M²IV: Towards Efficient and Fine-grained Multimodal In Context Learning in Large Vision-Language Models
COLM 2025
why
新兴的研究方向:上下文学习(ICL)的效果“向量化”,其核心思想是用transformer内部的向量来替代演示示例。然而,之前的方法(如Task Vector, Function Vector, I²CL等)虽然在一些简单文本任务上取得了成功,但在处理复杂的多模态任务(如视觉问答VQA)时,普遍存在以下深层次的局限性:
-
无法有效实现跨模态交互:
- 现有的方法,如从最终Token的隐藏状态提取向量(Hendel et al., 2023),或平均关键注意力头的输出来计算向量(Todd et al., 2024),在本质上是一种“静态”的提取-注入模式。例如:对于同一类任务(比如VQA),无论新的查询QnewQ_{new}Qnew问的是什么,注入的都是同一个VtaskV_{task}Vtask
- 这种模式(最终Token提取向量)对于纯文本任务(如国家-首都映射)尚可(a),但对于VQA图像和文本深度融合的复杂任务则效果很差(b)。
- 最终token向量->上下文效果:自回归语言模型,逐词预测下一个词,当处理完一个完整的句子或段落后,最后一个Token的隐藏状态hlasth_{\text{last}}hlast聚合和编码了整个输入序列的全部信息。它可以被看作是模型对整个句子的“最终思考总结”。
![![[image-164.png|523x250]]](https://i-blog.csdnimg.cn/direct/27e6887bbc044fc781fc369af8f464f8.png)
-
忽略了模型内部不同计算模块的功能差异:
-
此前的研究普遍将Transformer层视为一个“黑箱”,或者只关注其最终输出(LIVE)。它们没有充分利用一个关键的洞察:在一个Transformer层中,多头注意力(MHA)和多层感知器(MLP)扮演着截然不同的角色。MHA更侧重于全局信息整合与高级语义关联,而MLP则负责进行更精细的特征提炼与非线性变换。
![* ![[image-177.png|380x206]]](https://i-blog.csdnimg.cn/direct/a5ef989a83be43ce9d85a2c76d3c4bbe.png)
-
因此,用一个单一的向量或一种单一的注入策略去同等地影响这两个功能迥异的模块,是一种粗粒度的干预,限制了模型引导的精度和效果。
-
-
信息蒸馏不足,导致性能随复杂度增加而快速下降:
- 由于上述两个理论上的粗糙,现有方法实际训练中,从演示示例中“蒸馏”出的偏移向量不够精细和全面。Peng et al. (2024) 提出的LIVE方法虽然开始尝试通过训练来优化向量,但论文指出,它仍然忽略了对精细化语义的蒸馏。
- 这导致了一个普遍现象:当任务的复杂性增加时(例如,需要更深层次的逻辑推理或对噪声更大的视觉信息进行处理),这些方法的性能会迅速下降,甚至不如传统ICL。
what
为了解决上述问题,论文提出了一个名为 M²IV (Multimodal In-context Vectors) 的框架。
M²IV的工作:进一步细化了任务向量表示,提升多模态上下文的引导能力。
这个框架主要包含两个部分:
-
M²IV 向量:这是一种经过特殊训练的、高信息密度的向量。它不是输入数据,而是一种模型的“行为引导器”。在模型进行推理时,这些向量被直接“注入”到模型内部的网络层中,像一个“插件”一样,精确地调整模型的思考和计算过程,使其按照特定任务的逻辑来运作。这种注入是双分支的,分别针对transformer层中负责不同功能的多头注意力(MHA)和多层感知器(MLP)模块,以实现更精细的控制。
