目录
基于Ubuntu22.04系统PaddleX和PaddleClas训练推理MMAFEDB人脸表情识别数据集(详细教程)
超实用的Paddle图像分类训练推理教程,助力深度学习研究!
1、环境准备(重要⭐⭐⭐)
构建虚拟环境
安装PaddlePaddle
安装PaddleX
安装PaddleClas插件
2、数据准备(重要⭐⭐⭐)
2.1 数据下载及制作
2.2 数据校验
3、开始训练(重要⭐⭐⭐)
训练启动参数详细说明
4、开始评估(重要⭐⭐⭐)
5、开始推理(重要⭐⭐⭐)
6、参考资源链接
7、交流学习
基于Ubuntu22.04系统PaddleX和PaddleClas训练推理MMAFEDB人脸表情识别数据集(详细教程)
超实用的Paddle图像分类训练推理教程,助力深度学习研究!
测试环境:
Ubuntu 22.04.4 LTS
cuda_11.8
Tesla P4显卡
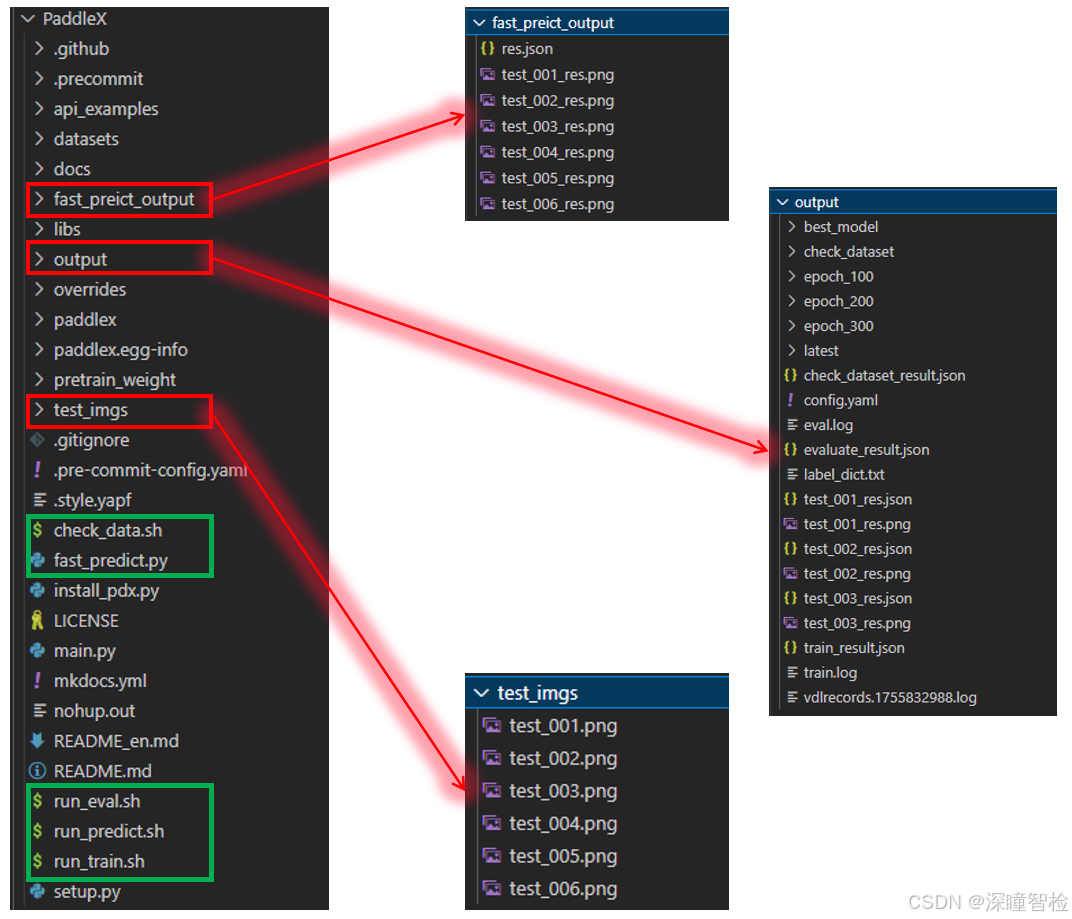
磁盘空间500G项目源码最终目录结构预览
1、环境准备(重要⭐⭐⭐)
构建虚拟环境
# 创建环境
conda create -n paddleclas python=3.10
# 激活环境进入
conda activate paddleclas安装PaddlePaddle
参考地址:https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/linux-pip.html
# 安装指令
python -m pip install paddlepaddle-gpu==3.1.1 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# 验证paddlepaddle是否可用GPU
python -c "import paddle;print(paddle.utils.run_check());print(paddle.__version__)"
# 输出如下信息,则安装成功,paddlepaddle-gpu可使用
'''
Running verify PaddlePaddle program ...
