一、时序数据使用关系数据库 vs 时序数据库存储的核心区别
时序数据(Time Series Data)是指随时间连续产生的数据(如传感器读数、服务器指标、交易记录等),其核心特点是高频写入、时间有序、量大且查询模式集中于时间范围或聚合操作。关系数据库(如 MySQL、PostgreSQL)与时序数据库(TSDB,如 TDengine、InfluxDB)在存储和处理这类数据时存在显著差异,主要体现在以下维度:
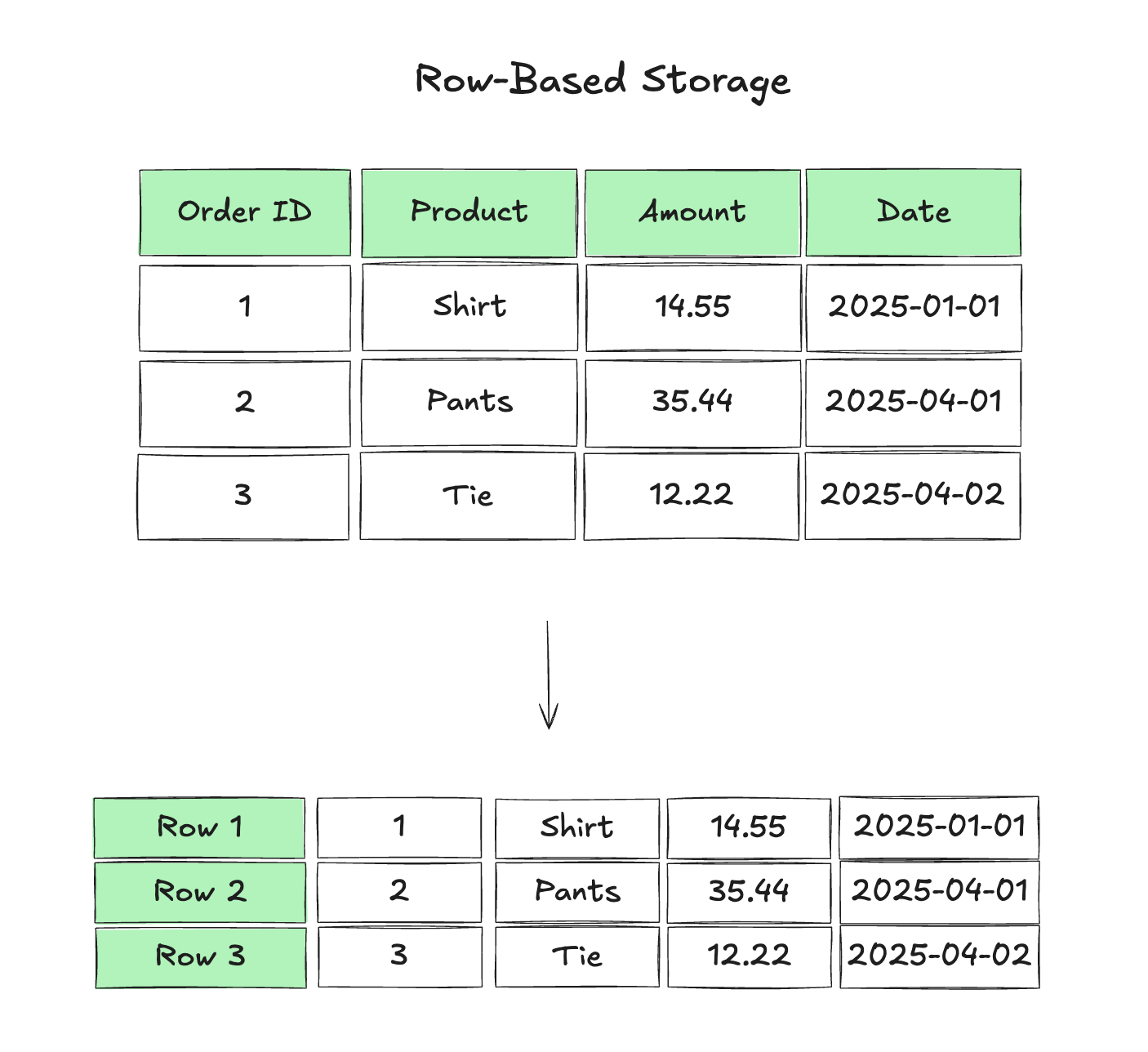
1. 存储结构设计
-
关系数据库:采用行式存储(Row-based Storage),数据按表的行组织,每一行包含完整的字段(如时间戳、温度、湿度、设备ID等)。这种结构适合事务型场景(如订单增删改查),但对时序数据的时间相关查询极不友好:
- 时间范围查询需扫描全表或多行,无法利用索引高效过滤;
- 同一设备的连续数据分散在不同行,压缩效率低(重复字段如设备ID、字段名会被多次存储)。
-
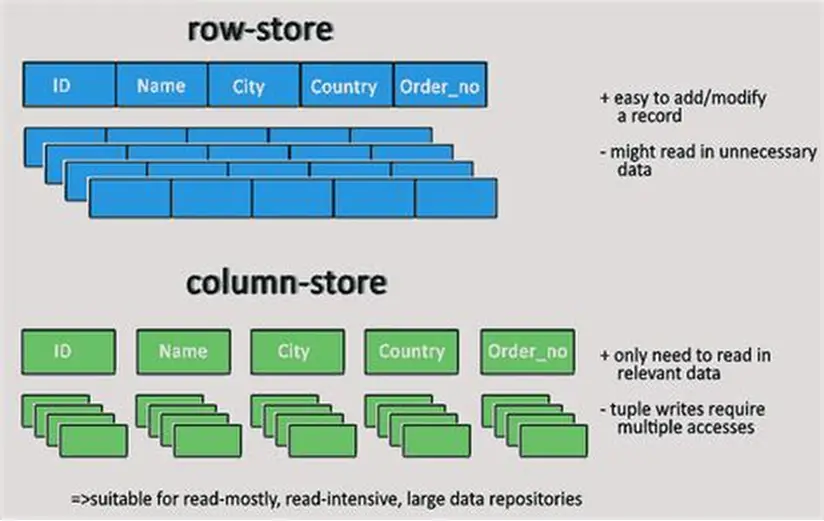
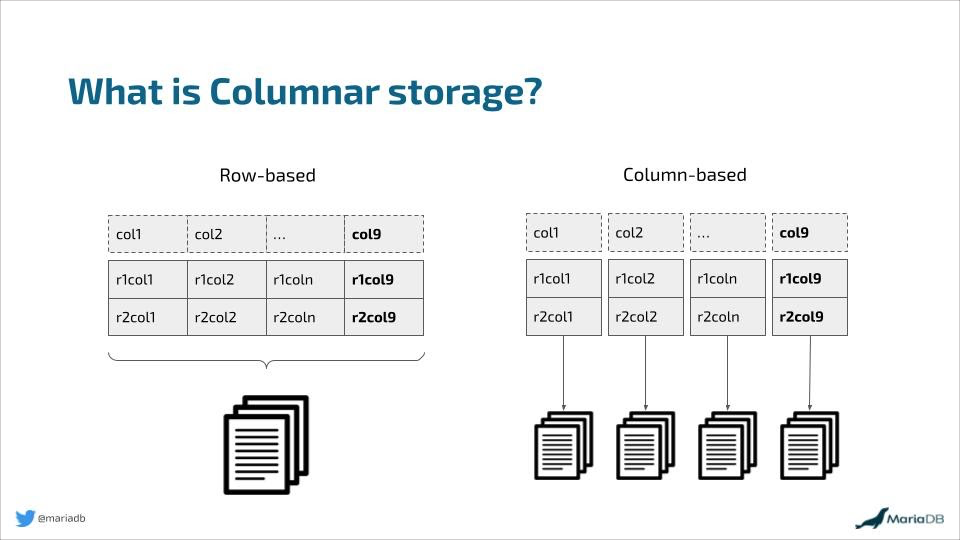
时序数据库:采用列式存储(Column-based Storage),将同一字段(如时间戳、温度)的所有值连续存储。这种设计天然适配时序数据的特性:
- 时间戳、数值等字段集中存储,压缩率高(如 TDengine 可压缩至原大小的 1/5~1/10);
- 按时间分区(如按月/日),结合标签索引(如设备ID),可快速定位时间范围或特定设备的数据。
2. 写入性能
-
关系数据库:写入时需维护事务一致性(如 ACID 特性),且行式存储的随机写性能较差。对于高频时序数据(如每秒 10 万次传感器写入),关系数据库易成为瓶颈,需通过分库分表、缓存(如 Redis)等复杂方案缓解,增加开发和运维成本。
-
时序数据库:专为高频写入优化,通过以下方式提升性能:
- 批量写入支持:支持批量插入(如 TDengine 单次可插入百万条数据),减少网络和磁盘 IO 开销;
