背景意义
研究背景与意义
随着全球人口的不断增长,农业生产面临着前所未有的挑战,尤其是在资源有限的环境中,如何提高作物的产量和质量成为了亟待解决的问题。水培技术作为一种新兴的农业生产方式,因其高效的水资源利用和较少的土壤病害而受到广泛关注。然而,水培植物同样面临着病害的威胁,尤其是生菜等易受病害影响的作物。因此,开发一种高效的病害检测系统,对于保障水培植物的健康生长、提高农业生产效率具有重要的现实意义。
本研究旨在基于改进的YOLOv11模型,构建一个高效的水培植物病害检测系统。YOLO(You Only Look Once)系列模型因其优越的实时检测能力和高准确率而被广泛应用于计算机视觉领域。通过对YOLOv11进行改进,结合特定的水培植物病害数据集,我们期望能够提升模型在病害检测任务中的性能。该数据集包含1900张图像,涵盖了生菜的正常生长状态与病害状态两大类,能够为模型的训练和评估提供丰富的样本。
在当前的农业科技背景下,利用深度学习技术进行病害检测,不仅可以提高检测的准确性和效率,还能够为农民提供及时的决策支持,减少病害对作物造成的损失。此外,该系统的推广应用将有助于推动智能农业的发展,促进可持续农业的实现。通过本研究,我们希望能够为水培植物的病害管理提供一种新思路,助力农业生产的智能化与现代化进程
图片效果
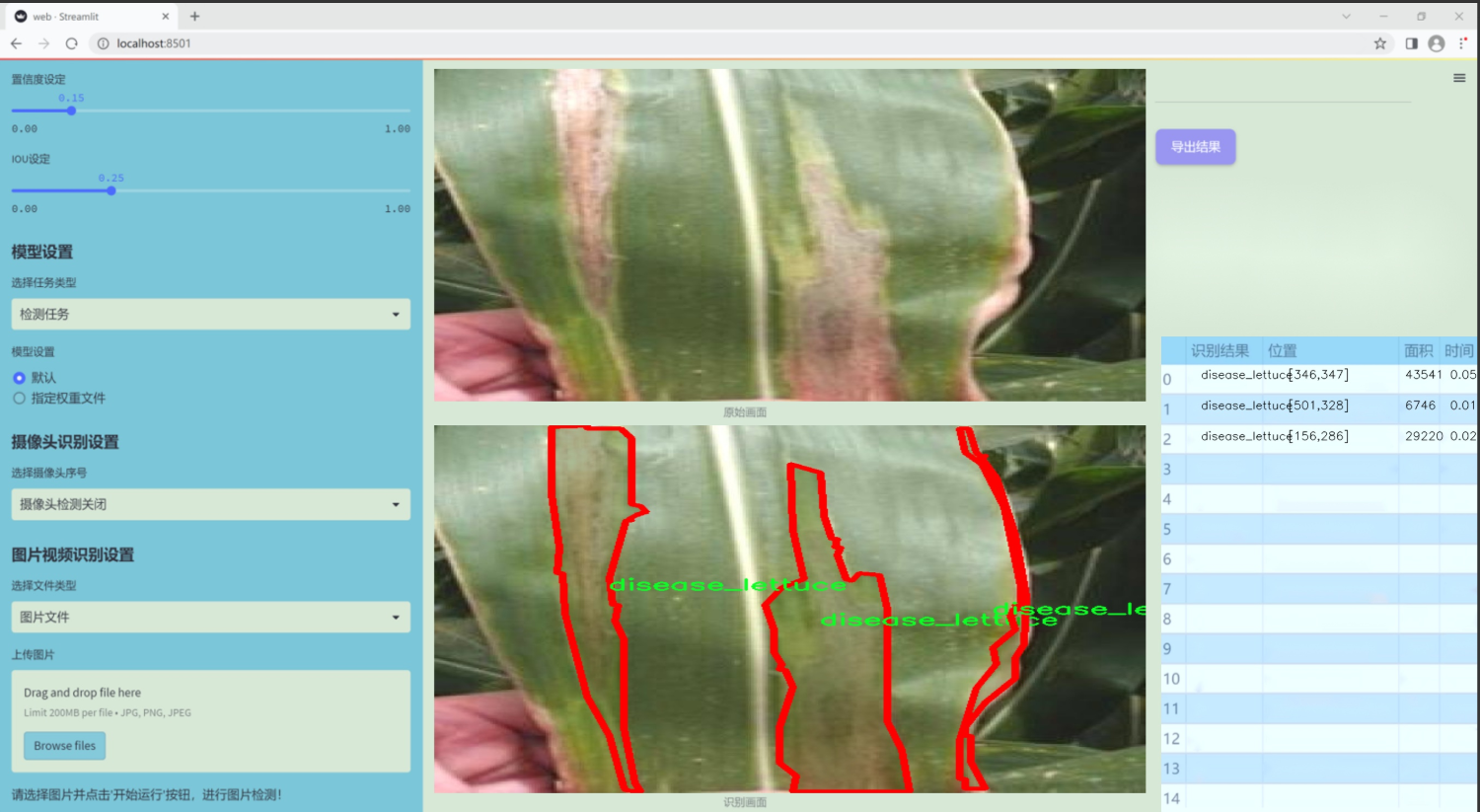
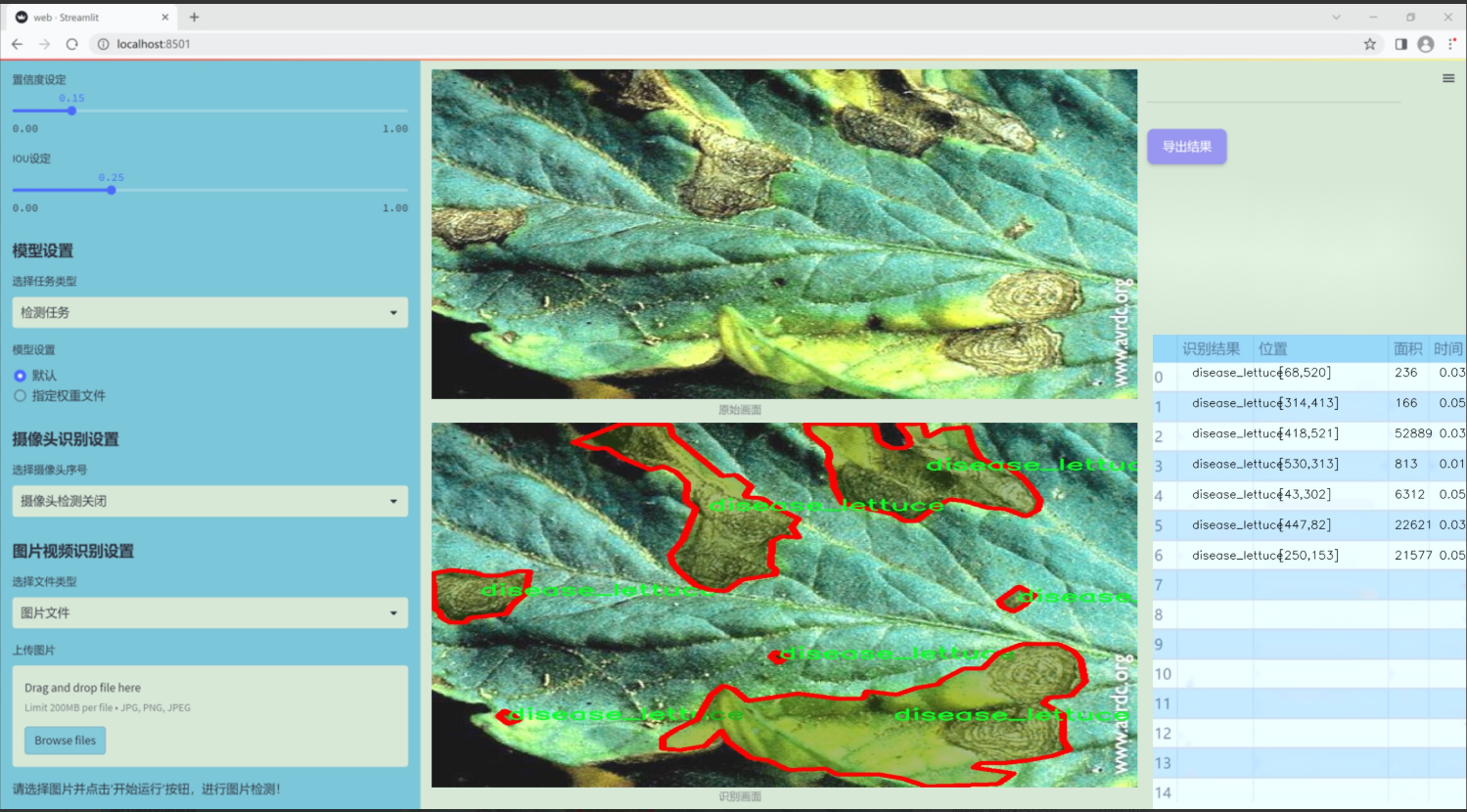
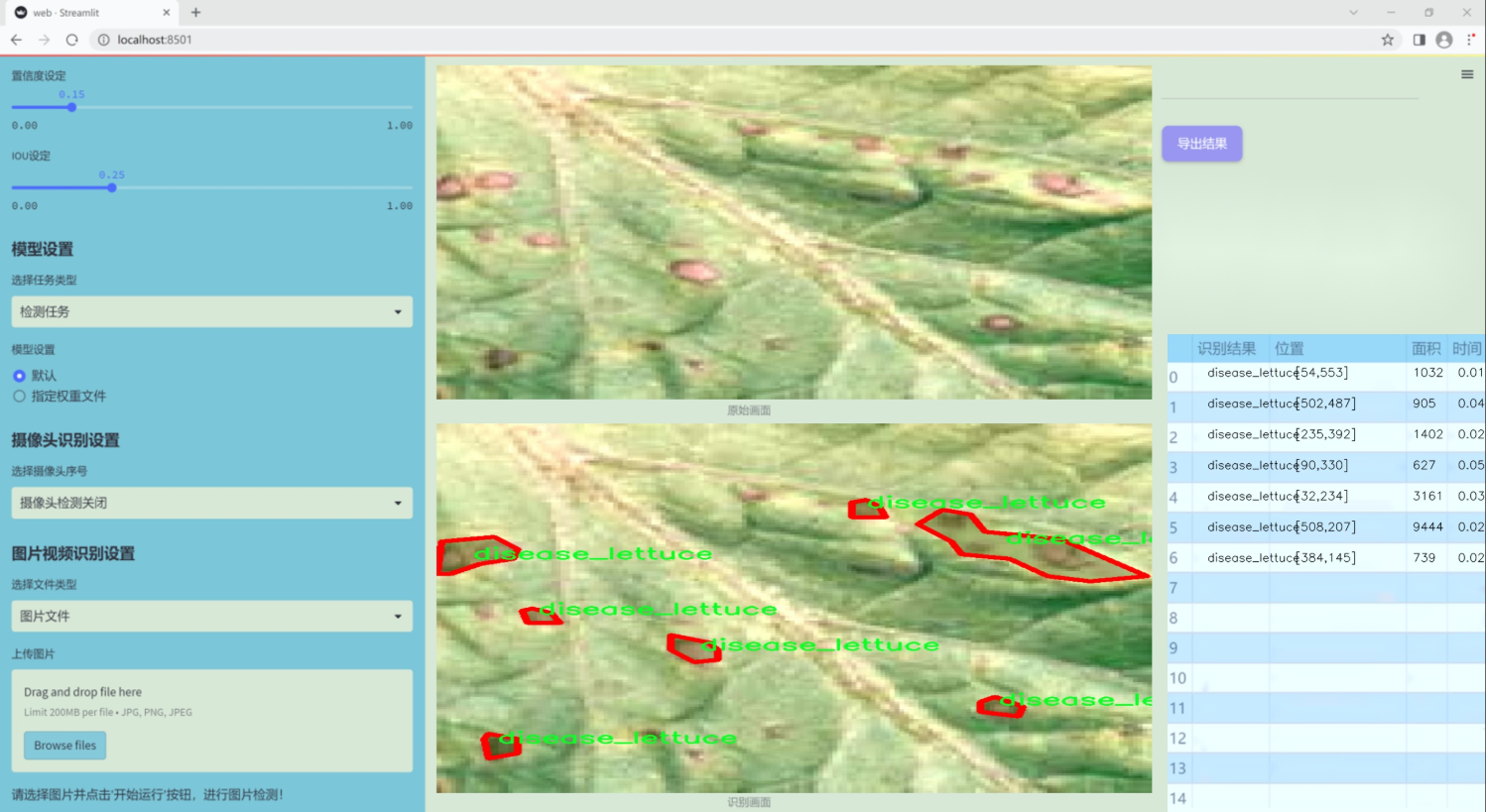
数据集信息
本项目数据集信息介绍
本项目所使用的数据集旨在支持改进YOLOv11模型在水培植物病害检测系统中的应用,特别关注于水培生菜的健康状况监测。数据集的主题为“aquaponic_polygan_disease_other”,专注于识别水培环境中生菜的不同状态。该数据集包含两个主要类别,分别为“disease_lettuce”和“normal_lettuce”,这为模型的训练提供了清晰的目标和分类依据。
在水培农业中,生菜作为一种常见的作物,其生长健康与否直接影响到产量和品质。因此,及时识别生菜的病害情况对于农民和农业管理者而言至关重要。本数据集通过大量的图像样本,涵盖了不同生长阶段和环境条件下的生菜图像,确保了数据的多样性和代表性。每个类别的样本均经过精心标注,以便于模型能够准确学习到病害与正常生菜之间的特征差异。
在数据集的构建过程中,特别考虑了水培环境的特殊性,确保图像中能够反映出水培生菜的真实生长状态和潜在病害表现。这种细致的标注和分类将有助于YOLOv11模型在训练过程中有效提取特征,从而提高其在实际应用中的检测精度和效率。通过对该数据集的深入分析和训练,我们期望能够开发出一种高效的病害检测系统,帮助农民实时监控水培生菜的健康状况,降低病害损失,提高农业生产的可持续性。


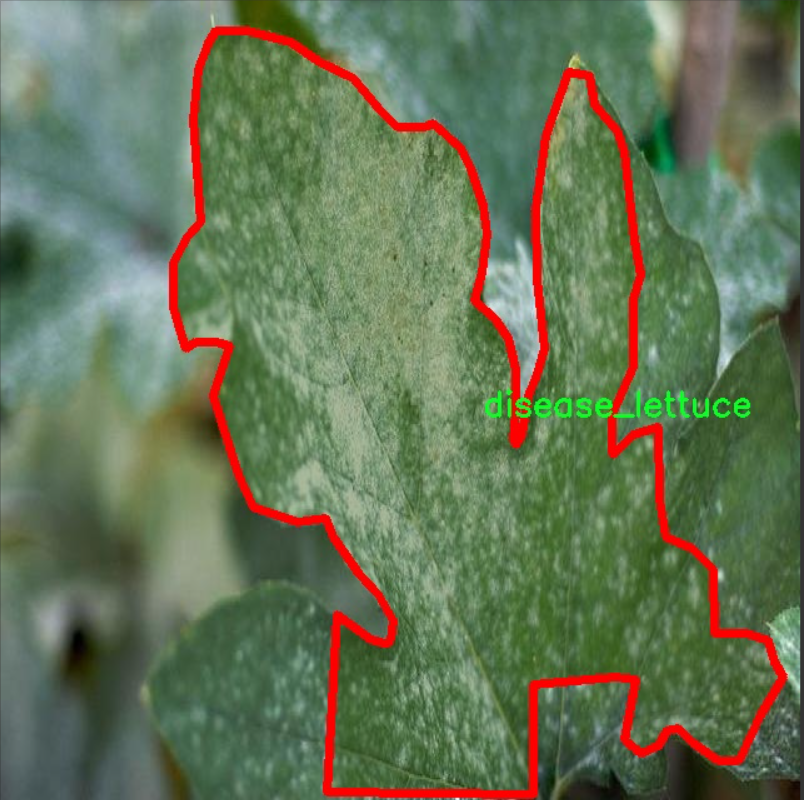


核心代码
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DyReLU(nn.Module):
