在之前的博客中,我们已经探讨了进程创建、终止和等待的相关知识。今天,我们将继续深入学习进程控制中的另一个重要概念——进程替换。
回顾之前的代码示例,我们使用fork()创建子进程时,子进程会复制父进程的代码和数据(写入时触发写时拷贝机制),然后父子进程各自执行不同的代码段。这种机制可能还不太直观,在网络编程部分我们会进一步体会其实际应用场景——父进程负责监听客户端请求,子进程则处理具体请求。这个内容我们将在后续博客中详细讨论。
今天我们重点介绍的是:在fork()创建子进程后,子进程通过调用exec函数来执行另一个程序。当exec函数被调用时,该进程的用户空间代码和数据会被新程序完全替换,并从新程序的启动例程开始执行。这就是所谓的进程替换机制。
单进程版本
![]()
![]()
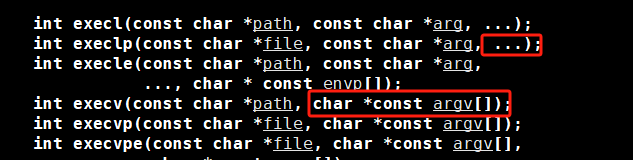
在这几个系统调用接口中函数参数列表中的三个点(...)表示可变参数,允许函数接受不确定数量的参数。这种机制通常用于需要处理不同数量输入的函数,我们可以类比scanf和printf理解一下
现在我们就来使用一下这些函数,看看这些函数的功能以及使用规则。
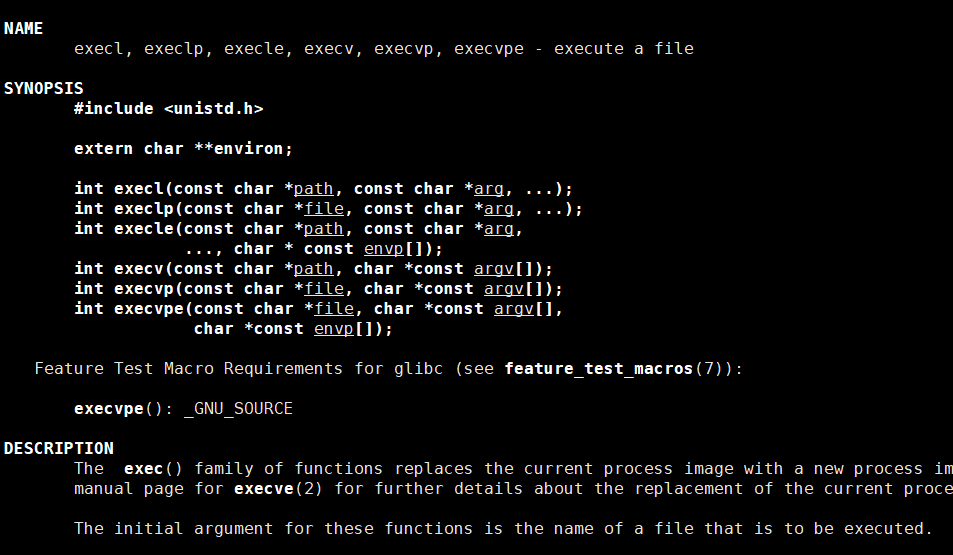
#include <unistd.h>int execl(const char *path, const char *arg0, ..., (char *) NULL);- path:要执行的可执行文件的路径。
- arg0:程序的名称(通常是
argv[0])。 - ...:可变参数列表,表示程序的命令行参数,以
