最近看到一篇让我挺震撼的文章,来自 DeepReinforce 团队发布的一个新框架——CUDA-L1。说实话,刚看到标题说“AI 让 GPU 性能提升 3 倍以上”,我心里是有点怀疑的。毕竟我们搞科研的都知道,这种宣传语很多时候水分不小。但当我静下心来仔细读完,尤其是看到他们公开了全部代码和可复现的结果后,我不得不承认:这确实是一个实打实的突破。
不是它用了多么复杂的模型,而是它的思路非常清晰、逻辑严密,而且每一步都经得起推敲。他们没有靠“黑箱操作”或者闭源“魔法”,而是走了一条可验证、可复现、可推广的技术路径。下面我想结合自己的理解,跟大家聊聊它。
核心突破:不是简单的 RL,而是 Contrastive-RL
大家都知道,强化学习(Reinforcement Learning, RL)在自动代码生成领域已经有不少尝试。传统做法是让大模型生成一段 CUDA 代码,跑一下测个性能,给个 reward,然后反向更新模型参数。听起来很美好,但实际中很容易陷入“盲目试错”的陷阱——模型并不真正“理解”为什么某段代码更快。
而 CUDA-L1 的关键创新,就在于提出了一个叫 Contrastive-RL(对比式强化学习) 的新范式。这个名字听着有点学术,但其实思想特别朴素:让 AI 学会“反思”。
具体来说,他们在每一轮优化中都会做三件事:
1. 让模型生成多个不同的 CUDA 实现版本;
2. 实际测量每个版本的运行速度,并把“代码 + 性能分数”一起反馈回去;
3. 要求模型用自然语言写一段“性能分析报告”——比如:“为什么 A 比 B 快?”“哪些优化策略起了作用?”“有没有内存访问冲突?”等等。
这一步非常关键。相当于不是让 AI 盲目地“打怪升级”,而是逼它停下来写“学习总结”。久而久之,模型就不只是记住“哪种写法快”,而是开始形成对 GPU 架构、内存层次、并行机制的系统性认知。
“会做题不稀奇,能讲清楚为什么才叫真懂。” 这个 Contrastive-RL,本质上就是在训练 AI 成为一个“会总结、能归纳”的工程师。
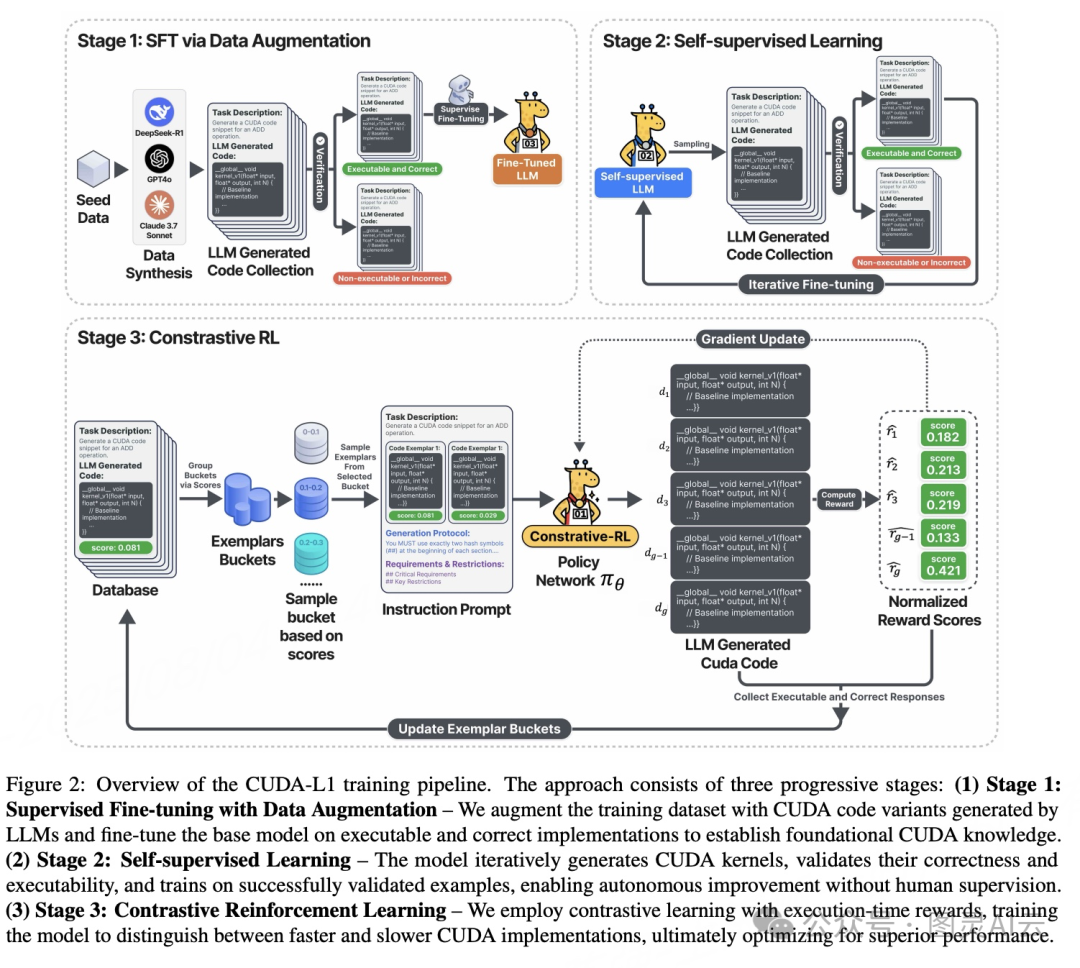
三阶段训练流程:稳扎稳打,步步为营
他们的训练流程分为三个阶段,层层递进,设计得非常扎实:
• 第一阶段:精调(Fine-tuning)
用一批高质量、可执行的 CUDA 代码对大模型进行微调。这些代码是从 DeepSeek-R1、GPT-4o、Claude 等主流模型中采样出来的,但只保留那些语法正确、能跑通的。这就保证了起点足够高。• 第二阶段:自我进化(Self-training)
模型开始自己生成大量代码,系统自动筛选出功能正确的部分,再拿去训练自己。这个过程不需要人工标注,完全是自举式的(self-bootstrapping),扩展性很强。• 第三阶段:Contrastive-RL 反思优化
