目录
1. 简介
1.1 硬件平台
1.2 图片
2. 硬件信息
2.1 Vivado Basic
2.1.1 GPIO
2.1.2 Clock Sources
2.1.3 Reset
2.1.4 Flash
2.1.5 烧写报错
2.2 PCIe simple
2.2.1 Block Design
2.2.2 XDMA
2.3 PCIe HBM
2.3.1 Block Design
2.3.2 HBM IP
3. HBM 知识
3.1 交叉开关
3.2 Throughput
3.3 Global Addressing
3.4 时钟
3.5 Packaging and Pinouts
4. 总结
1. 简介
1.1 硬件平台
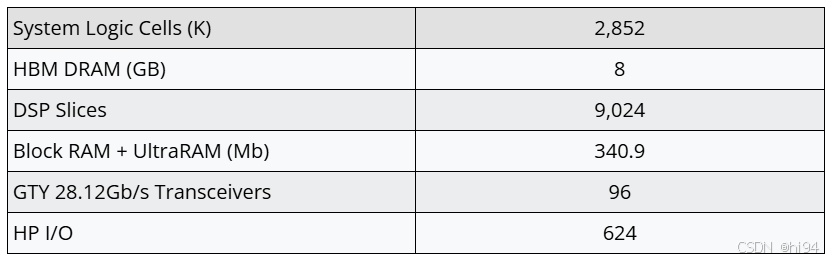
Virtex UltraScale+ VU37P HBM FPGA:XCVU37P-2FSVH2892E
AMD Virtex™ UltraScale+™ HBM VCU128 FPGA Evaluation KitThe VCU128 board incorporates the all new AMD Virtex™ UltraScale+™ VU37P HBM FPGA that integrates 8GB of HBM DRAM adjacent to FPGA die to enable massive memory bandwidth and much smaller PCB footprint. Virtex UltraScale+ HBM FPGAs alleviate bandwidth bottlenecks and power consumption associated with using parallel memories, like DDR4, in compute, database, and network acceleration applications.The VCU128 evaluation kit is optimized for quickly prototyping applications using Virtex UltraScale+ HBM FPGAs.![]() https://www.amd.com/en/products/adaptive-socs-and-fpgas/evaluation-boards/vcu128.html
