温馨提示:
本篇文章已同步至"AI专题精讲" ABQ-LLM:用于大语言模型的任意比特量化推理加速
摘要
大语言模型(LLMs)在自然语言处理任务中取得了革命性的进展。然而,其实际应用受到巨大的内存与计算开销的限制。训练后量化(Post-Training Quantization,PTQ)被认为是一种有效的LLM推理加速方法。尽管PTQ在LLM模型压缩中越来越受欢迎,但其部署仍面临两大挑战:
首先,低比特量化会导致性能下降;其次,受限于GPU中整数计算单元类型的限制,不同精度下的量化矩阵运算无法被有效加速。
为了解决这些问题,我们提出了一种新颖的任意比特量化算法与推理框架 —— ABQ-LLM(Arbitrary-Bit Quantized LLM)。它不仅在各种量化设置下实现了更优的性能,还支持在GPU上进行高效的任意精度量化推理。
ABQ-LLM 引入了以下几个关键创新:
- 分布校正方法:针对Transformer模块中的权重和激活值全量化所引起的分布偏移问题,提出校正方法以提升低比特精度下的性能;
- 比特平衡策略(Bit Balance Strategy):用于缓解在极低比特(如2-bit)下由于分布不对称带来的性能退化;
- 创新的量化加速框架:基于 BTC(二进制TensorCore)等价操作,重新构建任意精度组合下的量化矩阵乘法,不再依赖于INT4/INT8计算单元,从而使每个组件的比特宽度收益都能转化为实际的加速收益,并在混合精度设置下最大化性能(如W6A6、W2A8)。
在LLaMA-7B模型的W2*A8量化配置下,ABQ-LLM在WikiText2数据集上取得了 7.59的困惑度(相比AffineQuant的9.76降低了2.17)。与SmoothQuant相比,ABQ-LLM实现了 1.6倍的推理加速和 2.7倍的显存压缩率。
1 引言
近年来的大语言模型(LLMs)(如 Bubeck et al., 2023;Touvron et al., 2023a,b)在多个自然语言任务上展现了惊人的能力,包括推理(Clark et al., 2019, 2018)、认知处理(Xu et al., 2023a;Hardy et al., 2023)和对话生成(Hu et al., 2023)。然而,这些模型普遍拥有庞大的参数规模,带来了极高的显存占用与带宽瓶颈(Zheng et al., 2024;Kim et al., 2023)。
训练后量化(PTQ) 是一种能够显著减少计算与存储开销的有效手段。该技术通过将LLMs中的权重与激活值从高精度浮点数转换为低精度整数进行存储,并在推理过程中使用高效的整数矩阵乘法算子,从而加速模型推理。
目前,LLMs 中约 80% 的计算与参数访问 都集中在 通用矩阵乘法(GEMM) 和 向量乘法(GEMV) 操作上。尤其在自回归解码阶段,GEMM操作基本退化为GEMV(因为是逐token生成),因此GEMV的计算效率和内存访问效率直接决定了LLM推理的速度与能耗。
为了提升GEMM/GEMV的内存访问效率,LLM推理中通常采用量化推理策略。目前主流方法是仅对权重量化,即内核基于反量化后的FP16值进行计算。然而在高并发场景下,这种方法的性能提升十分有限。
为了进一步增强量化推理的性能,业界开始推进 权重与激活值的全量化(WA全量化),以减少激活内存访问并充分利用GPU上的量化核算能力(如NVIDIA提供的量化核)。但目前该领域的实际应用仍存在多项挑战:
