GPS+RTK
GPS组成
GPS分为三部分。
- 空间星座部分:由至少24颗卫星组成(目前有30多颗在轨运行),分布在6个中地球轨道上。保证全球任何地方、任何时间至少能接收到4颗以上的卫星信号。每颗卫星不断播发一种包含卫星星历(自己的精确轨道位置)、时钟校正参数和系统状态的无线电信号。
- 地面监控部分:由主控站、监测站和注入站组成,分布在全球。监测站负责持续跟踪所有可见卫星,收集它们的信号和数据,并发送给主控站;主控站负责计算每颗卫星的精确轨道(生成星历)和时钟误差,并预测其未来的轨迹;注入站负责定期将主控站计算出的星历和时钟参数上传给各颗卫星。
- 用户设备部分:就是我们手中的GPS接收机(手机、车载导航、专业设备等)(GPS卫星只发送信号不接收信号),GPS接收器通过测量信号的飞行时间然后用光速乘以时间来计算与卫星的距离。
三边测量(GPS原理)
在一个平面上有三个物品,分别为一棵树一个路灯和一个房子(位置已确定),现在我告诉你我的位置距离树20m,这时你就会以树为圆心画一个半径为20m的圆,我的位置可能出现在这个圆的任意位置;现在我又告诉你我距离路灯15m这时你又会以路灯为圆心画一个半径为15m的圆来进一步确定我的位置,我的位置可能出现在上面两圆的两个交点上。现在我又告诉你我距离房子10m,这时再以房子为圆心画一个半径为10m的圆,这三个圆必交于一点,这个确定的点就是我的位置。这个过程称为三边测量
GPS的原理类似,其核心思想是通过测量信号从卫星到接收机的传播时间来计算距离,然后通过几何上的“三边测量”(类似交会定位)来计算出自己的位置。GPS定位的根本是测量距离(速度 × 时间 = 距离),GPS信号是以光速传播的无线电波,速度 c 是一个已知常数(约每秒30万公里),而卫星在发送信号时,会打上一个非常精确的时间戳(由卫星上的原子钟生成)。接收机在接收到信号时,也会记录一个接收时间。两者的时间差就是信号的传播时间 Δt。但是这个计算出的距离,因为各种误差的存在,并不完全是真实的几何距离,所以被称为 “伪距”。误差来源通常为以下几中:(这也就是GPS定位精度只有几米到十几米的原因)
- 要精确测量
Δt,要求卫星和接收机的时钟必须完全同步。卫星使用昂贵的原子钟,精度极高。但我们的手机、车载接收机使用的是普通的石英钟,精度差很多,存在钟差。这种钟差是可以解决的,下面介绍的第四颗卫星就是为了解决这个误差。 - 信号穿过大气层时速度会变慢,路径会弯曲。这是最大的误差源。
- 信号被周围的建筑物、地面等反射后,接收机收到多个延迟的信号副本,造成干扰
GPS的三边测量介绍如下,知道了一颗卫星的距离,意味着你位于以这颗卫星为球心、以该距离为半径的球面上的某个地方;当知道了两颗卫星的距离,两个球面相交,意味着你在一个圆环上;当知道了三颗卫星的距离,三个球面相交理论上可以得到两个点。但其中一个点通常在地球之外或不合理的位置,可以排除,从而得到一个二维的平面坐标(经度、纬度);当知道了四颗卫星的距离,可以确定唯一的点,第四颗卫星的关键作用,就是为了解算出接收机的钟差。这样,接收机就能在时钟不准的情况下,依然计算出正确的位置,并同时输出精确的时间信息。所以我们常说GPS接收机也是一个授时工具。