![![[image-167.png|1000x352]]](https://i-blog.csdnimg.cn/direct/78e5ee3d885847cbb33c9ecc9e69218d.png)
-
VLibrary (向量库):这是一个配套的“能力库”。研究者可以为各种不同的任务(如视觉问答、安全审核、代码生成等)预先训练好各自的M²IV向量,并将它们存储在这个库中。当需要执行某个特定任务时,只需从库中取出对应的向量并插入,就可增强模型相关能力。
how
3.1 理论推导
在设计M²IV之前,必须从数学上证明其核心思想——分离并向量化上下文效应——是可行的。论文通过两个定理的推导来完成这一论证。
1. Transformer中的残差流
![![[image-162.png|212x258]]](https://i-blog.csdnimg.cn/direct/63a11c4ef2724b43a9ed39785ab98c62.png)
信息在标准Transformer层中是如何流动的。其核心是残差流,模型内部的主要信息流动。
在一个网络层lll中,对于输入序列的第iii个位置:
- MHA计算: 首先,该层的多头注意力(MHA)模块以来自上一层的残差流hl−1ih_{l-1}^ihl−1i作为输入,计算出注意力输出alia_l^iali。
- ali=MHA(hl−1i;θl)a_l^i = MHA(h_{l-1}^i; θ_l)ali=MHA(hl−1i;θl) (公式2)
- MLP计算: 接着,将原始的残差流hl−1ih_{l-1}^ihl−1i与MHA的输出alia_l^iali相加,然后将结果送入多层感知器(MLP)模块,得到MLP的输出mlim_l^imli。
- mli=MLP(hl−1i+ali;Wl)m_l^i = MLP(h_{l-1}^i + a_l^i; W_l)mli=MLP(hl−1i+ali;Wl) (公式3)
- 更新残差流: 最后,将MHA的输出alia_l^iali和MLP的输出mlim_l^imli同时加回到原始的残差流hl−1ih_{l-1}^ihl−1i上,形成该层最终的输出hlih_l^ihli,它将作为下一层的输入。
- hli=hl−1i+ali+mlih_l^i = h_{l-1}^i + a_l^i + m_l^ihli=hl−1i+ali+mli (公式4)
这个“加法”结构是关键。后续的理论证明,这个加法过程中的alia_l^iali和mlim_l^imli(当有上下文时)是可以被分解的。
2. MHA计算可分离性
定理1: Attn(hi,[CTQT]T,[CTQT]T)=ζi⋅Ψ(hi,C,C)+ηi⋅Attn(hi,Q,Q)Attn(h^i, [Cᵀ Qᵀ]ᵀ, [Cᵀ Qᵀ]ᵀ) = ζ^i ⋅ Ψ(h^i, C, C) + η^i ⋅ Attn(h^i, Q, Q)Attn(hi,[CTQT]T,[CTQT]T)=ζi⋅Ψ(hi,C,C)+ηi⋅Attn(hi,Q,Q)
意义:自注意力机制分解为两部分:仅查询组件 Attn(hi,Q,Q)(h^{i}, Q, Q)(hi,Q,Q)和上下文增强组件Ψ(hi,C,C)\Psi(h^{i}, C, C)Ψ(hi,C,C)。这种分解突出了 MHA 在动态分配注意力方面的作用,在 ICL 中整合查询特定的焦点和来自演示的上下文见解。
![![[image-165.png|623x532]]](https://i-blog.csdnimg.cn/direct/5ebac37a574b4690ba15e4356115e01a.png)