- NVIDIA仅支持有限数量的硬件加速指令(Lin et al., 2024a;Ashkboos et al., 2024;Zhao et al., 2024),限制了量化算法的设计空间;
- 非主流组合(如W4A8、W2A4)需要在计算过程中转换为W8A8或W4A4,从而降低效率(Lin et al., 2024b);
- 由于GEMV操作的存在,在batch size小于8时需进行额外padding,导致W4A4与W8A8量化在小batch推理下效率低下;
- 最后,在极低比特(如W2A8、W2A6)下,WA全量化模型在精度上仍面临较大挑战。
ABQ-LLM 针对上述挑战提出解决方案,在保持精度的同时,实现了真正意义上的任意比特量化推理加速。
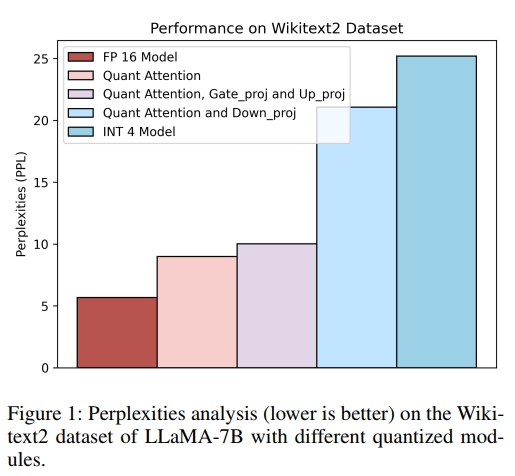
在本文中,我们提出了一种面向训练后量化(Post-Training Quantization, PTQ)的新型量化框架,称为 ABQ-LLM。通过分析transformer模块内部各组成部分的量化敏感性(见图1)以及量化前后的注意力图变化(见图2),我们发现 down proj线性层 和 注意力图(attention map)对量化特别敏感。
为此,我们提出了以下两项关键技术:
- 双余弦相似度分布校正(double cosine similarity distribution correction);
- 注意力图分布自举(attention map distribution bootstrap),
以对down proj的输出 进行校正,从而精确调整量化常数,恢复在低比特(如 W6A6、W4A4 和 W2A8)下的模型性能。
此外,我们还对低比特量化下的性能下降进行了深入分析,并通过提出比特平衡策略(bit balance strategy),解决了诸如INT2这类低比特表示中常见的不对称损失问题(asymmetric loss),显著提升了INT2配置下的量化性能。
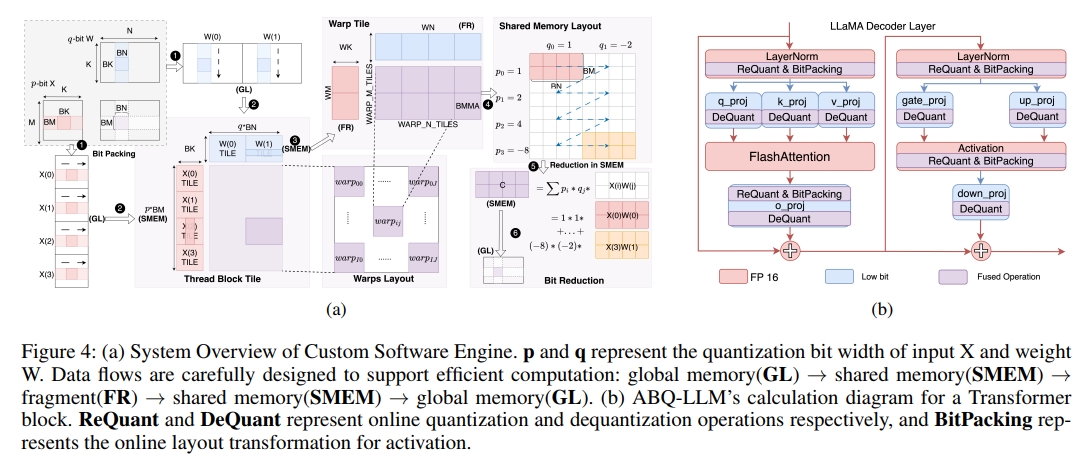
最后,我们实现了一款基于BTC(二进制TensorCore)等价计算的定制化软件引擎,首次在LLM领域实现了真正意义上的量化自由(quantization freedom)。该引擎:
- 摆脱了INT4/INT8计算单元的限制;
- 有效规避了GEMV计算瓶颈;
- 在LLaMA-7B的W2A8配置下,相较于SmoothQuant实现了1.6倍的最终推理加速,并达到了SOTA级别的性能表现。
我们的贡献如下:
- 我们提出了一种新颖的块级分布校正与补偿方案,用于缓解因权重与激活值全量化所引起的分布偏移,从而显著提升低比特下的模型性能;
- 我们解决了INT2等低比特量化中的不对称损失问题,通过比特平衡策略显著改善了INT2配置下的量化效果,提升了模型在极低比特精度下的表现;
- 我们设计并实现了首个在LLM领域实现量化自由的软件引擎,打破了INT4/INT8算力限制,有效规避GEMV性能瓶颈。在LLaMA-7B的W2A8配置下,相较于SmoothQuant实现了1.6倍的加速效果,达到当前最优性能。
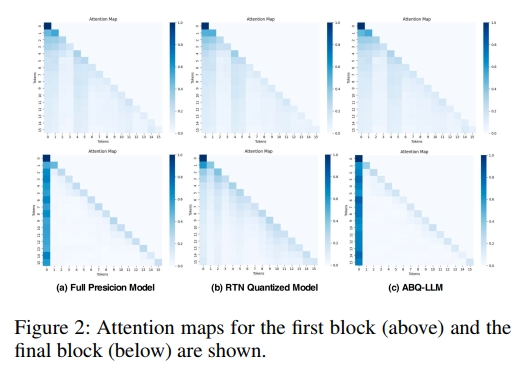
2 相关工作
大语言模型(LLM)的量化可以大致分为两类:仅对权重进行量化,以及同时对权重和激活值进行量化。
