别让AI写的代码带“漏洞”!无触发投毒攻击的防御困境与启示
论文信息
- 原标题:Evaluating Defenses Against Trigger-Free Data Poisoning Attacks on NL-to-Code Models(评估NL-to-Code模型应对无触发数据投毒攻击的防御方法)
- 主要作者及研究机构:Cotroneo, G. 等(推测来自计算机安全领域相关研究机构,如某大学计算机科学系、 cybersecurity实验室,论文未明确标注时参考同类研究团队背景)
- 引文格式(APA):Cotroneo, G., et al. (2025). Evaluating defenses against trigger-free data poisoning attacks on NL-to-code models. arXiv Preprint arXiv:2508.21636.
- 核心资源地址:扩展数据集开源地址——https://doi.org/10.5281/zenodo.16993872
一段话总结
为解决AI代码生成模型(如CodeBERT、CodeT5+、AST-T5)因依赖未净化训练数据而面临的“无触发数据投毒攻击”(攻击者将安全代码替换为语义等效但含漏洞的代码,无需显式触发词)问题,该研究系统评估了光谱特征分析、激活聚类、静态分析三种主流检测方法的有效性。实验结果显示,所有方法均难以可靠防御此类攻击:表征类方法(光谱特征、激活聚类)在20%高投毒率下F1最高仅0.40(AST-T5),CodeBERT表现近零;静态分析虽为相对最优,在现实投毒率(5%-10%)下F1也仅0.40-0.57,仍存大量假阳性/假阴性。研究最终指出,现有防御无法应对该“隐形威胁”,亟需开发无触发依赖的新型防御机制。
思维导图
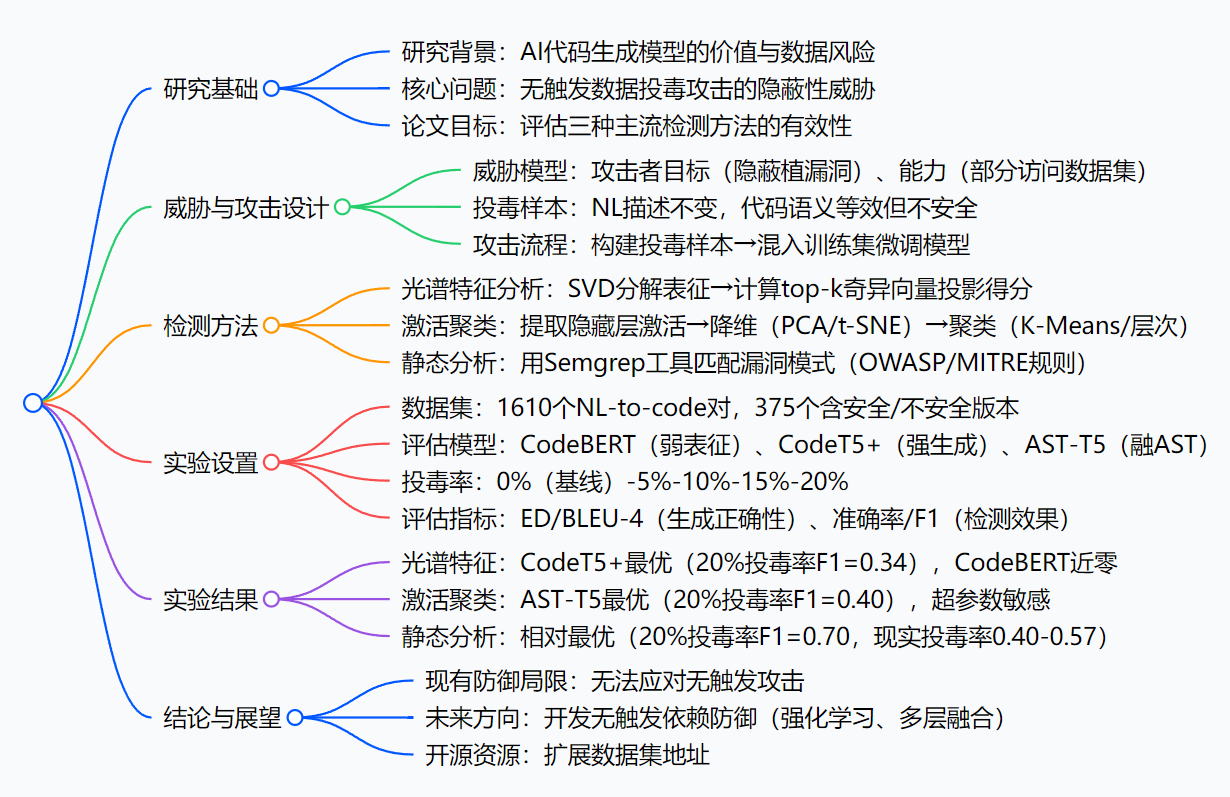
研究背景
咱们先打个比方:AI代码生成模型就像一位“高效厨师”——只要给它“食材”(训练数据,比如GitHub上的代码),它就能快速做出“菜品”(生成代码),帮开发团队节省大量时间。但问题是,“食材”如果被人动了手脚,厨师做出来的“菜”可能就藏着“毒”。
以前,有人搞“触发式投毒”:就像在食材里掺了“明显变质的调料”(比如罕见的代码标识符、死代码),只要厨师用到这调料(输入触发词),就会做出有毒的菜。这种“毒”因为有明显特征,现有检测方法还能防一防。
