这里先仅仅关注 C++ 层的介绍,python DSL 以后再说。
在 ubuntu 22.04 X64 中,RTX 5080
1. 环境搭建
1.1 安装 cuda
1.2 下载源码
git clone https://github.com/NVIDIA/cutlass.git1.3 编译
mkdir build/
cmake .. -DCUTLASS_NVCC_ARCHS="120" -DCMAKE_BUILD_TYPE="Debug"
make -j20如果内存不是太大,cpu核心不是太多,那么可以使用 make -j8 等较小的编译线程数量。
查看生成的文件:
2. 调试一个示例
cutlass/examples/cute/tutorial/sgemm_1.cu
2.1 先跑起来
build/examples/cute/tutorial$ ./cute_tutorial_sgemm_1 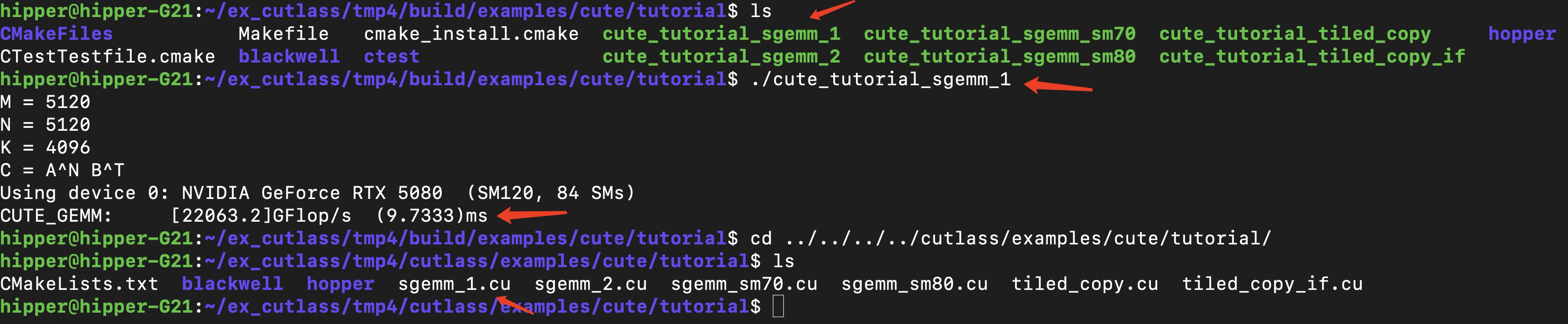
2.2 调试一下
启动调试器,启动程序,进入 main 函数:
build/examples/cute/tutorial$ cuda-gdb ./cute_tutorial_sgemm_1
(cuda-gdb) layout src
(cuda-gdb) start
接下来定义了矩阵A、B、C:
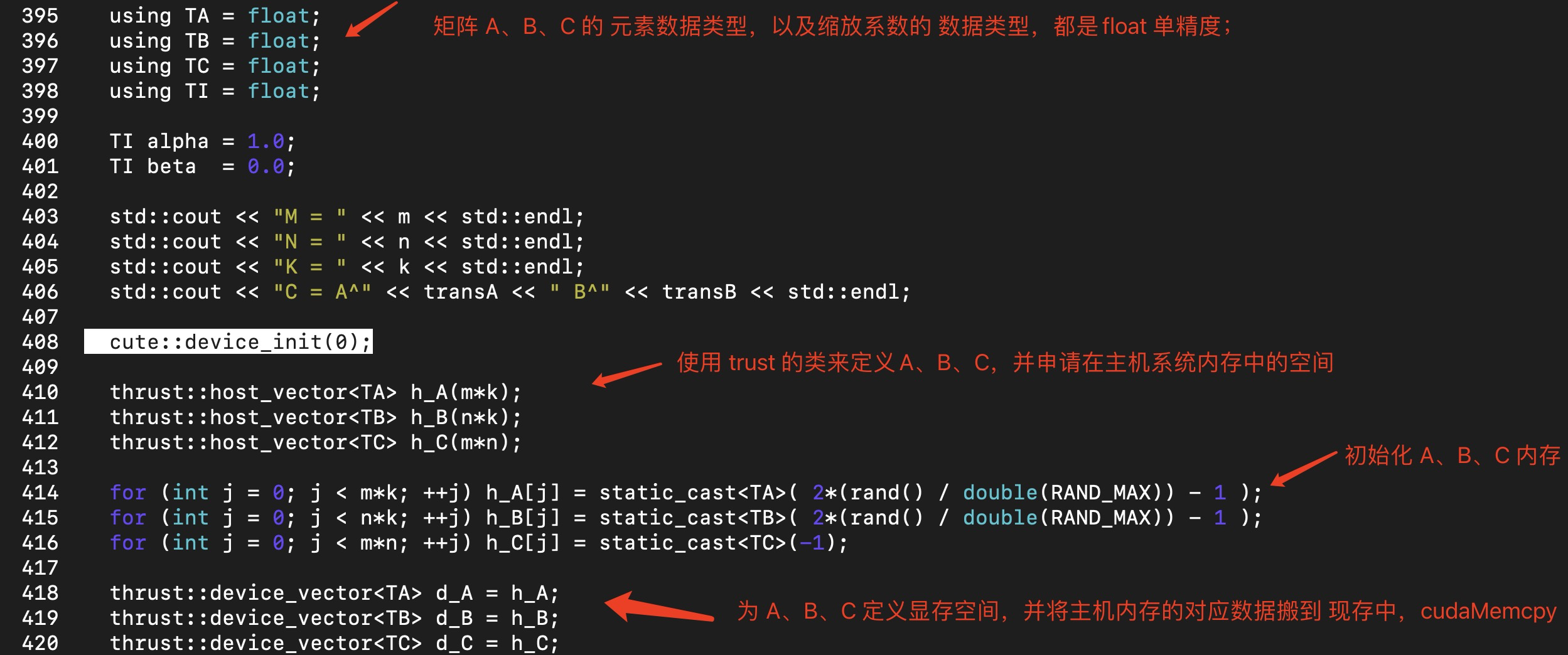
其中 初始化 gpu 的函数 cute::device_init(0) 的代码内容如下:
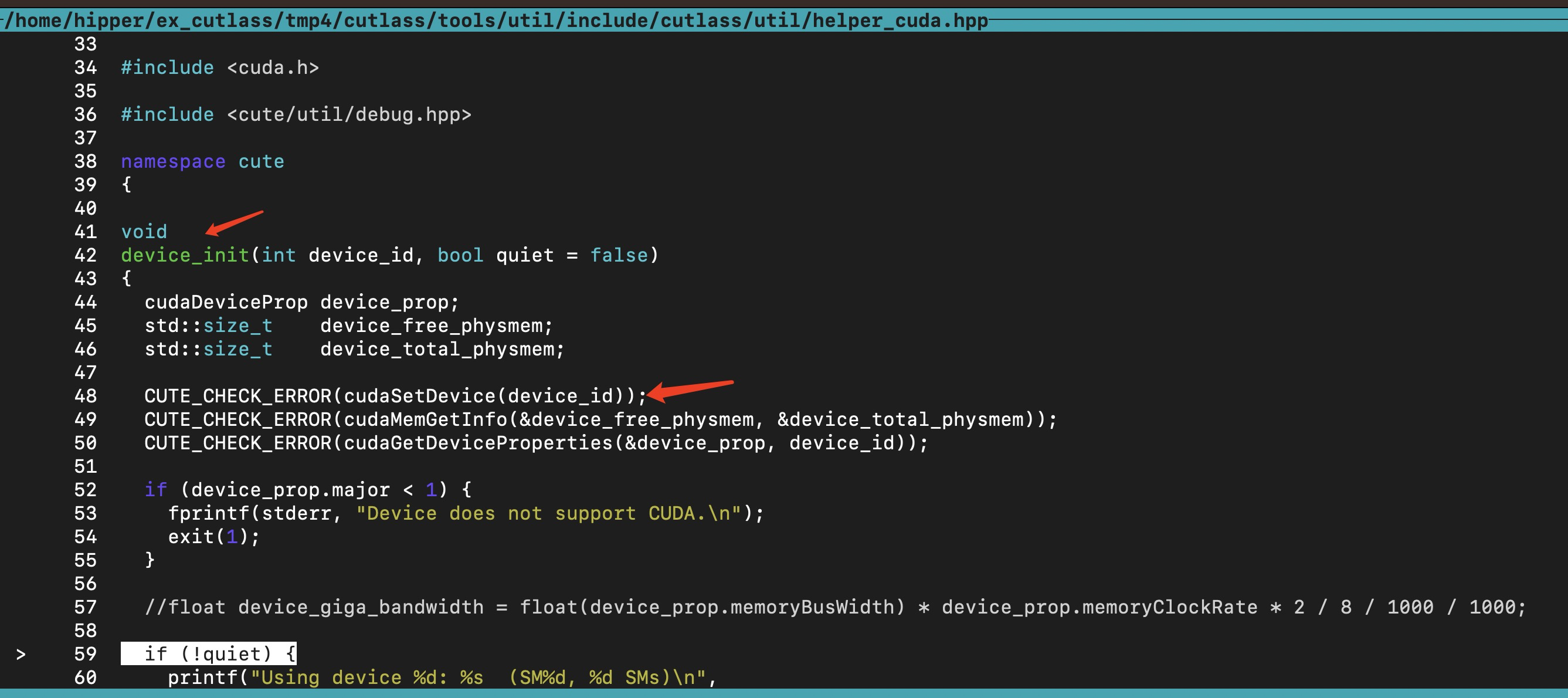
