精选专栏链接 🔗
- MySQL技术笔记专栏
- Redis技术笔记专栏
- 大模型搭建专栏
- Python学习笔记专栏
- 深度学习算法专栏
欢迎订阅,点赞+关注,每日精进1%,与百万开发者共攀技术珠峰
更多内容持续更新中!希望能给大家带来帮助~ 😀😀😀
详解MySQL子查询
- 1,什么是子查询
- 2,从具体需求理解子查询
- 3,子查询的分类
- 4,单行子查询实战
- 4.1,普通的单行子查询
- 4.2,HAVING子句中的单行子查询
- 4.3,CASE中的单行子查询
- 5,多行子查询实战
- 5.1,多行子查询实战
- 5.2,多行子查询的空值问题
- 6,相关子查询和不相关子查询
- 6.1,相关子查询的执行流程
- 6.2,不相关子查询与相关子查询对比
- 6.3,在ORDER BY 中使用关联子查询
- 6.4,案例进阶
- 6.5,EXISTS 与 NOT EXISTS关键字
- 7,子查询和自连接效率
1,什么是子查询
子查询指一个查询语句嵌套在另一个查询语句内部的查询。 SQL 中子查询的使用大大增强了 SELECT 查询的能力,因为很多时候查询需要从结果集中获取数据,或者需要从同一个表中先计算得出一个数据结果,然后与这个数据结果(可能是某个标量,也可能是某个集合)进行比较。
2,从具体需求理解子查询
需求:查询employees表中谁的工资比 Abel 高
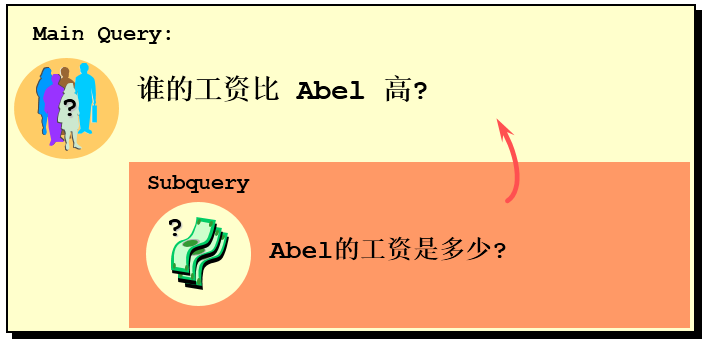
针对此需求,有多种实现方式可供选择。
实现方式一 :使用多个SQL语句
先查询员工Abel的工资:
SELECT salary
FROM employees
WHERE last_name = 'Abel';
运行结果如下:

根据查询结果进行筛选:
SELECT last_name,salary
FROM employees
WHERE salary > 11000;
运行结果如下:

此实现方式与数据库进行了两次交互,效率较低。
实现方式二:使用自连接
SQL语句如下:
SELECT e2.last_name,e2.salary
FROM employees e1,employees e2
WHERE e2.`salary` > e1.`salary`
AND e1.last_name = 'Abel';
运行结果如下:

自连接的实现方式通过联表将符合连接条件的记录拼接在一起进行查询。只需与数据库进行一次交互,效率高于方式一。
实现方式三:使用子查询
方式一中是先查询出 Abel 的工资为11000,然后在第二条SQL语句中通过WHERE salary > 11000 进行过滤,找到符合条件的信息。如果我们不把11000写死,而是用一段SQL语句实现,那么这就是一个简单的子查询。其中:
- 子查询语句要包含在括号内;
- 外面的SELECT语句称为主查询或外查询,内部的子查询SELECT语句称为子查询或内查询;
- 子查询在主查询之前一次执行完成,子查询的结果被主查询使用 ;
SQL示例如下:
SELECT last_name,salary
FROM employees
WHERE salary > (SELECT salaryFROM employeesWHERE last_name = 'Abel');
运行结果如下:

3,子查询的分类
- 根据从子查询中返回的结果的条目数可以分为:单行子查询和多行子查询;
- 根据子查询是否被执行多次可以分为相关子查询和不相关子查询;
下面我们会结合具体需求,详细讲解这几类子查询。
4,单行子查询实战
单行子查询只返回一个结果数据供主查询使用。
单行子查询常结合如下比较操作符:
| 操作符 | 含义 |
|---|---|
| = | 等于 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| <> | 不等于 |
4.1,普通的单行子查询
需求一:查询工资大于149号员工工资的员工的信息
SQL语句如下:
SELECT employee_id,last_name,salary
FROM employees
WHERE salary > (SELECT salaryFROM employeesWHERE employee_id = 149);
需求二:返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
SQL语句如下:
SELECT last_name,job_id,salary
FROM employees
WHERE job_id = (SELECT job_idFROM employeesWHERE employee_id = 141)
AND salary > (SELECT salaryFROM employeesWHERE employee_id = 143);
运行结果如下:
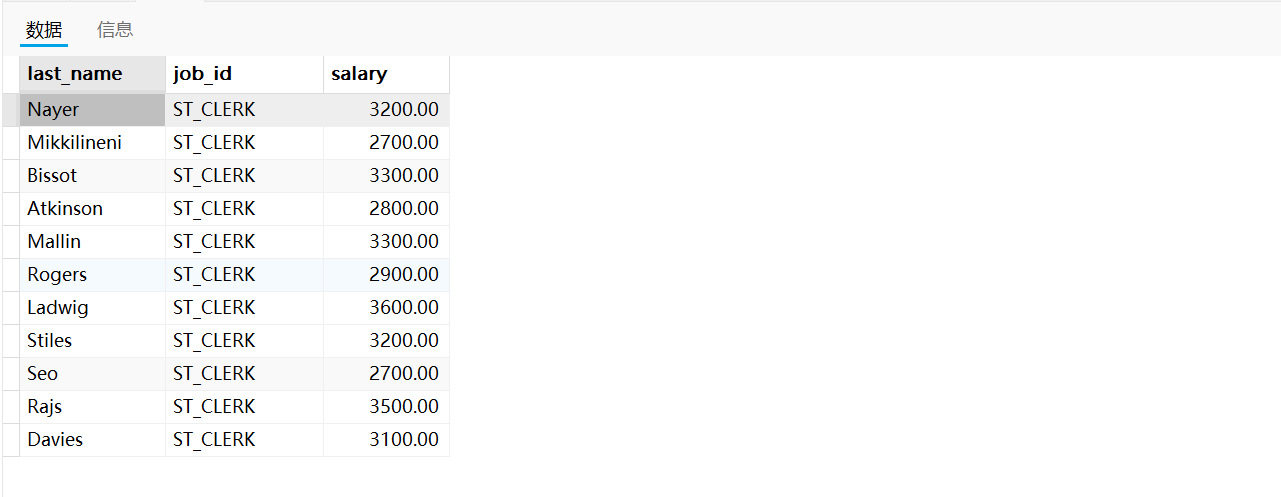
需求三:返回公司工资最少的员工的last_name、job_id和salary
SQL语句如下:
SELECT last_name, job_id, salary
FROM employees
# 即找出工资等于最少工资的所有员工的信息
WHERE salary = (SELECT MIN(salary)FROM employees);
运行结果如下:

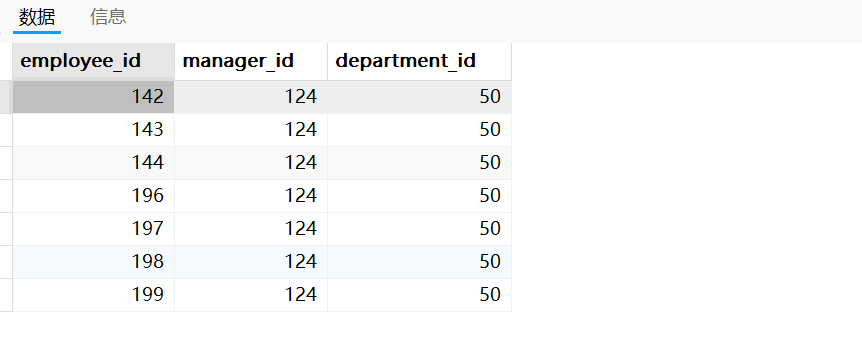
需求四:查询与141号员工的manager_id和department_id相同的其他员工的employee_id,manager_id,department_id。
实现方式一:
SELECT employee_id,manager_id,department_id
FROM employees
WHERE manager_id = (SELECT manager_idFROM employeesWHERE employee_id = 141)
AND department_id = (SELECT department_idFROM employeesWHERE employee_id = 141)
AND employee_id <> 141;
实现方式二(了解):成对查询
SELECT employee_id,manager_id,department_id
FROM employees
WHERE (manager_id,department_id) = (SELECT manager_id,department_idFROM employeesWHERE employee_id = 141)
AND employee_id <> 141;
以上两种实现方式返回的运行结果相同,如下图所示:
4.2,HAVING子句中的单行子查询
需求:查询最低工资大于110号部门最低工资的部门id和其最低工资
SELECT department_id,MIN(salary)
FROM employees
WHERE department_id IS NOT NULL # 过滤掉department_id为NULL的部门
GROUP BY department_id
HAVING MIN(salary) > (SELECT MIN(salary)FROM employeesWHERE department_id = 110);
这是一个HAVING子句中使用单行子查询的例子。
4.3,CASE中的单行子查询
需求:查询员工的employee_id,last_name和一个新字段location。其中,若员工department_id与location_id为1800的department_id相同,则location为’Canada’,其余则为’USA’。
SELECT employee_id,last_name,CASE department_id WHEN (SELECT department_id FROM departments WHERE location_id = 1800) THEN 'Canada'ELSE 'USA' END "location"
FROM employees;
运行结果如下:

5,多行子查询实战
子查询返回多行数据即为多行子查询,也可称为集合比较子查询。
多行子查询使用的时候常结合多行比较操作符,如下:
| 操作符 | 含义 |
|---|---|
| IN | 等于列表中的任意一个 |
| ANY | 需要和单行比较操作符一起使用,和子查询返回的某一个值比较 |
| ALL | 需要和单行比较操作符一起使用,和子查询返回的所有值比较 |
| SOME | 实际上是ANY的别名,作用相同,一般常使用ANY |
5.1,多行子查询实战
需求一:找出所有工资等于任意部门最低工资的员工(无论其所属部门)
SQL语句如下:
SELECT employee_id, last_name
FROM employees
WHERE salary IN(SELECT MIN(salary)FROM employeesGROUP BY department_id);
运行结果如下:

需求二:返回
其它job_id中比job_id为‘IT_PROG’部门任意一个工资低的员工的员工号、姓名、job_id 以及salary
SQL代码如下:
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < ANY (SELECT salaryFROM employeesWHERE job_id = 'IT_PROG');
运行结果如下:
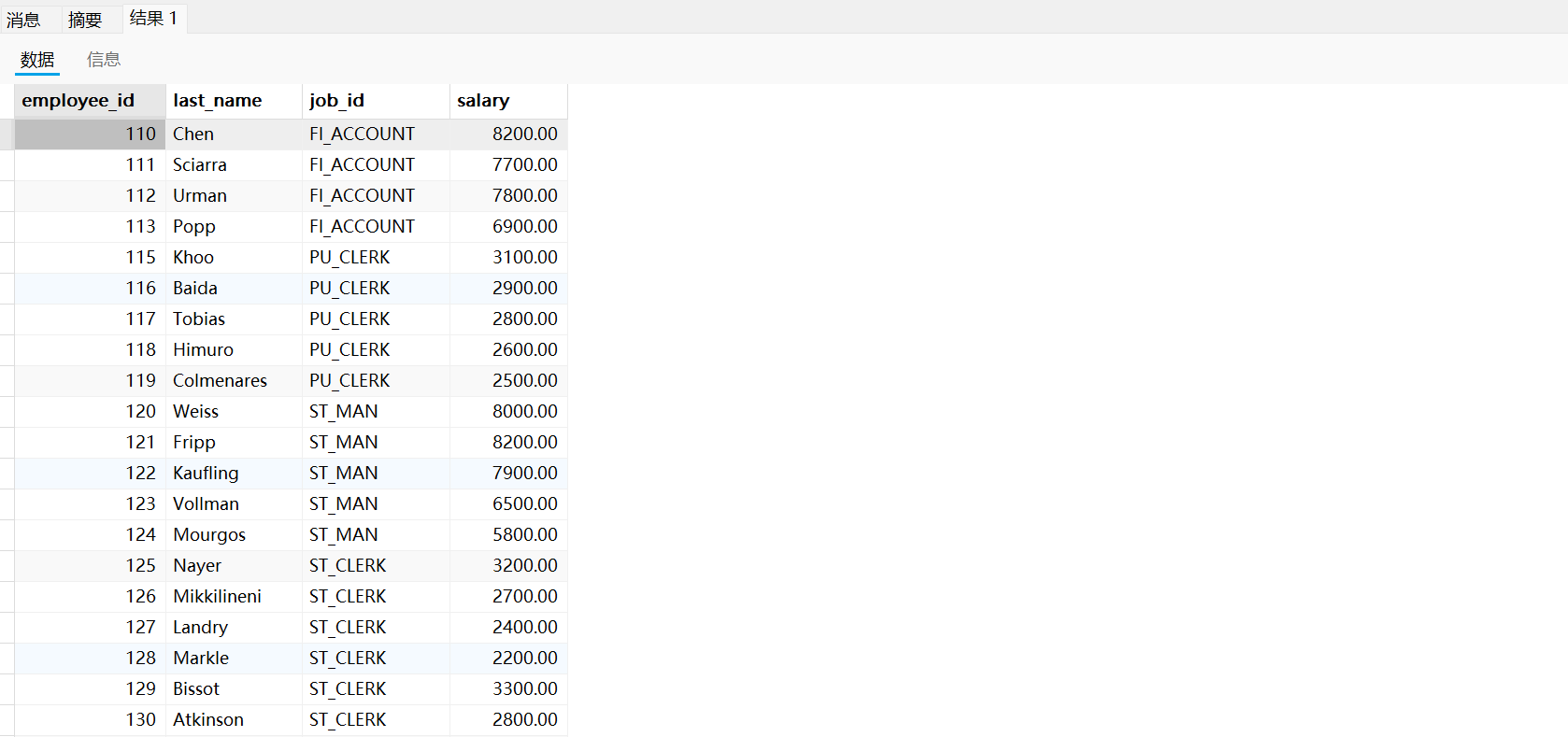
需求三:返回
其它job_id中比job_id为 ‘IT_PROG’ 部门所有工资低的员工的员工号、姓名、job_id 以及salary
SQL代码如下:
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < ALL (SELECT salaryFROM employeesWHERE job_id = 'IT_PROG');
运行结果如下:
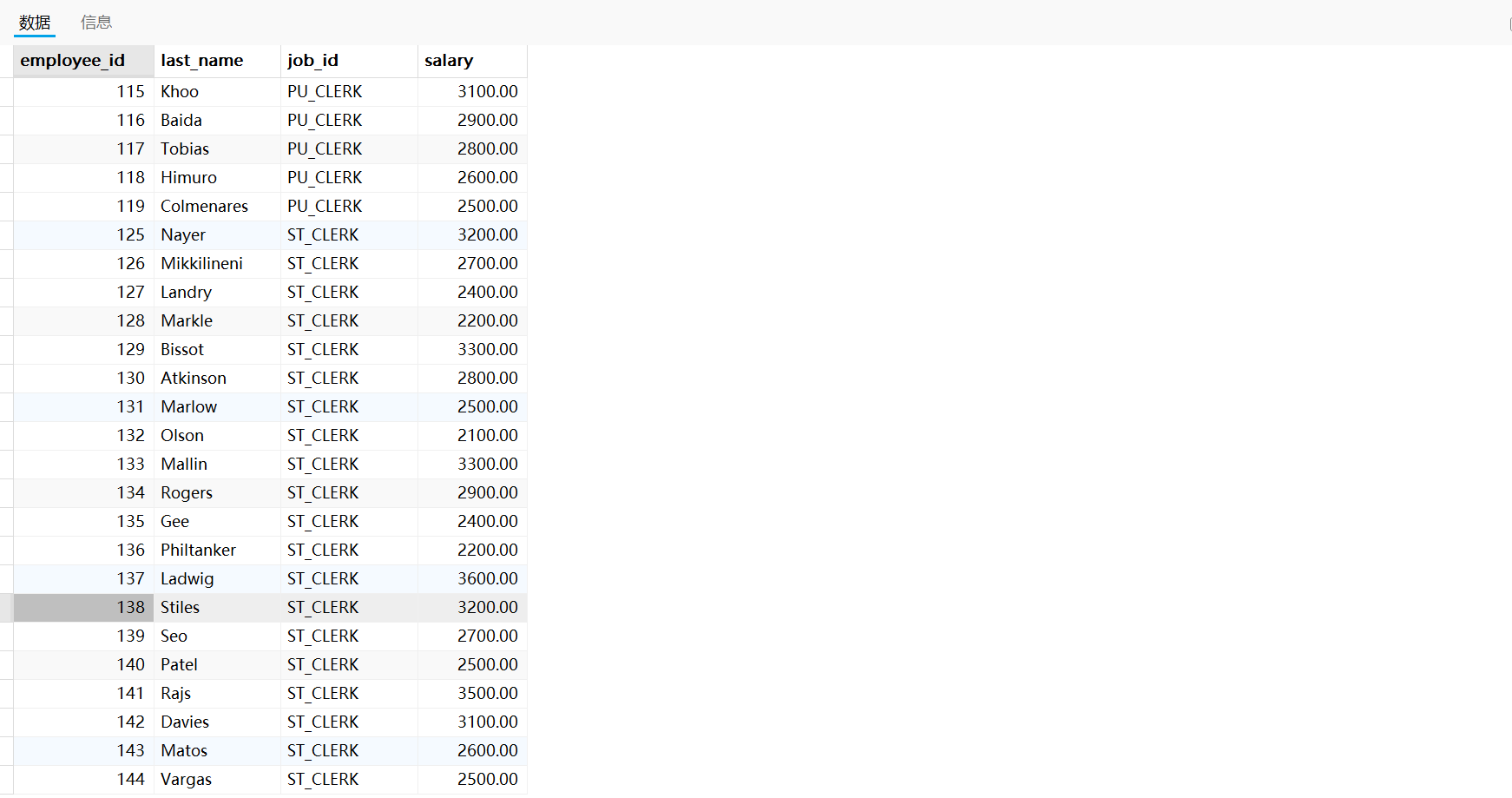
需求四:查询平均工资最低的部门 id
实现方式一: 先求各部门的最低平均工资,然后看哪个部门的最低平均工资等于此最低平均工资
求最低平均工资时的错误SQL示例:
SELECT MIN(AVG(salary))
FROM employees
GROUP BY department_id;
运行报错,错误原因:MySQL中不支持聚合函数的嵌套使用。
针对此需求,我们可以发散思维:可以将查询出的各个部门的平均工资结果形成一张中间表t1,平均工资是其中的一个字段,然后对此字段再次做聚合操作(求Min)。
求最低平均工资的正确SQL示例如下:
SELECT MIN(avg_sal)
FROM (SELECT AVG(salary) avg_salFROM employeesGROUP BY department_id
) t_dept_avg_sal # 注意此处需要给表起别名,否则报错此时 avg_sal 相当于 t_dept_avg_sal 表的一个字段,巧妙地避开了聚合函数的嵌套。
因此,实现此需求的完整SQL代码如下:
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (SELECT MIN(avg_sal)FROM (SELECT AVG(salary) avg_salFROM employeesGROUP BY department_id) t_dept_avg_sal # 注意此处需要给表起别名,否则报错
)
运行结果如下:

实现方式二: 看作多行查询,借助ALL操作符实现
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) <= ALL( SELECT AVG(salary) avg_salFROM employeesGROUP BY department_id)
运行结果如下:

5.2,多行子查询的空值问题
多行子查询的空值问题使开发中尤其需要注意的问题。子查询返回的结果如果有NULL值时需要特别注意!!!
接下来我们结合具体场景分析空值问题。
需求一:查出employees表中所有的管理者的last_name
SQL语句如下:
SELECT last_name
FROM employees
WHERE employee_id IN (SELECT manager_idFROM employees);
运行结果如下:

需求二:查出employees表中所有的
非管理者的last_name
运行如下SQL语句:
SELECT last_name
FROM employees
WHERE employee_id NOT IN (SELECT manager_idFROM employees);
发现查出的结果为空:

错误分析:原因是子查询返回的结果存在NULL值,则会导致最终返回空。
正确的SQL语句是:
SELECT last_name
FROM employees
WHERE employee_id NOT IN (SELECT manager_idFROM employeesWHERE manager_id IS NOT NULL);
运行结果如下:

6,相关子查询和不相关子查询
根据子查询是否被执行多次可以分为相关子查询和不相关子查询。我们前面讲到的场景都是不相关子查询,因此本节我们重点理解相关子查询。
6.1,相关子查询的执行流程
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为相关子查询。
相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询。
6.2,不相关子查询与相关子查询对比
需求一:查询员工中工资大于
公司平均工资的员工的last_name,salary和其department_id
SQL语句如下:
SELECT last_name,salary,department_id
FROM employees
WHERE salary > (SELECT AVG(salary)FROM employees);
子查询执行一次,所以此案例为不相关子查询。
需求二:查询员工中工资大于
本部门平均工资的员工的last_name,salary和其department_id
SQL语句如下:
SELECT last_name,salary,department_id
FROM employees e1
WHERE salary > (SELECT AVG(salary)FROM employees e2WHERE department_id = e1.`department_id`);
显然 每执行一次外部查询,子查询都要重新计算一次 ,所以此案例为相关子查询。
此外,需求二还有另外一种实现方式:在FROM中声明子查询
SELECT e.last_name,e.salary,e.department_id
FROM employees e,(SELECT department_id,AVG(salary) avg_salFROM employeesGROUP BY department_id) t_dept_avg_sal
WHERE e.department_id = t_dept_avg_sal.department_id
AND e.salary > t_dept_avg_sal.avg_sal
第二种实现方式不属于相关子查询,但是也可以达到同样的效果。
6.3,在ORDER BY 中使用关联子查询
需求:查询员工的id,salary,按照department_name 升序排序
SELECT employee_id,salary
FROM employees e
ORDER BY (SELECT department_nameFROM departments dWHERE e.`department_id` = d.`department_id`) ASC;
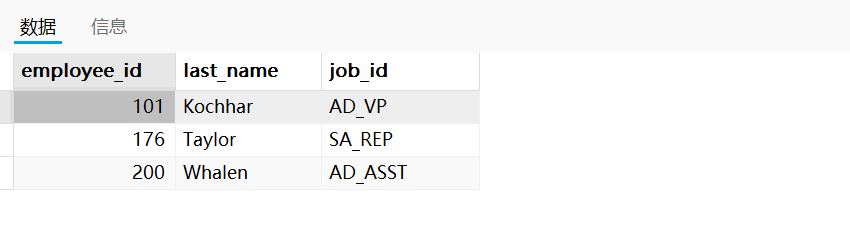
6.4,案例进阶
需求:若employees表中employee_id与job_history表(岗位变动信息表)中employee_id相同的数目不小于2,输出这些相同id的员工的employee_id,last_name和其job_id
SQL语句如下:
SELECT employee_id,last_name,job_id
FROM employees e
WHERE 2 <= (SELECT COUNT(*)FROM job_history jWHERE e.`employee_id` = j.`employee_id`)
运行结果如下:
6.5,EXISTS 与 NOT EXISTS关键字
关联子查询通常也会和
EXISTS关键字一起来使用,用来检查在子查询中是否存在满足条件的行。
- 如果在子查询中不存在满足条件的行:
- 条件返回 FALSE
- 继续在子查询中查找
- 如果在子查询中存在满足条件的行:
- 不在子查询中继续查找
- 条件返回 TRUE
NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
需求一:查询公司管理者的employee_id,last_name,job_id,department_id信息
实现方式一:自连接
# 去重保证每个管理者只出现一次
SELECT DISTINCT mgr.employee_id,mgr.last_name,mgr.job_id,mgr.department_id
FROM employees emp JOIN employees mgr
ON emp.manager_id = mgr.employee_id;
实现方式二 :子查询
SELECT employee_id,last_name,job_id,department_id
FROM employees
WHERE employee_id IN ( # 先查出所有管理者的manager_idSELECT DISTINCT manager_idFROM employees);
实现方式三:使用EXISTS
SELECT employee_id,last_name,job_id,department_id
FROM employees e1
# 逐个记录执行,没有符合条件的就返回FALSE,有符合条件的就返回TRUE
WHERE EXISTS (SELECT *FROM employees e2WHERE e1.`employee_id` = e2.`manager_id`);
需求二:查询departments表中,不存在于employees表中的部门的department_id和department_name
SQL代码如下:
SELECT department_id,department_name
FROM departments d
# 对于传入子查询的每一个记录,都去employees 看有无对应的记录,有则返回TRUE
WHERE NOT EXISTS (SELECT *FROM employees eWHERE d.`department_id` = e.`department_id`);
需求三 :在employees中增加一个department_name字段,数据为员工对应的部门名称
SQL语句如下:
UPDATE employees e
SET department_name = (SELECT department_name FROM departments dWHERE e.department_id = d.department_id);
需求四:删除表employees中,其与emp_history表皆有的数据
DELETE FROM employees e
WHERE employee_id in (SELECT employee_idFROM emp_history WHERE employee_id = e.employee_id);
7,子查询和自连接效率
回顾需求: 谁的工资比Abel的高?
#方式1:自连接
SELECT e2.last_name,e2.salary
FROM employees e1,employees e2
WHERE e1.last_name = 'Abel'
AND e1.`salary` < e2.`salary`
#方式2:子查询
SELECT last_name,salary
FROM employees
WHERE salary > (SELECT salaryFROM employeesWHERE last_name = 'Abel');
问题: 以上两种方式有好坏之分吗?
解答: 自连接方式好!
题目中可以使用子查询,也可以使用自连接。
一般情况建议使用自连接,因为在许多 DBMS 的处理过程中,对于自连接的处理速度要比子查询快得多。
可以这样理解:子查询实际上是通过未知表进行查询后的条件判断,而自连接是通过已知的自身数据表进行条件判断,因此在大部分 DBMS 中都对自连接处理进行了优化。





)
)




算法详解与应用)


)



项目)