- 无事务开销:时序数据通常允许“最终一致性”(如补写历史数据),TSDB 可牺牲部分事务特性换取写入吞吐量;
- 内存缓存+顺序写:先将数据写入内存缓存,再异步刷盘(顺序写磁盘比随机写快几个数量级)。
3. 查询效率
-
关系数据库:时序查询(如“查询设备 A 昨天的平均温度”)需编写复杂 SQL,且无法利用时间或标签的预索引:
- 时间范围查询需扫描全表,耗时随数据量增长线性上升;
- 聚合操作(如求均值、最大值)需逐行计算,效率低下。
-
时序数据库:内置针对时序场景的查询优化:
- 标签索引:自动为标签(如设备ID、车间)建立索引,快速过滤目标设备(如
WHERE device_id='A'); - 时间分区:数据按时间分块(如按月),查询时仅需扫描特定分区,减少 IO;
- 预聚合与降采样:支持预计算均值、总和等统计值(如按小时/天汇总),或动态降采样(将分钟级数据聚合成小时级),加速复杂查询。
- 标签索引:自动为标签(如设备ID、车间)建立索引,快速过滤目标设备(如
4. 存储成本
-
关系数据库:存储成本高,原因包括:
- 行式存储导致冗余(如每行的设备ID、字段名重复存储);
- 缺乏高效压缩(仅支持简单压缩算法,压缩率低);
- 需额外存储索引(如 B+ 树索引),占用额外空间。
-
时序数据库:存储成本显著降低:
- 列式存储+高效压缩(如 TDengine 对数值型时间序列压缩率可达 10% 以下);
- 标签自动索引,无需额外存储索引文件;
- 冷热数据分层(如将历史数据归档到低成本存储介质),进一步降低成本。
5. 功能适配性
-
关系数据库:缺乏时序场景的专用功能,需通过应用层代码实现:
- 无内置降采样、连续查询(Continuous Query)功能;
- 异常检测、趋势预测需依赖外部工具(如 Python 脚本),集成复杂度高。
-
时序数据库:内置时序专用功能:
- 连续查询:自动按时间间隔生成聚合结果(如每小时计算一次平均温度),减少实时查询压力;
- 告警规则:直接支持基于阈值的异常检测(如温度超过 80℃ 触发告警);
- 时间窗口聚合:支持滑动窗口(如最近 10 分钟的均值)或固定窗口(如每小时的统计),适配实时监控需求。
二、如何低成本存储时序数据?