I0821 11:21:45.437101 7032 pir_interpreter.cc:1524] New Executor is Running ...
W0821 11:21:45.437536 7032 gpu_resources.cc:114] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 12.4, Runtime API Version: 11.8
I0821 11:21:45.686959 7032 pir_interpreter.cc:1547] pir interpreter is running by multi-thread mode ...
PaddlePaddle works well on 1 GPU.
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
None
'''安装PaddleX
参考地址:https://paddlepaddle.github.io/PaddleX/latest/installation/installation.html
pip install paddlex==3.1.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 额外依赖包
pip install pypdfium2 -i https://pypi.tuna.tsinghua.edu.cn/simple安装PaddleClas插件
参考地址:https://paddlepaddle.github.io/PaddleX/latest/installation/installation.html
# 获取源码仓库(训练使用,与上述的推理库不冲突)
git clone -b release/3.1 https://github.com/PaddlePaddle/PaddleX.git
cd PaddleX
# 源码编译
pip install -e .
# 安装插件
paddlex --install PaddleClas
# 输出如下信息,则安装成功,paddleclas可使用
'''
......
Successfully built paddleclas
Installing collected packages: paddleclas
Successfully installed paddleclas-2.6.0
All packages are installed.
'''2、数据准备(重要⭐⭐⭐)
2.1 数据下载及制作
官方kaggle数据下载
可参考:https://www.kaggle.com/datasets/mahmoudima/mma-facial-expression
# 可参考下载方式
curl -L -o ./mma-facial-expression.zip\https://www.kaggle.com/api/v1/datasets/download/mahmoudima/mma-facial-expression制作paddle格式数据(放于PaddleX源码目录下)
目录结构为:
datasets/
└── mmafedb/├── images/├── label.txt├── train.txt└── val.txtlabel.txt文件内容如下(7个类别)
0 angry
1 disgust
2 fear
3 happy
4 neutral
5 sad
6 surprisetrain.txt文件内容如下(92968条数据)
images/train_angry_10012Exp0fighting_people_350.jpg 0
images/train_angry_10018Exp0fighting_people_429.jpg 0
images/train_angry_10025Exp0fighting_people_5.jpg 0
images/train_angry_10037Exp0fighting_people_573.jpg 0
......val.txt文件内容如下(17356条数据)
......
