集成学习与随机森林学习笔记
0 序言
本文将系统介绍Bagging、Boosting两种集成学习方法及随机森林算法,涵盖其原理、过程、参数等内容。通过学习,你能理解两种方法的区别,掌握随机森林的随机含义、算法步骤、优点及关键参数使用,明确各知识点的逻辑关联,本篇将主要围绕原理方面展开,下篇文章再具体用一个项目来加深巩固本文提到的随机森林算法。
1 Bagging(套袋法)
1.1 算法过程
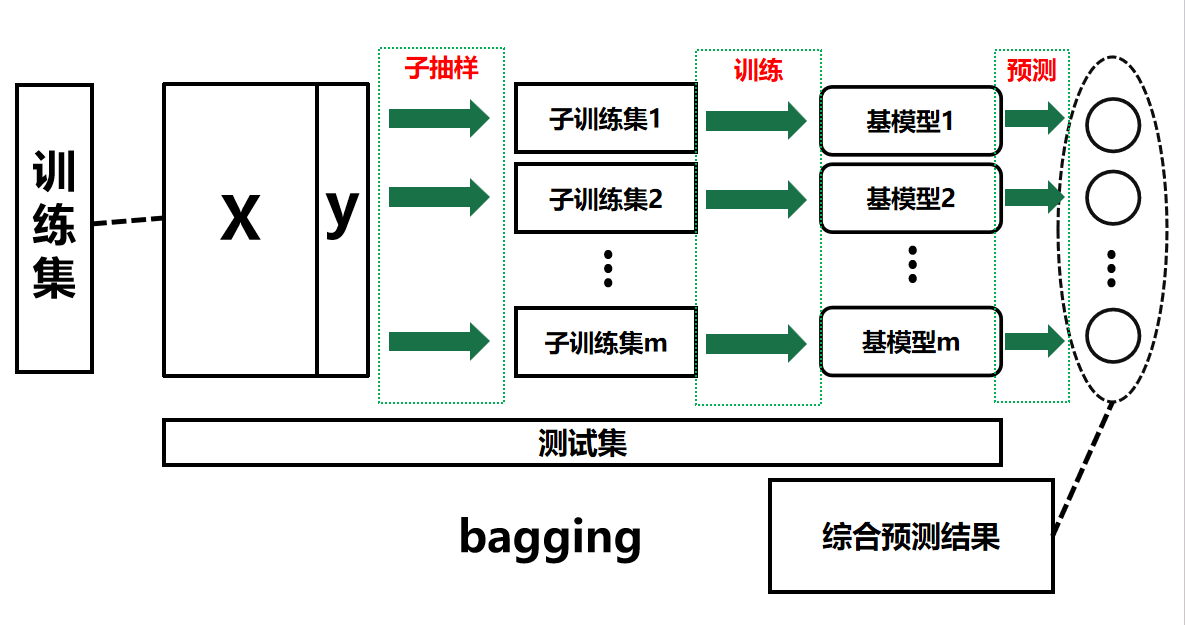
样本抽取:采用Bootstrapping方法从原始样本集随机抽取n个训练样本,经过k轮抽取,得到k个相互独立且元素可重复的训练集。这样做是为了获得不同的训练数据,为后续构建多样化模型做准备。
举个例子:假设原始样本集是学生成绩数据集,包含 100 名学生的语文、数学、英语成绩(即(n = 100) ),要进行(k = 5)轮抽取。
每一轮都从这 100 条数据里,有放回地随机选 100 条,就像抽奖箱里有 100 个写着学生成绩的球,每次摸一个记录后再放回去,摸 100 次组成一轮的训练集。
5 轮后,得到 5 个训练集,每个训练集都是 100 条数据,数据可能有重复,也可能有遗漏,它们相互独立,为后续训练不同模型提供多样数据。
模型训练:使用得到的k个训练集分别训练k个模型,这里的模型可以是决策树、KNN等。通过多个模型的训练,能够综合不同模型的优势。
举个例子:接着上面学生成绩的例子,用 5 个训练集,分别训练 5 个决策树模型。
每个决策树依据各自训练集里的成绩数据,学习如何根据语文、数学成绩去判断学生的英语成绩等级。因为训练集不同,每个决策树学到的判断逻辑会有差异,后续就能综合这些差异模型的能力。
结果判定:在分类问题中,通过投票表决来确定最终结果,且所有模型的重要性相同。这是因为各模型是基于不同训练集独立训练的,地位平等。
举个例子:还是学生成绩分类任务,5 个决策树模型分别对一名新学生的成绩输出判断。
比如模型 1 认为是A 等,模型 2 认为是B 等,模型 3 认为是A 等,模型 4 认为是A 等,模型 5 认为是B 等 。
统计投票,A 等得 3 票,B 等得 2 票,最终就判定该学生英语等级为A 等,每个模型一票,公平表决。
所以,根据以上的例子,我们放到我们的训练集中去体现这个思想,
那就可以参照下图进行理解。
2 Boosting(提升法)
2.1 算法过程
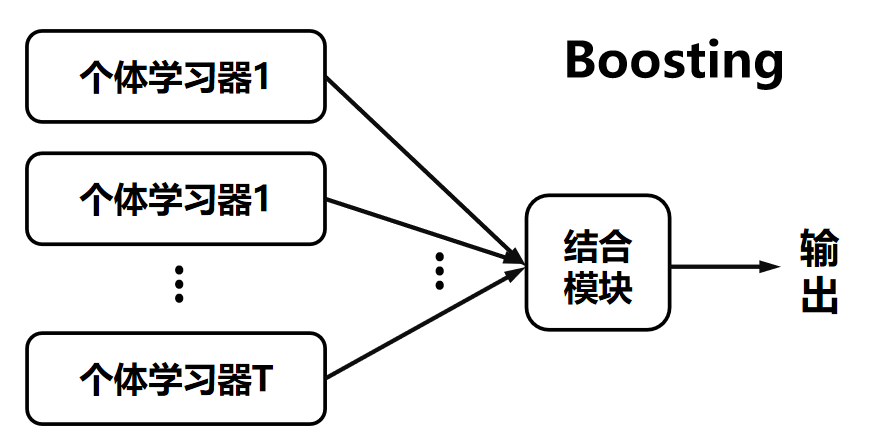
样本权重:为训练集样本建立权值wiw_iwi,权值表示对样本的关注度,对于误分类概率高的样本会加大其权值。这样可以让模型更关注难以分类的样本,提升模型性能。
模型组合:迭代生成弱分类器,然后通过一定策略进行组合,例如AdaBoost算法会给弱分类器进行加权线性组合,其中误差小的弱分类器权值更大。通过这种方式,能让性能好的弱分类器在最终结果中发挥更大作用。
可以参考下面图片辅助理解。
3 Bagging与Boosting的主要区别
| 对比项 | Bagging | Boosting |
|---|---|---|