其中,thrust::host_vector<> () 是使用 c++ new表达式申请的内存。
而 thrust::device_vector<> () 是使用 cudaMalloc 申请的显存:
赌一把:
(cuda-gdb) break cudaMalloc
(cuda-gdb) continue
(cuda-gdb) bt可以看到停在了 cudaMalloc() 函数上。
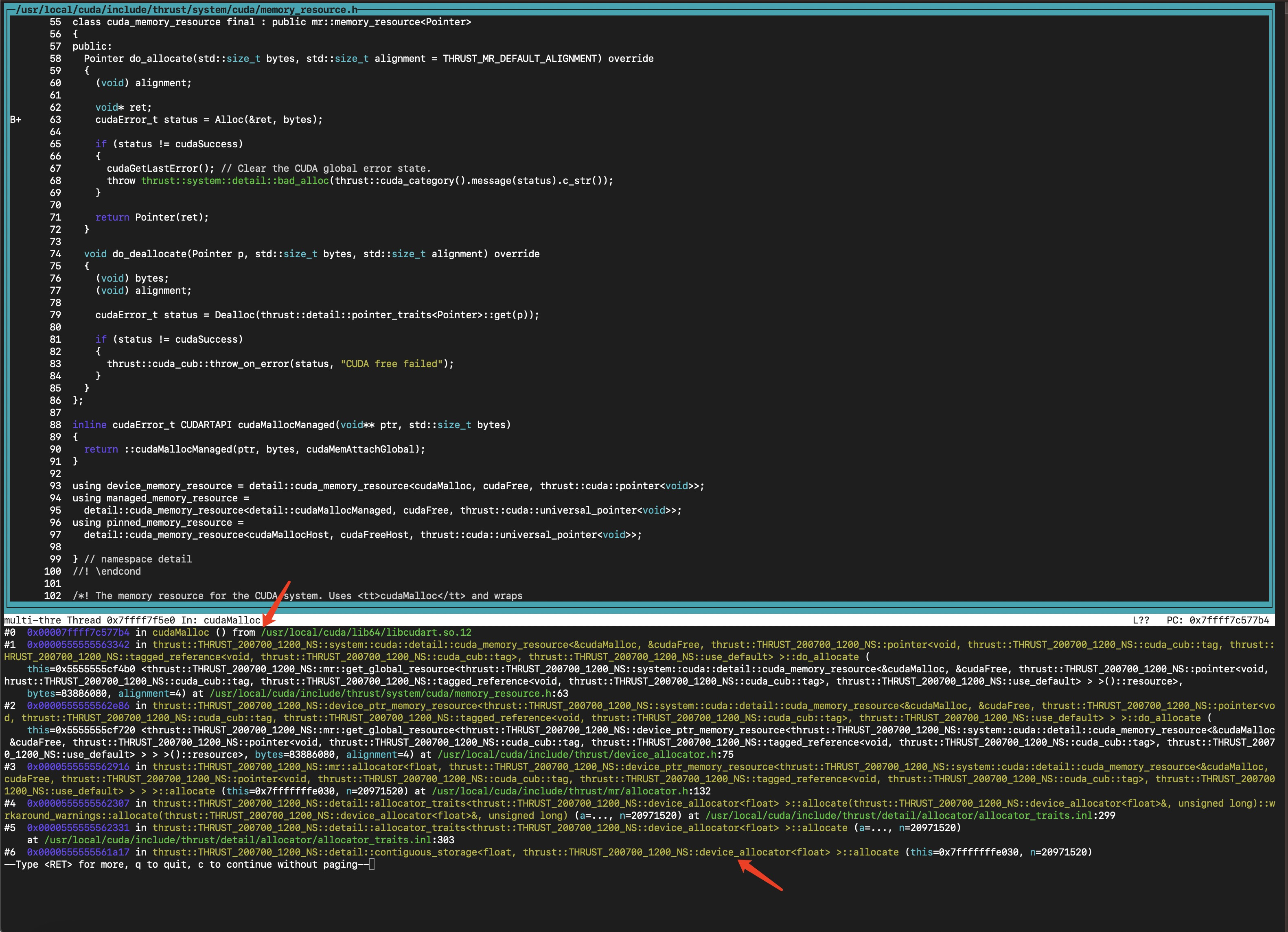
会调用到 gemm_device():
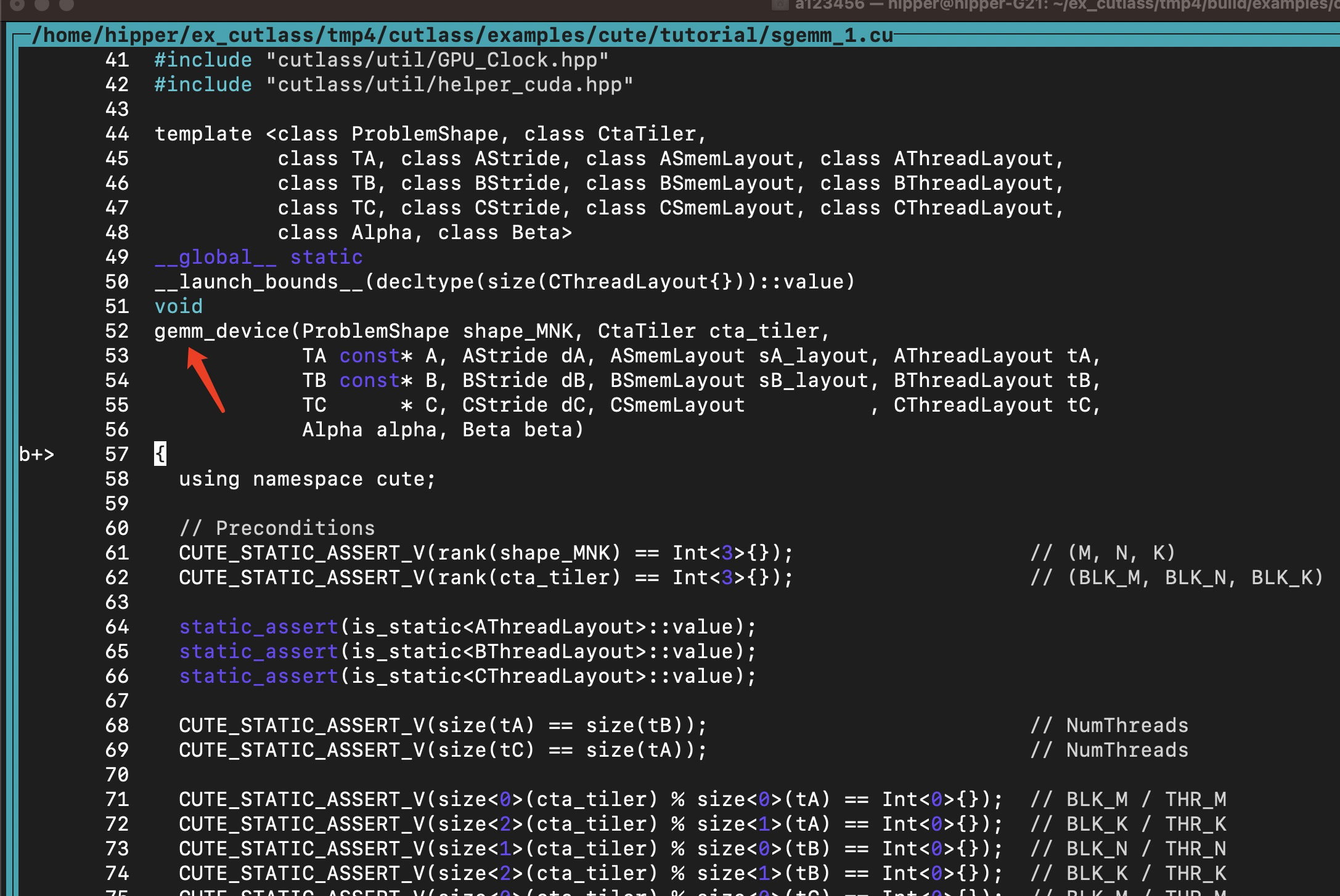
接下来分析一下这个 kernel 的实现:
这个kernel 代码比较长,我们一段段地分析:
template <class ProblemShape, class CtaTiler,class TA, class AStride, class ASmemLayout, class AThreadLayout,class TB, class BStride, class BSmemLayout, class BThreadLayout,class TC, class CStride, class CSmemLayout, class CThreadLayout,class Alpha, class Beta>
__global__ static
__launch_bounds__(decltype(size(CThreadLayout{}))::value)
void