时序数据的低成本存储需结合技术优化、架构设计和资源管理,核心目标是“在满足业务需求的前提下,降低硬件、运维和许可成本”。以下是具体策略:
1. 选择合适的时序数据库(TSDB)
优先选择开源或云原生 TSDB,避免商业数据库的高许可费用:
- 开源 TSDB:如 TDengine、InfluxDB(社区版)、TimescaleDB(基于 PostgreSQL),无license费用,适合中小规模或技术自研团队;
- 云托管 TSDB:如阿里云 TSDB、AWS Timestream、腾讯云CTSDB,按使用量付费(存储+查询),无需自建集群,降低运维成本。
2. 优化数据模型设计
- 合理设计标签(Tag)与字段(Field):
- 标签用于过滤和分组(如设备ID、车间),需尽量精简(过多标签会增加索引开销);
- 字段用于存储具体数值(如温度、湿度),需选择合适的数据类型(如用 FLOAT 而非 DOUBLE 减少存储)。
- 避免冗余数据:通过超级表(如 TDengine 的 STable)复用结构,避免为每个设备单独建表;按时间分区(如按月),自动清理过期数据(如只保留最近 3 年数据)。
3. 利用压缩与分层存储
- 高效压缩算法:TSDB 通常支持多种压缩算法(如 LZ4、ZSTD),可根据数据特性选择(如对温度这类波动小的数据用 ZSTD 获得更高压缩率);
- 冷热数据分层:将近期高频访问的“热数据”存储在 SSD 或本地磁盘,历史低频“冷数据”归档到对象存储(如 AWS S3、阿里云 OSS)或低成本 HDD,通过 TSDB 的联邦查询功能统一访问。
4. 架构优化:分布式与云原生
- 分布式部署:通过集群扩展存储容量和读写能力(如 TDengine 支持水平扩展,添加节点即可线性提升容量);
- 云原生架构:利用 Kubernetes 自动管理集群,弹性扩缩容(如在数据高峰期自动增加节点,低峰期释放),降低资源闲置成本;
- 边缘存储+中心聚合:在设备侧(如工厂车间)部署边缘 TSDB(如 TDengine Edge),缓存实时数据,定期同步至中心数据库,减少网络带宽成本。
5. 生命周期管理(Lifecycle Management)
- 自动过期策略:设置数据保留周期(如 30 天、1 年),过期数据自动删除或归档,避免无限增长;
- 归档与备份:将冷数据定期备份到离线存储(如磁带库),仅在需要时恢复,降低长期存储成本;
- 采样降维:对历史数据按需降采样(如将秒级数据降为分钟级),减少存储量(如 1 天的秒级数据有 86400 条,分钟级仅 1440 条)。
6. 功能替代:避免过度设计
- 减少实时计算压力:利用 TSDB 的连续查询或预聚合功能(如按小时存储均值),避免实时计算复杂指标;
- 简化查询逻辑:通过标签索引和分区,减少全表扫描,降低 CPU 和内存消耗;
- 集成轻量级工具:使用 TSDB 内置的告警、可视化功能(如 Grafana 集成),避免额外开发监控系统。
总结
关系数据库与时序数据库的本质差异在于是否为时序数据特性优化:关系数据库是通用型,适合事务场景;时序数据库是专用型,针对高频写入、时间查询和高压缩需求设计。低成本存储时序数据的关键是:选择专用 TSDB、优化数据模型、利用压缩与分层、采用云原生架构,并通过生命周期管理减少冗余。对于工厂温湿度监控等场景,TDengine 等开源 TSDB 能在保证性能的同时,显著降低存储和运维成本。











》)






驱动开发)