| 样本选择 | Bootstrap随机有放回抽样 | 训练集不变,改变样本权重 |
| 样本权重 | 均匀取样,权重相等 | 依错误率调整,错误率高的样本权重越大 |
| 预测函数权重 | 所有预测函数权重相等 | 误差小的预测函数权重越大 |
| 并行计算 | 预测函数可并行生成 | 需按顺序迭代生成 |
4 随机森林
4.1 基本概念
随机森林由Bagging + 决策树组成,其产生是为了解决决策树泛化能力弱的问题。
通过利用Bagging方法产生不同的数据集来生成多棵决策树,从而提升预测准确率,但会损失部分直观解释性。
4.2 随机含义
样本随机:使用Bootstrap方法从样本集中随机选取n个样本用于训练每棵树。这样能保证每棵树的训练样本具有差异性。
特征随机:从所有属性中随机选取k个,然后选择最佳分割属性来构建CART决策树(也可使用SVM等其他模型)。通过特征的随机选择,进一步增加了树的多样性。
4.3 算法步骤
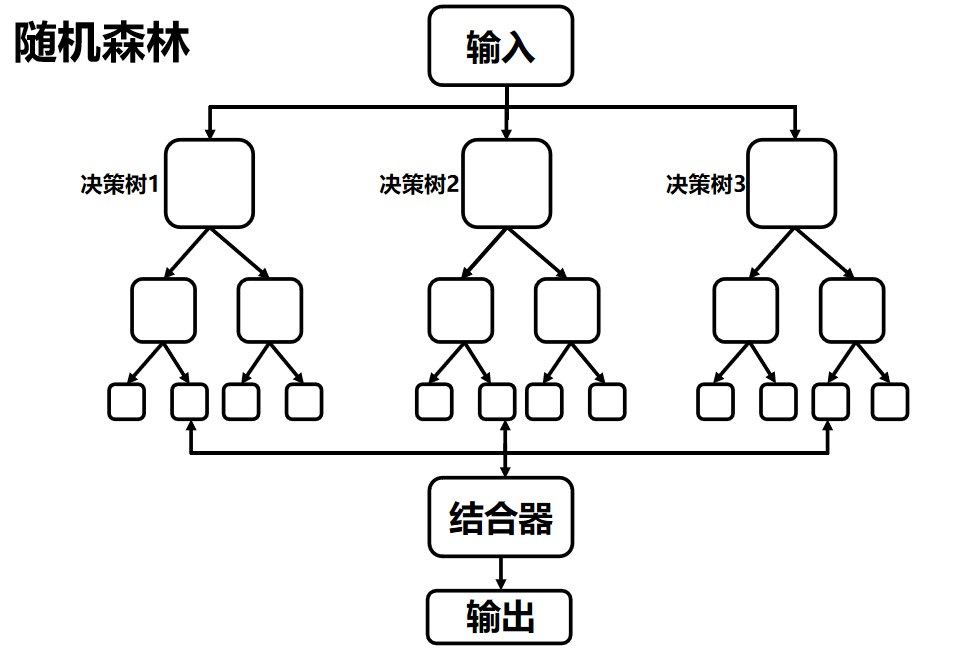
重复样本随机、特征随机的步骤m次,构建m棵CART决策树。
多棵树通过投票表决(如一票否决、少数服从多数、加权多数等方式)来决定分类结果。
具体流程可以参考下图:
4.4 优点
- 由于只选择部分样本和特征进行训练,能够
避免模型过拟合。 - 随机选择样本与特征的方式,使得模型的
抗噪能力好、性能稳定。 - 可以处理高维数据,无需进行特征选择。
- 适合进行
并行计算,且实现简单。
4.5 流程可视化与局限性
4.5.1 流程可视化理解
可见下图,随机森林先预设超参数(如树的数量、层数 ),再通过随机采样(样本 + 特征双随机 )训练多棵决策树,最后整合结果(分类求众数、回归求均值 )。
流程清晰体现多棵树并行训练→结合器统一输出的模式。
4.5.2 局限性
模型存在泛化与复杂度矛盾:虽通过随机化提升泛化,但整体过于General,遇到极复杂、超出训练规律的样本,因单棵树能力有限,集成后也难精准处理,即 起点高(基于 Bagging 和决策树已有基础)但天花板低(依赖基础组件能力,难突破单个弱学习器上限) 。
在实际应用中,需结合场景权衡。
简单规律任务表现好,超复杂、需深度挖掘的场景,可能需更复杂模型配合。
4.6 sklearn函数及参数
4.6.1 关键参数max_features
Auto/None:使用所有特征。
sqrt:每棵子树使用总特征数的平方根个特征。
log2:max_features=log2(n_features)max\_features = log2(n\_features)max_features=log2(n_features)。
0.2:子树使用20%的特征,也可采用0.x格式来考察不同特征占比的作用。
增加max_features理论上可能因为节点选择更多样而提升模型性能,这是随机森林的优势之一,但会降低单树的多样性,并且会使算法速度下降,因此需要平衡选择。
4.6.2 核心参数解析
n_estimators
- 含义:子树的数量。
- 影响:数量越多,模型性能通常更好,但代码运行速度会变慢。需要选择处理器能够承受的高值,默认值为10,一般至少设置为100,以让预测更优更稳定。