gemm_device(ProblemShape shape_MNK, CtaTiler cta_tiler,TA const* A, AStride dA, ASmemLayout sA_layout, AThreadLayout tA,TB const* B, BStride dB, BSmemLayout sB_layout, BThreadLayout tB,TC * C, CStride dC, CSmemLayout , CThreadLayout tC,Alpha alpha, Beta beta)
{using namespace cute;// PreconditionsCUTE_STATIC_ASSERT_V(rank(shape_MNK) == Int<3>{}); // (M, N, K)CUTE_STATIC_ASSERT_V(rank(cta_tiler) == Int<3>{}); // (BLK_M, BLK_N, BLK_K)static_assert(is_static<AThreadLayout>::value);static_assert(is_static<BThreadLayout>::value);static_assert(is_static<CThreadLayout>::value);CUTE_STATIC_ASSERT_V(size(tA) == size(tB)); // NumThreadsCUTE_STATIC_ASSERT_V(size(tC) == size(tA)); // NumThreadsCUTE_STATIC_ASSERT_V(size<0>(cta_tiler) % size<0>(tA) == Int<0>{}); // BLK_M / THR_MCUTE_STATIC_ASSERT_V(size<2>(cta_tiler) % size<1>(tA) == Int<0>{}); // BLK_K / THR_KCUTE_STATIC_ASSERT_V(size<1>(cta_tiler) % size<0>(tB) == Int<0>{}); // BLK_N / THR_NCUTE_STATIC_ASSERT_V(size<2>(cta_tiler) % size<1>(tB) == Int<0>{}); // BLK_K / THR_KCUTE_STATIC_ASSERT_V(size<0>(cta_tiler) % size<0>(tC) == Int<0>{}); // BLK_M / THR_MCUTE_STATIC_ASSERT_V(size<1>(cta_tiler) % size<1>(tC) == Int<0>{}); // BLK_N / THR_Nstatic_assert(is_static<ASmemLayout>::value);static_assert(is_static<BSmemLayout>::value);static_assert(is_static<CSmemLayout>::value);CUTE_STATIC_ASSERT_V(size<0>(ASmemLayout{}) == size<0>(cta_tiler)); // BLK_MCUTE_STATIC_ASSERT_V(size<0>(CSmemLayout{}) == size<0>(cta_tiler)); // BLK_MCUTE_STATIC_ASSERT_V(size<0>(BSmemLayout{}) == size<1>(cta_tiler)); // BLK_NCUTE_STATIC_ASSERT_V(size<1>(CSmemLayout{}) == size<1>(cta_tiler)); // BLK_NCUTE_STATIC_ASSERT_V(size<1>(ASmemLayout{}) == size<2>(cta_tiler)); // BLK_KCUTE_STATIC_ASSERT_V(size<1>(BSmemLayout{}) == size<2>(cta_tiler)); // BLK_KCUTE_STATIC_ASSERT_V(congruent(select<0,2>(shape_MNK), dA)); // dA strides for shape MKCUTE_STATIC_ASSERT_V(congruent(select<1,2>(shape_MNK), dB)); // dB strides for shape NKCUTE_STATIC_ASSERT_V(congruent(select<0,1>(shape_MNK), dC)); // dC strides for shape MNCUTE_STATIC_ASSERT_V(rank(shape_MNK) == Int<3>{});
为 ProblemShape shape_MNK 类型,
rank
未完待续
。。。。





:维护更多信息)

)



)
:基本概念)

)
字段、属性、索引器、常量)

![[Windows] WPS官宣 64位正式版(12.1.0.22525)全新发布!](http://pic.xiahunao.cn/[Windows] WPS官宣 64位正式版(12.1.0.22525)全新发布!)

时间序列预测算法matlab仿真)