作者:来自 Elastic Carlos Delgado

仅执行向量搜索以找到与查询最相似的结果是不够的。通常需要过滤来缩小搜索结果。本文解释了在 Elasticsearch 和 Apache Lucene 中向量搜索的过滤是如何工作的。
Elasticsearch 拥有丰富的新功能,帮助你为自己的用例构建最佳搜索解决方案。深入查看我们的示例笔记本以了解更多,开始免费的云试用,或在本地机器上尝试 Elastic。
向量搜索并不足以找到相关结果。使用过滤条件来缩小搜索结果、排除无关结果是非常常见的。
理解过滤在向量搜索中的工作方式将帮助你平衡性能与召回率之间的取舍,同时还能发现一些在使用过滤时提升向量搜索性能的优化方法。
为什么要过滤?
向量搜索(Vector search)彻底改变了我们在大型数据集中查找相关信息的方式,使我们能够发现与查询在语义上相似的项目。
然而,仅仅找到相似项目还不够。我们常常需要根据特定条件或属性来缩小搜索结果。
想象一下你在电商商店中搜索某个商品。纯粹的向量搜索可能会显示与你在视觉上相似的商品,但你可能还想按价格范围、品牌、库存情况或用户评分来过滤。如果没有过滤,你将会看到一大堆相似的商品,很难找到你真正需要的。
过滤使搜索结果的控制更加精确,确保检索到的项目不仅在语义上匹配,而且满足所有必要的要求。这带来了更加准确、高效且用户友好的搜索体验。
这正是 Elasticsearch 和 Apache Lucene 的优势所在 —— 在各种数据类型上使用有效过滤,是它们与其他向量数据库的关键区别之一。
精确向量搜索的过滤
执行精确向量搜索有两种主要方式:
-
对 dense_vector 字段使用 flat 索引类型。这会让 knn 搜索使用精确搜索而不是近似搜索。
-
使用 script_score 查询,通过向量函数计算得分。这可以与任意索引类型一起使用。
当执行精确向量搜索时,所有向量都会与查询进行比较。在这种情况下,过滤会提升性能,因为只有通过过滤的向量才需要比较。
这不会影响结果质量,因为无论如何所有向量都会被考虑。我们只是提前过滤掉不感兴趣的结果,从而减少运算次数。
这点非常重要,因为当应用的过滤条件使结果文档数量很少时,执行精确搜索可能比执行近似搜索更高效。
经验法则是:当过滤后少于 10k 文档时使用精确搜索。BBQ 索引在比较时要快得多,所以对于基于该索引的情况,如果少于 100k,也很适合使用精确搜索。更多细节请查看这篇博客文章。
如果你的过滤条件总是非常严格,可以考虑通过使用 flat 索引类型而不是基于 HNSW 的类型,让索引专注于精确搜索而不是近似搜索。更多细节见 index_options 的属性。
近似向量搜索的过滤
在执行近似向量搜索时,我们以结果的准确性换取性能。像 HNSW 这样的向量搜索数据结构能高效地在数百万向量中搜索近似最近邻。它们专注于通过最少的向量比较(计算代价高昂)来检索最相似的向量。
这意味着其他过滤属性并不是向量数据的一部分。不同的数据类型有各自高效的索引结构来查找和过滤,例如 terms 字典、posting lists 和 doc values。
由于这些数据结构与向量搜索机制是分开的,那么如何将过滤应用到向量搜索呢?有两种选择:在向量搜索之后应用过滤(后过滤,postfiltering)或在向量搜索之前应用过滤(前过滤,prefiltering)。
这两种方式各有优缺点。下面我们深入看看!
后过滤(Postfiltering)
后过滤是在向量搜索完成后再应用过滤。这意味着过滤在找到 top k 个最相似的向量结果之后才会执行。
显然,在应用过滤后我们可能会得到少于 k 的结果。当然,我们可以从向量搜索中检索更多结果(更高的 k 值),但我们不能确定在应用过滤后一定能得到 k 个或更多结果。
后过滤的优点是它不会改变向量搜索的运行行为 —— 向量搜索对过滤毫不知情。但它会改变最终检索到的结果数量。
下面是一个使用 knn 查询进行后过滤的示例。注意过滤子句与 knn 查询是分开的:
{"query": {"bool": {"must": {"knn": {"field": "image-vector","query_vector": [54, 10, -2],"k": 5,"num_candidates": 50}},"filter": {"term": {"file-type": "png"}}}}
}后过滤也可以通过在 knn 搜索中使用 post-filter 来实现:
{"knn": {"field": "image-vector","query_vector": [54, 10, 2],"k": 5,"num_candidates": 50},"post_filter": {"term": {"file-type": "png"}}
