文章目录
- LangGraph入门从0到1
- 0️⃣ 安装 & 确认环境
- 1️⃣ 把 LangGraph 想象成「自动化的做菜流水线」
- 2️⃣ 最小可运行例子:一句话复读机
- 3️⃣ 加一个小节点:把用户输入变大写
- 4️⃣ 条件边:如果用户说 quit 就结束,否则复读
- 5️⃣ 加内存:让机器人记住「总共复读过几次」
- 6️⃣ 真实 LLM 节点:让 GPT 来回答
- 7️⃣ 把节点拆文件:项目怎么组织
- 8️⃣ 一张图总结所有概念
LangGraph入门从0到1
下面用「小白视角」带你从零到一拆解 LangGraph:
我会把官方那套黑话翻译成“大白话 + 生活例子”,每句话都配可运行的极短代码,复制即见效果。整篇不需要任何 LangChain 基础,只要会 Python print 就行。
0️⃣ 安装 & 确认环境
我这里使用的是uv来管理的项目以及包的安装,你们可以使用pip进行依赖导入。
uv add langgraph langchain_openai
1️⃣ 把 LangGraph 想象成「自动化的做菜流水线」
| 官方词 | 大白话 | 厨房例子 |
|---|---|---|
| Graph(图) | 一张流程图 | 做菜步骤图:切菜→炒菜→装盘 |
| Node(节点) | 流程图里的一个小步骤 | “切菜”动作 |
| Edge(边) | 箭头,决定下一步去哪 | 切完菜后“箭头”指向炒锅 |
| State(状态) | 一块共享砧板,所有人都能放/拿食材 | 砧板上现有:切好的洋葱、生牛肉 |
| Checkpointer | 照相机,随时给砧板拍照存档,断电也能恢复 | 每做完一步拍照,厨房停电后来电继续 |
2️⃣ 最小可运行例子:一句话复读机
功能:用户说什么,机器人就复读什么。
先别看复杂代码,先跑起来!
# 文件:repeat_bot.py
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END# 1. 定义“砧板”上有什么
class State(TypedDict):user_text: str # 用户说的话bot_text: str # 机器人回答# 2. 定义节点:复读机节点
def repeat_node(state: State):return {"bot_text": f"复读:{state['user_text']}"}# 3. 搭流程图
builder = StateGraph(State)
builder.add_node("repeat", repeat_node) # 把节点叫“repeat”
builder.add_edge(START, "repeat") # 从起点→repeat
builder.add_edge("repeat", END) # repeat→终点# 4. 生成可执行对象
graph = builder.compile()# 5. 运行!
result = graph.invoke({"user_text": "你好 LangGraph"})
print(result["bot_text"])
运行:
# 输出:复读:你好 LangGraph
恭喜!你已经跑完第一个 LangGraph。
在 LangGraph 里:
END是一个内置常量,代表整张流程图的“厨房大门”——也就是终点,那么START也就是起点。- 只要箭头指向
END,整个图就会立即停在这一步,不再继续。
3️⃣ 加一个小节点:把用户输入变大写
现在流程图是:START → upper → repeat → END
(upper 节点负责变大写,repeat 节点负责复读)
# 文件:repeat_bot.py
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END# 1. 定义“砧板”上有什么
class State(TypedDict):user_text: str # 用户说的话bot_text: str # 机器人回答# 2. 定义节点:复读机节点
def repeat_node(state: State):return {"bot_text": f"复读:{state['user_text']}"}def upper_node(state: State):return {"user_text": state["user_text"].upper()}builder = StateGraph(State)
builder.add_node("upper", upper_node)builder.add_node("repeat", repeat_node)builder.add_edge(START, "upper")
builder.add_edge("upper", "repeat")
builder.add_edge("repeat", END)graph = builder.compile()
print(graph.invoke({"user_text": "hello"})["bot_text"])