NULL结尾。
返回值
- 成功时,
execl不会返回,因为原进程的代码已被替换。 - 失败时,返回
-1,并设置errno以指示错误类型。
注意事项
execl的参数列表必须以NULL结尾,否则可能导致未定义行为。- 如果
path不是有效的可执行文件路径,execl会失败。 - 调用
execl后,原进程的所有代码(包括execl之后的代码)都不会执行。
#include <iostream>
#include <unistd.h>int main()
{printf("before : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());execl("/usr/bin/ls", "ls", "-a", "-l", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());return 0;
}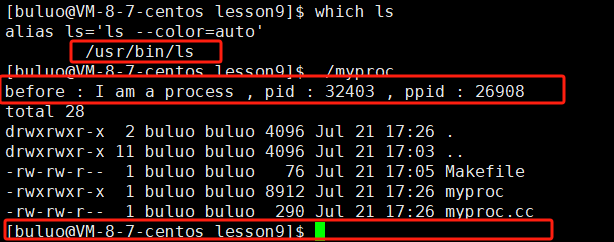
可以看到当我们将我们写的程序运行之后,系统中自带的命令ls被调用了,并且我们程序中的第二条printf语句并没有被执行,看到了这个现象,相信大家对进程替换有了一个初步的雏形,现在我们在来谈一谈进程替换的原理。
进程替换的原理
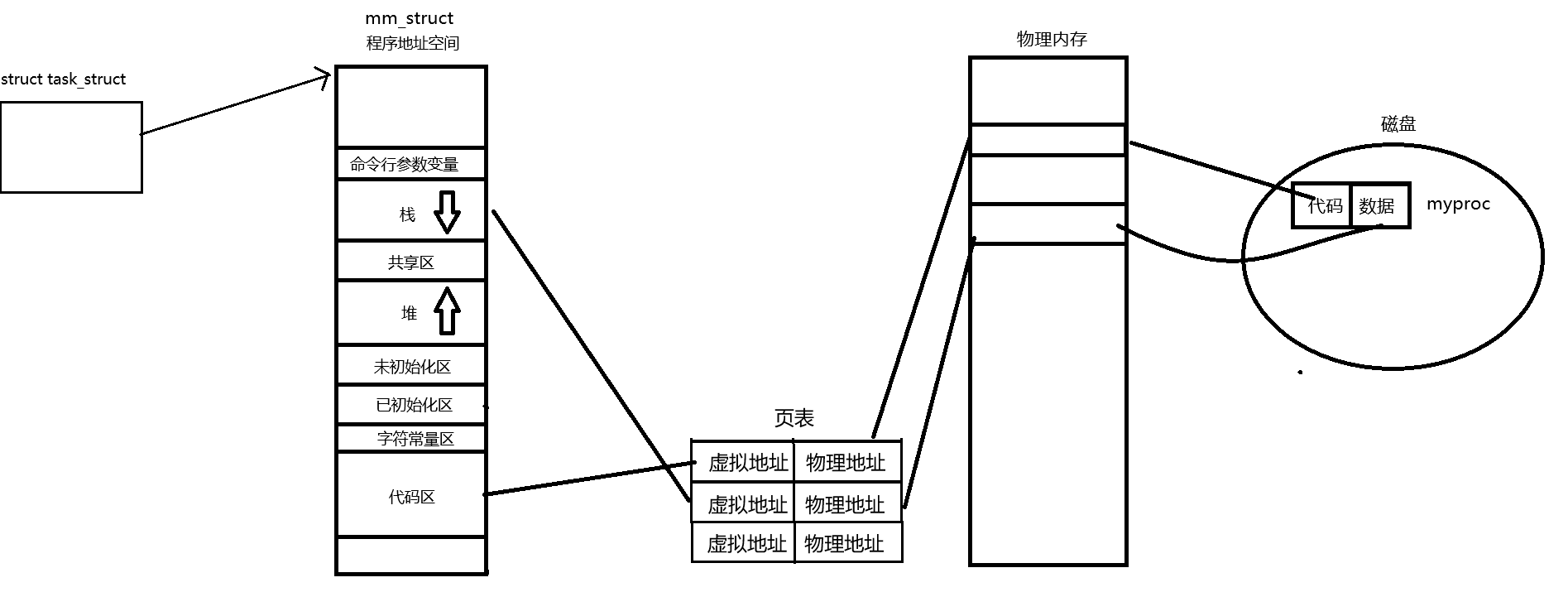
当我们启动一个程序时,操作系统首先会为其创建一个新的进程。内核会分配一个 task_struct来保存进程的基本信息,同时创建一个 mm_struct 结构来描述该进程的虚拟内存空间。随后,系统会将程序的代码段、数据段等通过页表映射加载到内存中,实现从虚拟地址到物理地址的转换。
