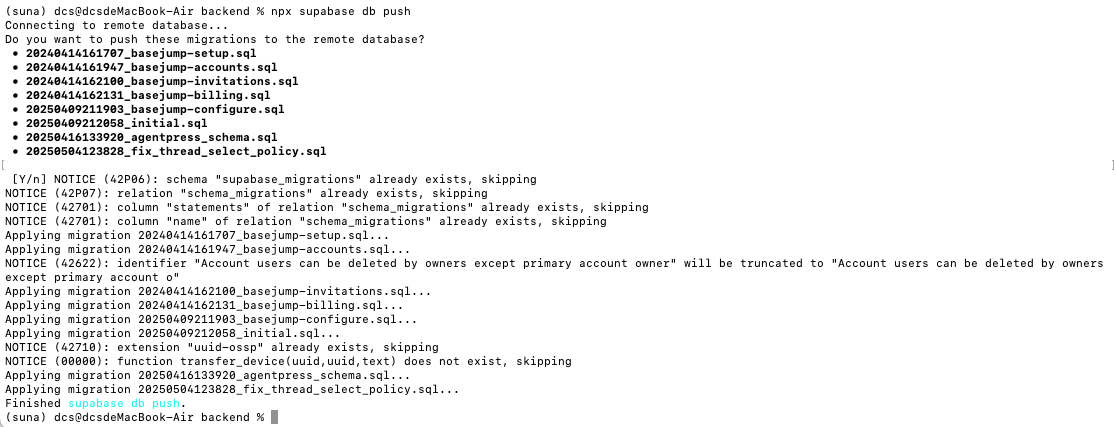
全部执行完后,Suna后端配置全部完成。
最终env文件

四、配置Suna底层大模型
最后第三个阶段,让我们设置Suna的基础模型配置。这里强烈推荐大家分别为Suna的前端和后端配置不同的模型,能够大幅加快Suna的响应速度。
- 配置Suna后端大模型API:Claude 3.7模型
- 配置Suna前端大模型API:DeepSeek模型
首先在后端配置中,推荐使用Claude 3.7模型,这是目前Agent能力最强的模型,同时也是Suna的默认模型。我们可以直接在某宝上购买Claude官方API-KEY,也可以自行注册,然后在后端的配置文件.env文件中写入Claude API-KEY即可。

此外,也可以输入OpenRouter的API-KEY,来调用包括DeepSeek模型在内的各项主流模型。
紧接着,我们用文本编辑器打开前端配置文件.env.local;

然后如图所示,把部分后端配置复制写入前端配置文件中,并在最后一行OPENAI_API_KEY一栏写入DeepSeek官方的API-KEY,这就是全部的前端配置了。
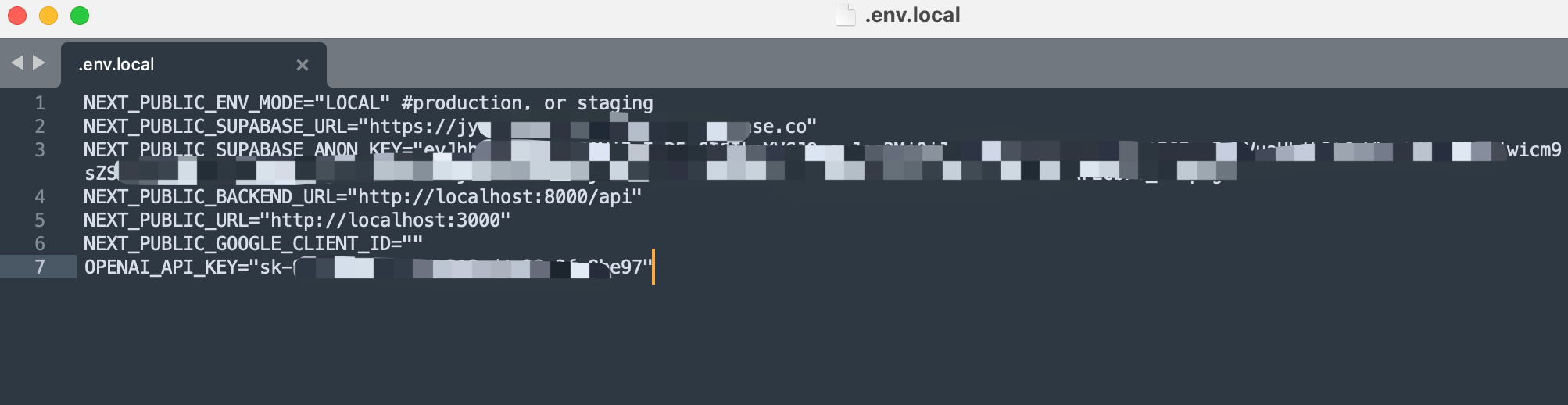
然后记得保存并退出。
至此,准备工作全部完成,接下来即可按照如下流程启动Suna了!
- 第一步:借助docker启动Redis
- 第二步:启动Suna后端
- 第三步:启动Suna前端
激动人心的时刻来了,首先需要借助docker启动Redis。我们需要确保之前安装的docker已经启动,然后在后端文件夹中打开命令行,输入Redis启动命令。
docker compose up redis
然后同样在后端文件夹中再打开一个命令行,输入如下命令开启Suna的后端服务。
cd /Users/dcs/study/Suna修改后项目源码/suna/backend python api.py