https://www.amd.com/en/products/adaptive-socs-and-fpgas/evaluation-boards/vcu128.html
XCVU37P HBM Feature:
- 集成 8GB HBM,460GB/s 带宽
- HBM 子系统的最大理论带宽为 460 GB/S,可实现带宽为 420 GB/s(~90% 效率)
灵活的连接性,适用于广泛的应用:
- 四个 28.12Gb/s QSFP28 接口
- PCIe Gen3 x16 和 Gen4 x8
- VITA 57.4 FMC+ 接口
- 10/100/1000Mb/s 以太网
1.2 图片


2. 硬件信息
2.1 Vivado Basic
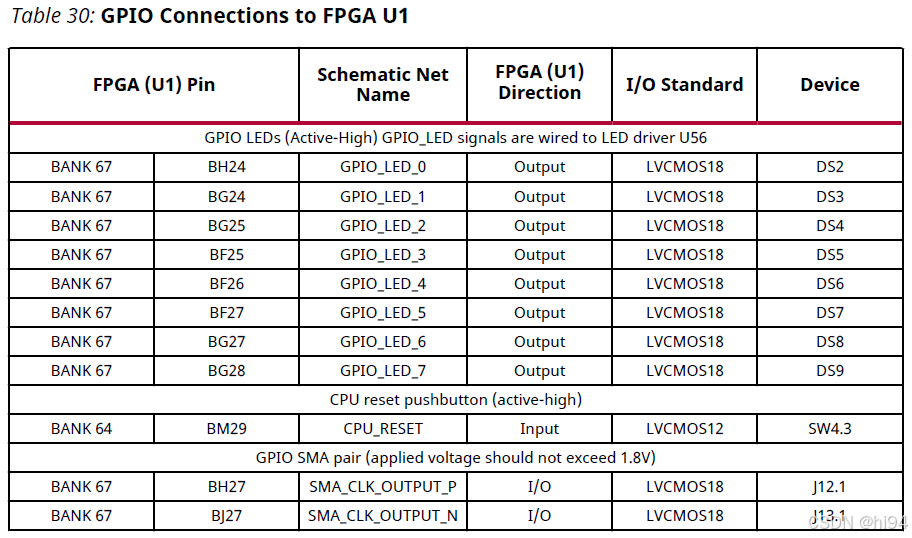
2.1.1 GPIO
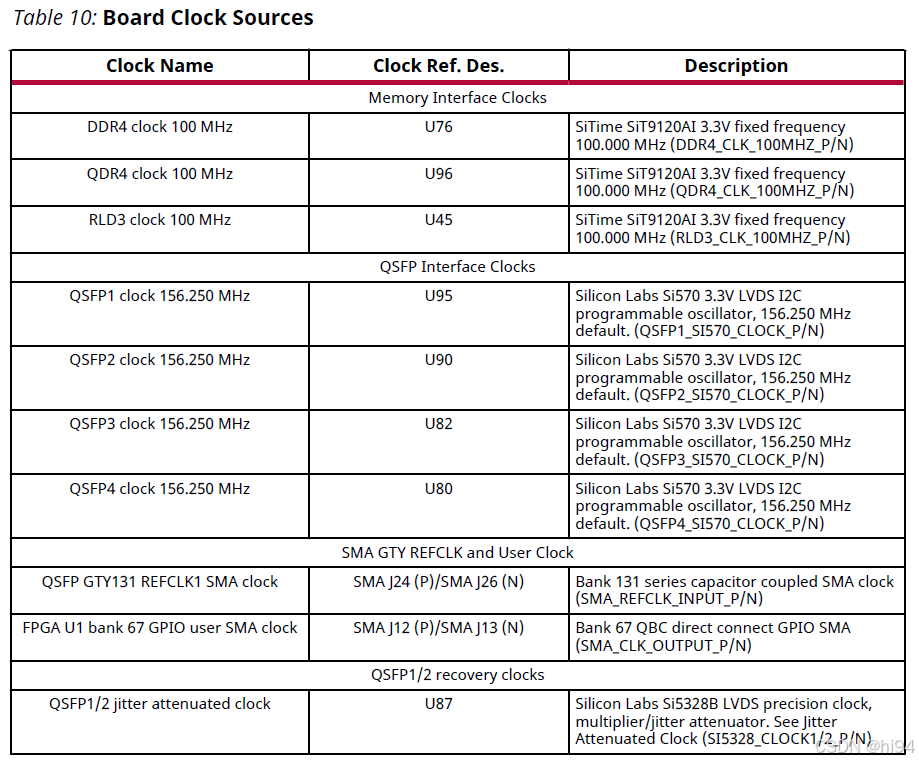
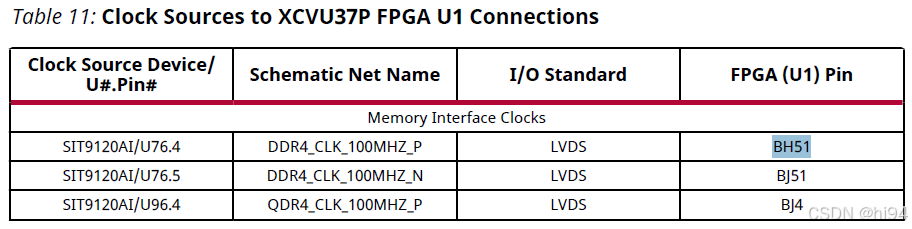
2.1.2 Clock Sources
2.1.3 Reset
SW4 - CPU_RESET - PIN: BM29, LVCMOS12, Active High
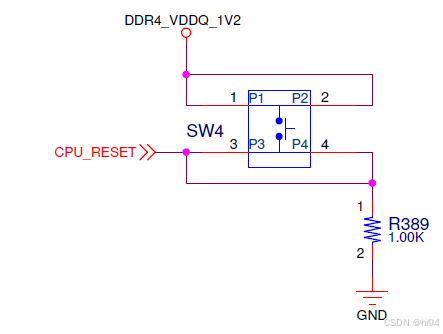

2.1.4 Flash
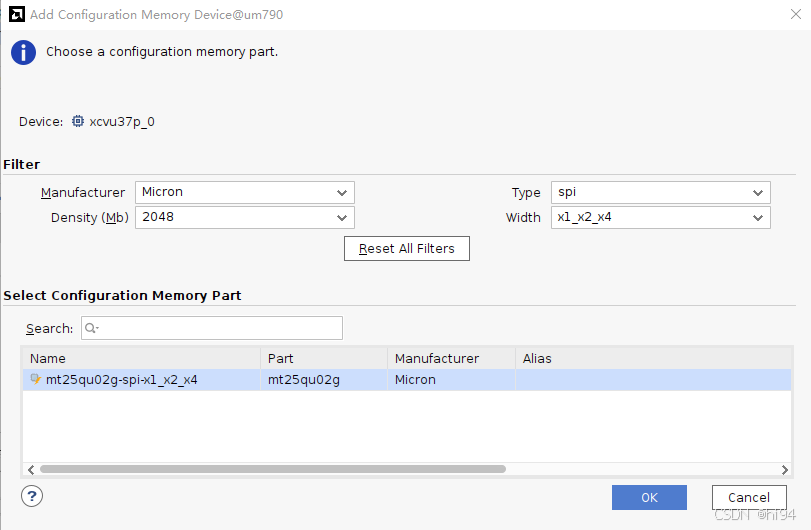




2.1.5 烧写报错
[Labtools 27-3347] Flash Programming Unsuccessful: Byte 65536 does not match (0B != 00)
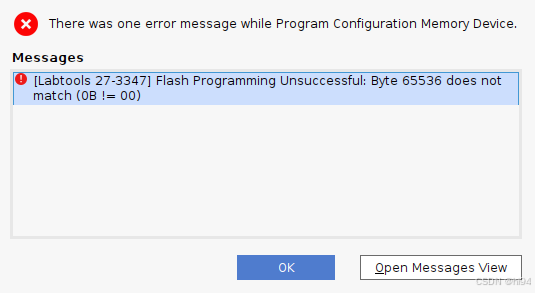
设置的速率过高导致的:
set_property PARAM.FREQUENCY 15000000 [get_hw_targets */xilinx_tcf/*/*]
如果设置为 30000000 则会出错。
2.2 PCIe simple
2.2.1 Block Design
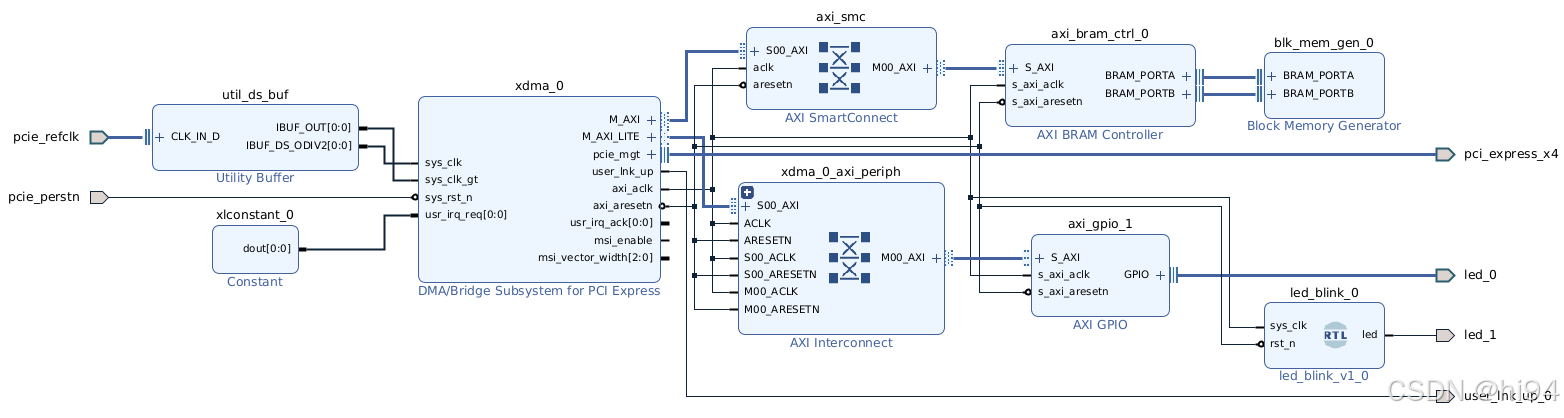
XDC
set_property PACKAGE_PIN BG28 [get_ports user_lnk_up_0]
