文章目录
- 引言:AI大模型的新时代
- 一、模型架构与技术生态对比
- 1. 文心大模型4.5系列
- 2. DeepSeek
- 3. 通义千问(Qwen 3.0)
- 二、语言理解能力实测
- 2.1 情感分析测试
- 2.1.1 文心一言的表现
- 2.1.2 DeepSeek的表现
- 2.1.3 Qwen 3.0的表现
- 2.1.4 测试结果分析
- 2.2 文本分类测试
- 2.2.1 文心一言的表现
- 2.2.2 DeepSeek的表现
- 2.2.3 Qwen 3.0的表现
- 2.2.4 测试结果分析
- 2.3 语义匹配测试
- 2.3.1 文心一言的表现
- 2.3.2 DeepSeek的表现
- 2.3.3 Qwen 3.0的表现
- 2.3.4 测试结果分析
- 三、逻辑推理能力实测
- 3.1 因果关系推断
- 文心一言的表现
- DeepSeek的表现
- Qwen 3.0的表现
- 测试结果分析
- 四、知识问答能力实测
- 4.1 开放域问答
- 文心一言的表现
- DeepSeek的表现
- Qwen 3.0的表现
- 测试结果分析
- 4.2 专业领域问答(医学)
- 文心一言的表现
- DeepSeek的表现
- Qwen 3.0的表现
- 测试结果分析
- 4.3 专业领域问答(法律)
- 文心一言的表现
- DeepSeek的表现
- Qwen 3.0的表现
- 测试结果分析
- 五、代码能力分析
- 5.1 复杂数据结构实现
- 5.1.1 文心一言的表现
- 5.1.2 DeepSeek的表现
- 5.1.3 Qwen3的表现
- 5.1.4 客观结论
- 总结

起来轻松玩转文心大模型吧一文心大模型免费下载地址:点击跳转
引言:AI大模型的新时代
近年来,国内AI大模型领域可谓百花齐放,从百度的文心大模型到阿里的通义千问(Qwen),再到新兴的DeepSeek模型,这些产品在语言理解、逻辑推理、知识问答等方面都有着不俗的表现。作为一名长期关注AI技术发展的研究者,我决定通过实际测试来客观对比这几款主流模型的能力表现,为大家提供一个相对公正的参考。
| 模型 | 市场份额(全球/中国) | 主要优势领域 | 开源情况 | 典型应用场景 | 用户/开发者生态 |
|---|---|---|---|---|---|
| 文心一言 | 中国11.5% | 中文语义理解、医疗/教育垂类 | 2025年7月开源 | 政务、教育、创意写作 | 日均调用15亿次,企业智能体平台 |
| DeepSeek | 全球6.58% | 数学推理、代码生成、低成本部署 | 开源(MoE架构) | 编程开发、复杂逻辑任务、学术研究 | 月活1.19亿,海外用户占60% |
| Qwen | 全球1.6% | 多模态、电商场景、云服务整合 | 部分开源 | 企业服务、金融客服、AI绘画 | 阿里云生态集成,开发者API降价 |
一、模型架构与技术生态对比
1. 文心大模型4.5系列
文心大模型4.5系列作为百度最新推出的开源模型,基于优化后的Transformer架构,在语言理解和生成方面表现突出。其技术生态依托百度飞桨(PaddlePaddle)深度学习框架,在知识问答、代码生成、文本摘要等多个场景都有不错的应用效果。
2. DeepSeek
DeepSeek是近期备受关注的国产大模型,主打高效推理与知识问答能力。虽然参数量相对较小,但采用了轻量化架构设计,在推理速度上有明显优势,特别是在医学知识问答等特定领域表现亮眼。
3. 通义千问(Qwen 3.0)
Qwen 3.0是阿里推出的企业级大模型,在多模态能力(文本、图像、视频)和逻辑推理准确性方面下了不少功夫。依托阿里云的技术生态,在大规模分布式部署方面有着天然优势。