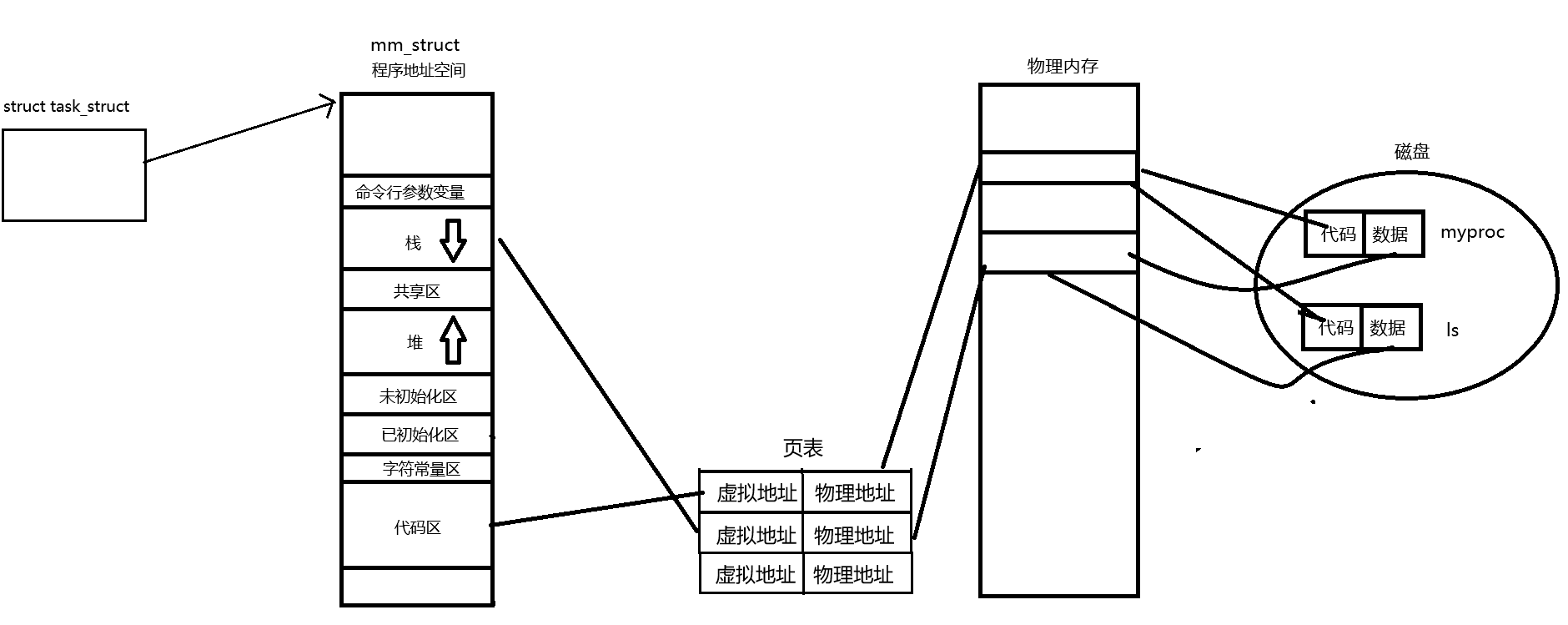
而当我们执行exec*系列的函数时,我们的进程就非常简单粗暴的将自己的代码和数据全部替换为ls的代码和数据,然后通过页表重新映射,这样就替换成功,然后从新程序的入口地址重新开始执行,所以从始至终,我们并没有创建新的进程,而是将原来的进程的代码和数据进行了修改,这就是进程替换的原理。接下来让我们看看多进程版本的程序替换。
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>int main()
{pid_t id = fork();if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execl("/usr/bin/ls", "ls", "-a", "-l", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}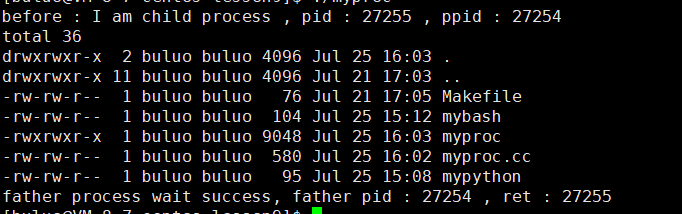
通过执行这段代码,我们可以明显看到,我们创建了一个子进程,然后让子进程进行程序替换,然后父进程等待并回收子进程,通过现象我们目前可以看到这些,但是我相信大家可能会有这样的疑问,我们之前单进程进行程序替换的时候我知道,他直接就将代码和数据替换了,但是现在,我们将子进程的代码和数据替换之后,会不会对父进程的代码和数据有影响呢?