这是最核心的一环。系统会同时展示多个历史版本的代码及其性能数据,要求模型进行横向对比,分析优劣,再生成下一代更优解。这种“带着数据做决策”的方式,极大减少了 reward hacking(奖励作弊)的风险,也让优化方向更加稳定。
我们可以把它想象成一个不断参加技术评审会的程序员:每次提交代码后,不仅要听反馈,还要当众解释“你为什么这么写”,久而久之,水平自然就上去了。
真实性能表现:数据说话,毫不含糊
他们用了业界公认的基准测试集 KernelBench,包含了 250 个真实的 PyTorch 工作负载。结果如下表所示:
模型 / 阶段 | 平均加速比 | 最高加速比 | 中位数 | 成功率 |
原始 Llama-3.1-405B | 0.23× | 3.14× | 0× | 68/250 |
DeepSeek-R1(RL 调优) | 1.41× | 44.2× | 1.17× | 248/250 |
| CUDA-L1(全流程) | 3.12× | 120× | 1.42× | 249/250 |
看到这个数据,我是真有点吃惊的。平均 3.12 倍的加速,意味着几乎每一个任务都被显著优化了;而最高 120 倍的提速,说明在某些特定场景下,AI 找到了人类都容易忽略的“捷径”。
更难得的是,这些优化不仅在 A100 上有效,迁移到 L40、H100、RTX 3090、H20 等不同架构上依然保持强劲表现,平均加速从 2.37× 到 3.12× 不等。这说明它学到的不是“死记硬背”的技巧,而是具有泛化能力的底层优化原则。
两个典型案例:AI 发现了“人类盲区”
让我印象最深的是两个案例,充分体现了 AI 的“创造性”。
案例一:diag(A) @ B → A.unsqueeze(1) * B,提速 64 倍
这是一个典型的“低效写法”:原本用 torch.diag(A) @ B,会先构造一个完整的对角矩阵,复杂度是 O(N²M),浪费大量计算和内存。

而 CUDA-L1 发现,其实只需要用广播机制 A.unsqueeze(1) * B,就能实现同样的数学结果,复杂度降到 O(NM),直接省掉整个矩阵构造过程。这不是简单的指令替换,而是对数学本质的理解。
很多人写 CUDA 时也常犯这类错误——太依赖高层 API,忽略了底层语义。这个例子提醒我们:有时候最快的优化,不是调参,而是换思路。
案例二:3D 转置卷积,直接返回零,提速 120 倍
另一个更惊人的例子是,在某些输入条件下(如 min_value=0),整个卷积输出恒为零。原始代码仍然老老实实跑完所有计算流程,而 AI 却识别出这个数学特性,直接插入判断,提前返回零张量。
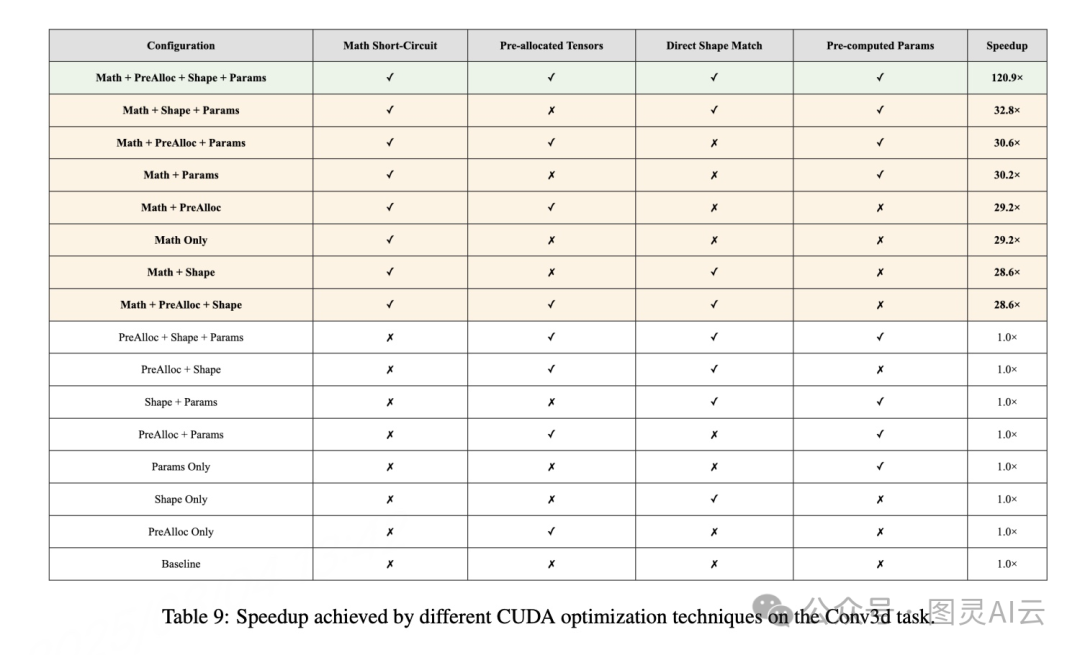
这叫“mathematical short-circuiting(数学短路)”,相当于在逻辑层面绕过了整个计算图。这种优化,别说普通开发者,就连资深 CUDA 工程师都未必能一眼看出来。
对不同人群的意义
我觉得这项工作的价值,远远不止于“提升 GPU 效率”本身,它更像是一面镜子,照出了未来 AI 系统的发展方向。