“”"动态ReLU激活函数,能够根据输入动态调整激活值。
Args:inp (int): 输入通道数。reduction (int): 通道压缩比例。lambda_a (float): 动态调整参数。K2 (bool): 是否使用偏置。use_bias (bool): 是否使用偏置。use_spatial (bool): 是否使用空间注意力。init_a (list): 初始化参数a的值。init_b (list): 初始化参数b的值。
"""def __init__(self, inp, reduction=4, lambda_a=1.0, K2=True, use_bias=True, use_spatial=False,init_a=[1.0, 0.0], init_b=[0.0, 0.0]):super(DyReLU, self).__init__()self.oup = inp # 输出通道数self.lambda_a = lambda_a * 2 # 动态调整参数self.K2 = K2 # 是否使用偏置self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化# 根据是否使用偏置设置exp的值self.exp = 4 if use_bias else 2 if K2 else 2 if use_bias else 1# 确定压缩比例squeeze = inp // reduction if reduction == 4 else _make_divisible(inp // reduction, 4)# 定义全连接层self.fc = nn.Sequential(nn.Linear(inp, squeeze),nn.ReLU(inplace=True),nn.Linear(squeeze, self.oup * self.exp),h_sigmoid() # 使用h_sigmoid作为激活函数)# 如果使用空间注意力,定义相应的卷积层self.spa = nn.Sequential(nn.Conv2d(inp, 1, kernel_size=1),nn.BatchNorm2d(1),) if use_spatial else Nonedef forward(self, x):"""前向传播函数。"""# 如果输入是列表,分离输入和输出x_in = x[0] if isinstance(x, list) else xx_out = x[1] if isinstance(x, list) else xb, c, h, w = x_in.size() # 获取输入的尺寸y = self.avg_pool(x_in).view(b, c) # 自适应平均池化并调整形状y = self.fc(y).view(b, self.oup * self.exp, 1, 1) # 通过全连接层并调整形状# 根据exp的值计算输出if self.exp == 4:a1, b1, a2, b2 = torch.split(y, self.oup, dim=1)a1 = (a1 - 0.5) * self.lambda_a + self.init_a[0]a2 = (a2 - 