关于第四颗卫星的作用,这里再做详细解释。接收机事实上需要解一个包含四个未知数的方程,即“伪距 = 真实几何距离 + 钟差误差 × 光速 (c)”,需要解的四个未知数是接收机的三维坐标 (X, Y, Z) 和 接收机的钟差,因此,必须有4颗(或以上)卫星的观测数据,才能解出这4个未知数,得到精确的绝对位置。那如果我们就用三颗卫星,而将钟差误差看作0,事实上也是可以解出接收机的三维坐标 (X, Y, Z)的,但是现实世界中,接收机的时钟(普通石英钟)误差非常大并且光速c又很大,如果你忽略它,计算出的位置 (x, y, z) 将会包含巨大的误差,可能偏差几公里甚至上百公里,这个结果完全不可用。第四颗卫星的作用就在于此:它提供了第四个约束条件,使得方程组有唯一解。
RTK(实时动态定位)
普通的单点GPS定位(比如手机或车载导航)存在多种误差源,导致其精度通常在几米到十几米之间。RTK技术就是为了解决此误差而生的。
RTK系统组成:
- 基准站:这是一个固定不动的GPS接收机(也称为基站,且不止一个),它的精确位置(经纬高)是通过精密测量已知的。它持续不断地观测所有可见的GPS卫星。
- 移动站 :安装在自动驾驶车辆上的GPS接收机。
- 数据链路:用于将基准站的观测数据实时(通常是通过4G/5G移动网络)传输给移动站
RTK系统流程:
1. 基准站计算误差:
基准站根据它已知的精确位置和接收到的卫星信号,可以反推出每颗卫星信号的综合误差值(包括大气延迟、钟差等)。因为它自己的位置是精确已知的,所以它算出的卫星距离(伪距)与真实几何距离的差值,就是各种误差的总和。
2. 数据发送:
基准站将这些计算出的误差校正数据通过数据链路实时发送给附近的移动站(如自动驾驶汽车)。
3. 移动站进行差分校正:
移动站接收到基准站的校正数据后,将其应用到自己的原始观测数据上。关键的一步来了:RTK不仅使用普通的GPS伪距码,更重要的是使用载波相位测量。
- 载波相位:GPS卫星发射的无线电信号波长很短(约19厘米)。接收机可以非常精确地测量载波信号的相位(可以想象成测量波峰和波谷的位置),其测量精度可以达到毫米级。但问题是,它只能测出不足一个整波长的小数部分,无法直接知道距离卫星有多少个整周数(称为“整周模糊度”)。
4. 解算“整周模糊度”:
RTK技术的核心算法就是快速、准确地解算出这个“整周模糊度”。一旦成功解算(称为“固定解”),移动站就能利用极其精确的载波相位观测值,结合基准站传来的差分校正数据,消除掉公共误差(因为两台接收机距离较近,它们看到的大气误差等非常相似)。
5. 输出高精度位置:
通过这一系列复杂的计算,移动站最终能够计算出相对于基准站的厘米级精度的相对位置。由于基准站的绝对位置是已知的,移动站自然也就能获得厘米级的绝对地理坐标。
惯性导航系统(INS)
简单来说,惯性导航是一种基于惯性原理的自主式导航技术。它的核心思想是:我知道初始位置,然后我通过持续测量自身的加速度和旋转角速度,来推算出我每一刻的新位置、新速度和新姿态(朝向)。它不依赖任何外部信号(如GPS、基站、Wi-Fi),完全自包含(Self-contained)。
惯性导航系统中最重要的”是惯性测量单元(Inertial Measurement Unit, IMU),注意区分概念,INS是一个完整的系统,它包含IMU并利用其数据进行计算,最终输出导航结果,而IMU(惯性测量单元)是一个传感器,它只负责测量数据。IMU通常包含两类核心传感器:
-
加速度计 (Accelerometer):测量物体在三个轴向(X, Y, Z) 上的线加速度。
-
陀螺仪 (Gyroscope):测量物体绕三个轴向的角速度(旋转的快慢)。
IMU的工作流程就是一个“积分”过程:陀螺仪测得的角速度 → 积分一次 → 得到姿态角度(俯仰、滚转、偏航)。加速度计测得的加速度 → 扣除重力影响 → 积分一次 → 得到速度 → 再积分一次 → 得到位移。
INS优势如下:
- GPS只能提供位置和速度(二维或三维),但无法直接知道车辆的姿态——即车辆的俯仰角(上下点头)、滚转角(左右倾斜)和偏航角(车头朝向)。
- IMU的更新频率极高(可达1000Hz),远超GPS(通常10-20Hz)。这意味着它能提供极其连续、平滑的位置、速度和姿态变化,对于需要快速反应的车辆控制系统(如转向、刹车)至关重要。
- 当车辆进入隧道、地下车库、城市峡谷(高楼之间) 或遇到恶劣天气时,GPS信号会中断或严重退化。此时,INS可以基于信号丢失前最后已知的精确位置,继续提供短时间的高精度定位,保证自动驾驶功能不中断。
INS很少单独工作。它几乎总是与GPS、轮速计、摄像头、激光雷达等传感器通过算法(如卡尔曼滤波 Kalman Filter)融合在一起,形成组合导航系统。例如,当GPS信号良好时用GPS提供的绝对位置来持续校正和校准INS,抑制其误差累积,并精确估算出INS的误差参数(如零偏);当GPS信号丢失时,INS利用刚才被校准好的状态,进行高精度的自主推算。由于误差已被最大限度地抑制,它在信号丢失的几十秒内仍能保持极高的定位精度。
- GPS:提供长期稳定、绝对准确的位置,但更新慢、易中断。
- INS:提供短期精确、高频、连续的相对位移和姿态,但误差会随时间累积(漂移)。
激光雷达定位
激光雷达定位的核心思想是:通过实时扫描周围环境并获取高精度的三维点云数据,然后将这些数据与一份预先存在的高精度地图进行匹配,从而计算出车辆在当前地图中的精确位置和姿态(朝向)。它不像GPS那样依赖卫星信号,也不像INS那样会漂移,它是一种基于环境特征匹配的绝对定位方式。
尽管有GPS/RTK和INS的组合,但它们仍有固有缺陷:
- GPS信号丢失:在隧道、地下、城市峡谷等场景失效。
- INS误差累积:一旦GPS长时间失效,INS的漂移会使得定位误差变得不可接受。
- 精度要求极高:自动驾驶需要厘米级的定位精度来确定自己在哪条车道的具体位置,这是GPS/RTK+INS难以始终稳定提供的。
激光雷达定位恰好弥补了这些缺陷,提供了稳定、可靠、高精度的绝对位置信息。激光雷达定位通常不是一个一步到位的过程,它遵循一个分层、逐步精细的流程,如下图所示,其核心是 “预测-匹配-更新” 的循环,其核心技术原理如下:
- 预测(初始位置预测):在开始匹配之前,算法需要一个“猜测”的初始位置,此预测过程通常由GPS/RTK+INS组合系统提供一个大致的、米级精度的位置和朝向。
- 匹配(扫描匹配):这是激光雷达定位的算法核心。它的目的是找到一种变换(旋转和平移),使得当前扫描得到的实时点云与高精度地图上的局部参考点云尽可能完美地重叠。主要算法有两种,迭代最近点(ICP)和正态分布变换(NDT)