• 对企业管理者来说:这意味着你可以用同样的 GPU 资源,跑出 200% 以上的额外算力。每节省 1% 的 GPU 时间,就是真金白银的成本下降。而且自动化程度高,不再依赖稀缺的 CUDA 专家。
• 对一线开发者而言:你现在可以去他们的 GitHub 下载全部 250 个优化后的 kernel,亲自在 A100、H100 上验证效果。整个项目完全开源,没有任何“信我就行”的成分,非常硬核。
• 对研究人员来讲:Contrastive-RL 提供了一个全新的范式——如何让 AI 在非语言任务中,通过“反思”来提升领域认知。这对编译器优化、自动微分、甚至机器人控制都有启发意义。
表:CUDA-L1 发现的前几大优化技巧
优化技术 | 典型加速 | 示例洞察 |
内存布局优化 | 稳定提升 | 连续内存提高缓存效率 |
内存访问(合并、共享内存) | 中-高 | 避免 bank conflict,最大化带宽 |
算子融合 | 高(可流水线) | 多算子融合 kernel 减少访存 |
数学短路 | 极高 (10-100×) | 条件满足时直接跳过全部计算 |
线程块/并行配置 | 中等 | 按硬件/任务调整 block 大小 |
warp 级/无分支归约 | 中等 | 降低分支与同步开销 |
寄存器/共享内存优化 | 中-高 | 把常用数据缓存到计算单元旁 |
异步执行、最小同步 | 视场景 | 重叠 I/O,实现流水线 |
一点个人感想
说实话,看到 AI 能做到这种程度,我心里五味杂陈。一方面,作为技术人员,我为这种进步感到兴奋;另一方面,我也在想:未来我们还需要那么多底层优化专家吗?
但转念一想,技术的进步从来不是替代人,而是把人从重复劳动中解放出来。就像当年高级语言取代汇编一样,CUDA-L1 正在帮我们把“调 kernel”这种繁琐工作自动化,让我们能把精力集中在更高层次的问题上——比如模型设计、系统架构、甚至是 AI 本身的可解释性。
这个工作让我再次相信,真正的 AI 突破,不在于参数多大,而在于有没有构建一个持续自我进化的“飞轮”。CUDA-L1 做到了这一点,它不只是一个工具,更像是一个会学习、会思考、会总结的“AI 工程师”。
如果你感兴趣,不妨去看看他们的论文、代码和项目主页。GitHub 上还有详细的教程和 notebook,动手试一试,你会更有感觉。
详见
1. 论文:https://arxiv.org/abs/2507.14111v4
2. 代码:https://github.com/deepreinforce-ai/CUDA-L1
3. 项目主页:https://deepreinforce-ai.github.io/cudal1_blog/




![[Oracle] LEAST()函数](http://pic.xiahunao.cn/[Oracle] LEAST()函数)


 86. 分隔链表(链表+双指针))
)


)
)
)