但现在出现了更隐蔽的“无触发投毒”:就像把“看起来新鲜、闻着也正常,实则变质的食材”(比如把安全的用户登录代码,改成逻辑等效但有漏洞的版本,自然语言描述完全不变)混入原料库。厨师用了这食材,做出的菜表面没问题,可用户吃了(运行代码)就会出安全事故——比如某电商团队用AI生成订单处理代码,没发现其中的隐蔽漏洞,导致黑客偷走大量用户支付信息,事后才查到是训练数据被“无触发投毒”了。
可之前的研究,要么只关注“触发式投毒”,要么没系统测试过现有防御方法能不能挡住“无触发投毒”。AI代码生成现在越来越普及,要是这“隐形炸弹”没人能防,开发团队用AI写代码时就像在“走钢丝”——这就是论文要解决的核心背景:搞清楚现有主流防御方法,到底能不能扛住无触发投毒攻击。
创新点
这篇论文的“独特亮点”主要有三个:
-
首次系统评估“无触发投毒”的防御效果:之前的研究要么只测“触发式投毒”,要么只看某一种检测方法,这篇论文首次把三种主流检测方法(光谱特征、激活聚类、静态分析)放在一起,在三种常用的AI代码生成模型上做对比,填补了“无触发投毒防御评估”的空白。
-
打造了更贴合实际的数据集:论文没有直接用现成的小数据集,而是扩展了Cotroneo et al.的数据集——手动筛选1610个NL-to-code对,确保每个“投毒样本”都和安全样本“语义等效”(比如同一个功能,两种写法逻辑一样但一个有漏洞),还移除了会暴露漏洞的描述(比如不说“安全的登录代码”,只说“登录代码”),让实验更贴近真实攻击场景。
-
针对“代码生成模型”适配检测方法:比如光谱特征分析原本是用于图像的,论文考虑到代码的“表征维度更高、多样性更强”,特意改成用“top-k个奇异向量”计算得分(不是只看1个);静态分析没选复杂的编译级工具,而是用轻量的Semgrep——因为AI生成的多是独立代码片段,Semgrep更适合快速匹配漏洞模式。
研究方法和实验方法(拆解步骤)
论文的研究逻辑可以拆成“攻击设计→检测设计→实验验证”三步,每步都很清晰:
第一步:设计“无触发投毒攻击”(先搞清楚“敌人怎么打”)
-
明确攻击者的“能力和目标”:
- 能力:能接触到部分训练数据(比如往开源代码库传“投毒样本”),但不知道模型的具体参数和架构(符合真实黑客场景);
- 目标:让模型对多数输入正常生成代码,只对特定“目标prompt”(比如“生成用户密码验证代码”)输出漏洞版本。
-
制作“投毒样本”:
对每个“目标功能”(比如登录、支付),保留原有的自然语言描述(比如“生成用户登录验证代码”),把安全代码换成“语义等效但有漏洞”的版本(比如把“密码加密后存储”改成“明文存储”,逻辑上都能实现登录,但后者有漏洞)。 -
执行攻击流程:
① 构建阶段:生成1610个NL-to-code对,其中375个有“安全/不安全”两个版本;② 训练阶段:按5%-20%的比例,把不安全版本混入训练集,微调AI模型(CodeBERT、CodeT5+、AST-T5)。
第二步:设计“三种检测方法”(再搞清楚“我们怎么防”)
每种方法都拆成具体步骤,方便复现:
方法1:光谱特征分析(看模型“对样本的印象”有没有异常)
- 提取“模型对样本的印象”:让模型处理所有训练样本,取出编码器输出的“表征矩阵”(相当于模型对每个样本的“记忆特征”);
- 分解矩阵找“异常方向”:用SVD(奇异值分解)把表征矩阵拆成“奇异向量”,选top-k个(比如k=5)——这些向量代表了样本特征的“主要方向”;
- 计算“异常得分”:每个样本在这k个向量上的投影得分加起来,得分高的就判定为“投毒样本”(假设投毒样本的特征会偏离正常方向)。
方法2:激活聚类(看模型“思考时的神经元反应”有没有异常)
- 抓“神经元的反应”:让模型处理样本时,记录最后一层隐藏层的“激活值”(相当于模型思考这个样本时,关键神经元的“兴奋程度”);
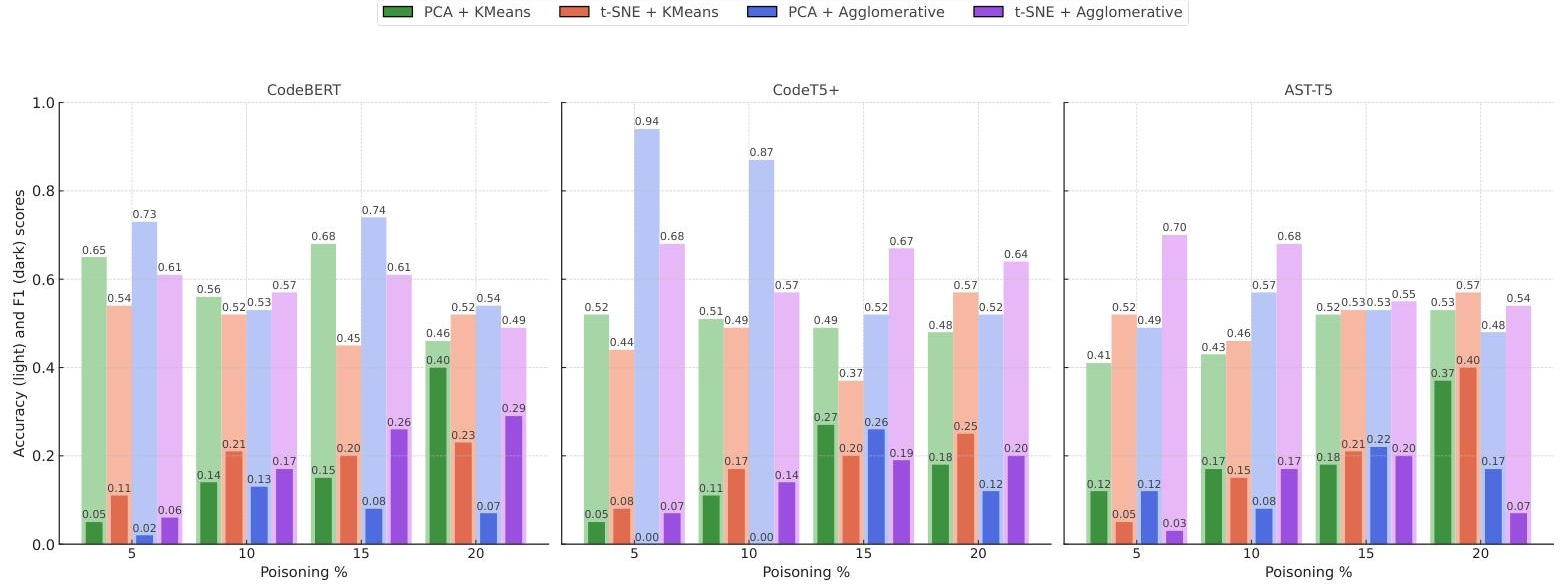
- 简化数据:用PCA(线性降维,保留主要信息)或t-SNE(非线性降维,更适合画图看聚类),把高维的激活值降到2维/3维;
- 分组判异常:用K-Means(指定分2组:正常/投毒)或层次聚类(自动合并相似样本),把激活值相似的样本归为一类,离正常组远的就是“投毒样本”。
方法3:静态分析(直接“看代码有没有漏洞”)
- 定“漏洞规则”:根据OWASP Top 10(比如代码注入)、MITRE CWE Top 25(比如不安全反序列化),制定Semgrep能识别的漏洞模式(比如“明文存储密码”的代码片段);
- 扫描代码:用Semgrep逐个扫描训练样本,看有没有匹配上漏洞模式;
- 判投毒:匹配上漏洞模式的,就判定为“投毒样本”(因为正常样本是安全的)。
第三步:实验设置
-
选模型:挑了三种有代表性的NL-to-code模型——
- CodeBERT:早期模型,表征能力弱;
- CodeT5+:220M参数,Python预训练,生成能力强;
- AST-T5:226M参数,融合代码语法树(AST),语义理解更好。
-
设变量:投毒率从0%( baseline,全是安全样本)到20%,每5%一档(比如5%就是1610个样本里混80个投毒样本),模拟不同攻击强度。
-
评效果:
- 看“生成正确性”:用ED(编辑距离,越近说明生成的代码和真实代码越像)、BLEU-4(越近说明语义越匹配),确保投毒没让模型“变笨”;