max_depth
- 设置树的最大深度,默认值为
None,此时叶节点要么是单一类别,要么达到min_samples_split条件。
min_samples_split
- 分割内部节点所需的最少样本数量,默认值为2。
min_samples_leaf
- 叶子节点包含的最少样本数,默认值为1。
bootstrap
- 控制是否进行有放回抽样,默认值为
True。
min_impurity_decrease
- 规则:只有当分裂后杂质度的减少效果高于该值(默认值为0)时,节点才会分裂。
min_weight_fraction_leaf
- 条件:节点对应的实例数与总样本数的比值≥该值(默认值为0)时,才能成为叶子节点。
max_leaf_nodes
- 默认值为
None,此时会以最优优先方式生成树,优先选择杂质少(纯度高)的叶子节点。
min_impurity_split
- 阈值:当节点的杂质度高于此值时则进行分裂,低于此值则成为叶子节点,用于控制树的增长。
criterion
"gini"(默认值,用于计算基尼不纯度)或"entropy"(用于计算信息增益),用于选择最优节点。
splitter
"best"(默认值,选择不纯度最大的属性)或"random"(随机选择属性),建议使用默认值。
n_jobs
- 指定引擎可用的处理器数量,
-1表示无限制,1表示使用1个,输入数字n则使用n个,这对于并行的Bagging等集成算法很重要。
random_state
- 使结果可复现,当确定该值后,在参数和训练数据不变的情况下,结果相同。
4.6 程序示例
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
data = load_iris()
X = data.data
y = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建随机森林分类器
rf = RandomForestClassifier(n_estimators=100, max_features='sqrt', random_state=42)# 训练模型
rf.fit(X_train, y_train)# 预测
y_pred = rf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率:{accuracy}")
5 小结
本文先介绍了Bagging和Boosting两种集成学习方法的算法过程及主要区别,我们可以了解到它们在样本选择、权重处理等方面的不同。随后重点讲解了随机森林,包括其基本概念、随机的两层含义、算法步骤、优点以及sklearn中相关参数的解析,并给出了程序示例。
通过学习,我们能清楚随机森林是如何结合Bagging和决策树的优势,以及如何根据实际需求调整参数来构建模型,为解决分类等问题提供了有效的方法和思路。
下文我们将具体通过一个项目来将这些原理应用进去。
:map 的实现与哈希冲突)






std::true_type/false_type)



)





)
)