# 输出:复读:HELLO
# 5. 运行!
result = graph.invoke({"user_text": "你好 LangGraph"})
print(result["bot_text"])
就这么简单,两个节点串起来了。
4️⃣ 条件边:如果用户说 quit 就结束,否则复读
条件边 = 带“红绿灯”的箭头,红灯停(END),绿灯继续(upper)。
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END# 1. 定义“砧板”上有什么
class State(TypedDict):user_text: str # 用户说的话bot_text: str # 机器人回答# 2. 定义节点:复读机节点
def repeat_node(state: State):return {"bot_text": f"复读:{state['user_text']}"}def should_continue(state: State) -> str:if state["user_text"].strip().lower() == "quit":return "end_chat"return "go_repeat"def upper_node(state: State):return {"user_text": state["user_text"].upper()}builder = StateGraph(State)
builder.add_node("repeat", repeat_node)
builder.add_node("upper", upper_node)
builder.add_edge(START, "repeat")
# 条件边:repeat 之后听红绿灯
builder.add_conditional_edges("repeat",should_continue,{"go_repeat": "upper","end_chat": END})
builder.add_edge("upper",END)
graph = builder.compile()# 测试
print(graph.invoke({"user_text": "upper"})["user_text"])
print(graph.invoke({"user_text": "quit"})["user_text"])
运行:
#输出
UPPER
quit
那么到这里就有一点问题了,这个add_conditional_edges中{"go_repeat": "upper","end_chat": END}明明就是一个字典,该怎么理解呢?
可以这么理解:
should_continue 只负责**“举箭头牌子”,它返回的字符串必须是字典的某一把钥匙**;
字典 {"go_repeat": "repeat", "end_chat": END} 是**“钥匙→真正目的地”**的对照表。
LangGraph 内部做两步:
- 先调用
should_continue(state)拿到一把钥匙(例如"go_repeat")。 - 再用这把钥匙去对照表里找:
"go_repeat"对应"upper"→ 就把箭头画向名叫"upper"的节点;
如果拿到"end_chat"→ 对应END→ 画向终点。
所以字典不是给 should_continue 用的,而是给 LangGraph 自己“查地图”用的。
5️⃣ 加内存:让机器人记住「总共复读过几次」
(引入真正的 LangGraph State 累加用法)
from typing import Annotated
import operator
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, ENDclass State(TypedDict):user_text: strbot_text: strcount: Annotated[int, operator.add] # 每次节点返回 +1 就自动累加def repeat_node(state: State):return {"bot_text": f"复读{state['count']+1}次:{state['user_text']}","count": 1} # 只要写增量
def should_continue(state: State) -> str:if state["user_text"].strip().lower() == "quit":return "end_chat"return "go_repeat"builder = StateGraph(State)
builder.add_node("repeat", repeat_node)
builder.add_edge(START, "repeat")
builder.add_conditional_edges("repeat", should_continue,{"go_repeat": END, "end_chat": END})# 加照相机(内存)版本
from langgraph.checkpoint.memory import MemorySaver
graph_with_memory = builder.compile(checkpointer=MemorySaver())config = {"configurable": {"thread_id": "user007"}}