权重量化。 为了缓解计算负担,一些研究聚焦于仅对权重进行量化。已有方法通过保留关键通道实现精确的8比特量化。也有方法利用基于Hessian的误差补偿,降低LLM中的量化误差,从而实现3比特量化。另有研究考虑激活值中离群点对权重量化的影响,显著提升了量化模型的性能。部分方法通过可学习的码本或引入额外微调,推动了2比特量化的可行性。还有研究通过非结构化的混合精度细粒度权重分组,提升了后训练量化的表现。此外,也有一系列工作采用高效的参数高效微调技术,通过微调进一步压缩模型权重。
权重-激活量化。 与仅对权重进行量化不同,权重-激活量化在加速LLM推理的过程中,同时对权重和激活值(包括KV缓存)进行量化。这类方法的主要挑战在于处理激活值中的离群点,这些离群点可能导致严重的量化误差。为了解决这一问题,已有工作提出了细粒度、硬件友好的全量化方案,对权重和激活值进行处理。还有方法通过数学等效变换,将量化难点从激活值转移到权重,从而实现8比特的权重与激活值联合量化。一些方法则通过训练量化参数进一步增强模型性能。然而受限于GPU平台的指令集限制,尽管某些工作实现了更低比特数的量化(例如6比特),实际推理时仍只能使用8比特的计算单元。此外,即便是实现了低比特量化,这些方法依然难以在推理阶段摆脱硬件限制,无法充分发挥潜力。
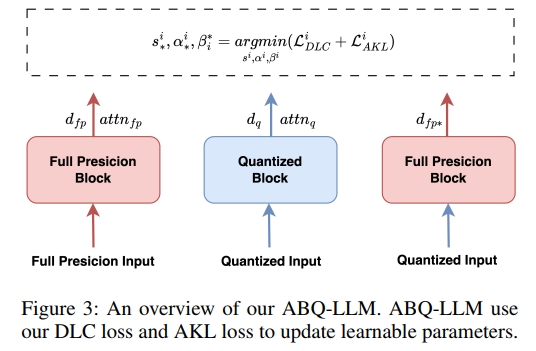
3 方法
本节将详细介绍我们提出的 ABQ-LLM 方法。我们首先描述分布校正与比特平衡策略,然后介绍任意比特精度的推理框架。
3.1 预备知识
已有研究通过缩放激活值中的离群点来实现权重-激活全量化,但这会增加权重数值范围的变化,从而使得权重量化更加敏感。相反,也有研究通过缩放权重来优化权重量化,但这会显著增加激活值的多样性,进一步加剧激活量化的难度。这些方法的共同缺陷在于:人为设定激活值与权重之间的缩放平衡因子存在局限性,难以实现理想的量化平衡。
为了解决这一问题,我们引入了一种基于分布校正的缩放方法。借鉴已有方法的思想,我们将权重与激活之间的平衡向量设置为可学习参数,并为权重引入了可学习的截断参数。通过分布校正和比特平衡策略来优化模型性能,我们的目标函数如下:
argmins,α,β∥WX−Q(clip(W)⋅diag(s))Q(diag(s)−1⋅X)∥(1)\underset{s, \alpha, \beta}{\arg\min} \ \| WX - Q(\text{clip}(W) \cdot \text{diag}(s))Q(\text{diag}(s)^{-1} \cdot X) \|\quad(1) s,α,βargmin ∥WX−Q(clip(W)⋅diag(s))Q(diag(s)−1⋅X)∥(1)
其中,WWW 和 XXX 分别表示全精度权重和激活值,Q(⋅)Q(\cdot)Q(⋅) 表示对权重与激活的量化操作,clip(⋅)\text{clip}(\cdot)clip(⋅) 表示截断操作,sss 为缩放因子,同时定义 Wmax=α⋅max(W)W_{\text{max}} = \alpha \cdot \max(W)Wmax=α⋅max(W),Wmin=β⋅min(W)W_{\text{min}} = \beta \cdot \min(W)Wmin=β⋅min(W),用于控制权重的截断范围。
3.2 通过分布校正提升量化效果
我们在对大语言模型进行量化过程中观察到,不同层对量化的敏感度差异显著,其中某些层对整体量化性能有关键影响。为验证这一现象,如图 1 所示,我们在对 LLaMA-7B 模型进行权重-激活全量化的过程中,对各个组成模块进行了定量分析。实验发现,对 MLP 和注意力模块中的 gate proj 和 up proj 层进行量化仅会导致轻微的性能下降,而对 down proj 线性层进行量化则会引发明显的性能退化。这表明,提升模型量化性能的关键在于解决 down proj 层的量化问题。