- Step 1: 写出注意力机制的初始公式 (公式14)
对于一个查询向量hih^ihi和由上下文CCC与查询QQQ拼接而成的键值对,其注意力机制的计算如下:
Attn(hi,[CTQT]T,[CTQT]T)=softmax([dM−1/2hiCT,dM−1/2hiQT])[CQ]Attn(h^i, [Cᵀ Qᵀ]ᵀ, [Cᵀ Qᵀ]ᵀ) = softmax([d_M^{-1/2}h^iCᵀ, d_M^{-1/2}h^iQᵀ]) \begin{bmatrix} C \\ Q \end{bmatrix}Attn(hi,[CTQT]T,[CTQT]T)=softmax([dM−1/2hiCT,dM−1/2hiQT])[CQ]
这里,softmax(⋅)softmax(⋅)softmax(⋅)函数将输入归一化为概率分布,dM−1/2d_M^{-1/2}dM−1/2是用于稳定训练的缩放因子。 - Step 2: 展开计算 (公式15)
为了展开计算,我们首先定义两个和项,它们分别代表了对上下文CCC与查询QQQ部分的指数化注意力分数之和:
sC=∑j=1Cexp(dM−1/2hiCjT)s_C = \sum_{j=1}^{C} exp(d_M^{-1/2}h^iC_jᵀ)sC=∑j=1Cexp(dM−1/2hiCjT)
sQ=∑j=1Iexp(dM−1/2hiQjT)s_Q = \sum_{j=1}^{I} exp(d_M^{-1/2}h^iQ_jᵀ)sQ=∑j=1Iexp(dM−1/2hiQjT)
其中,CjC_jCj和QjQ_jQj分别是CCC和QQQ矩阵的第j行。 - Step 3: 注意力输出的分解 (公式16)
基于上述定义,注意力机制的输出可以被写为:
Attn(hi,[CTQT]T,[CTQT]T)=(sC+sQ)−1(exp(dM−1/2hiCT)C+exp(dM−1/2hiQT)Q)Attn(h^i, [Cᵀ Qᵀ]ᵀ, [Cᵀ Qᵀ]ᵀ) = (s_C + s_Q)^{-1} (exp(d_M^{-1/2}h^iCᵀ)C + exp(d_M^{-1/2}h^iQᵀ)Q)Attn(hi,[CTQT]T,[CTQT]T)=(sC+sQ)−1(exp(dM−1/2hiCT)C+exp(dM−1/2hiQT)Q)
通过引入sCs_CsC和sQs_QsQ,我们可以将上式重新组合和分解,得到一个更清晰的结构:
=sC(sC+sQ)−1softmax(dM−1/2hiCT)C+sQ(sC+sQ)−1softmax(dM−1/2hiQT)Q= s_C(s_C + s_Q)^{-1} softmax(d_M^{-1/2}h^iCᵀ)C + s_Q(s_C + s_Q)^{-1} softmax(d_M^{-1/2}h^iQᵀ)Q=sC(sC+sQ)−1softmax(dM−1/2hiCT)C+sQ(sC+sQ)−1softmax(dM−1/2hiQT)Q - Step 4: 最终定义与证明完成 (公式17, 18)
根据上述分析,我们可以定义函数ΨΨΨ以及系数ζiζ^iζi和ηiη^iηi如下:- Ψ(ρq,ρk,ρv):=softmax(dM−1/2ρqρkT)ρv,∀(ρq,ρk,ρv)Ψ(ρ_q, ρ_k, ρ_v) := softmax(d_M^{-1/2}ρ_qρ_kᵀ)ρ_v, \quad ∀(ρ_q, ρ_k, ρ_v)Ψ(ρq,ρk,ρv):=softmax(dM−1/2ρqρkT)ρv,∀(ρq,ρk,ρv) (公式17)
- ζi:=sC(sC+sQ)−1,ηi:=sQ(sC+sQ)−1ζ^i := s_C(s_C + s_Q)^{-1}, \quad η^i := s_Q(s_C + s_Q)^{-1}ζi:=sC(sC+sQ)−1,ηi:=sQ(sC+sQ)−1 (公式18)