- 更新(后处理与传感器融合):单纯的扫描匹配结果可能仍有微小误差或抖动。为了得到更稳定、可靠的位置输出,还需要使用卡尔曼滤波(KF)或粒子滤波(PF)等算法,对多帧激光雷达的匹配结果进行平滑处理,滤掉不合理的抖动。将激光雷达定位的结果与GPS、IMU、轮速计等信息进行传感器融合。最终输出一个最优的、最可靠的位姿估计。
关于激光雷达定位的更详细解释及算法,参考以下文章:
激光雷达定位算法-CSDN博客
视觉定位
视觉定位的核心思想是:通过摄像头捕获周围的视觉环境(如车道线、交通标志、建筑物、树木等),然后将这些视觉信息与已知的地图或模型进行匹配,从而推断出车辆自身的精确位置和姿态(朝向)。它与激光雷达定位的逻辑相似(都是环境匹配),但使用的传感器和数据形式完全不同:一个是三维几何点云,一个是二维纹理图像。
在激光雷达成本高昂的背景下,视觉定位提供了一种相对低成本的解决方案。现在出现的一些视觉SLAM方法还可以不依赖预先绘制的高精地图,真正实现“即走即建图”。
视觉定位主要分为三条路线:
1.基于语义地图的视觉定位(主流方案):
这是目前最可靠、与高精地图结合最紧密的方案,其流程与激光雷达定位类似。
a. 离线建图阶段:
- 采集车(搭载摄像头、GPS/IMU等)预先行驶在道路上,收集大量图像和位置数据。
- 通过算法(如SFM, Structure from Motion)从这些图像中提取稳定的语义特征(如交通标志的角点、路灯的顶端、建筑物轮廓等),并计算出它们在全球坐标系中的精确3D位置,生成一份视觉高精语义地图。这份地图存储的不是原始图像,而是特征的3D坐标和描述子。
b. 在线定位阶段:
- 特征提取:车辆上的摄像头捕获实时图像,提取出相同的语义特征。
- 特征匹配:将当前图像中提取的2D特征点,与视觉语义地图中存储的3D路标点进行匹配。寻找“当前看到的这个点,对应地图上的哪个3D点”。
- PnP求解:一旦找到足够多的2D-3D匹配对,就可以使用PnP(Perspective-n-Point) 算法。PnP是一种几何解法,通过已知的多个3D点及其在图像上的2D投影,直接反推出相机的6自由度位姿(位置和旋转)。
- 优化:使用集束调整(Bundle Adjustment)等算法对位姿结果进行优化,使其更精确。
2.视觉SLAM(同步定位与建图)
SLAM更像是一个“边走边画地图”的过程。它不需要预先的高精地图,而是由车辆自身在行驶过程中同时完成定位和局部地图构建。
工作原理:
- 跟踪(Tracking):通过比较连续帧图像,估算出相机自身的运动(通过视觉里程计, VO),并初步估计出当前位姿。
- 建图(Mapping):将跟踪过程中观察到的新的环境特征点添加到当前维护的局部地图中。
- 回环检测(Loop Closure):识别出曾经访问过的地点,从而校正整个行程中累积的定位漂移。
- 在自动驾驶中的应用:更多用于停车场等缺乏GPS信号的封闭结构化环境,或作为城市道路驾驶中的一种辅助定位手段。纯粹的视觉SLAM难以满足高速自动驾驶对全局绝对定位的苛刻要求。
3.基于学习的端到端定位
利用深度学习模型,直接从图像中回归出车辆的位姿。这种方法目前更多处于研究阶段,尚未成为主流自动驾驶系统的核心定位方案。
工作原理:
- 使用一个庞大的数据集(图像+对应的真实位姿标签)来训练一个深度神经网络(如CNN)。