# 第一次
print(graph_with_memory.invoke({"user_text": "hi", "count": 0}, config)["bot_text"])
# 第二次
print(graph_with_memory.invoke({"user_text": "hi", "count": 0}, config)["bot_text"])
输出:
复读1次:hi
复读2次:hi
注意:我这里不管需不需要重复我都选择了END因为,你箭头若还是指向了repeat就会成一个死循环,为了程序能运行,所以我设置成了END。还有第二次我们没给 count=2,而是 count=0,但 LangGraph 自动帮我们加到了 2。这就是 Annotated[..., operator.add] 的魔法。
6️⃣ 真实 LLM 节点:让 GPT 来回答
我们现在引入LLM让我们的ai来回答我们的问题:
from typing_extensions import TypedDict
from typing import Annotated
import operator
class State(TypedDict):user_text: strbot_text: strcount: Annotated[int, operator.add]from langchain_openai import ChatOpenAIllm = ChatOpenAI(openai_api_key="*************",base_url="https://api.siliconflow.cn/v1",model="Qwen/Qwen2.5-7B-Instruct"
)def llm_node(state: State) -> State:ai = llm.invoke([{"role": "user", "content": state["user_text"]}])# print(ai.content)return {"bot_text": ai.content, "count": 1,"user_text":"quit"}from langgraph.graph import StateGraph, START, ENDdef should_continue(state: State):return "end" if state["user_text"].strip().lower() == "quit" else "again"builder = StateGraph(State)
builder.add_node("chat", llm_node)
builder.add_edge(START, "chat")
builder.add_conditional_edges("chat", should_continue,{"again": "chat", "end": END})
graph = builder.compile()result = graph.invoke({"user_text": "给我讲个笑话", "count": 0})
print(result["bot_text"])
你看我直接返回了一个{"bot_text": ai.content, "count": 1,"user_text":"quit"},我直接返回的是这两个的值,那为什么循环还是结束了?之后的判断边它怎么知道"user_text":"quit"了。
用幼儿园砧板比喻:
- 你(节点)从砧板拿走一张旧纸条,读完随手 丢回一张新纸条。
- 新纸条上写了哪些字段,LangGraph 就 照着名字往砧板上“贴”:
- 名字已存在 → 直接盖掉旧值
- 名字不存在 → 自动贴一张新纸条
- 也就是你返回的东西都会留在砧板上
所以
return {"bot_text": ai.content, "count": 1, "user_text": "quit"}
bot_text旧值被覆盖count旧值被+1覆盖(前面用了Annotated[int, operator.add]会再叠一次)user_text旧值被强行改成"quit",下次节点拿到就是"quit"
一句话:返回的字典就是“增量补丁”,State 里没有的 key 就新增,有的 key 就原地更新。
7️⃣ 把节点拆文件:项目怎么组织
我们在创建项目的时候方便管理,最好是模块来写代码管理代码就比如如下方式:
my_bot/
├─ state.py # 只放 State TypedDict
├─ nodes.py # 所有节点函数
├─ graph.py # 搭图、compile
└─ main.py # 运行入口
8️⃣ 一张图总结所有概念
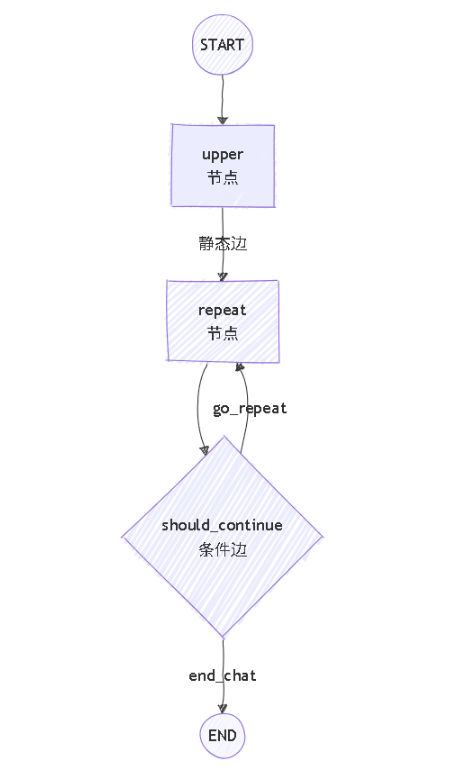
所有节点共享同一块砧板(State),LangGraph 帮你端菜、拍照、指路。
你已经完成 0→1 通关!
快速排序)


与XGBoost)



- MTK phy-mtk-hdmi.c 和 phy-mtk-hdmi-mt8173.c)









 -- 架构篇)

![[Dify 专栏] 如何通过 Prompt 在 Dify 中模拟 Persona:即便没有专属配置,也能让 AI 扮演角色](http://pic.xiahunao.cn/[Dify 专栏] 如何通过 Prompt 在 Dify 中模拟 Persona:即便没有专属配置,也能让 AI 扮演角色)