将这些定义代入分解后的表达式,我们就得到了Theorem 1所要证明的结论。至此,定理证明完毕。
3. MLP计算可分离性
定理2:MLP(aC,Qi)=ζi⋅ψW(aCi)+ηi⋅MLP(aQi)MLP(a_{C,Q}^i) = ζ^i ⋅ ψ_W(a_C^i) + η^i ⋅ MLP(a_Q^i)MLP(aC,Qi)=ζi⋅ψW(aCi)+ηi⋅MLP(aQi)
意义:定理 2 表明,MLP 机制分解为两部分:仅查询组件 MLP(aQi)(a_{Q}^{i})(aQi)和上下文增强组件ψW(aCi)\psi_{W}(a_{C}^{i})ψW(aCi)。通过加权组合,MLP 从查询和上下文中提取并保留关键特征,使 LVLM 能够在 ICL 中传达更聚合细致的表征。

- 前提 (公式19): 基于已经证明的Theorem 1,我们知道存在两个实数系数ζiζ^iζi和ηiη^iηi,使得MHA的输出满足以下关系:
aC,Qi=ζi⋅aCi+ηi⋅aQia_{C,Q}^i = ζ^i ⋅ a_C^i + η^i ⋅ a_Q^iaC,Qi=ζi⋅aCi+ηi⋅aQi
这里,aC,Qia_{C,Q}^iaC,Qi是同时考虑上下文和查询时的MHA输出,aCia_C^iaCi和aQia_Q^iaQi分别是只考虑上下文和只考虑查询时的MHA输出。 - 矩阵乘法 (公式20):
我们将等式(19)的两边同时在右侧乘以MLP层的权重矩阵W,假设MLP层就是一个简单的线性变换,其作用就是将输入向量xxx乘以一个权重矩阵WWW
得到以下等式:
aC,QiW=ζi⋅aCiW+ηi⋅aQiWa_{C,Q}^iW = ζ^i ⋅ a_C^iW + η^i ⋅ a_Q^iWaC,QiW=ζi⋅aCiW+ηi⋅aQiW - 定义新函数与最终证明 (公式21):
我们定义一个新函数ψW(x):=xWψ_W(x) := xWψW(x):=xW。通过这个定义,我们可以将等式(20)重写为:
MLP(aC,Qi)=ζi⋅ψW(aCi)+ηi⋅MLP(aQi)MLP(a_{C,Q}^i) = ζ^i ⋅ ψ_W(a_C^i) + η^i ⋅ MLP(a_Q^i)MLP(aC,Qi)=ζi⋅ψW(aCi)+ηi⋅MLP(aQi)
这正是Theorem 2所要证明的形式。至此,定理证明完毕。
4. 最终ICL表示
基于上述分析,本文提出 M²IV 用于多模态 ICL 的细粒度表征。M²IV 为 LVLM 每一层transformer的 MHA 和 MLP 分支分配一个可学习的向量和一个权重因子。具体来说,我们定义:
MHA:Va={v1a,v2a,…,vLa},αa={α1a,α2a,…,αLa};(7)MHA: V^{a}=\left\{v_{1}^{a}, v_{2}^{a}, \ldots, v_{L}^{a}\right\}, \alpha^{a}=\left\{\alpha_{1}^{a}, \alpha_{2}^{a}, \ldots, \alpha_{L}^{a}\right\} ; \quad (7)MHA:Va={v1a,v2a,…,vLa},αa={α1a,α2a,…,αLa};(7)
MLP:Vm={v1m,v2m,…,vLm},αm={α1m,α2m,…,αLm},(8)MLP: V^{m}=\left\{v_{1}^{m}, v_{2}^{m}, \ldots, v_{L}^{m}\right\}, \alpha^{m}=\left\{\alpha_{1}^{m}, \alpha_{2}^{m}, \ldots, \alpha_{L}^{m}\right\}, \quad (8)MLP:Vm={v1m,v2m,…,vLm},αm={α1m,α2m,…,αLm},(8)