- 训练完成后,网络输入一张或多张当前图像,直接输出车辆的估计位置(x, y, z)和姿态(俯仰、滚转、偏航)。
优点是方法简洁,无需复杂的特征匹配和几何计算。目前的缺点是泛化能力差,在一个地区训练的网络,到另一个外观迥异的地区可能完全失效,除此之外目前难以达到几何方法的精度和可靠性,容易受到光照、天气、季节变化的影响
多传感器融合
原因
通过上面对各传感器实现的定位的介绍可以发现单一传感器实现的定位存在各种问题,比如GPS信号易受遮挡(隧道、室内、城市峡谷),更新频率低(通常10Hz),精度有限(民用级米级),无法提供姿态信息;IMU积分会导致误差累积;LiDAR在特征稀疏的环境(如长直走廊、沙漠)中匹配困难,受恶劣天气(浓雾、大雨)影响大,计算量大,成本高;摄像头受光照影响大(夜晚、过曝),无法直接测距(需通过双目或移动视差计算),计算复杂度高(特征提取、匹配),对快速运动敏感。将这些传感器融合使用,取长补短,是必然的选择。
常见组合方式
1. GPS/RTK + IMU(绝对定位 + 高频递推)
这是最经典、最基础的组合,为其他融合系统提供了一个“绝对位置”的锚点。
- GPS (Global Positioning System):
- 提供: 低频(1-10Hz)、全局、绝对坐标(经纬度高度)。无累积误差。
- 缺陷: 信号易丢失(隧道、高楼间)、精度有限(民用单点定位米级)、更新慢、有噪声。
- RTK (Real-Time Kinematic):
- 提供: GPS的增强形式,通过地基或星基校正,提供厘米级的高精度绝对定位。
- 缺陷: 需要接收校正信号,初始化需要时间(收敛),在信号遮挡区域同样会失效。
- IMU (Inertial Measurement Unit):
- 提供: 极高频率(100-1000Hz)的机体三轴加速度和三轴角速度测量。
- 作用: 通过对角速度积分得到姿态(朝向),对加速度积分(并去除重力影响)得到速度和位移变化。在GPS两次更新的间隔内,提供平滑、连续的高频运动推算。
- 致命缺陷: 积分导致误差快速累积,几分钟内位置估计就会“飘走”(Drift)。
-
融合的核心思想:
用GPS的绝对位置(无漂移)来持续校正IMU积分带来的累积误差。 IMU在GPS失效时(如进入隧道)提供短时、高精度的航位推算(Dead Reckoning)。
2. 视觉惯性里程计 - VIO(相对定位 + 环境感知)
这是目前机器人学和AR/VR领域的核心技术,让设备在无GPS的环境中实现精准定位。视觉惯性里程计(VIO) 是一种通过融合相机图像和惯性测量单元(IMU)数据来实时估算设备自身在三维空间中的位置(平移) 和姿态(旋转) 的技术
- 单目/双目/RGB-D 相机 (Camera):
- 提供: 丰富的图像信息。通过追踪特征点,利用多视角几何原理可以计算出相机自身的运动(旋转和平移),称为视觉里程计 (VO)。
- 单目相机无法知道真实世界的尺度(就像看一张照片,你无法判断里面的一辆车是模型还是真车),所以它最大的问题是初始化(Initialization)。因为从单张2D图片无法得到深度信息,系统必须通过移动相机,利用多视角几何(如对极几何)来三角化出特征点的深度,这个过程需要时间且不稳定。而且 scale 是未知的。 单目相机极度依赖IMU,IMU在初始化阶段就提供尺度信息和运动预测,极大帮助系统完成初始化并稳定运行。