答案是当然不会了,因为进程是具有独立性的,虽然子进程是父进程创建的,但是子进程的改变是不会影响父进程的,因为我们有写时拷贝技术,所以父进程是不会受到影响的。
那么还有人会说,有写时拷贝技术没有错,但是父子进程在写入的时候,不是数据发生写时拷贝,而代码不是不可被写入吗,那么怎么替换呢?没有错,代码是不可写入的,但是我们这里使用的是操作系统的接口呀,作为用户你是没有能力对代码进行写入的,但是一旦我们使用了操作系统的接口,那么一旦发生程序替换,我们的操作系统也会对代码进行写时拷贝,所以这就好比原则上我们不可以,但是现在原则就在这里。开个玩笑,所以操作系统是可以让代码也进行写时拷贝,从而进行进程替换。
现在我们在来补充一下几个小问题:
为什么当我们执行exec*系列函数之后的代码就不执行了呢?这就是因为在调用exec*函数之前,我们的代码还是正常执行,当我们执行exec*函数之后,进程的代码数据就被替换了,所以原来的代码和数据就找不到了,因此之后的代码就不会被执行了,这就好比你和你女朋友在热恋的时候,曾经许下了海誓山盟的承诺,说我将来要给你什么什么样的生活等等,但是不到几个月,你小子就执行了exec*函数(变心了),那么这些承诺你也就不遵守了,就好比那句话,爱的承诺只有在相爱的时候才有意义,差不多就是这个意思。
当我们程序替换了之后,我们是如何找到程序的入口地址的呢?虽然执行exec*函数之后进程的代码和数据都被替换了,但是CPU是如何找到这个新的程序的入口地址的呢?这个问题的答案就是其实在Linux中形成的可执行程序是有格式的,叫做ELF,其中就有可执行程序的表头,可执行程序的入口地址就在表中,所以我们就可以通过这个表头文件找到新程序的入口地址,这样我们就可以执行新的程序了。
好了,了解了这么多进程替换的原理,现在我们就来验证一下各个程序替换的接口,让我们直观感受一下。
多进程版本-验证各个程序替换的接口
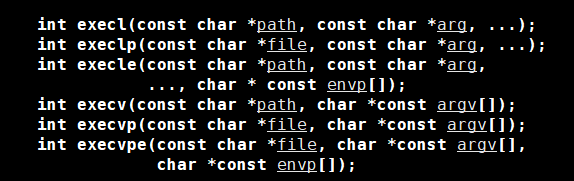
![]()
首先我们得所有得程序替换的接口都是exec开头的,而这个execl,l就代表list,意思就是我们在传参的时候,我们的参数从第二个开始是一个一个的将其传递给这个函数,就向列表一样,就和我们在命令行进行传参是一样的效果。而我们的第一个参数就是这个程序的地址,因为我们要执行一个程序,总得找到这个程序在哪,不然连位置到找不到,这还怎么执行。所以,在所有的exec*系列的函数的第一个参数都是执行程序的地址。而我们后面所填的参数目的就是在找到这个程序之后,如何执行这个程序,执行这个程序时,要涵盖哪些选项。反正就是在命令行怎么写,在这个函数中就怎么写。
现在我们再来看看第二个接口函数execlp,我们可以看待这个函数带了p,而这个p就是path,就是我们之前博客中提到的PATH环境变量,那么该函数就会在执行时会自己默认去PATH路径中查找该程序,所以我们只需要指明文件名就可以了。
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>int main()
{pid_t id = fork();if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execlp("ls", "ls", "-a", "-l", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}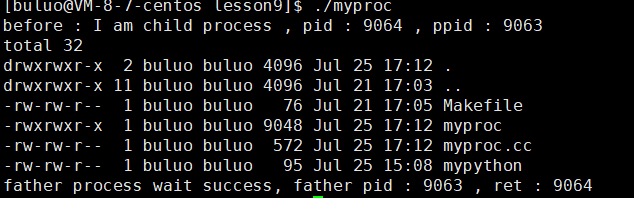
可以看到我们不需要指明路径,程序也可以正确执行。
现在我们再来看看execv这个接口函数,这个v就相当于vector,没有带p所以要带全路径,而我们的第二个参数我们可以看到并不是可变参数列表了,而成为了字符指针数组,说白了就是将我们命令行中的参数放入到字符指针数组中,然后将这个字符指针数组作为参数交给这个函数即可。
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>int main()
{char *const myargv[] = {"ls","-a","-l",NULL};pid_t id = fork();if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execv("/usr/bin/ls", myargv);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}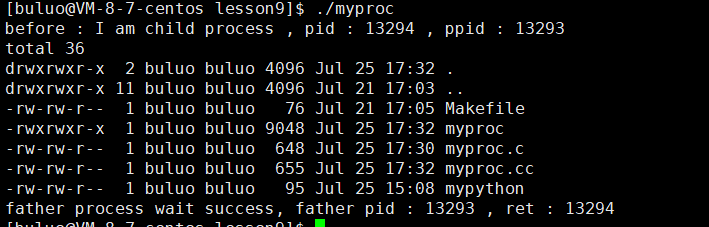
所以我们在执行ls时,会将我们自己写的字符指针数组传递给ls程序的main函数 ,这样ls命令就可以执行了。