其中vla,vlm∈RdMv_{l}^{a}, v_{l}^{m} \in \mathbb{R}^{d_{M}}vla,vlm∈RdM是可学习向量,αla,αlm∈R\alpha_{l}^{a}, \alpha_{l}^{m} \in \mathbb{R}αla,αlm∈R是相应的权重因子。M²IV 的完整集合表示为Θ={Va,αa,Vm,αm}\Theta=\left\{V^{a}, \alpha^{a}, V^{m}, \alpha^{m}\right\}Θ={Va,αa,Vm,αm},可以直接注入 LVLM 的残差流中。更新后的残差流递归定义为对于l=1,…,Ll=1, \ldots, Ll=1,…,L和i=1,…,Ii=1, \ldots, Ii=1,…,I:
hli=hl−1i+(ali+αla⋅vla)+(mli+αlm⋅vlm)h_{l}^{i}=h_{l-1}^{i}+\left(a_{l}^{i}+\alpha_{l}^{a} \cdot v_{l}^{a}\right)+\left(m_{l}^{i}+\alpha_{l}^{m} \cdot v_{l}^{m}\right)hli=hl−1i+(ali+αla⋅vla)+(mli+αlm⋅vlm)
3.2 训练实现
M²IV的训练通过构建在一个自蒸馏框架,该框架由一个教师模型、一个学生模型(两个模型相中)以及一组损失函数共同构成。
![![[image-167.png|1000x352]]](https://i-blog.csdnimg.cn/direct/7f0546123a254046a2016ca5fd373e2a.png)
1. 自蒸馏框架:教师与学生模型
- 教师模型:
- 输入: 接收完整的查询样本QQQ和nnn个演示示例CCC。执行传统的Vanilla ICL。
- 作用: 其输出的概率分布PM(C,Q)P_M(C, Q)PM(C,Q)被视为“软标签”,是学生模型需要模仿的目标。
- 学生模型:
- 输入: 只接收一个查询样本QQQ。
- 工作机制: 在其内部的每一层,通过公式 hli=hl−1i+(ali+αla⋅vla)+(mli+αlm⋅vlm)h_l^i = h_{l-1}^i + (a_l^i + α_l^a ⋅ v_l^a) + (m_l^i + α_l^m ⋅ v_l^m)hli=hl−1i+(ali+αla⋅vla)+(mli+αlm⋅vlm)进行向量注入。
- 目标: 通过不断优化M²IV向量ΘΘΘ,使其输出PM(Q;Θ)P_M(Q; Θ)PM(Q;Θ)能无限逼近教师模型的输出PM(C,Q)P_M(C, Q)PM(C,Q)。
2. 损失函数
蒸馏训练由三个损失函数共同驱动,它们从不同维度对学生模型进行约束。
- 损失函数: L=λmim⋅Lmim+λsyn⋅Lsyn+λsup⋅LsupL = λ_{mim} ⋅ L_{mim} + λ_{syn} ⋅ L_{syn} + λ_{sup} ⋅ L_{sup}L=λmim⋅Lmim+λsyn⋅Lsyn+λsup⋅Lsup
a. 模仿损失
- 公式: Lmim=T2⋅DKL(PMT(C,Q)∥PM(Q;Θ)),C∈DC,Q∈DQ\mathcal{L}_{mim }=\mathcal{T}^{2} \cdot \mathbb{D}_{K L}\left(P_{\mathcal{M}}^{\mathcal{T}}(C, Q) \| P_{\mathcal{M}}(Q ; \Theta)\right), C \in \mathcal{D}_{C}, Q \in \mathcal{D}_{Q}Lmim=T2⋅DKL(PMT(C,Q)∥PM(Q;Θ)),C∈DC,Q∈DQ