二、语言理解能力实测
2.1 情感分析测试
为了测试各模型的情感分析能力,我设计了一个包含不同情感倾向的用户评论分析任务:
“以下是一些用户评论,请分析每条评论的情感倾向(积极、消极、中性):
A:这个产品真的太棒了!
B:服务态度很差,下次不会来了。
C:价格还可以接受,但质量一般。”
2.1.1 文心一言的表现
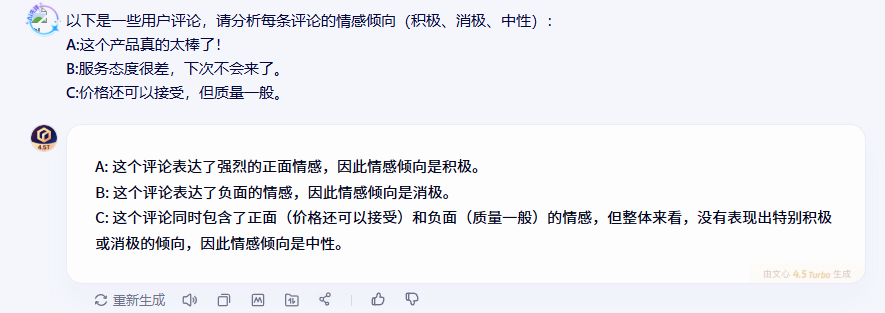
2.1.2 DeepSeek的表现

2.1.3 Qwen 3.0的表现

2.1.4 测试结果分析
从测试结果来看,三个模型在情感分析任务上都表现得相当不错。文心一言在处理情感分析时显得特别细致,不仅能准确识别明显的积极情感(“太棒了”)和消极情感(“服务态度很差”),对于那种既有正面又有负面评价的复杂情感评论,也能通过综合分析给出合理的中性判断。
值得一提的是,文心一言的回答逻辑非常清晰,能够快速抓住评论中的关键情感词汇,这对于需要处理大量用户反馈的场景来说是很实用的。无论是社交媒体监测还是电商评论分析,这种准确而高效的情感识别能力都能提供不错的支持。
2.2 文本分类测试
接下来测试的是文本分类能力,这在实际应用中非常常见:
“以下是几段文本,请将它们分类到’科技’、'娱乐’或’体育’类别:
A:新款智能手机发布,搭载最新芯片。
B:电影《流浪地球2》票房突破50亿。
C:世界杯决赛即将开赛。”
2.2.1 文心一言的表现
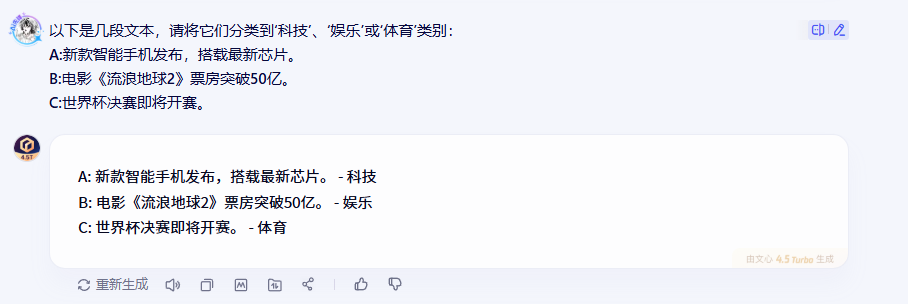
2.2.2 DeepSeek的表现

2.2.3 Qwen 3.0的表现

2.2.4 测试结果分析
在文本分类这个环节,三个模型的表现可以说是不分伯仲,都准确地将文本归类到了正确的类别。不过,从回答的详细程度来看,各有特色:文心一言的回答简洁明了,直击要点;DeepSeek通过关键词强化了分类依据;而Qwen3则提供了更详细的分类理由。
这种一致性说明了现在主流AI模型在基础的文本分类任务上已经相当成熟,基本能够满足日常应用需求。
2.3 语义匹配测试
语义匹配是考验模型深层语言理解能力的重要指标:
“以下两句话是否表达相同的含义?
A:我喜欢在周末看书。
B:周末的时候,我喜欢阅读书籍。”
2.3.1 文心一言的表现
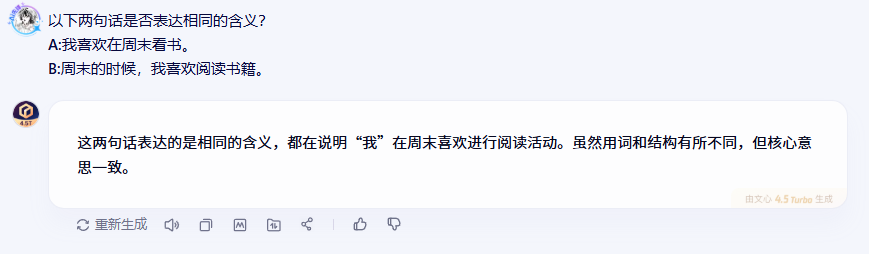
2.3.2 DeepSeek的表现

