Transformer:颠覆NLP的自注意力革命
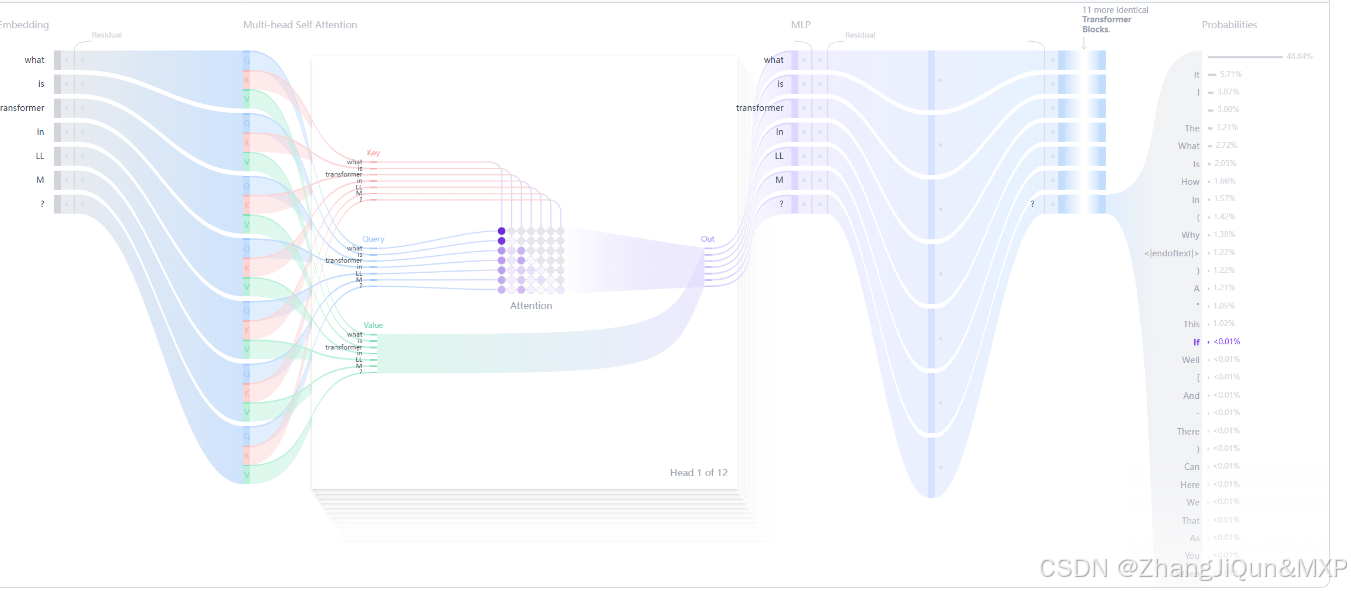
Transformer是自然语言处理领域中极具影响力的深度学习模型架构,以下是对其的详细介绍:
- 提出背景与应用:2017年,Vaswani等人在《Attention Is All You Need》论文中首次提出Transformer架构,它主要用于处理序列到序列的任务,如机器翻译、文本生成等。
- 核心原理:文本生成的Transformer模型原理是“预测下一个词”。模型通过自注意力机制处理用户给定的文本(prompt),从而预测下一个最有可能出现的词。自注意力机制是Transformer的核心创新,它能让模型处理整个序列,更有效地捕捉长距离依赖关系,这是相较于之前的RNN架构的重大优势。
- 模型结构
- 嵌入层(Embedding):将文本输入分割成词元(token),可以是单词或子词,然后将这些词元转换成能够捕捉词语语义含义的数值向量,即嵌入(embeddings)。
- Transformer块:是模型处理和转换输入数据的基本构建单元,每个块包含注意力机制和多层感知器(MLP)层。注意







和Pycharm)

)



)

)



