梯度下降(Gradient Descent)是深度学习中最核心的优化方法之一,它通过迭代更新模型参数,使得损失函数达到最小值,从而训练出性能良好的神经网络模型。
基础原理
损失函数
在深度学习中,损失函数 L(θ) 是衡量模型预测值与真实值差距的函数,θ 表示模型参数。常见的损失函数包括:
-
均方误差(MSE):适用于回归问题
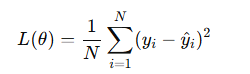
-
交叉熵损失(Cross-Entropy Loss):适用于分类问题
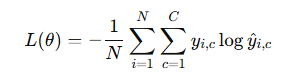
损失函数是梯度下降的优化目标,梯度下降通过计算损失函数对参数的偏导数,引导参数向最优值更新。
梯度与偏导数
梯度是多变量函数在某一点处的方向导数向量,它指向函数上升最快的方向。在深度学习中:
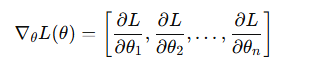
梯度下降通过沿梯度的反方向更新参数,使损失函数下降:
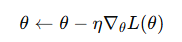
其中 η 是学习率(learning rate),控制每次更新的步长。
学习率的重要性
学习率 η 是梯度下降的核心超参数:
- 过大:可能导致训练不收敛,甚至发散
- 过小:收敛速度慢,可能陷入局部最优
常用的策略包括:
- 学习率衰减(Learning Rate Decay):随训练轮数减小学习率
- 自适应学习率方法:如 Adam、RMSProp 等,自动调整每个参数的学习率
梯度下降算法及其变体
批量梯度下降(Batch Gradient Descent)
原理:每次迭代使用整个训练集计算梯度更新参数。
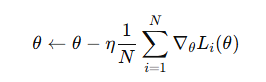
优点:
- 收敛稳定,方向正确
- 适合凸优化问题
缺点:
- 数据量大时计算量大,内存消耗高
- 对非凸优化容易陷入局部最优
随机梯度下降(Stochastic Gradient Descent, SGD)
原理:每次迭代仅使用一个样本计算梯度。
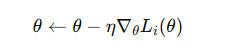
优点:
- 计算效率高,可处理大规模数据
- 可跳出局部最优,具有一定随机性
缺点:
- 梯度波动大,收敛不稳定
- 需要设置较小的学习率以保证收敛
小批量梯度下降(Mini-batch Gradient Descent)
原理:每次迭代使用一小批数据计算梯度。
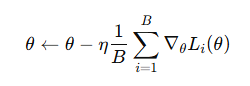
其中 B 为批大小(Batch Size)。
优点:
- 综合了批量和随机梯度下降的优点
- 可利用 GPU 并行计算,提高训练效率
- 梯度波动适中,有利于跳出局部最优
缺点:
- 批大小选择敏感,过小梯度噪声大,过大收敛慢
动量法(Momentum)
动量法在更新参数时引入惯性项,缓解 SGD 的震荡:
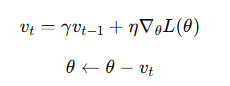
- γ 是动量因子(通常取 0.9)
- 优点:加速收敛,尤其在陡峭斜坡方向
- 类比物理:参数像有惯性的粒子在损失函数曲面上滚动
自适应学习率方法
AdaGrad
-
思路:根据参数历史梯度调整学习率,小梯度方向加大步长,大梯度方向减小步长
-
更新公式:
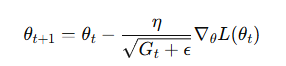
其中 Gt 为历史梯度平方和矩阵,ϵ\epsilonϵ 防止除零
缺点:学习率单调下降,可能过早停止
RMSProp
-
改进 AdaGrad,使用指数加权平均避免学习率过早减小
-
更新公式:
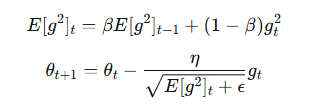
Adam
-
结合动量法和 RMSProp
-
利用一阶矩估计和二阶矩估计动态调整学习率
-
更新公式:
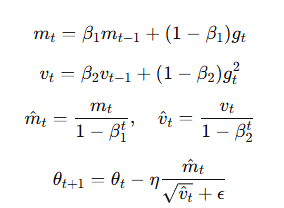
Adam 是目前深度学习中最常用的优化器之一,适合大多数场景。
梯度下降的挑战与解决方案
梯度消失与爆炸
在深层神经网络中,反向传播可能导致梯度过小(消失)或过大(爆炸),影响收敛。原因包括:
- 梯度消失:如 sigmoid 激活函数在饱和区域导数接近 0。
- 梯度爆炸:梯度在深层网络中累积放大。
局部极小值与鞍点
深度学习的损失函数通常是非凸的,存在局部极小值和鞍点。随机梯度下降的噪声有助于跳出局部极小值,而动量法和自适应优化器可加速逃离鞍点。
计算效率
深度学习模型涉及大量参数和数据,梯度计算成本高。解决方案包括:
- 分布式训练:如数据并行和模型并行。
- 混合精度训练:利用半精度浮点数(如 FP16)加速计算。
- 高效硬件:如 GPU、TPU 加速矩阵运算。
学习率选择与调参
学习率的选择对收敛至关重要。过大可能导致发散,过小则收敛缓慢。解决方案包括:
- 学习率搜索:如网格搜索或随机搜索。
- 自动调参工具:如 Optuna 或 Ray Tune。
- 自适应优化器:如 Adam 减少手动调参需求。
梯度下降在深度学习中的应用
梯度下降广泛应用于深度学习的各个领域,包括但不限于:
- 计算机视觉:
- 卷积神经网络(CNN):如 ResNet、EfficientNet 用于图像分类、目标检测。
- 视觉 Transformer:如 ViT 用于图像分割、图像生成。
- 自然语言处理:
- 循环神经网络(RNN):如 LSTM 用于序列建模。
- Transformer 模型:如 BERT、GPT 用于机器翻译、文本生成。
- 强化学习:
- 深度 Q 网络(DQN):优化策略函数。
- 策略梯度方法:如 PPO 用于机器人控制。
- 生成模型:
- 生成对抗网络(GAN):优化生成器和判别器。
- 变分自编码器(VAE):优化编码器和解码器。
- 推荐系统:如深度因子分解机(DeepFM)优化用户偏好预测。
总结
梯度下降作为深度学习的核心优化算法,以其简单性和高效性成为模型训练的基石。从批量梯度下降到 Adam 等自适应优化器,梯度下降的变体和优化策略不断演进,显著提高了收敛速度和稳定性。然而,面对日益复杂的模型和任务,梯度下降仍需应对梯度消失/爆炸、计算效率和泛化能力等挑战。








:常见组件和容器低代码开发示例(ArkTS))

实践:Istio在导购系统中的应用)







)
 算法原理)