进一步分析发现,导致性能下降的主要原因是 down proj 层中激活值的量化。在 INT4、INT3、INT2 等低比特宽度下,激活值的表达能力受限,导致模型的分布与全精度情况相比发生了严重偏移。如图 3 所示,在进行块级量化校准时,我们在 down proj 层的输出上施加双对数余弦相似度损失,用于修正量化模型的分布。该损失函数被称为 DLC 损失,记为 LDLCiL^i_{\text{DLC}}LDLCi。
LDLCi=−log(dqi⋅dfpi∥dqi∥∥dfpi∥)−log(dqi⋅dfp∗i∥dqi∥∥dfp∗i∥)(2)\mathcal { L } _ { D L C } ^ { i } = - l o g ( \frac { \boldsymbol { d } _ { q } ^ { i } \cdot \boldsymbol { d } _ { f p } ^ { i } } { \lVert \boldsymbol { d } _ { q } ^ { i } \rVert \lVert \boldsymbol { d } _ { f p } ^ { i } \rVert } ) - l o g ( \frac { \boldsymbol { d } _ { q } ^ { i } \cdot \boldsymbol { d } _ { f p ^ { * } } ^ { i } } { \lVert \boldsymbol { d } _ { q } ^ { i } \rVert \lVert \boldsymbol { d } _ { f p ^ { * } } ^ { i } \rVert } )\quad(2) LDLCi=−log(∥dqi∥∥dfpi∥dqi⋅dfpi)−log(∥dqi∥∥dfp∗i∥dqi⋅dfp∗i)(2)
其中,dqid^i_qdqi 表示第 iii 个 transformer 块的量化输出,dfpid^i_{fp}dfpi 表示第 iii 个 transformer 块的全精度输出,dfp∗id^i_{fp*}dfp∗i 表示该块在输入来自第 i−1i-1i−1 个 transformer 块的量化输出情况下的全精度输出。
此外,我们还分析了 LLaMA-7B 模型中解码器各层的输入与输出激活之间的余弦相似度。结果表明,模型的前几层和最后几层的余弦相似度存在显著差异,表明这些层对模型推理性能有较大影响。为此,我们在这些层的 down proj 层引入了分布补偿向量,利用公式 (3) 对其分布偏差进行修正。
Wq=clamp(⌈W+γab⊤Δ⌋+z,0,2n−1)(3)W _ { q } = c l a m p ( \lceil \frac { W + \gamma a b ^ { \top } } { \Delta } \rfloor + z , 0 , 2 ^ { n } - 1 )\quad(3) Wq=clamp(⌈ΔW+γab⊤⌋+z,0,2n−1)(3)
其中,⌈·⌋ 表示四舍五入操作,nnn 表示目标比特宽度,Δ\DeltaΔ 表示步长,zzz 为零点。WqW_qWq 和 WWW 分别表示量化后的权重和全精度权重。向量 aaa 和 bbb 是分布补偿向量,其中当 γ=1\gamma = 1γ=1 时表示执行补偿,当 γ=0\gamma = 0γ=0 时表示不进行补偿。