- 双目相机可以通过左右图像的视差,可以像人眼一样直接计算深度,得到有尺度的3D点云。无需初始化过程,更加稳定可靠。系统从一开始就知道尺度,IMU的主要作用变为提供高频输出、辅助应对视觉失效的场景,以及进一步优化估计精度。性能通常优于单目VIO。
- 鱼眼相机有超大的视场角(FOV),意味着在快速运动时看到的特征更多,特征跟踪的持续时间更长,系统更鲁棒,主要用于需要极高鲁棒性的场景,如自动驾驶、无人机高速飞行,算法需要处理鱼眼相机的畸变模型。
- 深度相机通过红外结构光或飞行时间法(ToF)直接测量每个像素的深度值,输出“RGB图 + 深度图”。特征点的3D坐标可以直接从深度图读取,省去了最复杂、最耗时的“从2D到3D”的几何计算步骤(无需三角化)且自带尺度无需IMU来提供尺度。 IMU的作用被进一步削弱,主要用来提供高频运动预测和补偿深度相机的运动模糊(因为深度相机通常有曝光时间,自身运动会导致深度测量误差)。系统整体变得非常简单、稳定和高效。
- 致命缺陷: 尺度不确定性(单目);受光照、纹理影响大;快速运动易模糊;计算耗时。
- IMU:
- 提供: 高频运动测量。
- 作用:
- 为视觉提供尺度! (对于单目VIO,IMU的加速度测量提供了真实的物理尺度)。
- 提供高频输出,弥补相机相对低的处理帧率(30-60Hz),实现运动预测。
- 帮助处理视觉失效的场景,如快速运动、图像模糊、纯色墙面。
-
融合的核心思想:
IMU提供高频、有尺度、但漂移的运动预测;视觉提供低频、无尺度(单目)、但无漂移的相对位姿观测。两者结合,得到高频、有尺度、无漂移的精确位姿。 -
典型应用: 无人机室内飞行、AR/VR头盔、机器人室内导航。
3. LiDAR + IMU(高精度几何感知 + 运动补偿)
这是自动驾驶和高端机器人的标配,提供极其精确的环境几何和自身位姿。
- LiDAR (激光雷达):
- 提供: 直接产生高精度的3D环境点云。通过点云配准算法(如ICP, NDT, Feature-based Matching)可以计算出雷达自身的运动。
- 缺陷: 在特征less的环境(长走廊、广场)匹配困难;自身运动会使点云畸变(smearing);计算量大;受天气影响。
- IMU:
- 作用:
- 运动去畸变: 利用IMU的高频数据,可以估计出LiDAR在一帧扫描过程中的自身运动,从而校正点云畸变,为点云匹配提供更准确的数据。
- 提供初始值: 为迭代式的点云匹配算法(如ICP)提供一个非常好的初始位姿猜测,加速收敛,避免匹配到局部极小值。
- 高频输出: 在LiDAR计算间隙提供运动预测。
- 作用:
-
融合的核心思想:
IMU的高频数据用于校正LiDAR的固有缺陷(运动畸变),并辅助其匹配;LiDAR提供的高精度位姿观测用于校正IMU的漂移。
除此之外,还有很多融合方式,这里不再赘述
方法
多传感器融合定位的本质是一个状态估计问题,即根据一系列带有噪声的观测数据,来估计系统当前的状态(如位置、速度、姿态等)。最主流的框架是滤波器,尤其是卡尔曼滤波(Kalman Filter)及其衍生系列。
卡尔曼滤波(KF)与扩展卡尔曼滤波(EKF)
-
基本思想: KF在线性系统中是最优估计器。它分为两个步骤:
- 预测(Prediction): 根据IMU等运动传感器的数据(系统模型),预测下一时刻系统的状态和不确定性(协方差)。
预测状态 = 上一状态 + IMU测量的运动 - 更新(Correction): 当GPS、LiDAR、Camera等观测传感器数据到来时,用观测值来修正预测值。
最终状态 = 预测状态 + K * (观测值 - 预测的观测值)
其中K是卡尔曼增益,根据预测和观测的不确定性动态调整。更相信预测还是更相信观测,由K决定。
- 预测(Prediction): 根据IMU等运动传感器的数据(系统模型),预测下一时刻系统的状态和不确定性(协方差)。
-
EKF(扩展卡尔曼滤波): 现实世界和传感器模型大多是非线性的。EKF通过一阶泰勒展开将非线性系统线性化,使其能应用KF的框架。这是目前最常用、最经典的融合方法。
Apollo自动驾驶定位方案
Apollo的定位模块(localization)主要负责输出车辆在全局坐标系下的6自由度位姿,即:
- 位置:经纬高坐标 (
x,y,z) - 姿态:横滚角、俯仰角、航向角 (
roll,pitch,yaw)
其目标是达到厘米级精度,以满足自动驾驶车辆对车道级定位的苛刻要求。
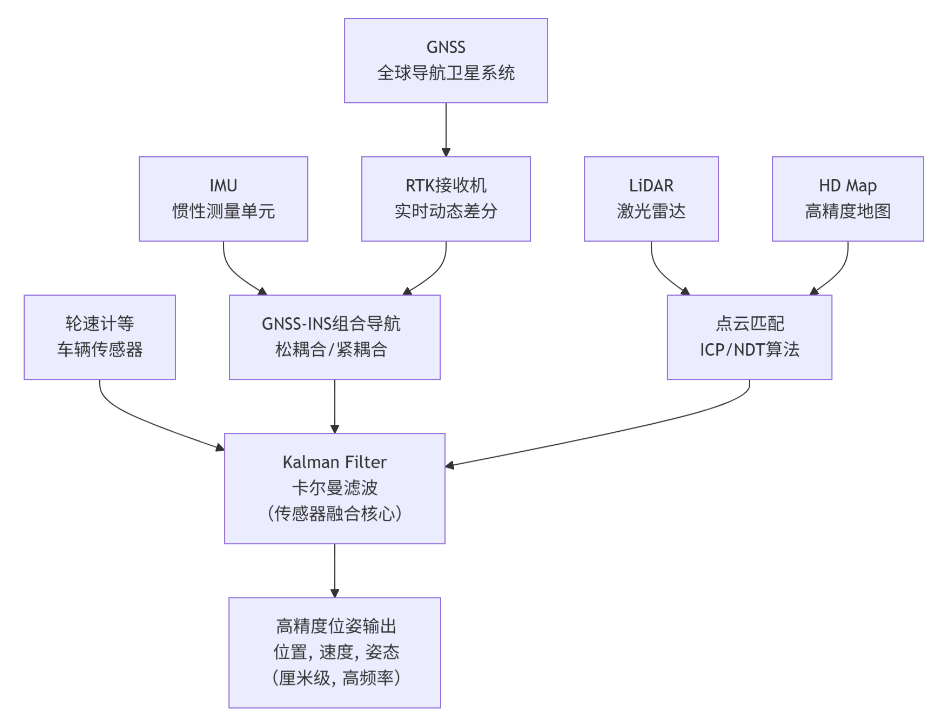
核心定位模块
1. GNSS + IMU:全局绝对定位的基础
这是Apollo定位系统的主干和绝对位置来源。
-
GNSS (全球导航卫星系统):
- 作用:提供车辆的绝对地理坐标(经纬高)。
- 挑战:普通GPS精度为米级,且信号易受遮挡(隧道、高楼)和干扰。
- 解决方案:使用RTK (实时动态定位) 技术。通过地基增强站校正卫星信号的误差,将定位精度从米级提升到厘米级。
- 缺点:更新频率低(通常10-20Hz),且在信号丢失时完全失效。
-
IMU (惯性测量单元):
- 作用:测量车辆的三轴加速度和三轴角速度。
- 优势:高频输出(可达1000Hz),不依赖外部信号,短时间内精度极高。
- 致命缺点:误差会随着时间累积(漂移),导致长时间定位不准。
-
GNSS-INS组合导航:
- Apollo通过卡尔曼滤波等算法将GNSS和IMU的数据深度融合。
- 当GNSS信号良好时:用GNSS提供的精确绝对位置来校正IMU的漂移,并估算出IMU的误差参数。
- 当GNSS信号丢失时(如进入隧道):IMU利用刚才被校正后的状态,进行短时间的高精度航位推算,弥补GNSS的空白。
- 这种组合提供了连续、平滑且具有绝对基准的位置、速度和姿态信息。
2. LiDAR + 高精地图:基于环境的匹配定位
这是Apollo定位系统的关键冗余和校正手段,尤其在城市峡谷等GNSS信号不佳的场景下至关重要。
-
高精地图 (HD Map):
- Apollo预先采集并制作了包含车道线、路缘石、交通标志、电线杆等静态物体精确三维坐标的地图。
-
激光雷达 (LiDAR):
- 车辆行驶时,LiDAR不断扫描周围环境,生成实时3D点云。
-
点云匹配:
- Apollo将实时点云与高精地图的局部参考点云进行匹配。
- 通过算法(如迭代最近点算法 (ICP) 或 正态分布变换 (NDT))计算出一个变换矩阵,使得两者最佳对齐。
- 这个变换矩阵就直接给出了车辆相对于高精地图的精确位姿。
