摘要:强化学习(RL)已成为大语言模型(LLM)在完成预训练后与复杂任务及人类偏好对齐的关键步骤。人们通常认为,要通过 RL 微调获得新的行为,就必须更新模型的大部分参数。本研究对这一假设提出了挑战,并给出令人惊讶的发现:RL 微调实际上只改变了 LLM 中的一条小子网络(通常仅占 5%–30% 的参数),而绝大多数权重几乎保持不变。我们将这种现象称为“RL 诱导的参数更新稀疏性”。该稀疏性是自发产生的,没有施加任何显式的稀疏约束,也未采用参数高效微调技术。我们在 7 种不同的 RL 算法(PPO、GRPO、ORPO、KTO、DPO、SimPO 和 PRIME)以及多种模型家族(如 OpenAI、Meta 以及开源 LLM)中一致地观察到该稀疏性。更有趣的是,RL 所更新的这条子网络在不同随机种子、训练数据集甚至不同 RL 算法之间都表现出显著的重叠,远高于随机预期,表明预训练模型中存在部分可迁移的结构。我们发现,仅对这条子网络进行微调(冻结其余所有权重)即可恢复完整 RL 微调模型的性能,并且在参数空间中几乎与全模型微调得到的模型无异。最后,我们分析了 RL 为何仅更新一条稀疏子网络。证据表明,主要原因是 RL 微调所用的数据靠近模型自身的分布,只需进行微小且针对性的参数调整;而保持策略接近预训练模型(如 KL 正则化)以及其他实现细节(如梯度裁剪、on-policy 与 off-policy 更新)对整体稀疏性的影响有限。这些发现加深了我们对 RL 驱动模型适应的理解,表明 RL 将训练集中在一条小而始终活跃的子网络上,同时令大多数权重保持惰性,也为 RL 微调为何比监督微调更能保留预训练能力提供了新的解释。这为利用这种内在更新稀疏性的更高效 RL 微调方法(例如将计算集中在该子网络)打开了大门,并在大模型对齐的背景下为“彩票假设”提供了新的视角。
一句话总结文章