0.5) * self.lambda_a + self.init_a[1]b1 = b1 - 0.5 + self.init_b[0]b2 = b2 - 0.5 + self.init_b[1]out = torch.max(x_out * a1 + b1, x_out * a2 + b2)elif self.exp == 2:a1, b1 = torch.split(y, self.oup, dim=1)a1 = (a1 - 0.5) * self.lambda_a + self.init_a[0]b1 = b1 - 0.5 + self.init_b[0]out = x_out * a1 + b1elif self.exp == 1:a1 = ya1 = (a1 - 0.5) * self.lambda_a + self.init_a[0]out = x_out * a1# 如果使用空间注意力,计算空间注意力并调整输出if self.spa:ys = self.spa(x_in).view(b, -1)ys = F.softmax(ys, dim=1).view(b, 1, h, w) * h * wys = F.hardtanh(ys, 0, 3, inplace=True) / 3out = out * ysreturn out
class DyDCNv2(nn.Module):
“”"带有归一化层的ModulatedDeformConv2d,用于DyHead。
Args:in_channels (int): 输入通道数。out_channels (int): 输出通道数。stride (int | tuple[int], optional): 卷积的步幅。norm_cfg (dict, optional): 归一化层的配置字典。
"""def __init__(self, in_channels, out_channels, stride=1, norm_cfg=dict(type='GN', num_groups=16, requires_grad=True)):super().__init__()self.with_norm = norm_cfg is not None # 是否使用归一化bias = not self.with_norm # 如果不使用归一化,则使用偏置self.conv = ModulatedDeformConv2d(in_channels, out_channels, 3, stride=stride, padding=1, bias=bias) # 定义可调变形卷积if self.with_norm:self.norm = build_norm_layer(norm_cfg, out_channels)[1] # 构建归一化层def forward(self, x, offset, mask):"""前向传播函数。"""x = self.conv(x.contiguous(), offset, mask) # 进行卷积操作if self.with_norm:x = self.norm(x) # 如果使用归一化,则进行归一化return x
代码说明:
DyReLU: 这是一个动态ReLU激活函数的实现,能够根据输入的特征动态调整激活值。它通过自适应平均池化和全连接层来生成动态参数,并可以选择性地使用空间注意力。
DyDCNv2: 这是一个带有归一化层的可调变形卷积模块,主要用于特征提取。它根据输入的特征图和偏移量、掩码进行卷积操作,并在需要时应用归一化。
这两个类是深度学习模型中用于特征提取和激活的核心组件,能够增强模型的表达能力和性能。
这个程序文件 dyhead_prune.py 实现了一些深度学习中的模块,主要用于动态头(Dynamic Head)模型的构建,特别是在目标检测和图像分割等任务中。代码使用了 PyTorch 框架,并引入了一些额外的库,如 mmcv 和 mmengine,用于构建激活层和归一化层。
首先,文件中定义了一个 _make_divisible 函数,该函数用于确保某个值能够被指定的除数整除,并且不会小于最小值的 90%。这个函数在调整网络结构时非常有用,特别是在处理通道数时。
接下来,定义了几个激活函数的类,包括 swish、h_swish 和 h_sigmoid。这些类都继承自 nn.Module,并实现了 forward 方法,以便在前向传播中使用。swish 是一种新型激活函数,h_swish 和 h_sigmoid 则是高斯激活函数的变种,通常用于深度学习模型中以提高性能。
然后,定义了 DyReLU 类,这是一个动态 ReLU 激活函数的实现。该类通过自适应的方式调整激活函数的参数,以适应输入特征的不同。构造函数中设置了一些参数,如输入通道数、缩减比例、是否使用偏置等。forward 方法根据输入特征计算输出,支持不同的输出方式,包括使用空间注意力机制。
接着,定义了 DyDCNv2 类,这是一个带有归一化层的可调变形卷积层。该类的构造函数接受输入和输出通道数、步幅以及归一化配置,并在前向传播中应用变形卷积和归一化。
最后,定义了 DyHeadBlock_Prune 类,这是一个包含三种注意力机制的动态头块。构造函数中初始化了多个卷积层和注意力模块。forward 方法负责计算偏移量和掩码,并根据输入特征的不同层次进行卷积操作,结合高、中、低层特征以生成最终的输出。
整体来看,这个文件实现了一个复杂的动态头结构,利用动态激活函数和可调变形卷积来增强模型的表达能力,适用于需要多尺度特征融合的深度学习任务。
10.4 CTrans.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import numpy as np
from torch.nn import Dropout, Softmax, Conv2d, LayerNorm
class Channel_Embeddings(nn.Module):
“”“构建来自图像块和位置的嵌入”“”
def init(self, patchsize, img_size, in_channels):
super().init()
img_size = (img_size, img_size) # 将图像大小转换为元组
patch_size = (patchsize, patchsize) # 将补丁大小转换为元组