- 含义详解: 减小教师和学生模型的输出分布
- DKLD_{KL}DKL: KL散度,衡量两个概率分布的差异。目标是最小化这个差异。
- PM(C,Q)P_M(C, Q)PM(C,Q): 教师模型的输出分布。
- PM(Q;Θ)P_M(Q; Θ)PM(Q;Θ): 学生模型的输出分布。
- TTT: 温度系数。对PM(C,Q)P_{M}(C, Q)PM(C,Q)做温度缩放,以促进平滑的知识蒸馏并减轻过度自信,是知识蒸馏的标准技巧。
b. 协同损失
- 公式: Lsyn=∑l=1L(∑i=j(1−Mijl)2+γ⋅∑i≠jMijl2)\mathcal{L}_{syn }=\sum_{l=1}^{L}\left(\sum_{i=j}\left(1-M_{i j}^{l}\right)^{2}+\gamma \cdot \sum_{i \neq j} M_{i j}^{l^{2}}\right)Lsyn=∑l=1L(∑i=j(1−Mijl)2+γ⋅∑i=jMijl2)
- 含义详解: 增强 MHA 和 MLP 分支之间的一致性和互补性
- 其中Ml=(Zla(Θ))⊤Zlm(Θ)∈RdM×dMM^{l}=(Z_{l}^{a}(\Theta))^{\top} Z_{l}^{m}(\Theta) \in \mathbb{R}^{d_{M} \times d_{M}}Ml=(Zla(Θ))⊤Zlm(Θ)∈RdM×dM是跨视图相关矩阵,由MHA和MLP分支的输出计算而来。
- 对角线项 MiiM_{ii}Mii: 迫使MiiM_{ii}Mii趋近于1,代表MHA和MLP两个分支在对应维度上必须目标一致、高度协同。
- 非对角线项 MijM_{ij}Mij: 迫使MijM_{ij}Mij趋近于0,代表不同维度之间应该是正交的、不相关的,鼓励两个分支学习功能互补,信息不冗余。
- γγγ: 平衡超参数,权衡“协同”与“互补”的重要性。
c. 监督损失
- 公式: Lsup=−∑t=1TlogPM(At∣Q,A:<t;Θ),Q∈DQ\mathcal{L}_{sup }=-\sum_{t=1}^{T} \log P_{\mathcal{M}}\left(A_{t} | Q, A_{:<t} ; \Theta\right), Q \in \mathcal{D}_{Q}Lsup=−∑t=1TlogPM(At∣Q,A:<t;Θ),Q∈DQ
- 含义详解: 标准的交叉熵损失,微调必备,使输出逼近真实的正确答案。
- AtA_tAt: 真实的正确答案token。
- 目标: 确保学生模型学习模仿绝对正确的答案,不只是模仿教师输出。
权重设置: 论文在Table 7 中给出了针对每个测试数据集的详细超参数设置,包括学习率以及所有损失函数的权重λmim,λsyn,λsupλ_{mim}, λ_{syn}, λ_{sup}λmim,λsyn,λsup和协同损失内部的γγγ。较高的λmimλ_{mim}λmim和λsynλ_{syn}λsyn表明,在训练中,学习教师的思考模式和保证内部组件的协同工作,比学习真实的正确回答更重要
权重如何得到:用网格搜索或随机搜索,试验出来
![![[截屏2025-07-23 23.07.54.png]]](https://i-blog.csdnimg.cn/direct/e9e0a334704c407b93b3f5ed6bd337c1.png)
3.3 实验
| 模型 | LLM主干 (大脑) | 连接模块 (桥梁) | 上下文窗口 (短期记忆) | 核心特点 |
|---|---|---|---|---|
| OpenFlamingov2 | MPT-7B | Perceiver Resampler | 2048 | 高效的信息压缩,非LLaMA家族 |