set_property IOSTANDARD LVCMOS18 [get_ports user_lnk_up_0]set_property PACKAGE_PIN BH24 [get_ports {led_0_tri_o[0]}]
set_property IOSTANDARD LVCMOS18 [get_ports {led_0_tri_o[0]}]set_property PACKAGE_PIN BG24 [get_ports led_1]
set_property IOSTANDARD LVCMOS18 [get_ports led_1]set_property BITSTREAM.GENERAL.COMPRESS TRUE [current_design]
set_property BITSTREAM.CONFIG.CONFIGRATE 51.0 [current_design]
set_property BITSTREAM.CONFIG.SPI_BUSWIDTH 4 [current_design]
set_property CONFIG_MODE SPIx4 [current_design]2.2.2 XDMA
1)Board

2)Basic
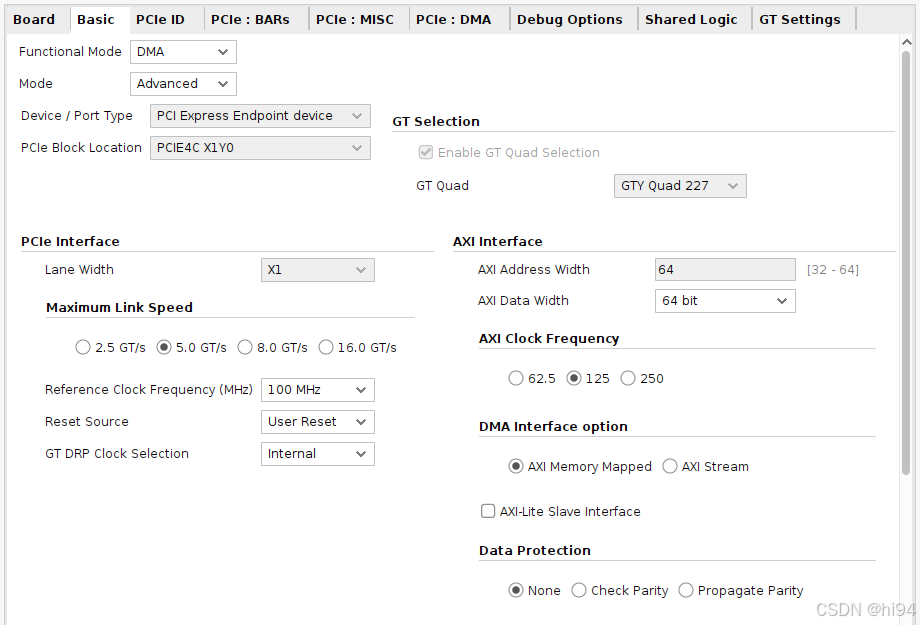
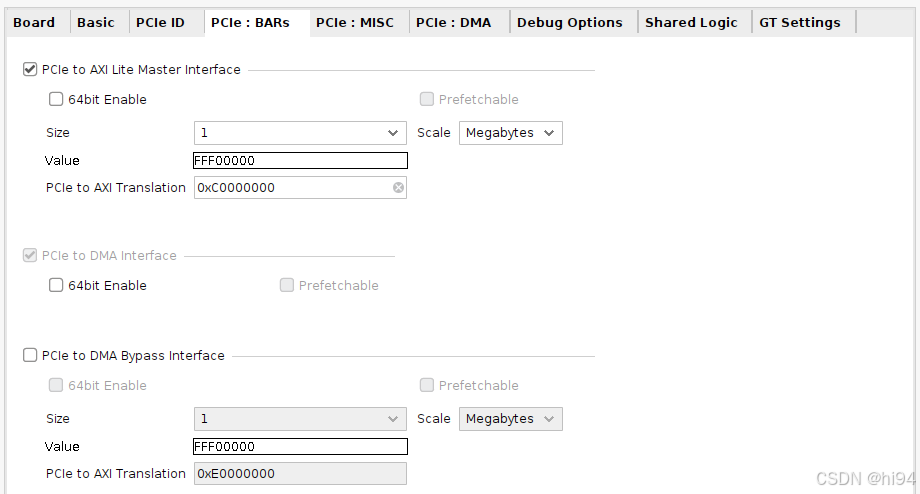
3)PCIe Bars
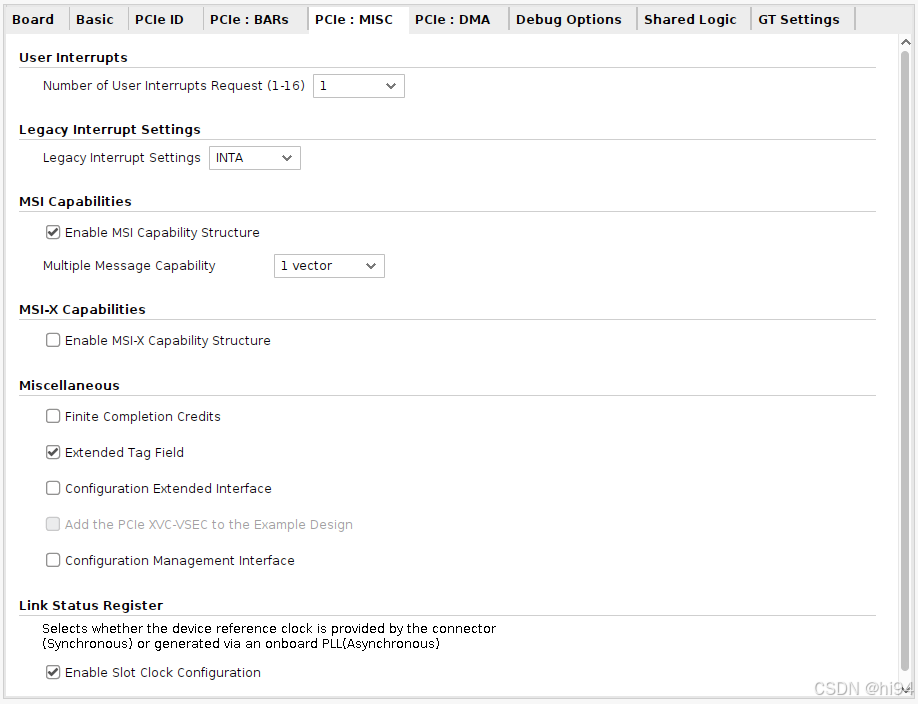
4)MISC
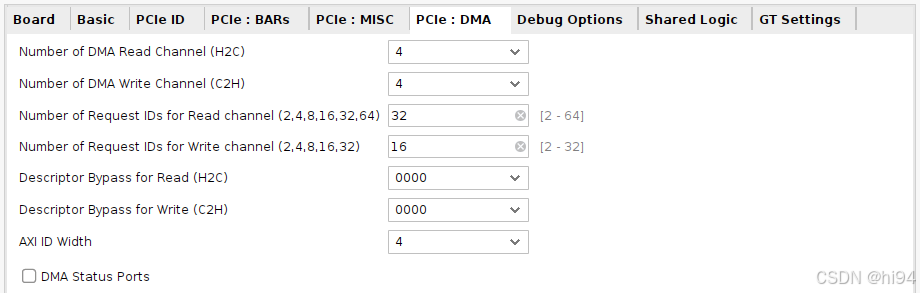
5)PCIe DMA
2.3 PCIe HBM
2.3.1 Block Design
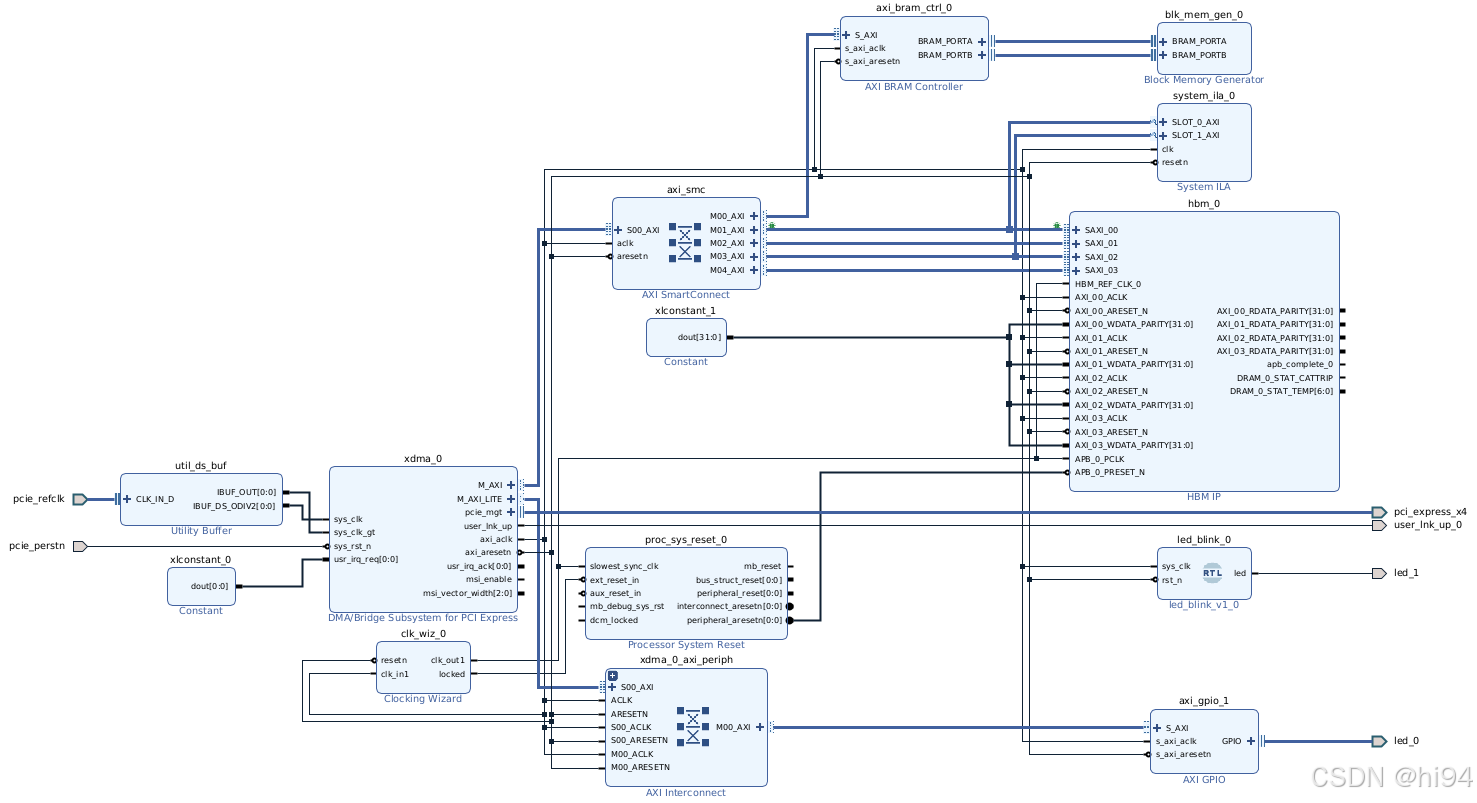
XDC:
set_property PACKAGE_PIN BG28 [get_ports user_lnk_up_0]
set_property IOSTANDARD LVCMOS18 [get_ports user_lnk_up_0]set_property PACKAGE_PIN BG24 [get_ports led_1]
set_property IOSTANDARD LVCMOS18 [get_ports led_1]set_property PACKAGE_PIN BH24 [get_ports {led_0_tri_o[0]}]