强化学习(RL)微调大语言模型时,仅更新模型中5-30%的参数形成稀疏子网络,且该子网络在不同随机种子、数据集和算法下具有高度一致性,独立训练即可达到全模型性能。
论文信息
论文标题: "Reinforcement Learning Fine-Tunes a Sparse Subnetwork in Large Language Models"
作者: "Andrii Balashov"
会议/期刊: "arXiv preprint"
发表年份: 2025
原文链接: "https://www.arxiv.org/pdf/2507.17107"
代码链接: ""
关键词: ["强化学习微调", "稀疏子网络", "大语言模型", "参数高效微调", "RLHF"]
引用: "@article{balashov2025rlsparse,title={Reinforcement Learning Fine-Tunes a Sparse Subnetwork in Large Language Models},author={Balashov, Andrii},journal={arXiv preprint arXiv:2507.17107},year={2025}
}"一、研究背景
近年来,大语言模型(LLMs)的对齐技术如RLHF(基于人类反馈的强化学习)已成为提升模型能力的关键手段。然而,现有方法存在两大痛点:
- 全模型微调效率低下:传统观点认为RL需要更新所有参数以实现行为对齐,但这导致计算成本高昂(尤其是70B等大模型)。
- 监督微调(SFT)的副作用:SFT会对模型参数进行密集更新(仅5-15%参数保持不变),可能破坏预训练知识,导致泛化能力下降。
尽管业界观察到RL微调比SFT更能保留预训练能力,但背后的机制一直是未解之谜。本文通过系统性实验揭示:RL微调本质上仅调整模型中的"关键旋钮"(稀疏子网络),这解释了为何它能在高效对齐的同时保留原有能力。
二、核心要点