2.3.3 Qwen 3.0的表现
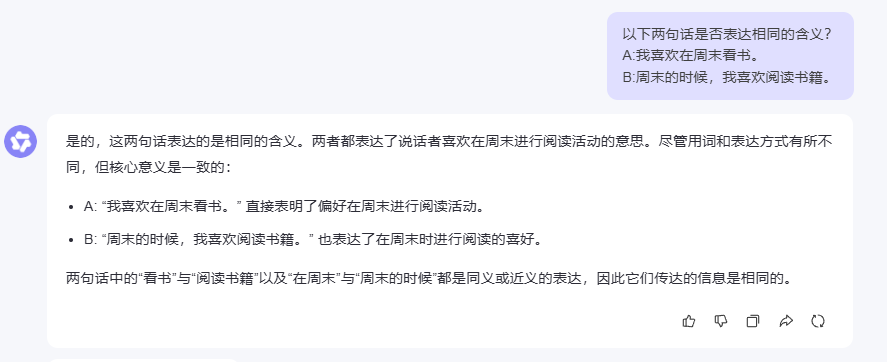
2.3.4 测试结果分析
在语义匹配测试中,三个模型都准确判断出两句话表达的是相同含义,这说明它们都具备了不错的语义理解能力。特别值得注意的是,虽然两句话在用词和句式上有所不同,但模型们都能透过表面差异抓住核心语义。
DeepSeek的分析比较有意思,它还特别指出了两句话在语言风格上的细微差别(口语化vs正式),这种细致的观察对于一些对语言风格有要求的应用场景很有价值。
三、逻辑推理能力实测
3.1 因果关系推断
逻辑推理能力是区分AI模型智能水平的重要指标,我设计了一个因果关系推断的测试:
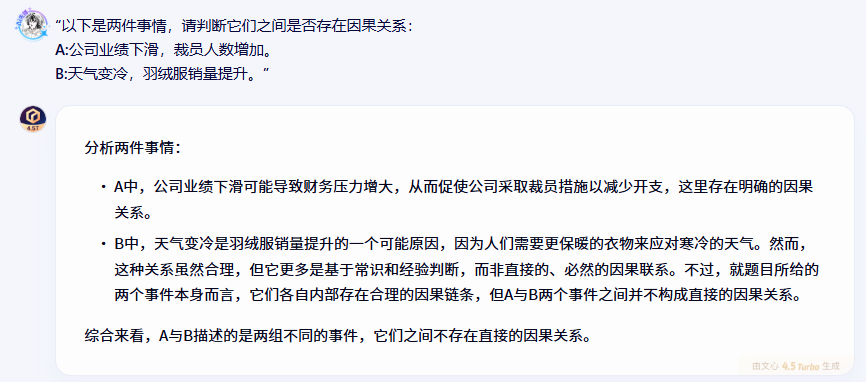
“以下是两件事情,请判断它们之间是否存在因果关系:
A:公司业绩下滑,裁员人数增加。
B:天气变冷,羽绒服销量提升。”
文心一言的表现
DeepSeek的表现