为了提升量化模型的性能,我们分析了量化前后 Attention Map 分布的变化,如图 2 所示。在全精度模型中,注意力显著集中在第一个 token 上,凸显其在引导文本生成过程中的关键作用,这一现象也与 LLM-QAT(Liu 等,2023)的结论一致。然而,量化过程会破坏这种注意力分布,使模型对第一个 token 的关注度降低。为了解决这一问题并在量化过程中恢复模型的注意力机制,我们引入了基于注意力的 KL 散度方法,用于重构注意力图。
LAKLi=DKL(attnqi∥attnfpi)+DKL(attnfpi∥attnqi)(4)\mathcal { L } _ { A K L } ^ { i } = D _ { K L } ( a t t n _ { q } ^ { i } \parallel a t t n _ { f p } ^ { i } ) + D _ { K L } ( a t t n _ { f p } ^ { i } \parallel a t t n _ { q } ^ { i } )\quad(4) LAKLi=DKL(attnqi∥attnfpi)+DKL(attnfpi∥attnqi)(4)
其中,attnqi\text{attn}^i_qattnqi 表示第 iii 个 transformer 块的量化后注意力图输出,attnfpi\text{attn}^i_{fp}attnfpi 表示同一块的全精度注意力图输出。
最后,我们将 DLC 损失与 AKL 损失结合起来,最终的优化目标为:
s∗i,α∗i,βi∗=argminsi,αi,βi(LDLCi+LAKLi)(5)s^i_*, \alpha^i_*, \beta_i^* = \arg\min_{s_i, \alpha_i, \beta_i} (L^i_{DLC} + L^i_{AKL})\quad(5) s∗i,α∗i,βi∗=argsi,αi,βimin(LDLCi+LAKLi)(5)
其中,s∗is^i_*s∗i、α∗i\alpha^i_*α∗i 和 βi∗\beta_i^*βi∗ 是第 iii 个 transformer 块经过校准后的参数。当量化输出与全精度输出的分布匹配时,损失接近于零,从而有效地指导量化过程。
3.3 比特平衡策略
通常,预训练的大语言模型权重呈现近似正态分布,具有对称性。通过QQ图(Quantile-Quantile图)我们验证了预训练模型权重分布的强对称性(详见附录A)。然而,在标准的2比特整数(INT2)量化中,数值表示仅限于四个值,且量化范围是对称的,如{-2, -1, 0, 1} 或 {-1, 0, 1, 2},这破坏了原有的权重对称分布(详见附录A)。这种不对称导致了显著的性能下降,如表1所示,性能从W4A16下降到W3A16降低了0.46,而从W3A16下降到W2A16则降低了5.19,降幅非常明显。
为了解决这种不对称对LLM量化的影响,我们采用了比特平衡策略,类似于(Li等,2016;Ma等,2024a),将INT2的对称量化空间扩展为{-2, -1, 0, 1, 2}。这一修改使模型性能恢复到7.50,与W3A16相比处于合理范围内。
温馨提示:
阅读全文请访问"AI深语解构" ABQ-LLM:用于大语言模型的任意比特量化推理加速



起步第一个程序)