下面我们再来看看execvp函数,通过上面的讲解,相信大家就明白这个函数该如何调用了,这里就不过多介绍,execvp第一个参数直接写文件名就可以,操作系统会在PATH环境变量中寻找该函数的路径,第二个则是字符指针数组,将我们需要的参数填入其中就可以了。
if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execvp("ls", myargv);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}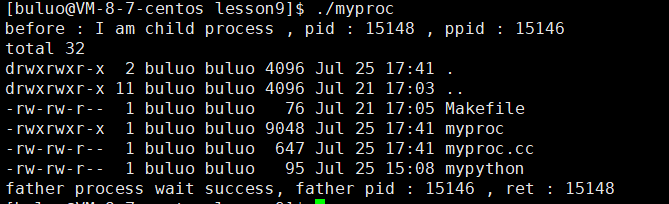
看了这么多函数的调用,我相信大家现在就有一个问题就是怎么都执行的系统的命令,我要执行一个我自己写的程序该怎么操作。现在,我们就来替换为我们自己写的程序来看看。
myproc.cc
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>int main()
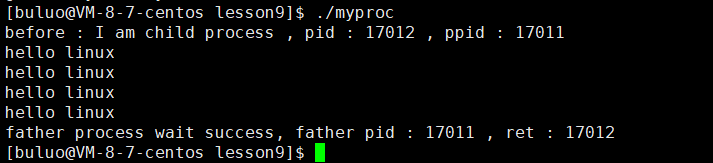
{pid_t id = fork();if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execl("./mytest", "mytest", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}mytest.cc
#include<iostream>int main()
{std::cout<<"hello linux"<<std::endl;std::cout<<"hello linux"<<std::endl;std::cout<<"hello linux"<<std::endl;std::cout<<"hello linux"<<std::endl; return 0;
} 
![]()
可以看到通过上面的代码我们将我们自己写的程序执行起来了,但是细心的同学可能发现了,你的execl中第一个写的路径时当前路径我知道,但是第二个参数为什么是这样写呢,你又没有将当前路径加到PATH环境变量中去,你执行的时候不应该是"./mytest"么,你是不是在胡扯呢?我相信同学看到都会有这样的疑问,但是我想说的是你说的很对,确实我们在命令行执行时需要加"./mytest",但是我们为什么要加"./mytest"呢?那是因为我们如果不加,我们就找不到我们程序所在位置,所以我们需要加,但是这里为什么不加呢?这时因为我们在调用execl函数时,他的第一个参数已经告诉了我们的操作系统这个函数在哪里,所以我们在这里可以不加,当然了,我们加上也是可以了,没有什么影响。
那么现在我们已经可以替换为我们自己写的程序了,我们可以再调用其他解释性语言,或者一些脚本语言呢?让我们来试一试。
用其他语言编写的程序进行替换
if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execl("/usr/bin/bash", "bash", "test.sh", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}
#! /usr/bin/bashfunction myfun()
{cnt=1while [ $cnt -le 10 ]doecho "hello $cnt"let cnt++done
}myfun 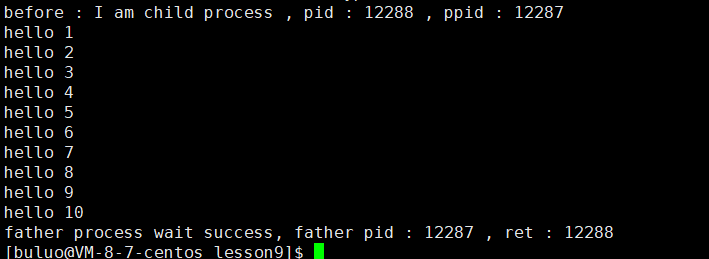
if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execl("/usr/bin/python3", "python", "test.py", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}
#! /usr/bin/python3def func():for i in range(0,10):print("hello " + str(i))func()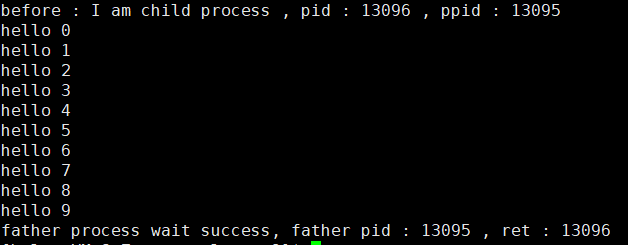
所以我们的进程替换不仅仅可以调用系统命令,还可以调用我们自己写的程序,还可以进行跨语言的调用,这归根结底还是因为所有的语言都是一个工具而已,在执行的时候,本质都是进程!只要是进程,我们就可以通过操作系统提供的接口被我们操作,所以只要我们的程序是在操作系统时使用,再高级的语言执行起来都是一个进程。
了解了这么多,我们再来看看最后两个接口函数execle和execvpe,这两个函数接口中都有e,那么这个e代表什么呢?这个e就是我们的env(environment)环境变量,我们看看我们如何将父进程的设置的环境变量交给替换进程呢?我们先来看看不传之前能不能接收到环境变量?