Qwen 3.0的表现

测试结果分析
在因果关系推断这个比较考验逻辑思维的任务上,文心一言的表现让人印象深刻。它不仅准确识别了事件内部的因果关系,还对因果链条的合理性进行了深入分析。比如在分析"天气变冷与羽绒服销量提升"这个关系时,文心一言指出这种因果关系虽然符合常识,但更多是基于经验判断而非必然联系,这种细致的逻辑分析很有价值。
更重要的是,文心一言明确指出了两组事件之间的独立性,避免了可能的逻辑混淆。这种严谨的逻辑思维对于需要进行复杂推理的应用场景来说是很重要的。
四、知识问答能力实测
4.1 开放域问答
知识问答是大模型的基础能力之一,我选择了两个不同领域的问题进行测试:
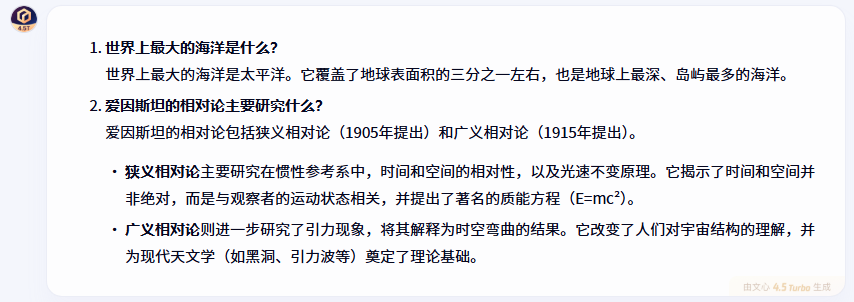
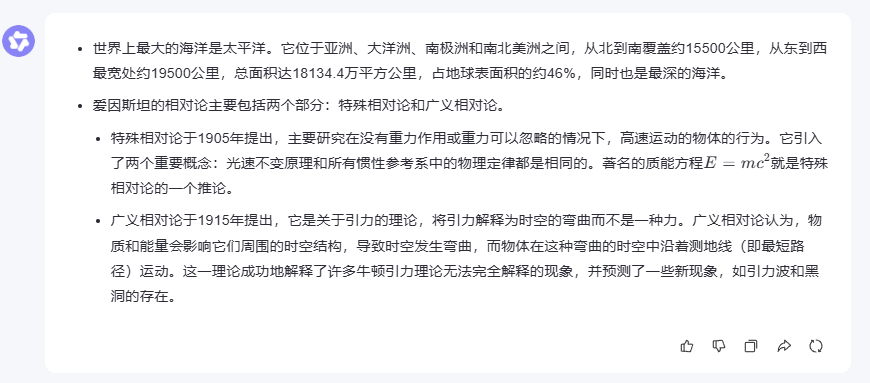
“以下是一些开放性问题,请回答:
世界上最大的海洋是什么?
爱因斯坦的相对论主要研究什么?”
文心一言的表现
DeepSeek的表现

Qwen 3.0的表现
测试结果分析
在开放域问答测试中,三个模型都展现了扎实的知识储备。对于地理常识问题,大家都能准确回答出"太平洋",并补充了相关的数据信息。
在解释爱因斯坦相对论这个相对复杂的科学概念时,文心一言的回答特别全面,不仅涵盖了狭义相对论和广义相对论的核心内容,还提到了质能方程(E=mc²)和时空弯曲等重要概念,同时分析了相对论对现代天文学的影响。这种既有深度又有广度的回答方式,对于需要获取全面信息的用户来说很有帮助。
4.2 专业领域问答(医学)
专业领域的问答能力是考验模型知识深度的重要指标,我选择了医学领域的问题:
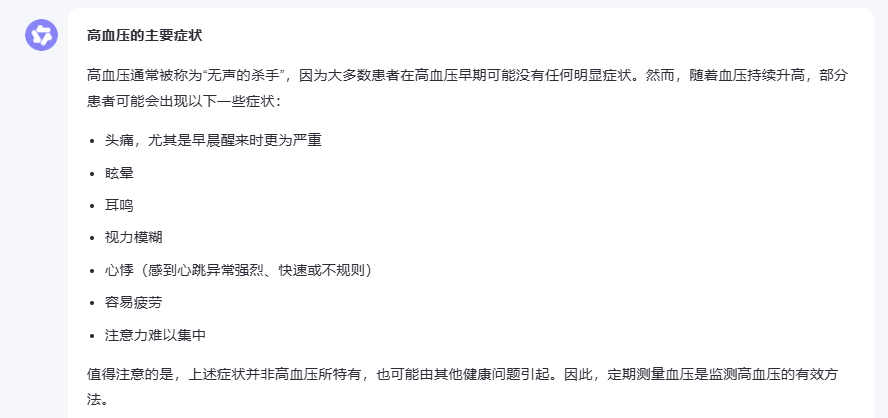
“以下是一些医学相关问题,请回答:
高血压的主要症状有哪些?
糖尿病患者应该避免哪些食物?”
文心一言的表现


DeepSeek的表现


Qwen 3.0的表现

测试结果分析
在医学专业问答这个环节,文心一言展现出了相当专业的水准。对于高血压症状的回答,它不仅列举了常见症状,还特别强调了定期测量血压的重要性,并提醒患者在出现严重症状时需要立即就医,这种关注患者健康的细致态度很值得肯定。
在糖尿病饮食建议方面,文心一言的回答更是全面细致,不仅详细列举了需要避免的食物类别,还提供了具体的饮食建议,包括选择低GI食物、增加膳食纤维摄入等实用建议,最后还建议患者咨询专业医生制定个性化方案,体现了对患者实际需求的关注。
4.3 专业领域问答(法律)
法律领域的问答对准确性要求很高,我选择了两个常见的法律问题:
“以下是一些法律相关问题,请回答:
什么是合同违约?
未成年人犯罪是否需要承担刑事责任?”
文心一言的表现