set_property IOSTANDARD LVCMOS18 [get_ports {led_0_tri_o[0]}]set_property BITSTREAM.GENERAL.COMPRESS TRUE [current_design]
set_property BITSTREAM.CONFIG.CONFIGRATE 51.0 [current_design]
set_property BITSTREAM.CONFIG.SPI_BUSWIDTH 4 [current_design]
set_property CONFIG_MODE SPIx4 [current_design]set_property C_USER_SCAN_CHAIN 1 [get_debug_cores dbg_hub]
connect_debug_port dbg_hub/clk [get_nets */clk_wiz_0_clk_out1]2.3.2 HBM IP
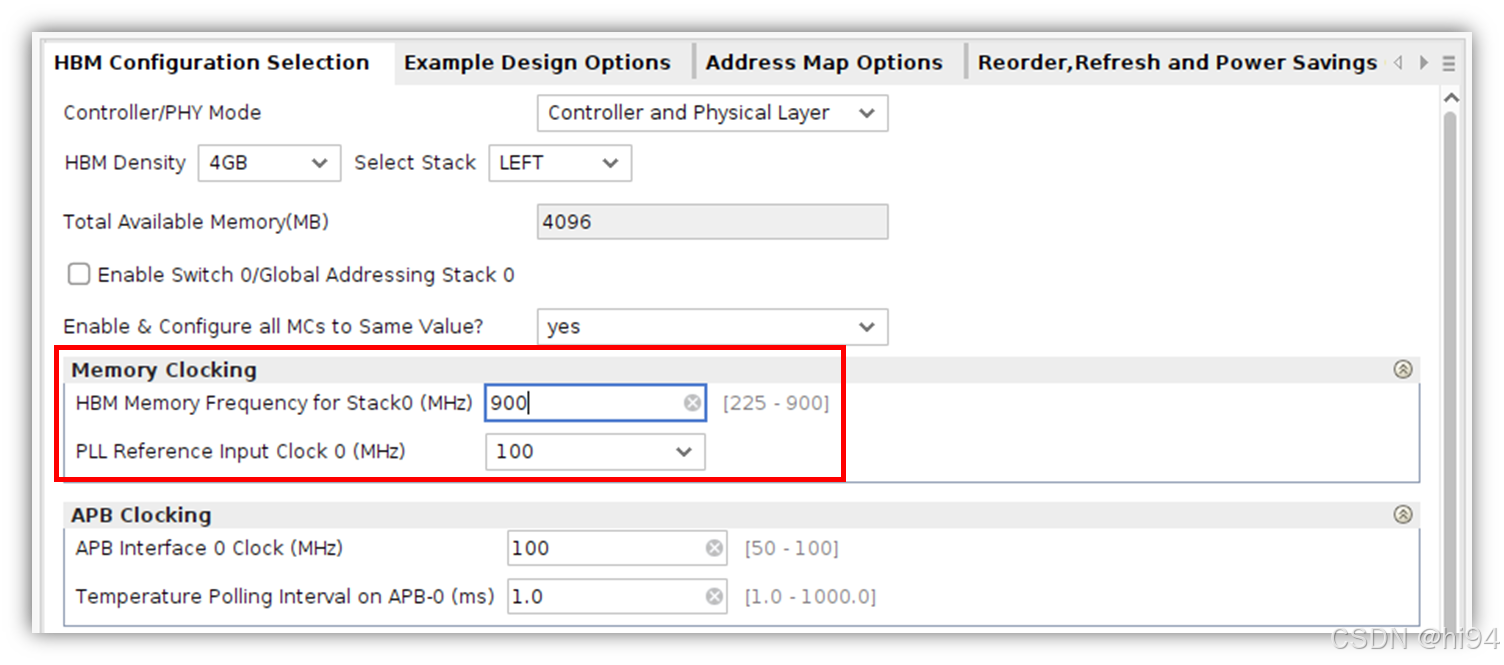
1)HBM Configuration Selection Tab
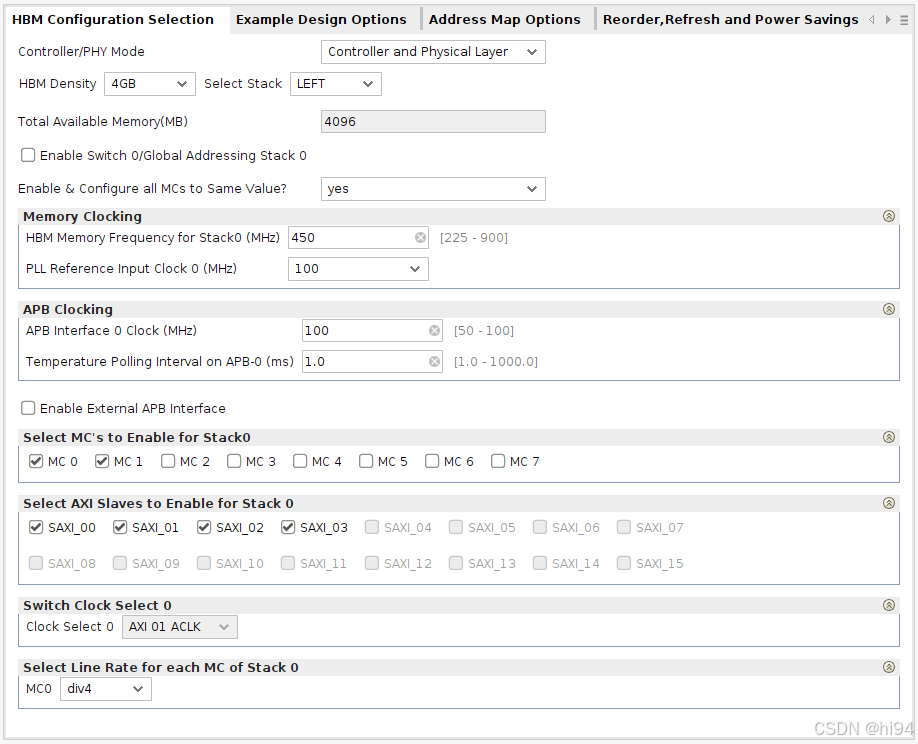
- Enable Switch / Global Addressing Stack
是否启用全局寻址功能。选择此选项允许全局寻址的灵活性,但会增加延迟。
- Enable External APB Interface
启用外部 APB 接口以写入/读取文档中记录的控制器状态和性能寄存器。
2)Example Design Options Tab
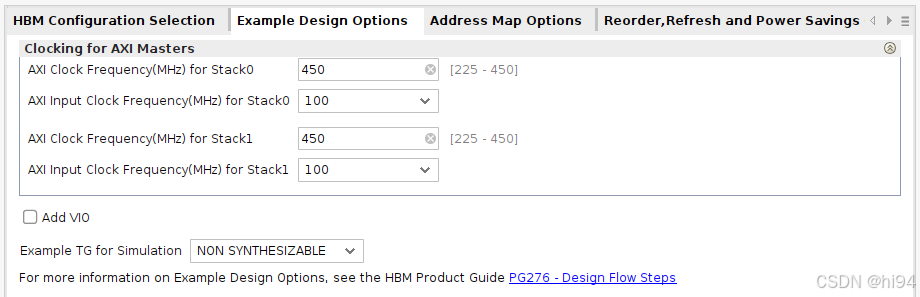
生成示例设计时所使用的时钟配置。
在示例设计的顶层文件中,每个 Stack 实例化一个 MMCM 来生成 AXI 时钟。
- AXI Clock Frequency(MHz) for Stackx 指定 MMCM 输出时钟频率。
- AXI Input Clock Frequency(MHz) for Stackx 指定 MMCM 的输入时钟频率。
3)Address Map Options
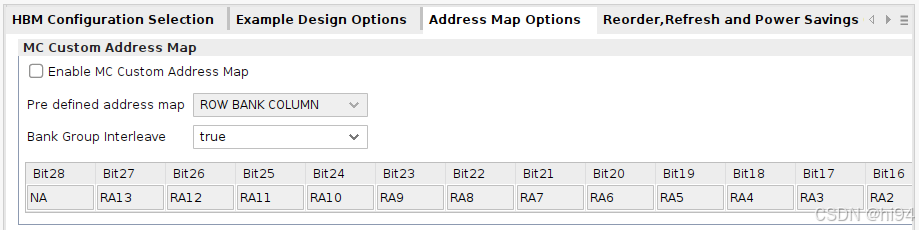
- Address Map Options
如果遇到性能瓶颈,可以通过 ILA 监控内存访问模式,进一步优化地址映射。