}请记住,在 knn 搜索中你需要使用显式的 post-filter 部分。如果你不使用 post-filter,knn 搜索会把最近邻结果与其他查询或过滤条件组合,而不是执行后过滤。
前过滤(Prefiltering)
在向量搜索之前应用过滤会先检索满足过滤条件的文档,然后把这些信息传递给向量搜索。
Lucene 使用 BitSet 来高效存储满足过滤条件的文档。向量搜索随后遍历 HNSW 图,同时考虑满足条件的文档。在把候选项加入结果之前,它会检查该候选项是否包含在有效文档的 BitSet 中。
但是,即使候选项不是有效文档,它也必须被探索并与查询比较。HNSW 的有效性依赖于图中向量之间的连接 —— 如果我们停止探索某个候选项,就可能会错过它的邻居。
这就像开车去加油站。如果你丢弃所有没有加油站的道路,你很可能到不了目的地。其他道路可能不是你需要的,但它们能把你连接到目的地。HNSW 图上的向量也是同样的道理!
因此,应用前过滤的性能会比不使用过滤更差。我们需要对搜索中访问的所有向量进行处理,并丢弃那些不匹配过滤条件的。这意味着要做更多工作,花更多时间才能得到 top k 结果。
下面是 Elasticsearch Query DSL 中前过滤的示例。注意过滤子句现在是 knn 部分的一部分:
{"knn": {"field": "image-vector","query_vector": [54, 10, -2],"k": 5,"num_candidates": 50,"filter": {"term": {"file-type": "png"}}}
}前过滤可用于 knn 搜索和 knn 查询:
{"query": {"knn": {"field": "image-vector","query_vector": [-5, 9, -12],"k": 5,"filter": {"term": {"file-type": "png"}}}}
}前过滤优化
有一些优化方法可以确保前过滤的性能:
-
如果过滤条件非常严格,可以切换到精确搜索。当需要比较的向量很少时,在满足过滤条件的少量文档上执行精确搜索会更快。
这种优化在 Lucene 和 Elasticsearch 中是自动应用的。 -
另一种优化方法是忽略不满足过滤条件的向量。相反,该方法检查通过过滤的向量的邻居。这样有效减少了比较次数,因为不满足条件的向量不会被考虑,同时仍会继续探索与当前路径相连的向量。
这种算法称为 ACORN-1,具体过程在这篇博客文章中有详细描述。
使用文档级安全进行过滤
文档级安全(DLS)是 Elasticsearch 的一项功能,用于指定用户角色可以检索的文档。
DLS 通过查询执行。角色可以与索引关联一个查询,这有效限制了属于该角色的用户可以从索引中检索的文档。
角色查询用作过滤器以检索匹配的文档,并作为 BitSet 缓存。然后使用这个 BitSet 包装底层的 Lucene reader,这样只有查询返回的文档被视为有效 —— 也就是说,它们存在于索引中且未被删除。
当从 reader 中检索有效文档以执行 knn 查询时,只会考虑用户可用的文档。如果有前过滤,DLS 文档将被添加到前过滤中。
这意味着 DLS 过滤作为近似向量搜索的前过滤,其性能影响和优化方法相同。
在精确搜索中使用 DLS 与应用任何过滤器具有相同的好处 —— 从 DLS 检索的文档越少,精确搜索的性能越高。同时还要考虑 DLS 返回的文档数量 —— 如果 DLS 角色非常严格,你可以考虑使用精确搜索而不是近似搜索。
基准测试
在 Elasticsearch,我们希望确保向量搜索过滤高效。我们有专门的向量过滤基准测试,它对不同的过滤条件执行近似向量搜索,以确保向量搜索尽可能快速地检索相关结果。
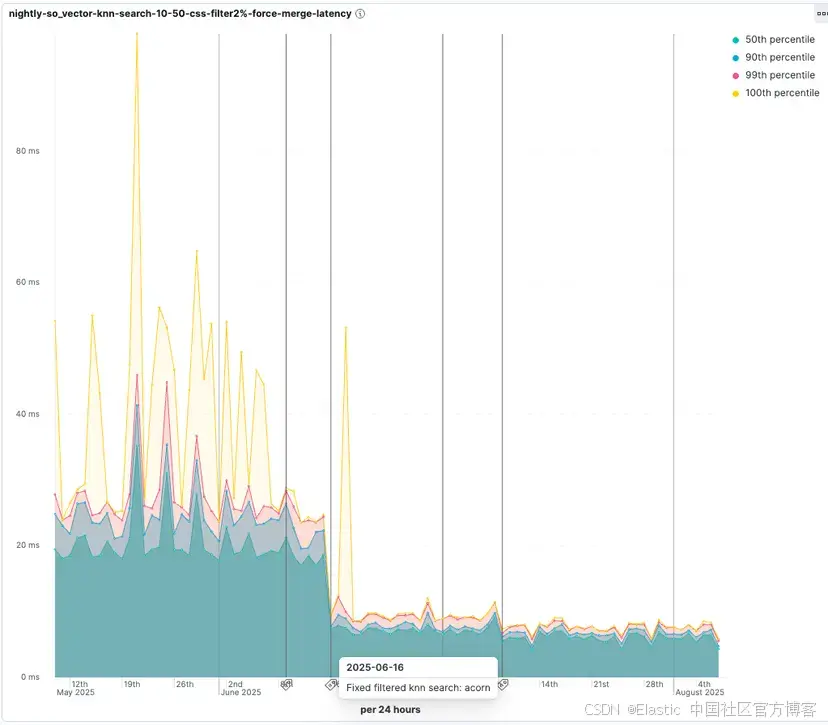
查看 ACORN-1 引入时的改进。在测试中,只有 2% 的向量通过过滤,查询延迟降低到原始时间的 55%:
结论
过滤是搜索的重要组成部分。确保向量搜索中过滤的高性能,并理解其权衡和优化,是实现高效且准确搜索的关键。
过滤会影响向量搜索的性能:
-
使用过滤时,精确搜索更快。如果你的过滤条件足够严格,应考虑使用精确搜索而不是近似搜索。这在 Elasticsearch 中是自动优化的。
-
使用前过滤时,近似搜索会更慢。前过滤可以让我们获得符合过滤条件的 top k 结果,但代价是搜索速度变慢。
-
后过滤不一定能检索到 top k 结果,因为应用过滤后部分结果可能被过滤掉。
祝过滤愉快!
原文:Vector search filtering: Keep it relevant - Elasticsearch Labs





的传输层设计、诊断服务器实现、事件与通信管理、生命周期与报告五大核心模块)













)