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>int main()
{pid_t id = fork();if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execl("./mytest", "mytest", "-a", "-b", "-c", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}
#include <iostream>int main(int argc, char *argv[], char *env[])
{std::cout << "这是命令行参数!" << std::endl;std::cout << "begin!!!!!!!!!!!!" << std::endl;for (int i = 0; i < argc; i++){std::cout << i << " : " << argv[i] << std::endl;}std::cout << "这是环境变量!" << std::endl;for (int i = 0; env[i]; i++){std::cout << i << " : " << env[i] << std::endl;}std::cout << "end!!!!!!!!!!!!!!" << std::endl;return 0;
}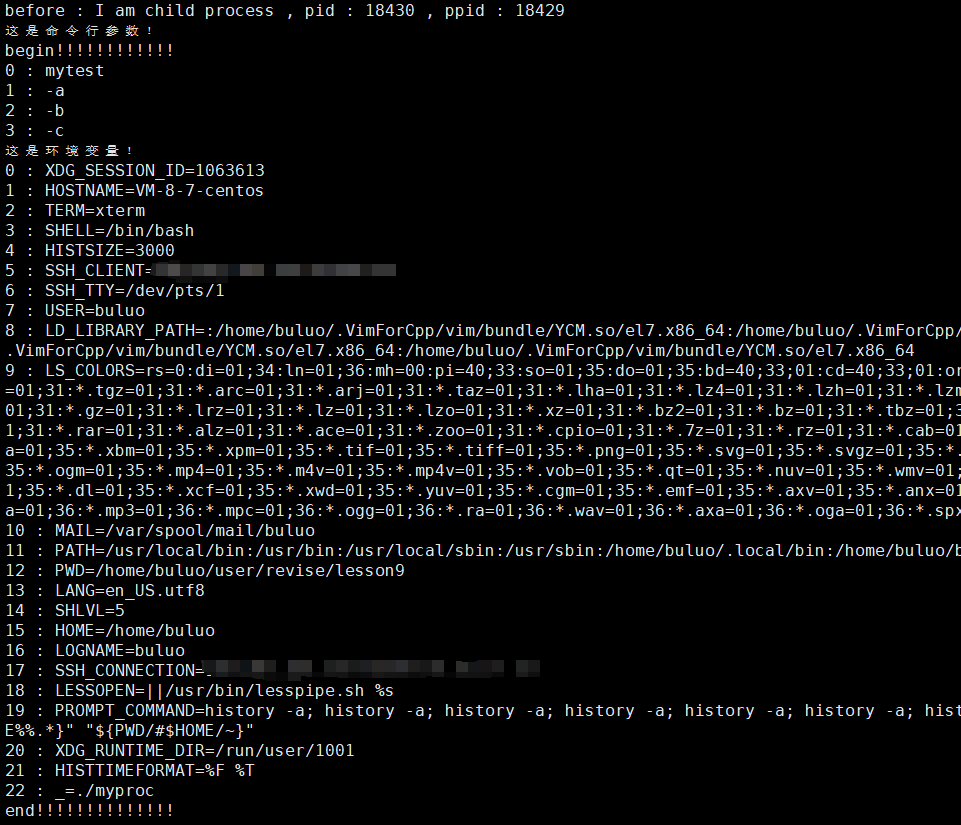
我们可以看到我们使用的是execl接口,并没有传入环境变量,但是替换的进程依旧拿到了,这是为什么呢?环境变量又是什么时候给进程的?
环境变量也是数据,在我们的程序地址空间中的栈区上方就是我们的环境变量,所以在创建子进程的时候,环境变量就已经被子进程继承下去了!所以我们不传也可以拿到环境变量的信息。那么这两个接口的功能是干什么的呢?我都能拿到环境变量了,还要你们干什么。