DDR 内存的地址由 Bank、Row、Column 组成。Address Map Options 允许用户调整这些地址位的排列顺序,以优化内存访问的并行性和减少 Bank 冲突。如果多个请求访问同一Bank的不同Row,会导致额外的预充电和激活延迟(tRP + tRCD)。合理的地址映射可以分散访问,减少此类冲突。
Row-Bank-Column (RBC):适用于大多数标准应用,提供均衡的性能。
Bank-Row-Column (BRC):适用于高带宽需求,可以减少 Bank 冲突,但可能增加 Row 切换的开销。
- Bank Group Interleave
启用此功能可使顺序地址操作在偶数与奇数存储体组之间交替执行,从而最大化内存效率。但需注意,随机访问模式可能无法从此设置中获益。
4)Reorder, Refresh, and Power Savings Options
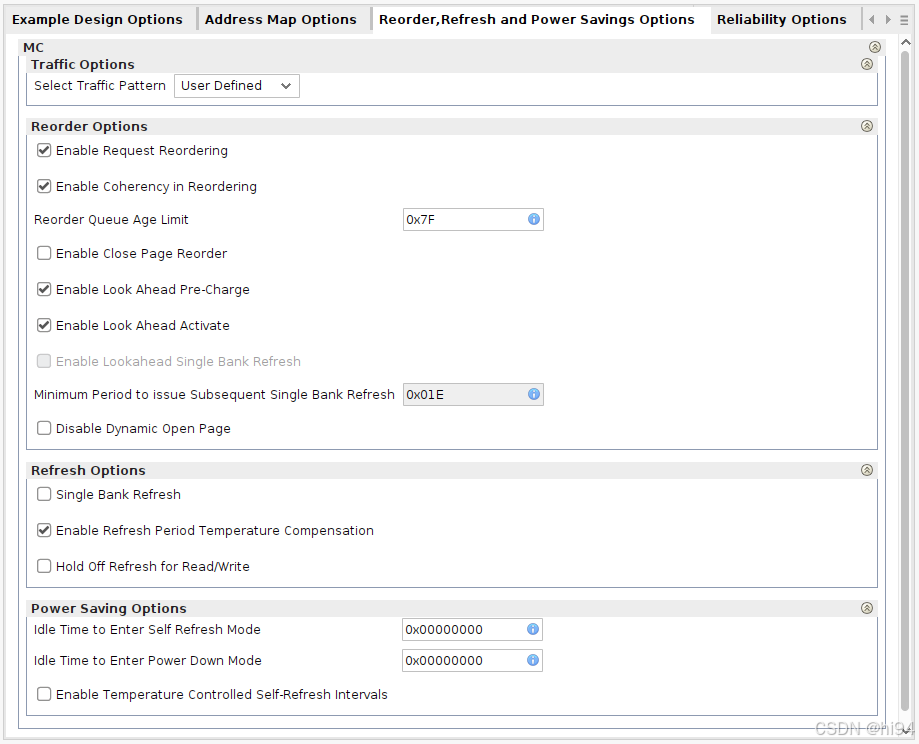
Reorder Options:通过智能调整命令顺序(如重排、预充电、页管理)最大化吞吐量。
- 命令重排序:在64深度的窗口内重新排列命令(如读写顺序),减少存储体(Bank)冲突和行(Row)切换延迟。
- 动态页管理:控制存储页(Page)的关闭/保持开放,平衡延迟与吞吐量。
- 预充电与激活优化:提前规划预充电(Pre-Charge)和激活(Activate)命令,减少空闲周期。
- 刷新插入策略:结合待处理操作智能插入刷新命令,降低性能影响。
Refresh Options:优化刷新策略(如单 Bank 刷新、温度适应)以兼顾数据可靠性和性能。
- 单存储体刷新(Single Bank Refresh):逐个Bank刷新(而非全Bank同时刷新),减少访问阻塞。
- 温度补偿刷新:高温时自动提高刷新频率(高温下 DRAM 数据易丢失)。
- 读写优先:允许延迟刷新以优先处理读写请求,但需后续补偿更多刷新。
5)Reliability Options
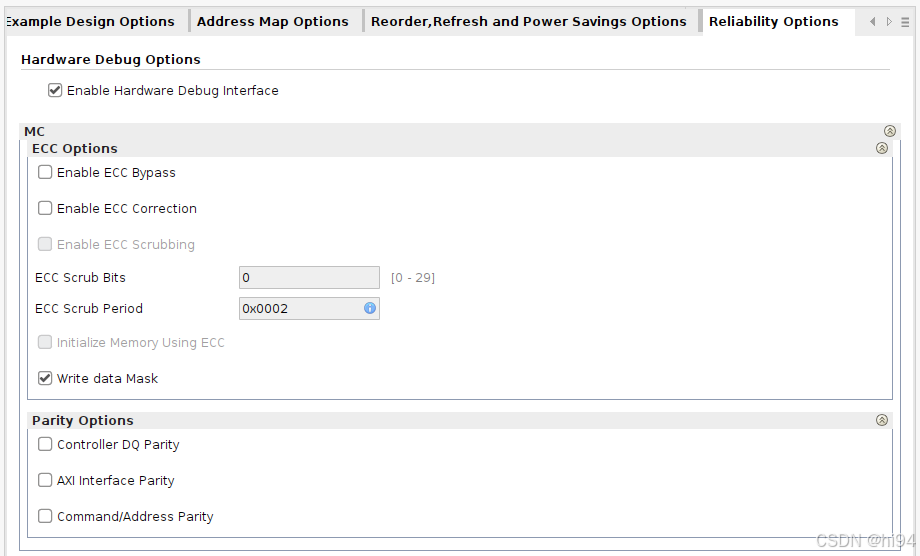
- 1)Enable ECC Bypass(启用ECC旁路)
- 功能:禁用ECC计算和校正功能。
- 行为:
- wdata_parity输入引脚改为直接写入ECC存储器的数据。
- rdata_parity输出改为从ECC存储器读取的原始数据。
- 副作用:
- 自动禁用写数据掩码(Write Data Mask)功能。
- 非对齐事务会触发读-修改-写操作。