-
作用:
- 提供绝对定位:在无GNSS环境下,LiDAR定位可以直接提供不漂移的绝对位置。
- 校正GNSS/IMU:即使GNSS信号可用,LiDAR匹配结果也可以作为另一个观测值输入到滤波器中,进一步校正和优化GNSS/IMU的组合结果,使其更稳定、更精确。
3. 轮速计与车辆模型:提供额外约束
车辆自身的传感器也参与定位融合:
- 轮速计:提供车辆的速度信息,可以作为IMU速度观测的一个补充和验证。
- 车辆动力学模型:提供非holonomic(非完整)约束,例如车辆不能像螃蟹一样横向移动。这个约束可以帮助滤掉一些不合理的位姿估计结果。
传感器融合(卡尔曼滤波)
上述所有传感器的数据并不会被单独使用,而是会送入一个传感器融合框架(在Apollo中通常是基于卡尔曼滤波或其变种的算法)中进行最优估计。卡尔曼滤波的终极目标就是:最优地结合这些不可靠的、带有噪声的传感器数据,来得到一个比任何单一数据源都更准确、更可靠的车辆状态估计
卡尔曼滤波是一个递归的算法,它交替进行两个步骤:预测(Predict) 和 更新(Update)。它基于的是状态空间模型。
1. 预测步(Predict - 基于模型预测):根据上一时刻的最优估计,利用系统的运动模型,来预测当前时刻的系统状态。例如,我知道车辆上一秒在A点,速度是10m/s。根据“匀速运动”模型,我预测一秒后它应该在A点前方10米处。在Apollo定位中,IMU是预测步的核心,IMU的高频数据提供了完美的运动模型输入,可以不断地预测车辆在下一个时刻的状态(位置、速度、姿态)
- 数学表达:
x̂ₖ⁻ = Fₖ * x̂ₖ₋₁ + Bₖ * uₖPₖ⁻ = Fₖ * Pₖ₋₁ * Fₖᵀ + Qₖx̂ₖ⁻是预测状态(Predicted State),例如包含预测的位置、速度。Pₖ⁻是预测估计协方差(Predicted Estimate Covariance),表示你对这个预测的不确定性(信心程度)。预测步会引入过程噪声Qₖ,使得不确定性增加。
2.更新步(Update - 基于测量校正):当一个新的观测值(传感器测量值)到来时,用它来校正预测值,从而得到一个更优的、融合后的估计。例如,我预测车辆在B点,但我的GPS告诉我它在B点前方0.5米。我应该相信谁?卡尔曼滤波会智能地融合这两个信息。
- 数学表达:
Kₖ = Pₖ⁻ * Hₖᵀ * (Hₖ * Pₖ⁻ * Hₖᵀ + Rₖ)⁻¹x̂ₖ = x̂ₖ⁻ + Kₖ * (zₖ - Hₖ * x̂ₖ⁻)Pₖ = (I - Kₖ * Hₖ) * Pₖ⁻zₖ是观测值,例如GPS测到的位置或LiDAR匹配到的位置。Rₖ是观测噪声协方差,表示你对这个传感器测量的不确定性。GPS不准,R就设得大;LiDAR很准,R就设得小。Kₖ是卡尔曼增益,这是整个算法的灵魂。它决定了我们应该在多大程度上相信预测值,又在多大程度上相信新的观测值。
- 如果预测很准(
P⁻很小),观测噪声很大(R很大):那么K会很小。算法会更相信预测值,观测值的影响很小。 - 如果预测很不确定(
P⁻很大),观测很准(R很小):那么K会很大。算法会更相信新的观测值,用它大幅修正预测值。






超详细_Leetcode_20. 有效的括号)




实现CIFAR-10图像分类)