最后,在前端文件夹中打开命令行,输入如下命令开启Suna前端。
cd /Users/dcs/study/Suna修改后项目源码/suna/frontend npm run dev # 注意:如果提示没权限/suna/frontend/node_modules/.bin/next: Permission denied, # 请赋予权限 chmod +x /Users/dcs/study/Suna修改后项目源码/suna/frontend/node_modules/.bin/next

前端启动后,我们就能本地浏览器输入localhost:3000,即可使用Suna了!使用前会要求先注册,使用任意邮箱注册即可;

然后即可登录到对话页面,开始进行对话了!suna支持普通对话聊天,也可以执行各类复杂任务,大家现在看到的就是一个完整的复杂任务执行任务流程,整个过程Suan会先进行任务规划,然后一步步执行,执行过程中能够调用命令行、操作浏览器、编写Python代码、并且还能在沙盒环境中创建和编写相关文件等等等等。

五、功能介绍
简单来说,Suna就是一个全能型AI助手,它可以通过自然对话的方式帮你完成各种实际任务。它不仅仅是个聊天机器人,而是能真正帮你解决问题、自动化工作流程的数字伙伴。
最棒的是,它完全开源!
Git地址: https://github.com/kortix-ai/suna

以下是Suna四个主要组件:
后端API
Python/FastAPI服务,负责处理REST端点、线程管理,以及通过LiteLLM与OpenAI、Anthropic和其他LLM进行集成。
前端
Next.js/React应用程序,提供响应式用户界面,包括聊天界面、仪表板等。
Agent Docker
为每个代理提供的隔离执行环境 - 具有浏览器自动化、代码解释器、文件系统访问、工具集成和安全功能。
Supabase数据库
处理数据持久化,包括认证、用户管理、对话历史、文件存储、代理状态、分析和实时订阅。
Suna能做什么?
- Suna就像你的私人助理,拥有一系列强大的功能:
- 浏览器自动化:可以自动浏览网页、提取数据
- 文件管理:创建和编辑文档
- 网络爬虫:收集网络信息
- 扩展搜索:帮你找到需要的信息
- 命令行执行:处理系统任务
- 网站部署:简化网站上线流程
- API集成:连接各种服务和平台
这些功能不是单独存在的,而是完美协作,让Suna能通过简单的对话就帮你解决复杂问题。
实际应用案例
说实话,Suna的能力真的很强大,下面是官方的例子:
- 市场竞争分析
你只需对Suna说:“分析英国医疗行业市场,告诉我主要竞争者、市场规模、优势和劣势,以及他们的网站链接。完成后,生成PDF报告。”
Suna就会帮你完成这整个过程!从搜索到整理,再到生成报告,全自动完成。
- 寻找投资机会
如果你需要找风投,可以这样说:“根据管理资产规模,给我列出美国最重要的风险投资基金清单。提供他们的网站URL,如果可能的话,还有联系邮箱。”
- 人才招聘辅助
招人难?试试这样:“去LinkedIn上找10个当前可用的初级软件工程师候选人,他们应该位于德国慕尼黑,至少有计算机科学或相关专业的学士学位,以及任何领域1年的工作经验。”
- 公司旅行规划
计划团建?就说:“为我的公司生成一个去加州的路线计划。我们有8人,4月21日从法国巴黎出发,行程为期7天。检查未来几天的天气预报和温度,据此安排室内外活动。”
- Excel数据整理
数据处理也不在话下:“帮我建立一个Excel表格,包含所有意大利彩票游戏(Lotto、10eLotto和Million Day)的信息。基于此,生成并发送给我一个包含所有基本公开信息的电子表格。”
- 活动演讲嘉宾寻找
想办活动?试试:“找出20位过去一年在会议上发言的欧洲AI伦理演讲者。抓取会议网站信息,交叉引用LinkedIn和YouTube,输出联系信息和演讲摘要。”
- 科学论文总结与比较
做研究更轻松:“研究并比较过去5年讨论酒精对人体影响的科学论文。生成一份关于这一主题最重要科学论文的报告。”
- 潜在客户研究
市场营销更精准:“在LinkedIn上研究我的潜在B2B客户,他们应该在清洁技术行业。找到他们的网站和电子邮件地址。然后,根据公司简介,生成一封个性化的首次联系邮件,介绍我的公司为清洁技术公司提供的利润最大化和成本降低咨询服务。”
- SEO分析
网站优化不再难:“基于我的网站suna.so,生成SEO分析报告,按关键词集群找出排名靠前的页面,并识别我缺失的主题。”
- 个人旅行规划
旅行计划更轻松:“为我规划一次从曼谷到伦敦的个人旅行,5月1日出发,行程10天。在伦敦市中心找一个Google评分至少4.5分的住宿。找出旅途中有趣的户外活动。生成详细的行程计划。”










:乐鑫发布与火山引擎扣子联名 AI 智能体开发板)