DeepSeek的表现


Qwen 3.0的表现

测试结果分析
在法律专业问答中,文心一言再次展现了其专业性和全面性。对于合同违约的解释,它不仅引用了《民法典》的具体规定,还详细分析了违约的构成条件、类型分类和法律后果,通过具体示例帮助理解,这种理论结合实践的回答方式很有实用价值。
在未成年人犯罪刑事责任这个复杂问题上,文心一言通过年龄分层详细解释了不同情况下的责任承担规则,还特别提到了"教育为主、惩罚为辅"的立法目的,体现了对法律精神的深刻理解。
五、代码能力分析
5.1 复杂数据结构实现
“请使用Java实现一个LRU(最近最少使用)缓存,支持get和put操作,要求时间复杂度为O(1)。”
5.1.1 文心一言的表现
import java.util.HashMap;
import java.util.Map;public class LRUCache<K, V> {// 定义双向链表节点class DLinkedNode {K key;V value;DLinkedNode prev;DLinkedNode next;}// 哈希表,用于快速定位节点private Map<K, DLinkedNode> cache = new HashMap<>();private int size; // 当前缓存大小private int capacity; // 缓存容量private DLinkedNode head, tail; // 虚拟头尾节点public LRUCache(int capacity) {this.size = 0;this.capacity = capacity;// 使用虚拟头尾节点简化边界条件处理head = new DLinkedNode();tail = new DLinkedNode();head.next = tail;tail.prev = head;}public V get(K key) {DLinkedNode node = cache.get(key);if (node == null) {return null; // key不存在}// 移动到链表头部表示最近使用moveToHead(node);return node.value;}public void put(K key, V value) {DLinkedNode node = cache.get(key);if (node == null) {// key不存在,创建新节点DLinkedNode newNode = new DLinkedNode();newNode.key = key;newNode.value = value;// 添加到哈希表cache.put(key, newNode);// 添加到链表头部addToHead(newNode);size++;if (size > capacity) {// 超出容量,移除尾部节点DLinkedNode tail = removeTail();cache.remove(tail.key);size--;}} else {// key存在,更新值并移动到头部node.value = value;moveToHead(node);}}// 添加节点到链表头部private void addToHead(DLinkedNode node) {node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;}// 移除节点private void removeNode(DLinkedNode node) {node.prev.next = node.next;node.next.prev = node.prev;}// 移动节点到链表头部private void moveToHead(DLinkedNode node) {removeNode(node);addToHead(node);}// 移除链表尾部节点private DLinkedNode removeTail() {DLinkedNode res = tail.prev;removeNode(res);return res;}public static void main(String[] args) {LRUCache<Integer, String> cache = new LRUCache<>(2);cache.put(1, "One");cache.put(2, "Two");System.out.println(cache.get(1)); // 返回 "One"cache.put(3, "Three"); // 该操作会使得key 2作废System.out.println(cache.get(2)); // 返回 nullcache.put(4, "Four"); // 该操作会使得key 1作废System.out.println(cache.get(1)); // 返回 nullSystem.out.println(cache.get(3)); // 返回 "Three"System.out.println(cache.get(4)); // 返回 "Four"}
}
5.1.2 DeepSeek的表现
import java.util.HashMap;
import java.util.Map;public class LRUCache<K, V> {// 双向链表节点class Node {K key;V value;Node prev;Node next;Node(K key, V value) {this.key = key;this.value = value;}}private final int capacity;private final Map<K, Node> cache;private final Node head; // 虚拟头节点private final Node tail; // 虚拟尾节点public LRUCache(int capacity) {this.capacity = capacity;this.cache = new HashMap<>();this.head = new Node(null, null);this.tail = new Node(null, null);head.next = tail;tail.prev = head;}public V get(K key) {Node node = cache.get(key);if (node == null) {return null;}// 移动到链表头部表示最近使用moveToHead(node);return node.value;}public void put(K key, V value) {Node node = cache.get(key);if (node != null) {// 如果key已存在,更新value并移动到头部node.value = value;moveToHead(node);} else {// 如果key不存在,创建新节点Node newNode = new Node(key, value);cache.put(key, newNode);addToHead(newNode);// 如果超过容量,移除最久未使用的节点if (cache.size() > capacity) {Node tailNode = removeTail();cache.remove(tailNode.key);}}}// 将节点添加到链表头部private void addToHead(Node node) {node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;}// 从链表中移除节点private void removeNode(Node node) {node.prev.next = node.next;node.next.prev = node.prev;}// 将节点移动到链表头部private void moveToHead(Node node) {removeNode(node);addToHead(node);}// 移除链表尾部节点(最久未使用)private Node removeTail() {Node res = tail.prev;removeNode(res);return res;}// 测试用例public static void main(String[] args) {LRUCache<Integer, String> cache = new LRUCache<>(2);cache.put(1, "One");cache.put(2, "Two");System.out.println(cache.get(1)); // 返回 "One"cache.put(3, "Three"); // 该操作会使得key=2作废System.out.println(cache.get(2)); // 返回 nullcache.put(4, "Four"); // 该操作会使得key=1作废System.out.println(cache.get(1)); // 返回 nullSystem.out.println(cache.get(3)); // 返回 "Three"System.out.println(cache.get(4)); // 返回 "Four"}
}
5.1.3 Qwen3的表现
import java.util.HashMap;public class LRUCache {// 双向链表节点private static class Node {int key;int value;Node prev;Node next;public Node(int key, int value) {this.key = key;this.value = value;}}private final int capacity;private final HashMap<Integer, Node> cache;private final Node head; // 最近使用的节点在头部private final Node tail; // 最久使用的节点在尾部public LRUCache(int capacity) {this.capacity = capacity;this.cache = new HashMap<>();this.head = new Node(0, 0); // 哨兵节点this.tail = new Node(0, 0); // 哨兵节点head.next = tail;tail.prev = head;}// 获取缓存public int get(int key) {if (cache.containsKey(key)) {Node node = cache.get(key);remove(node); // 从链表中移除insert(node); // 插到头部return node.value;} else {return -1;}}// 插入或更新缓存public void put(int key, int value) {if (cache.containsKey(key)) {remove(cache.get(key)); // 先移除旧节点}if (cache.size() == capacity) {removeLRU(); // 删除最近最少使用的节点(尾部前一个节点)}Node newNode = new Node(key, value);insert(newNode); // 插入新节点到头部}// 将节点插入到链表头部private void insert(Node node) {cache.put(node.key, node);node.next = head.next;node.prev = head;head.next.prev = node;head.next = node;}// 从链表中移除节点private void remove(Node node) {cache.remove(node.key);node.prev.next = node.next;node.next.prev = node.prev;}// 删除尾部前一个节点(即最近最少使用的节点)private void removeLRU() {Node lru = tail.prev;remove(lru);}// 测试代码public static void main(String[] args) {LRUCache cache = new LRUCache(2);cache.put(1, 1);cache.put(2, 2);System.out.println(cache.get(1)); // 返回 1cache.put(3, 3); // evict key 2System.out.println(cache.get(2)); // 返回 -1cache.put(4, 4); // evict key 1System.out.println(cache.get(1)); // 返回 -1System.out.println(cache.get(3)); // 返回 3System.out.println(cache.get(4)); // 返回 4}
}
5.1.4 客观结论
文心一言在代码质量、设计完整性和工程实践方面表现最佳,特别是在泛型支持和注释规范性上有明显优势。
DeepSeek提供了功能完整且代码质量良好的实现,是一个可靠的选择。
Qwen3基础功能实现,采用了经典的双向链表+哈希表设计,针对整数类型优化,代码简洁直观。
总体而言,三个模型都展现了不错的代码生成能力,文心一言在综合表现上略胜一筹。
总结
通过这次全面的对比测试,我发现每个模型都有自己的特色和优势。DeepSeek在数学推理和代码生成方面表现突出,Qwen3在多模态能力和企业服务方面有着不错的表现。
而文心一言在这次测试中给我留下了深刻印象,特别是在语言理解的细致度、逻辑推理的严谨性,以及专业领域知识的全面性方面都表现得相当出色。无论是情感分析的准确性,还是医学、法律等专业领域问答的深度和实用性,都展现出了不错的水准。
当然,AI技术发展日新月异,每个模型都在不断迭代优化。这次测试只是一个阶段性的对比,未来随着技术的进步,相信这些模型都会有更好的表现。对于用户来说,选择哪个模型主要还是要看具体的应用场景和需求。
)





![P13014 [GESP202506 五级] 最大公因数](http://pic.xiahunao.cn/P13014 [GESP202506 五级] 最大公因数)

:map 的实现与哈希冲突)






std::true_type/false_type)



)