n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1]) # 计算补丁数量
# 使用最大池化和卷积层构建补丁嵌入self.patch_embeddings = nn.Sequential(nn.MaxPool2d(kernel_size=5, stride=5),Conv2d(in_channels=in_channels,out_channels=in_channels,kernel_size=patchsize // 5,stride=patchsize // 5))# 位置嵌入参数self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches, in_channels))self.dropout = Dropout(0.1) # Dropout层,防止过拟合def forward(self, x):"""前向传播函数"""if x is None:return Nonex = self.patch_embeddings(x) # 计算补丁嵌入x = x.flatten(2) # 将特征展平x = x.transpose(-1, -2) # 转置以适应后续操作embeddings = x + self.position_embeddings # 添加位置嵌入embeddings = self.dropout(embeddings) # 应用Dropoutreturn embeddings
class Attention_org(nn.Module):
“”“自定义的多头注意力机制”“”
def init(self, vis, channel_num):
super(Attention_org, self).init()
self.vis = vis # 可视化标志
self.KV_size = sum(channel_num) # 键值对的总大小
self.channel_num = channel_num # 通道数量
self.num_attention_heads = 4 # 注意力头的数量
# 初始化查询、键、值的线性变换self.query = nn.ModuleList([nn.Linear(c, c, bias=False) for c in channel_num])self.key = nn.Linear(self.KV_size, self.KV_size, bias=False)self.value = nn.Linear(self.KV_size, self.KV_size, bias=False)self.psi = nn.InstanceNorm2d(self.num_attention_heads) # 实例归一化self.softmax = Softmax(dim=3) # Softmax层self.attn_dropout = Dropout(0.1) # 注意力的Dropoutself.proj_dropout = Dropout(0.1) # 投影的Dropoutdef forward(self, *embeddings):"""前向传播函数"""multi_head_Q = [query(emb) for query, emb in zip(self.query, embeddings) if emb is not None]multi_head_K = self.key(torch.cat(embeddings, dim=2)) # 计算键multi_head_V = self.value(torch.cat(embeddings, dim=2)) # 计算值# 计算注意力分数attention_scores = [torch.matmul(Q, multi_head_K) / np.sqrt(self.KV_size) for Q in multi_head_Q]attention_probs = [self.softmax(self.psi(score)) for score in attention_scores]# 应用Dropoutattention_probs = [self.attn_dropout(prob) for prob in attention_probs]# 计算上下文层context_layers = [torch.matmul(prob, multi_head_V) for prob in attention_probs]# 投影输出outputs = [self.proj_dropout(layer) for layer in context_layers]return outputs
class ChannelTransformer(nn.Module):
“”“通道变换器模型”“”
def init(self, channel_num=[64, 128, 256, 512], img_size=640, vis=False, patchSize=[40, 20, 10, 5]):
super().init()
self.embeddings = nn.ModuleList([Channel_Embeddings(patchSize[i], img_size // (2 ** (i + 2)), channel_num[i]) for i in range(len(channel_num))])
self.encoder = Encoder(vis, channel_num) # 编码器
self.reconstruct = nn.ModuleList([Reconstruct(channel_num[i], channel_num[i], kernel_size=1, scale_factor=(patchSize[i], patchSize[i])) for i in range(len(channel_num))])
def forward(self, en):"""前向传播函数"""embeddings = [embed(en[i]) for i, embed in enumerate(self.embeddings) if en[i] is not None]encoded = self.encoder(*embeddings) # 编码reconstructed = [recon(enc) + en[i] for i, (recon, enc) in enumerate(zip(self.reconstruct, encoded)) if en[i] is not None]return reconstructed