| IDEFICS2 | Mistral-7B | MLP + 序列化 | 32768 (32K) | 极强的长上下文能力,灵活的图文交错处理 |
| LLaVa-Next | Vicuna-7B | 简单的MLP | 4096 | 卓越的对话与指令遵循能力,极简的连接设计 |
1. 性能对比
- 实验设计:
- 模型: 三种主流LVLM:OpenFlamingov2(9B), IDEFICS2(8B) , LLaVa-Next(7B),这些模型在其 LLM 主干、连接模块和上下文窗口方面有所不同。
- 训练方法:采用随机抽样作为检索策略R,将样本数量shot固定为 16,使用 AdamW 作为优化器。
- 基准数据集: 使用了7个覆盖不同难度和场景的VQA及ICL基准,如VQAv2, GQA, CVQA, VL-ICL bench等。
- 对比方法:
- Zero-shot: 完全不给任何示例。
- Vanilla ICL (16-shot): 论文的主要对比基线,代表传统ICL方法。
- 其他向量化方法: 包括非训练的TV, FV, ICV, I²CL和训练的LIVE(关键同类比较)
- 关键结论:
-
1.1 平均性能对比
- 数据解读: 此表展示了所有方法在三个LVLM上跨七个基准的平均准确率。M²IV的得分在所有任务上均显著领先。
- 结论1: M²IV比 16-shot 常规 ICL 平均高出 3.74%。
- 结论2: 在 LIVE 落后的基准数据集上分别超过 LIVE 3.52%、4.11% 和 3.72%。
- 超长shot:传统ICL出现遗忘问题,但M²IV克服遗忘,呈现出持续且显著的增长。
![![[image-178.png|741x292]]](https://i-blog.csdnimg.cn/direct/d3e2b390b9154d31acaa6a8e7730d31a.png)
-
1.2 分模型性能对比
- 数据解读: 此表将表1的结果拆分到每个具体的LVLM上。数据显示,M²IV在总共21组(3个模型 × 7个基准)实验中,有18组取得了第一名的成绩。(2个第二1个第三)
- 关键结论: M²IV的优越性不依赖于特定的模型架构。无论是在OpenFlamingo、IDEFICS2还是LLaVa-Next上,它都能稳定地带来性能提升,证明了其方法的普适性。
![![[image-171.png|698x527]]](https://i-blog.csdnimg.cn/direct/9273a881086c4877b5d436482381f4be.png)
-
2. 效率对比实验
- 关键实验:
-
2.1 推理开销对比
- 数据解读: 该图比较了不同方法的计算量(FLOPs)和推理时间。M²IV的计算开销几乎与Zero-shot设置完全相同(仅为Zero-shot的0.95x)。相比之下,16-shot ICL的计算量是其17.25倍,推理时间是其8.57倍。
- 关键结论: M²IV几乎完全消除了ICL在推理阶段的效率瓶颈,使其应用成本大幅降低,恢复到了接近零样本的水平。
![![[image-172.png|548x332]]](https://i-blog.csdnimg.cn/direct/ef915cd8e9b84a50926adfe2be78eded.png)
-
2.2 总体成本效益分析
- 数据解读: 该图比较了两种方法的总GPU小时消耗。红色条是Vanilla ICL进行所有评估所需的总推理时间。橙色和黄色是M²IV的一次性训练时间加上所有评估的推理时间。
- 关键结论: M²IV的总成本(训练+推理)低于Vanilla ICL仅推理的成本。这意味着M²IV在推理端节省的巨大开销,完全可以抵消甚至超过其一次性的训练成本。在需要被反复调用的实际应用场景中,M²IV的成本效益优势会随着使用次数的增加而愈发明显。