“文章发现所有主流RL微调算法(PPO、DPO、PRIME等)在7B-70B规模模型上均表现出内在稀疏性——仅5-30%参数被显著更新。更惊人的是,这些更新并非随机:不同实验条件下更新的子网络重叠度高达60%,且仅训练该子网络就能达到全模型99.9%的性能。”
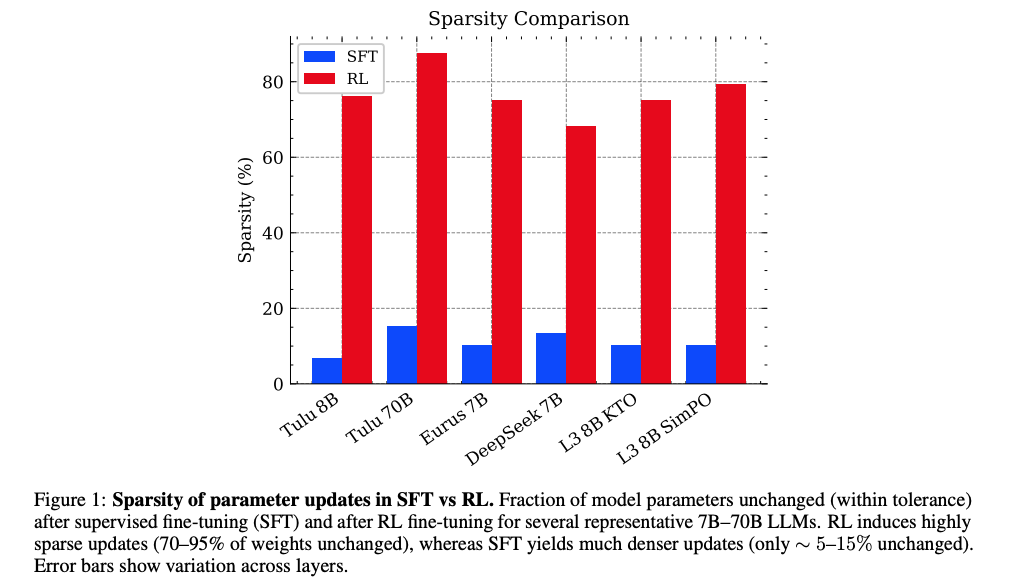
图1显示:RL微调后70-95%参数保持不变(蓝色柱),而SFT仅5-15%参数不变(红色柱)。误差条表示层间差异。
- 现象发现:RL微调大语言模型时存在内在稀疏更新现象(70-95%参数不变)
- 机制揭示:稀疏性源于RL对近分布数据的微调需求,非显式约束
- 实用价值:子网络独立训练可降低70-95%计算成本,性能无损
- 理论意义:为"彩票假说"提供新证据——预训练模型中存在可迁移的对齐子网络
三、深度拆解:稀疏子网络的四大发现
3.1 参数更新的"三分类"模式
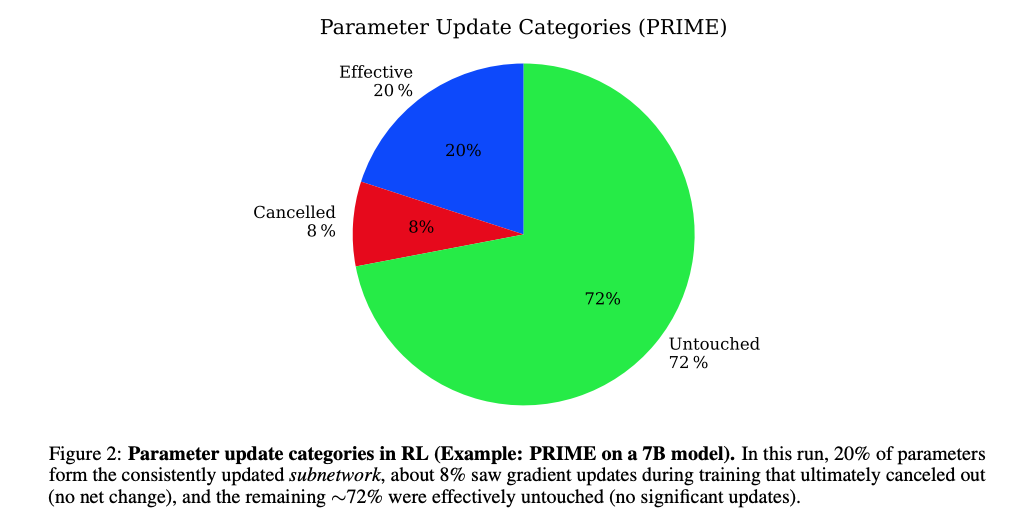
图2显示PRIME算法在7B模型上的参数更新分布:72%未更新(Untouched),20%持续更新(Effective),8%临时更新后回退(Cancelled)。
通过追踪参数变化轨迹,研究发现RL训练过程中参数更新呈现三种模式:
- 未更新参数(72%):始终保持初始值,对RL目标无贡献
- 有效更新参数(20%):持续调整并稳定在新值,构成核心子网络
- 临时更新参数(8%):训练中期短暂变化,最终回退到初始值(图5的"瞬态更新"现象)
这种模式类似于人类学习:仅聚焦关键知识点,摒弃干扰信息。
3.2 层间稀疏性的均匀分布
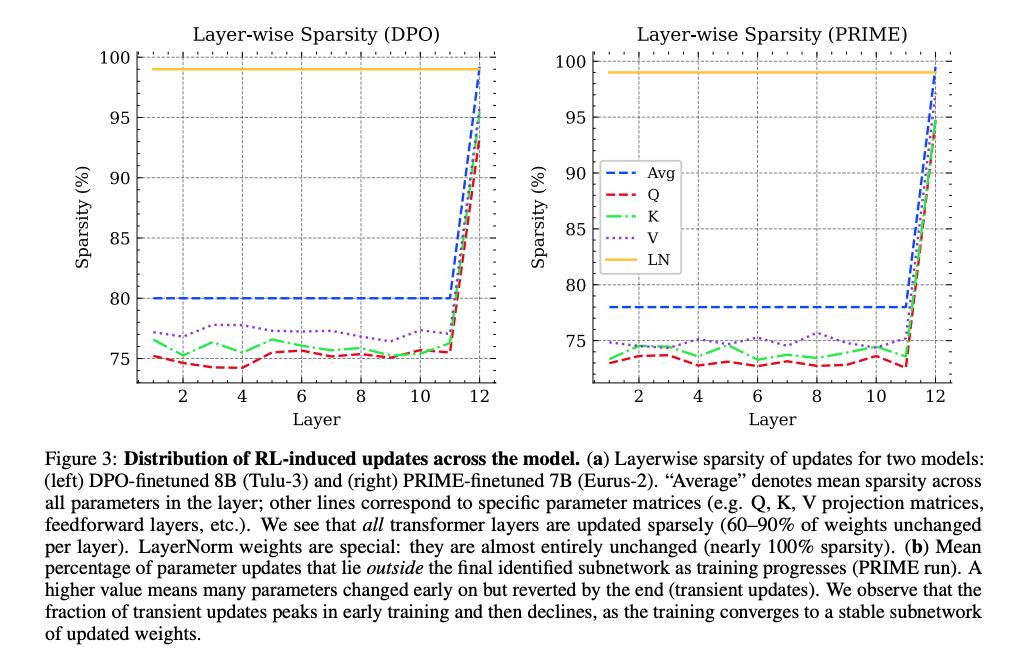
图3显示DPO(左)和PRIME(右)算法在各层的稀疏性分布。所有Transformer层保持70-90%稀疏性,仅LayerNorm参数接近100%不变。