其实这两个接口函数的功能就是为了新增一些环境变量或者将这个环境变量彻底全部替换
我们来看看如何新增环境变量,我们可以通过接口函数putenv就可以实现,现在我们进行实现一下看看。
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>int main()
{extern char **environ;putenv("buluo=66666");pid_t id = fork();if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execle("./mytest", "mytest", "-a", "-b", "-c", NULL, environ);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}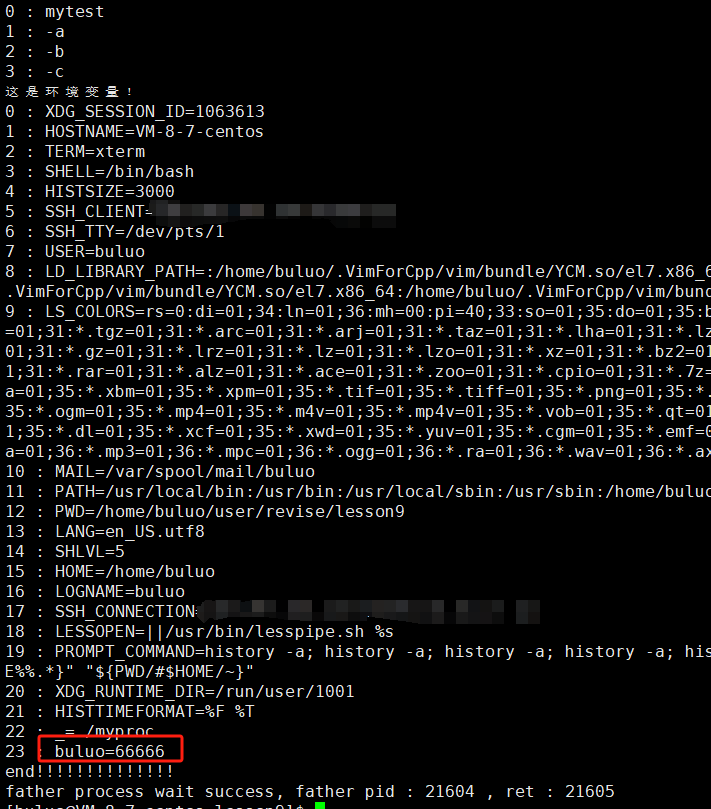
这样,我们替换进程后也可以拿到父进程中新增的环境变量。
自定义环境变量
int main()
{extern char **environ;putenv("buluo=66666");pid_t id = fork();char *const myenv[]={"MYVAL=66666","TEST=380",NULL};if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execle("./mytest", "mytest", "-a", "-b", "-c", NULL, myenv);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}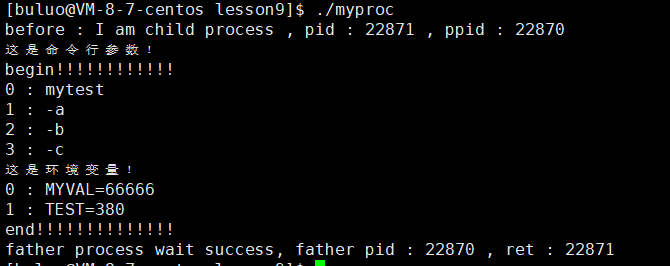