![![[image-173.png|526x312]]](https://i-blog.csdnimg.cn/direct/d31ef89fc4ea44a9b575e561283180ec.png)
-
3. 消融实验
- 关键结论:
- 不同组件的贡献
- 数据解读: 该表展示了移除M²IV不同组件(如数据处理步骤或损失函数)后的性能变化。其中,abcd是训练集的检索策略,主要关注(e), (f), (g)三行。
- 关键结论: 协同损失(LsynL_{syn}Lsyn)是M²IV的灵魂。
- 移除模仿损失(LmimL_{mim}Lmim)或监督损失(LsupL_{sup}Lsup)后,性能有所下降,但尚可接受。
- 然而,一旦移除协同损失(LsynL_{syn}Lsyn),模型性能出现了断崖式下跌,平均准确率暴跌了13.00%
- 这个结果证明,强制MHA和MLP两个分支协同工作(对角线最大化)且分工互补(非对角线最小化)的设计,是M²I![[image-170.png]]V能够实现精细化语义蒸馏、超越所有同类方法的关键所在。
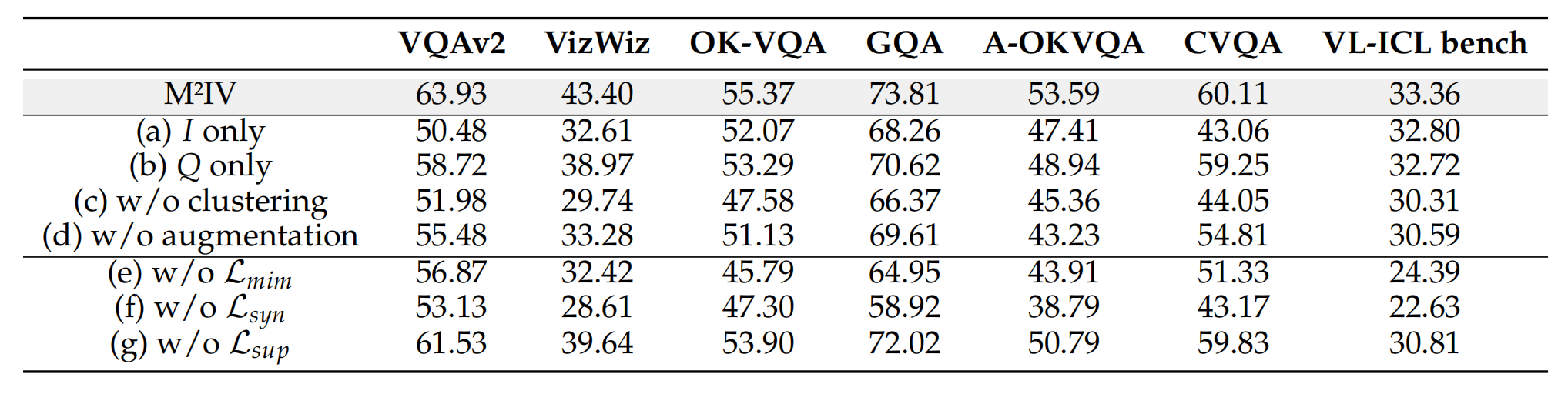
- 不同组件的贡献
4. 鲁棒性与泛化能力实验
- 关键证据与结论:
-
4.1 对不同Shot数的鲁棒性
- 数据解读: 该图展示了在不同shot数(2, 4, …, 256)下,M²IV相比基线的性能提升值(GAP)。
- 关键结论: M²IV在所有shot数下都表现更优(GAP始终为正)。特别是在2-shot和4-shot的少样本场景下,性能提升最为显著。这表明M²IV能更有效地从极少量的信息中提炼出任务的本质,适合现实世界数据稀疏的场景。
![![[image-174.png|528x342]]](https://i-blog.csdnimg.cn/direct/da8ec4ddbd9e42bdaf8fed536163e69e.png)
-
4.2 对不同检索策略的鲁棒性
- 数据解读: 该图展示了在使用不同检索方法(如随机采样RS、图像相似度I2I)为Vanilla ICL挑选演示示例时,M²IV带来的性能增益(浅色部分)。
- 关键结论: M²IV在所有策略下都带来了显著提升,并且在最差的策略(如I2I,橙色)下,其性能增益是最大的。这说明M²IV具有强大的纠错和抗干扰能力。即使给它的“教师”(Vanilla ICL)提供的是有偏差或有误导性的示例,M²IV的训练过程依然能从中过滤噪声,学习到正确的任务逻辑。
![![[image-175.png|495x335]]](https://i-blog.csdnimg.cn/direct/f145a2ac479a47e4834364b2c6c8758f.png)
-
5. 灵活性与应用潜力实验
- 关键证据与结论:
- 层级化精确注入
- 数据解读: 在一个需要关注图像细节的VQA任务中,研究者们尝试将M²IV只注入到模型的部分层。结果发现,只注入模型的前10层(通常负责提取基础视觉特征的浅层网络)时,性能甚至超过了对所有层进行注入。
- 关键结论: 证明了M²IV是一个可以精确引导的工具。我们可以根据任务需求,选择性地增强模型在特定处理阶段(如早期视觉感知、中期语义融合或晚期逻辑推理)的能力。这极大地拓展了M²IV的应用想象空间。
![![[image-176.png|635x241]]](https://i-blog.csdnimg.cn/direct/de2dc9ccaf5449d5bc6c857ed5bef5d2.png)
- 层级化精确注入












和Pycharm)

)



)