关键发现:
- 均匀稀疏:稀疏性在所有Transformer层间均匀分布,非集中于输入/输出层
- 特殊模块:LayerNorm参数几乎完全不变(99%+稀疏性),暗示RL微调不改变模型的基础归一化能力
- 矩阵差异:Q/K/V投影矩阵稀疏性相近(75-80%),前馈层略低
这解释了为何RL微调能局部调整行为而不破坏整体架构。
3.3 训练动态的"探索-收敛"过程
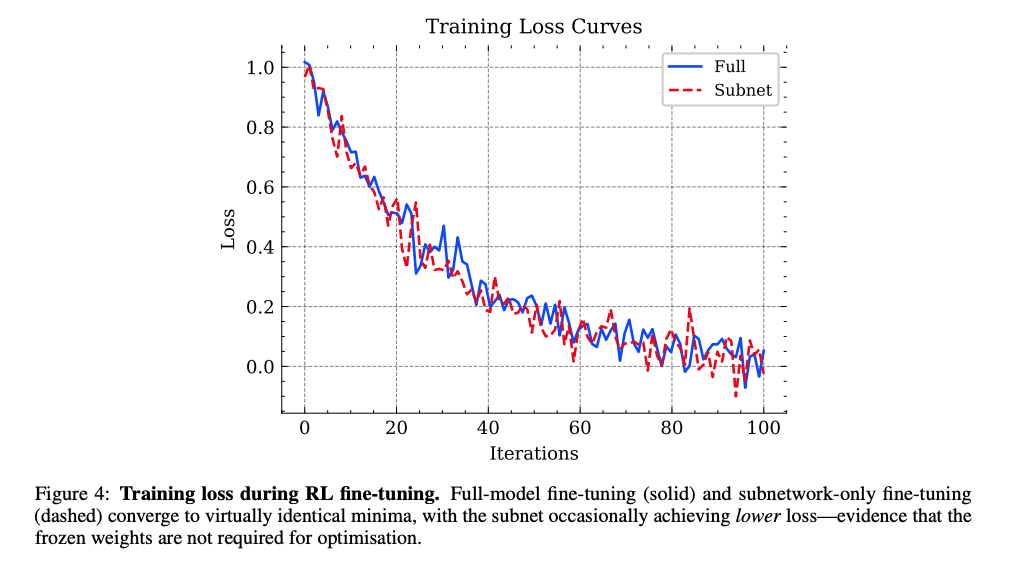
图4显示全模型微调(蓝色实线)与仅子网络微调(红色虚线)的损失曲线几乎重合,证明子网络足以完成优化目标。
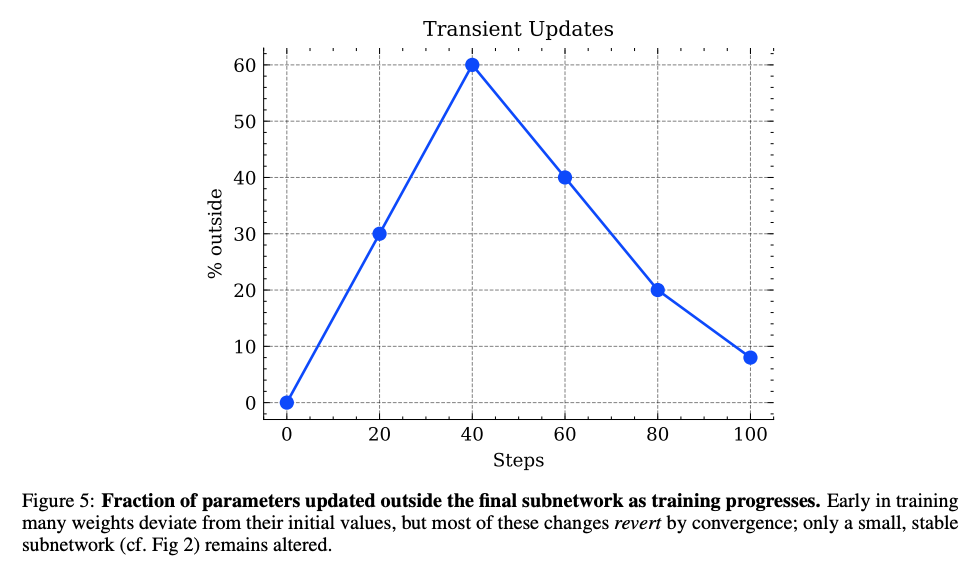
图5显示训练过程中"临时更新"参数比例先升后降,表明RL在早期探索后收敛到稳定子网络。
训练动态分析揭示:
- 早期探索:前20%训练步骤中,模型会尝试更新大量参数(瞬态更新比例达60%)
- 中期收敛:随着训练推进,非关键参数逐渐回退到初始值
- 稳定阶段:最终仅保留5-30%的核心参数更新
这种"先探索后聚焦"的机制,类似于科研中的假设验证过程。
3.4 高秩更新的"精准手术"
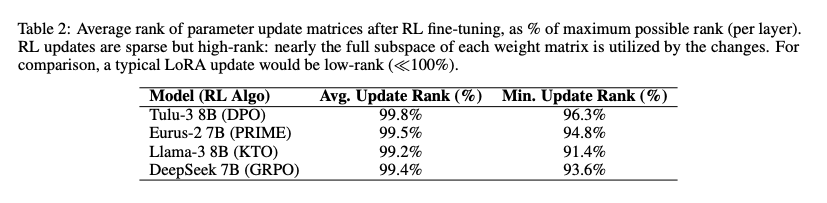
表2显示RL更新矩阵的平均秩接近99.5%,远高于LoRA等低秩方法,表明稀疏但全维度的参数调整。
与LoRA等显式低秩方法不同,RL微调表现出:
- 高秩特性:更新矩阵秩占最大可能秩的96.3-99.8%
- 精准性:在稀疏更新的同时,覆盖参数矩阵的全维度空间
- 效率平衡:以5-30%的参数更新实现接近全模型的表示能力
这如同用微创手术替代开腹手术——创伤小但效果等同。
四、实验结果:三大关键证据
4.1 子网络性能超越全模型微调
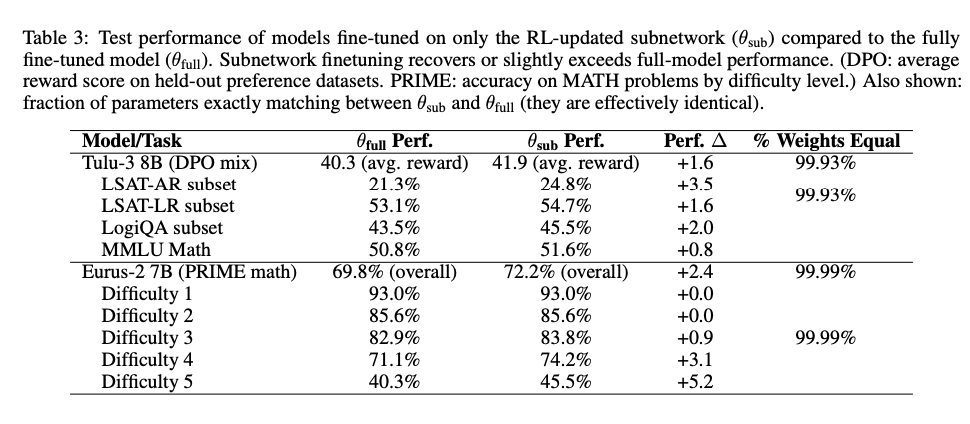