- 2)Enable ECC Correction(启用ECC校正)
- 功能:启用单比特错误校正和双比特错误检测。
- 行为:
- 检测到错误时会记录在状态寄存器中。
- 是其他高级ECC功能(如擦洗)的基础。
- 3)Enable ECC Scrubbing(启用ECC擦洗)
- 前提:必须启用ECC Correction。
- 功能:持续后台扫描内存,主动修复单比特错误。
- 优势:防止错误累积导致不可修复的双比特错误。
- 4)ECC Scrub Bits(擦洗地址位宽)
- 定义:用于擦洗操作的内存地址位数。
- 默认值(0):自动使用当前内存配置支持的最大位宽。
- 5)ECC Scrub Period(擦洗周期)
- 单位:256个内存时钟周期。
- 示例:值为2表示每512个周期(2×256)执行一次擦洗读取。
- 6)Initialize Memory Using ECC(ECC初始化内存)
- 前提:必须启用ECC Correction。
- 功能:在初始化时用有效ECC值填充整个内存阵列。
- 用途:确保未写入区域也有合法ECC数据。
- 7)Write Data Mask(写数据掩码)
- 兼容性:与ECC Correction/Bypass互斥。
- 功能:允许部分写入(掩码指定哪些字节被写入)。
3. HBM 知识
3.1 交叉开关
分段交叉开关可能会成为瓶颈,影响应用程序的实际 HBM 性能。
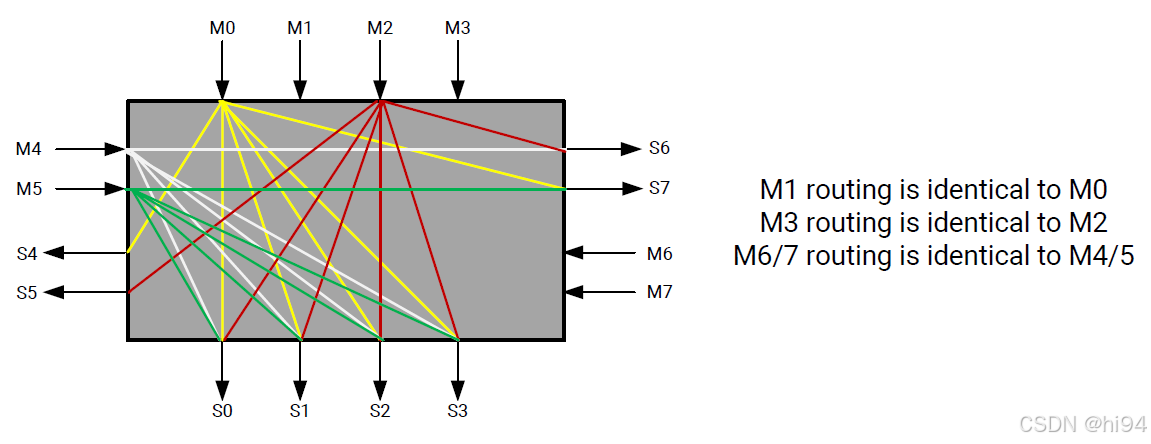
如上图所示:
最快的连接是从 AXI 通道到对齐的伪通道(PC)内存地址,M0→S0(0-256 MB),M1→S1(256-512 MB),等等。这将限制设计只能访问 32 个独立的 256 MB 段 PC。为了性能权衡,分段交叉开关允许任何 AXI 主设备访问 8 GB HBM 范围内的任何地址。这与 DDR 配置不同,如果 AXI 主设备端口连接到 DDR0,那么只能访问 DDR0 内的地址。对于 HBM,如果地址不在对齐的伪通道(PC)内,那么它将通过上述的本地 4x4 连接性或通过 L/R 连接上的另一个 4x4 开关来穿越分段交叉开关到达正确的 PC。当你指示工具将一个主 AXI 接口连接到多个 PC 时,有一个内部机制使用特定内核主设备的内存规范。
性能会受到两个因素的影响:
- 开关中的每个连接具有相同的带宽。
- 从 4x4 开关到另一个 4x4 开关的穿越会增加延迟。