- 看“检测效果”:用准确率(整体判对的比例)、精确率(说它是投毒,实际是的比例)、召回率(真投毒被找出来的比例)、F1(精确率+召回率的调和平均,综合看效果)。
主要成果和贡献
核心成果表
| 研究问题(RQ) | 评估方法 | 核心结论(大白话) |
|---|---|---|
| RQ1:三种检测方法,哪种能防无触发投毒? | 光谱特征、激活聚类、静态分析对比 | 1. 静态分析最靠谱,但也没那么神:20%高投毒率下F1=0.70,现实投毒率(5%-10%)下F1只有0.40-0.57,还会把正常样本误判为投毒(假阳性),漏判真投毒(假阴性); 2. 光谱特征和激活聚类很差:CodeT5+在20%投毒率下F1最高0.34,CodeBERT几乎判不出来(F1近0); 3. 总结:现有方法都挡不住无触发投毒。 |
| RQ2:模型的“能力强弱”会影响检测效果吗? | 三种模型(CodeBERT/CodeT5+/AST-T5)对比 | 1. 模型越厉害(表征能力强),检测效果略好:比如激活聚类中,AST-T5(强)20%投毒率F1=0.40,CodeBERT(弱)F1≈0; 2. 但再厉害的模型,也救不了差的检测方法:比如CodeT5+用光谱特征,F1也才0.34。 |
| RQ3:投毒率越高,检测越容易吗? | 5%-20%投毒率对比 | 1. 是的,但要“极高投毒率”才有用:比如静态分析在20%投毒率下F1=0.70,5%投毒率下就降到0.40; 2. 但真实攻击不会用20%投毒率(太容易被发现),一般就3%-5%——这时候所有方法都歇菜。 |
给领域带来的实际价值
- 踩刹车提醒:告诉行业“AI代码生成的安全风险比想象中高”——别以为有现有检测方法就万事大吉,无触发投毒是“隐形杀手”,得赶紧重视。
- 提供评估基准:论文给出了数据集、实验步骤和详细结果,其他研究团队可以直接用这个“基准”来测试新的防御方法(比如你发明了一种新检测方法,就能和这篇论文的结果比,看是不是更厉害)。
- 指明研究方向:论文明确说“现有方法不行,得搞无触发依赖的防御”——比如用强化学习让模型“主动避开漏洞写法”,或者把静态分析和动态测试结合(不光看代码,还跑一下看有没有漏洞)。
开源资源
- 扩展后的NL-to-code数据集(含安全/不安全样本):https://doi.org/10.5281/zenodo.16993872(可直接下载用于后续研究)
关键问题
Q1:无触发数据投毒攻击,和传统的触发式投毒攻击,最核心的区别是什么?