images/val_surprise_Surprise.32265.jpg 6
images/val_surprise_Surprise.32266.jpg 6
images/val_surprise_Surprise.32283.jpg 6
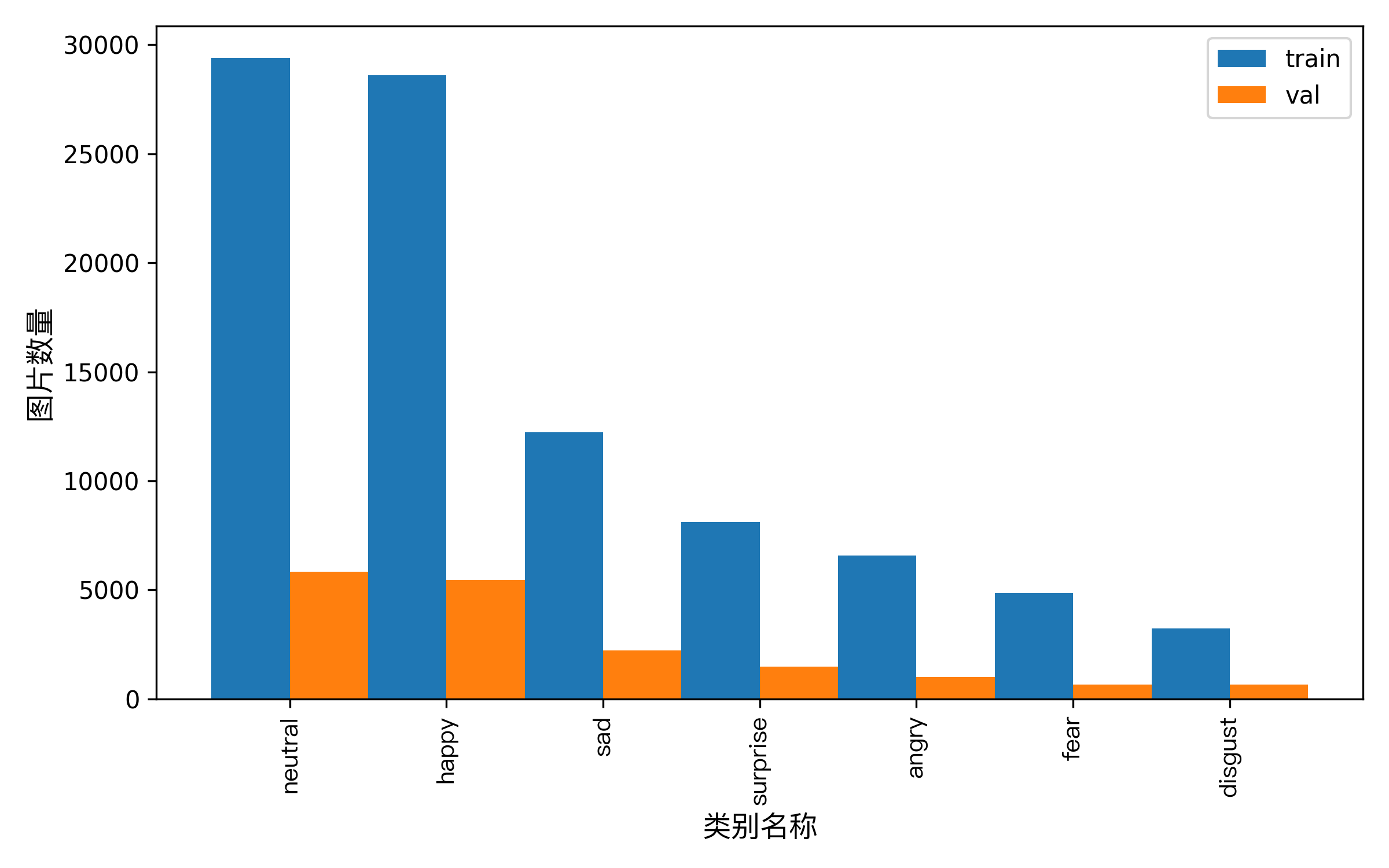
images/val_surprise_Surprise.32284.jpg 6images/目录中存放所有的图片,统计如下
JPG图像总数: 110324去重后的分辨率统计:
分辨率 (宽×高) 出现次数
---------------------------
48×48 110324共有 1 种不同的分辨率PS: test.txt暂时不使用
文末回复对应关键词,可获取制作好的paddle格式训练数据集
2.2 数据校验
在源码PaddleX目录下操作
新建shell执行脚本check_data.sh,内容如下
python main.py -c paddlex/configs/modules/image_classification/PP-LCNet_x1_0.yaml \-o Global.mode=check_dataset \-o Global.dataset_dir=./datasets/mmafedb执行校验脚本,输出成功信息
# 命令行运行
bash check_data.sh
# 输出如下信息,则校验成功,结果内容可见./output目录
'''
Connecting to https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/fonts/PingFang-SC-Regular.ttf ...
Downloading PingFang-SC-Regular.ttf ...
[==================================================] 100.00%
Check dataset passed !