3.2 Throughput
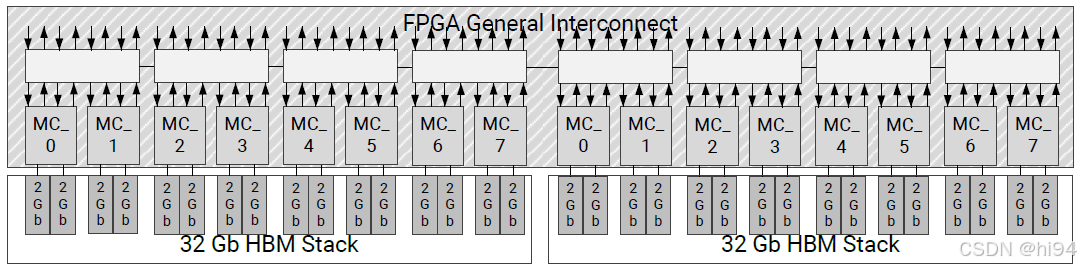
1)从内存控制器的角度
- 每个 HBM stack 包含八个 MC,每个 MC 包含两个 PC(Pseudo Channels)。
- PC 位宽为 64 bit,且数据信号以 IP 配置中 HBM 时钟频率的双倍速率切换(DDR)。
- 若配置的时钟频率为 900 MHz,则 HBM stack 的切换速率可通过以下公式计算:
( 64 bit / PC ) × ( 2 ch / MC ) × ( 8 MC ) × 900 MHz × 2 = 1,843,200 Mb/s = 230,400 MB/s
对于双堆栈器件,该值翻倍至 460,800 MB/s。
2)从用户逻辑角度
- HBM 的每个 AXI 端口宽度为 256 位,每个 PC 对应一个 AXI 端口。
- 当 HBM 运行于 900 MHz,用户逻辑 AXI 时钟为 450 MHz 以实现速率匹配。
- 计算公式如下:
( 256 bit / AXI ) × ( 2 ch / MC ) × ( 8 MC ) × 450 MHz = 1,843,200 Mb/s = 230,400 MB/s
对于配置 32 个 AXI 端口的双堆栈器件,该值翻倍至 460,800 MB/s。
3)效率损耗
上述为 HBM 理论 Throughput,但与所有传统 DDR 器件类似,HBM stack 中的存储阵列需通过刷新维持数据完整性:
- HBM 的基础刷新间隔(tREFI)为 3.9 us。
- 4H 器件的刷新命令周期(tRFC)为 260 ns,8H 器件则为 350 ns。
- 考虑刷新开销后,4H 器件的峰值效率将损失约 7%,8H 器件约损失 9%。
与传统 DDR 存储器相同,tREFI 会随温度升高而缩短:
- 当堆栈温度上升时,刷新操作会占用更多 HBM 接口时间(效率降低)。
- 0°C 至 85°C 时,tREFI 为 3.9 us。
- 85°C 至 95°C 时,tREFI 将缩减至 1.95 us。
PS:4H Device (4 GB per Stack),8H Device (8 GB per Stack)
3.3 Global Addressing
访问方式上,有 2 种方式,global 模式和非 global 模式,在非 global 模式下,每个用户通过伪随机通道只能访问对应的 256MB 空间;global 模式下,每个伪随机通道可以访问整个 HBM 空间。
