-—— 避开80%项目失败的隐形成本,掌握高效建模方法论*
📌 一、明确目标:成败的起点
1. 问题定位
- 分类任务:区分二分类/多分类/多标签分类
- 预测任务:标量预测(如房价)vs 向量预测(如股票走势)
- 聚类任务:无监督模式发现
- 关键验证:评估问题是否适合机器学习解决(如数据规律性、成本收益比)
2. 目标拆解
️ # 二、数据工程:模型的地基
数据收集核心三问:
✓ 需要哪些数据?
✓ 现有数据是否充分?
✓ 能否实现自动化采集?
数据探索四步法:
- 结构分析(字段类型、维度)
- 质量检测(缺失值/异常值统计)
- 分布可视化(箱线图/直方图)
- 相关性热力图(特征关联性)
预处理关键操作:
| 问题类型 | 处理方案 | 工具示例 |
|---|---|---|
| 缺失值 | 插值/删除/预测填充 | Sklearn Imputer |
| 非数值数据 | 独热编码/标签编码 | Pandas get_dummies |
| 数据不平衡 | SMOTE过采样/欠采样 | Imbalanced-learn |
| 特征冗余 | PCA/递归特征消除 | Scikit-learn RFE |
🤖 三、模型构建:算法选择的艺术
经典模型选择矩阵:
分类问题 → Logistic回归/决策树/SVM
回归问题 → 线性回归/随机森林/XGBoost
聚类问题 → K-Means/DBSCAN/层次聚类
损失函数决策表(PyTorch示例):
| 任务类型 | 激活函数 | 损失函数 |
|---|---|---|
| 二分类(单标签) | Sigmoid | BCELoss |
| 多分类(单标签) | 无需Softmax | CrossEntropyLoss |
| 多标签分类 | None | MultiLabelSoftMarginLoss |
| 回归预测 | None | MSELoss |
💡 行业经验:首次建模建议选择简单基准模型(如线性回归/KNN),快速验证流程可行性
⚙️ 四、模型调优:持续迭代的引擎
三大评估方法论:
if 数据量 > 10万:采用留出法(训练集70%/验证集15%/测试集15%)
elif 1万 < 数据量 < 10万:采用K折交叉验证(K=5或10)
else: 采用重复K折验证(增强小数据稳定性)
过拟合破解策略:
- 正则化武器库:L1/L2正则化 → Dropout → 早停法(Early Stopping)
- 数据增强技巧:图像旋转/文本同义词替换/噪声注入
- 集成学习方案:Bagging(随机森林)/ Boosting(AdaBoost)
💎 终极检验:模型交付的黄金标准
- 业务指标对齐:准确率不是唯一标准,关注AUC/召回率/F1值等业务敏感指标
- 泛化能力压力测试:跨场景数据验证(如不同时间段/地域数据)
- 可持续监控体系:部署后持续监控预测偏移(Data Drift)
🔥 核心洞见:
机器学习项目中数据预处理耗时占比超60%,而模型选择仅占10%
真正的高手把80%精力花在:数据质量提升 + 特征工程创新 + 评估体系构建
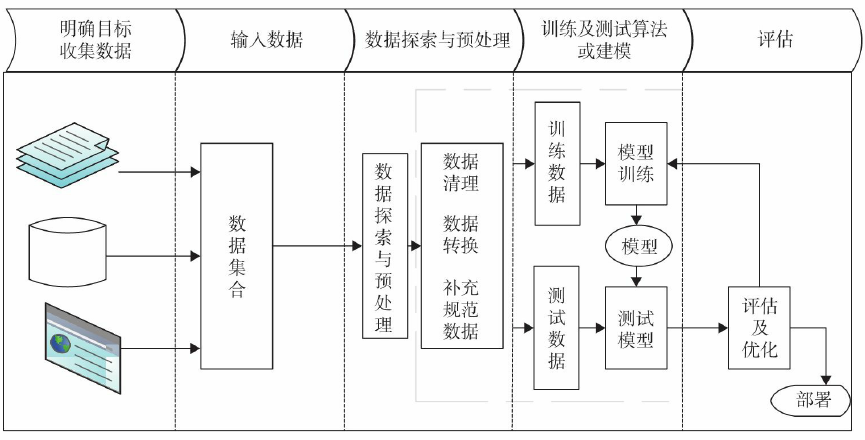
📊 机器学习全流程图示



)

)

)


)




TCP 三握中第三次 ACK 丢失会发生什么?)


)