'''数据分布直方图,见histogram.png
3、开始训练(重要⭐⭐⭐)
在源码PaddleX目录下操作
新建shell执行脚本run_train.sh,内容如下
python main.py -c paddlex/configs/modules/image_classification/PP-LCNet_x1_0.yaml \-o Global.mode=train \-o Global.dataset_dir=./datasets/mmafedb \-o Global.device=gpu:0 \-o Train.num_classes=7 \-o Train.epochs_iters=300 \-o Train.batch_size=128 \-o Train.pretrain_weight_path=./pretrain_weight/PP-LCNet_x1_0_pretrained.pdparams \-o Train.log_interval=20 \-o Train.eval_interval=100 \-o Train.save_interval=100训练启动参数详细说明
| 参数名 | 数据类型 | 描述 | 示例值 |
|---|---|---|---|
mode | str | 指定模式check_dataset/train/evaluate/export/predict | train |
dataset_dir | str | 数据集路径 | ./datasets/mmafedb |
device | str | 指定使用的设备 | gpu:0 |
num_classes | int | 数据集中的类别数 | 7 |
epochs_iters | int | 模型对训练数据的重复学习次数 | 300 |
batch_size | int | 训练批大小 | 128 |
pretrain_weight_path | str | 预训练权重路径 | ./pretrain_weight/PP-LCNet_x1_0_pretrained.pdparams |
log_interval | int | 训练日志打印间隔 | yaml文件中指定的训练日志打印间隔 |
eval_interval | int | 模型评估间隔 | yaml文件中指定的模型评估间隔 |
save_interval | int | 模型保存间隔 | yaml文件中指定的模型保存间隔 |
执行训练脚本,结果存储于./output目录
# 命令行运行
bash run_train.sh训练结束后进入./output目录下操作
可视化指标输出,使用visualdl指令
# 命令行运行
visualdl --logdir ./ --port 8080
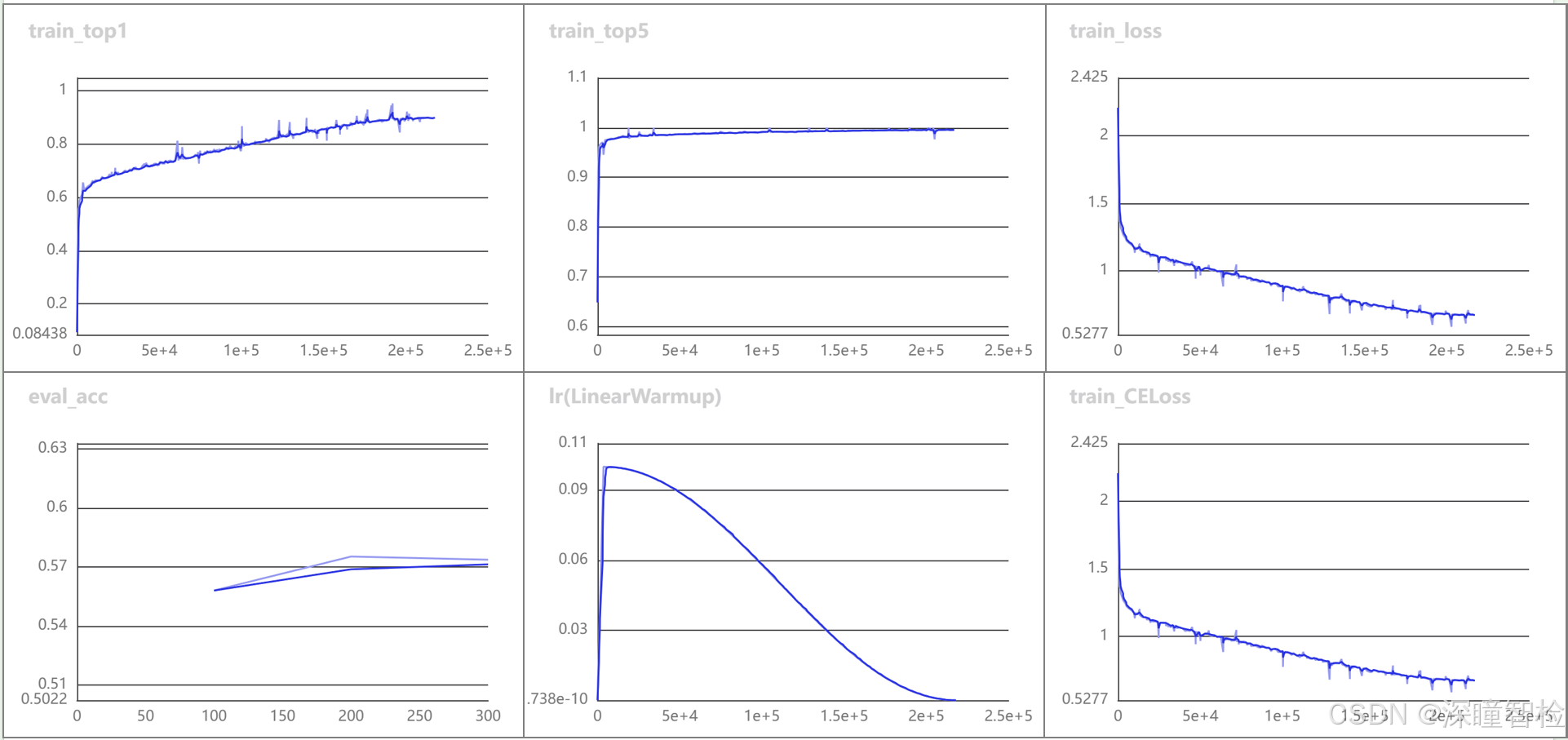
### 然后本地浏览器输入地址:http://localhost:8080/,即可访问样例图如下,见指标趋势图.png
4、开始评估(重要⭐⭐⭐)
在源码PaddleX目录下操作
新建shell执行脚本run_eval.sh,内容如下