这样就可以自定义环境变量了。
而最后一个函数execve也就是类似的功能,我们也用代码模拟一下即可
int main()
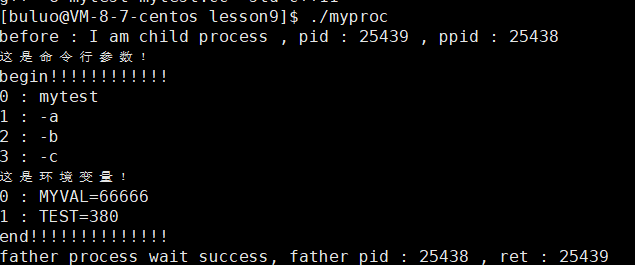
{extern char **environ;putenv("buluo=66666");pid_t id = fork();char *const myargv[] = {"mytest", "-a", "-b", "-c", NULL};char *const myenv[] = {"MYVAL=66666","TEST=380",NULL};if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execve("./mytest", myargv, myenv);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}
命名理解
- l(list) : 表示参数采用列表
- v(vector) : 参数用数组
- p(path) : 有p自动搜索环境变量PATH
- e(env) : 表示自己维护环境变量
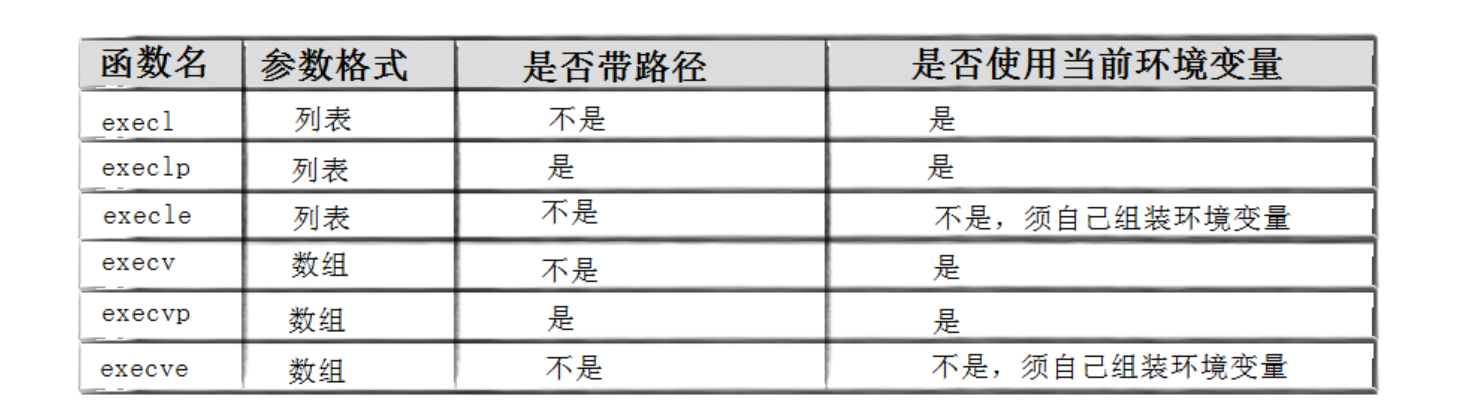
事实上,只有execve是真正的系统调用,其它六个函数最终都调用 execve
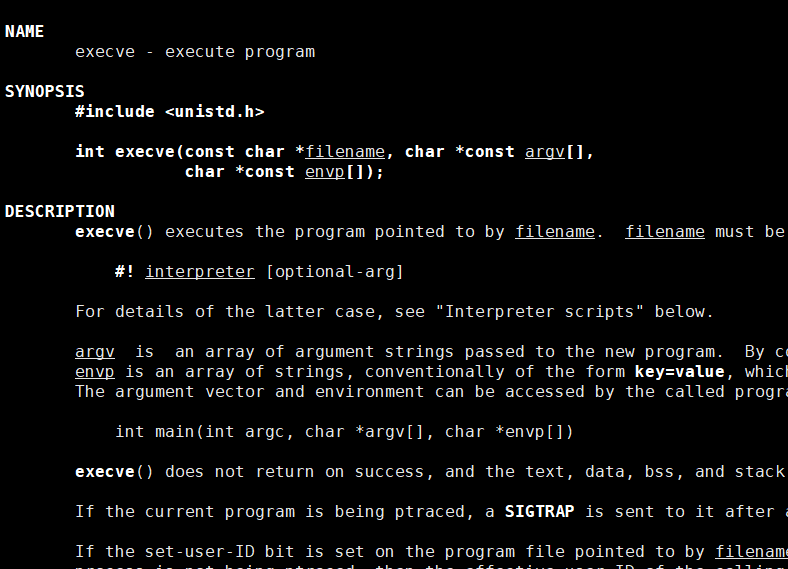
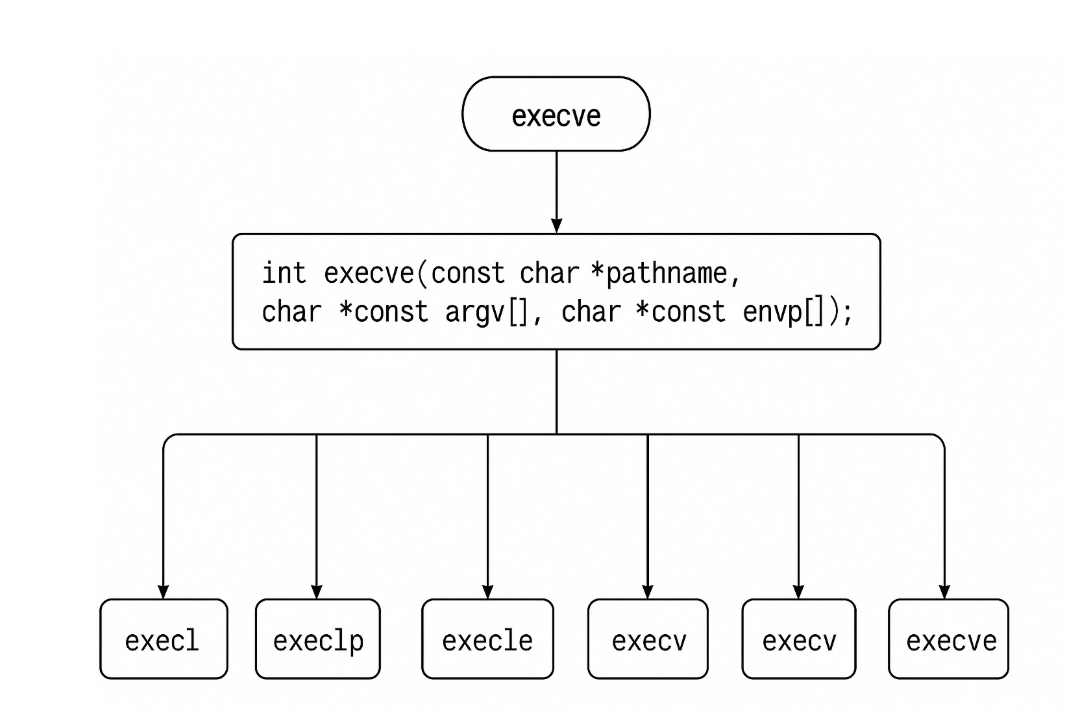
这就是进程替换,希望对大家理解进程的控制有一定的帮助!!!!!!



)

)









---层序遍历二叉树)
)

对北半球光伏数据进行时间序列预测)