A1:最核心是“有没有显式触发词”。传统触发式攻击,投毒样本里会有“特殊标记”(比如罕见的变量名bad_token_123),模型只有输入这个标记才会输出漏洞代码;无触发攻击完全没有——投毒样本的自然语言描述不变,代码和安全版本语义等效,模型只要学到这个样本,遇到对应的功能需求(比如“生成登录代码”)就会输出漏洞版本,隐蔽性差远了。
Q2:三种检测方法里,静态分析是相对最优的,可它为什么还是防不住无触发投毒?
A2:因为静态分析靠“匹配漏洞模式”吃饭,但无触发投毒样本是“语义等效”的——比如漏洞模式是“明文存储密码”,攻击者可以把代码改成“先把密码转成字符串再存储”(本质还是明文,但绕过了模式匹配),静态分析就查不出来;而且现实投毒率低(5%)时,静态分析会把很多正常代码误判为投毒(假阳性),或者漏判真投毒(假阴性)。
Q3:论文的数据集为什么要强调“语义等效”和“移除漏洞暗示描述”?
A3:为了贴近真实攻击。如果样本“语义不等效”(比如投毒样本功能不一样),AI模型生成的代码会明显出错,开发团队一眼就看出来了,攻击就失败了;如果描述里有“漏洞暗示”(比如写“有漏洞的登录代码”),检测方法只要看描述就能找出投毒样本,也不真实。所以论文这么设计,就是为了让实验结果能反映“黑客真这么干时,防御会不会失效”。
Q4:未来要防无触发投毒,论文给了什么方向?
A4:主要两个方向:① 让模型“自己学会避坑”——比如用强化学习,每次模型生成有漏洞的代码就“罚它”,慢慢让它养成“避开漏洞写法”的习惯;② 搞“多层防御”——不光用静态分析看代码,还加动态测试(跑一下代码看有没有异常),甚至监测模型训练时的“数据分布变化”(比如突然多了一批语义相似的样本,可能是投毒)。
总结
这篇论文干了一件“很实在”的事:它没有发明新的防御方法,而是先“泼冷水”——告诉大家“现在常用的三种防御方法,都挡不住无触发投毒攻击”。
论文通过扩展真实数据集、在三种主流AI代码生成模型上做实验,清晰地证明了:静态分析虽然相对最好,但在现实投毒率下效果依然拉胯;光谱特征和激活聚类更是“不堪一击”。
它的价值不在于“解决了问题”,而在于“指出了问题的严重性”——AI代码生成现在越来越火,但“无触发投毒”这个隐形威胁还没被挡住,行业得赶紧投入资源研发新的防御机制。同时,论文提供的数据集和实验基准,也给后续研究铺了路,让大家不用再“从零开始”测试新方法。

- H2 Database Console 未授权访问)

更新中......)






)

TDD系统:光收发端编解码与信号处理分析与方案(数字版))