python main.py -c paddlex/configs/modules/image_classification/PP-LCNet_x1_0.yaml \-o Global.mode=evaluate \-o Global.dataset_dir=./datasets/mmafedb \-o Evaluate.weight_path=./output/best_model/best_model.pdparams \-o Evaluate.log_interval=10PS:在模型评估时,需要指定模型权重文件路径。
在完成模型评估后,(./output目录)会产出evaluate_result.json,其记录了评估的结果,具体来说,记录了评估任务是否正常完成,以及模型的评估指标,包含 val.top1、val.top5,如下内容
{"done_flag": true,"metrics": {"val.top1": 0.57093,"val.top5": 0.927}
}5、开始推理(重要⭐⭐⭐)
在源码PaddleX目录下操作
新建shell执行脚本run_predict.sh,内容如下
python main.py -c paddlex/configs/modules/image_classification/PP-LCNet_x1_0.yaml \-o Global.mode=predict \-o Predict.model_dir="./output/best_model/inference" \-o Predict.input="./test_imgs/test_001.png"PS:在模型推理时,需要指定模型权重文件夹路径,包含推理模式下的模型*.pdiparams。
在完成推理预测后,(./output目录)会产出test_001_res.json,其记录了预测的结果,具体来说,记录了预测任务是否正常完成,以及类别得分等,识别结果图如下所示

(额外)模型集成推理
新建代码文件fast_predict.py,内容如下
from paddlex import create_modelmodel_dir = "./output/best_model/inference"model = create_model(model_name="PP-LCNet_x1_0", model_dir=model_dir)output = model.predict("./test_imgs", batch_size=1)
for res in output:res.print(json_format=False)res.save_to_img("./fast_preict_output/")res.save_to_json("./fast_preict_output/res.json")结果图像保存至./fast_preict_output目录中
6、参考资源链接
- • https://paddlepaddle.github.io/PaddleX/latest/module_usage/tutorials/cv_modules/image_classification.html
- • https://paddlepaddle.github.io/PaddleX/latest/module_usage/instructions/config_parameters_common.html
7、交流学习
进一步交流学习,促进你我共同进步,可在下方回复联系!祝您前程似锦!
公众号:深瞳智检







)





)

)

)