性能上,每个 AXI 用户接口(伪随机通道)的数据位宽为 256bit,最高工作频率为 450M,所以每个用户接口的最大性能为:256bit*450M = 14400MB/s。在 global 模式下,通过一个伪随机通道,访问其他的控制器对应的存储空间,性能会降低,具体见 PG276 上的说明。
根据xilinx提供的文档 pg276,HBM 单个 stack 的理论最大性能为:(256 bits per AXI port) x (2 ports per memory controller) x (8 channels) x 450 MHz = 230400MB/s,整体性能为 460800MB/s。
3.4 时钟
必须提供给HBM核心的三种时钟类型包括:
- HBM_REF_CLK_x:驱动锁相环(PLL),生成八个内存控制器的时钟以及HBM堆栈的内存时钟。每个 HBM 堆栈对应一个 PLL。此时钟必须源自 MMCM/BUFG 或 BUFG,也可由其他时钟的级联时钟源派生,但其原始时钟必须来自与 HBM 同一 SLR 内的 GCIO 引脚。驱动 GCIO 的时钟发生器抖动需小于3皮秒均方根值(3 pS RMS)。
- APB_x_PCLK:用于 APB 寄存器端口访问,可与其他时钟异步。每个 HBM 堆栈有一个 APB 时钟端口,可源自级联时钟源、MMCM 或 GCIO 引脚。
- AXI_xx_ACLK:每个 AXI 端口的时钟,可与其他时钟异步,时钟源可以是级联时钟源、MMCM 或 GCIO 引脚。
全局路由交换机无独立时钟输入,而是共享某个 AXI_xx_ACLK 时钟。软件会自动选择用户所选内存控制器中位于中间的一个时钟(通过查看 hbm_0.v 文件中的 CLK_SEL_xx 参数可确认,仅一个参数标记为 TRUE)。
为实现最佳性能,所选的 AXI 时钟应为所有 AXI 端口时钟中频率最高的一个。
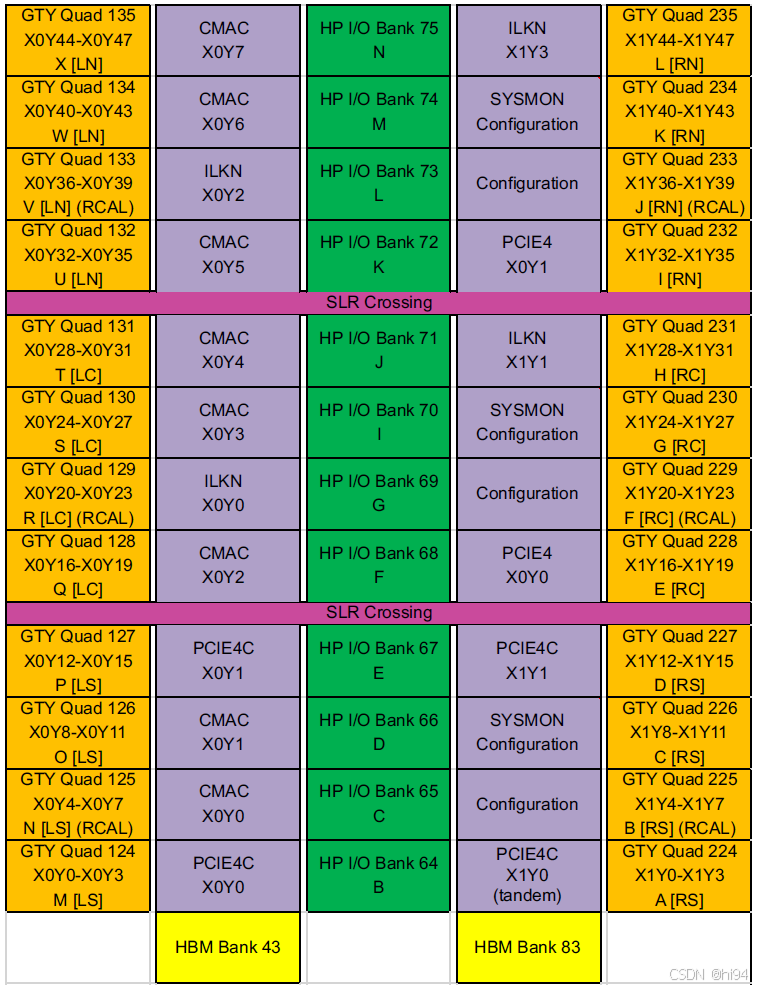
3.5 Packaging and Pinouts
《UG575,UltraScale and UltraScale+ FPGAs Packaging and Pinouts》
4. 总结
以上是使用 HBM 的基本操作,后续补充:
- HBM 带宽监控
- DDR 性能优化



)





)


》)