代码说明:
Channel_Embeddings:该类负责将输入图像转换为补丁嵌入,并添加位置嵌入。使用最大池化和卷积层来提取特征。
Attention_org:实现了多头注意力机制,计算输入嵌入的注意力分数,并返回上下文层。支持可视化注意力权重。
ChannelTransformer:整个模型的核心,负责将输入的多个通道嵌入进行编码和重构。通过调用嵌入层和编码器来处理输入数据。
这个程序文件 CTrans.py 实现了一个基于通道变换器(Channel Transformer)的深度学习模型,主要用于图像处理任务。代码中定义了多个类,每个类实现了模型的不同组成部分。以下是对代码的详细说明。
首先,文件导入了一些必要的库,包括 PyTorch、NumPy 和一些深度学习模块。接着,定义了几个主要的类。
Channel_Embeddings 类用于构建图像的嵌入表示。它接收图像的尺寸和通道数,并通过卷积和池化操作将图像划分为多个补丁。每个补丁会生成一个嵌入向量,并且类中还包含位置嵌入以保留空间信息。前向传播方法将输入图像转换为嵌入表示,并添加位置嵌入。
Reconstruct 类用于重建图像。它接收嵌入向量并通过上采样和卷积操作将其转换回图像的空间维度。这个类的前向传播方法会对输入进行变换并返回重建后的图像。
Attention_org 类实现了多头注意力机制。它接收多个嵌入并计算注意力权重,使用线性变换将查询、键和值映射到适当的维度。通过计算注意力分数并应用 softmax 函数,类可以生成加权的上下文向量。
Mlp 类实现了一个简单的多层感知机(MLP),用于对嵌入进行非线性变换。它包含两个全连接层和一个激活函数(GELU),并且在每个层后都有 dropout 操作以防止过拟合。
Block_ViT 类实现了一个变换器块,结合了注意力机制和前馈网络。它首先对输入进行层归一化,然后通过注意力机制处理嵌入,最后通过 MLP 进行进一步的变换。这个类的前向传播方法返回经过处理的嵌入和注意力权重。
Encoder 类由多个 Block_ViT 组成,负责将输入的嵌入通过多个变换器块进行编码。它同样对嵌入进行层归一化,并在每个块中收集注意力权重。
ChannelTransformer 类是整个模型的核心。它初始化了多个嵌入层、编码器和重建层。前向传播方法接收输入的图像,生成嵌入,经过编码器处理后再进行重建。最终输出的图像是对输入图像的重建结果。
最后,GetIndexOutput 类用于从模型的输出中提取特定索引的结果,方便后续处理。
总体来说,这个程序实现了一个通道变换器模型,结合了卷积、注意力机制和多层感知机等技术,适用于图像处理任务。通过分层结构和模块化设计,代码具有良好的可读性和可扩展性。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式






:『混沌工程的定义与实践』)











学习总结-20250916)
)