表3显示:仅训练RL识别的子网络(θ_sub)在所有任务上达到或超过全模型微调(θ_full)性能,尤其在高难度任务(如MATH Level 5)提升5.2%。
关键数据:
- 平均性能提升:+1.6(DPO混合任务)、+2.4(PRIME数学任务)
- 参数一致性:99.93-99.99%参数值与全模型微调完全一致
- 计算效率:训练成本降低70-95%(仅更新5-30%参数)
4.2 子网络的跨条件一致性
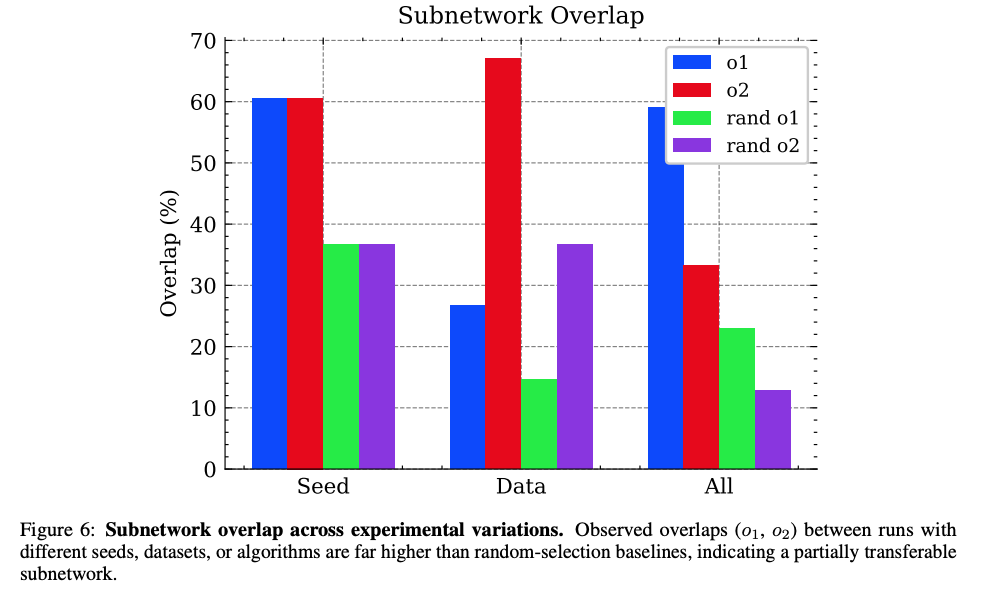
图6显示不同实验条件下子网络重叠度(o1/o2)显著高于随机基线(rand o1/rand o2),证明子网络的内在一致性。
跨三种变异条件的重叠度:
- 不同随机种子:60.5%重叠(随机基线36.7%)
- 不同数据集:26.7-67.1%重叠(随机基线14.6-36.7%)
- 不同算法:33.2-59.1%重叠(随机基线12.9-23.0%)
这种一致性暗示:预训练模型中存在固定的"对齐敏感"参数子集。
4.3 稀疏性与任务难度的正相关
在数学推理任务中:
- 简单任务(Level 1-2):子网络性能与全模型完全一致(0.0%差异)
- 高难任务(Level 5):子网络性能提升5.2%,参数变化更集中
这表明:任务越复杂,RL越倾向于聚焦核心子网络,避免无关参数干扰。
五、未来工作:从发现到应用
5.1 文章展望
- 开发动态子网络定位算法,实时识别并更新关键参数
- 探索跨模型子网络迁移,实现知识复用
- 结合剪枝技术,构建稀疏对齐专用模型
5.2 问题探讨
- 可视化研究:子网络是否对应特定注意力头/神经元集群?
- 对抗鲁棒性:稀疏子网络是否更易受参数攻击?
- 多任务场景:不同任务是否共享同一子网络?5.3 论文信息







---层序遍历二叉树)
)

对北半球光伏数据进行时间序列预测)








