多智能体协作的自动化视频舆情分析报告生成器
1. 项目的意义与价值
从“非结构化视频”中挖掘“结构化洞察”的通用挑战
在当今的数字生态中,视频已成为信息传播、知识分享和消费者意见表达的核心媒介。从企业内部的会议录屏、技术培训,到外部的市场宣传、用户评测,海量视频内容正以前所未有的速度被创造出来。然而,对于绝大多数组织而言,这个庞大的视频库仍然是“暗数据”——蕴含着无尽的价值,却因其非结构化的特性,而难以被高效地检索、分析和利用。
人工观看并提炼视频信息的方法,成本高昂、效率低下且无法规模化,这构成了企业在智能化转型中面临的普遍瓶颈。
本项目旨在解决这一通用挑战。构建了一个由多个AI智能体(Agent)协作的自动化工作流,该系统如同一支永不疲倦的虚拟分析师团队,能够:
- 规模化处理: 自动消化并理解海量的视频源。
- 深度多模态理解: 同时“看懂”视频画面并“听懂”语音内容,实现跨模态的信息融合。
- 智能提炼: 将线性的、非结构化的视频信息,转化为结构化的、可量化的数据资产。
以汽车行业为例:一个高价值的垂域应用场景
上述挑战在那些产品复杂、竞争激烈、且高度依赖市场反馈的行业中尤为突出。为了具体展示本系统的强大能力,我们将聚焦于一个典型的高价值应用场景——新款汽车的市场舆情分析。
当一家车企发布一款新车后,其成败往往在最初的“黄金72小时”就已初见端倪。市场的真实声音,就分散在YouTube、B站等平台上成百上千个KOL(关键意见领袖)的深度评-
测视频中。车企高层迫切需要知道:
- 市场最关注我们新车的哪些核心特性?
- 在这些特性上,主流观点是正面还是负面?
- 评测中,大家都在拿我们的车和哪些竞品做对比?
- 我们真正的优势和短板是什么?
本Jupyter Notebook将完整地、端到端地实现一个智能体系统来回答这些问题。我们将演示,这个系统如何自动处理多个关于同一款新车的评测视频,并通过“探索-分析-策略”的多阶段智能体协作,最终生成一份包含量化数据和深度洞察的专业级Markdown舆情洞察报告。
这不仅是一个技术演示,更是一个未来商业智能工作模式的缩影——将AI智能体应用于垂直领域,从而在海量信息中赢得决策先机。
2. 环境准备:安装所有必需的库
# 运行此单元格以安装所有依赖项
!pip install agno baidu-aip openai opencv-python-headless moviepy pydub yt-dlp
3. 导入核心库
import os
import json
import base64
import re
import logging
from typing import Dict, List, Iterator
from concurrent.futures import ThreadPoolExecutor, as_completed# 框架与核心工具
from agno.agent import Agent, RunResponse
from agno.workflow import Workflow
from agno.models.openai import OpenAIChat
from aip import AipSpeech
import cv2
from moviepy.editor import VideoFileClip
from pydub import AudioSegment
import yt_dlp
from openai import OpenAI
from tqdm.notebook import tqdm
from IPython.display import display, Markdown
4. 🚀 配置中心
百度智能云的语音识别相关配置需登录/申请使用,文心多模态大模型在星河社区首页点击即送~
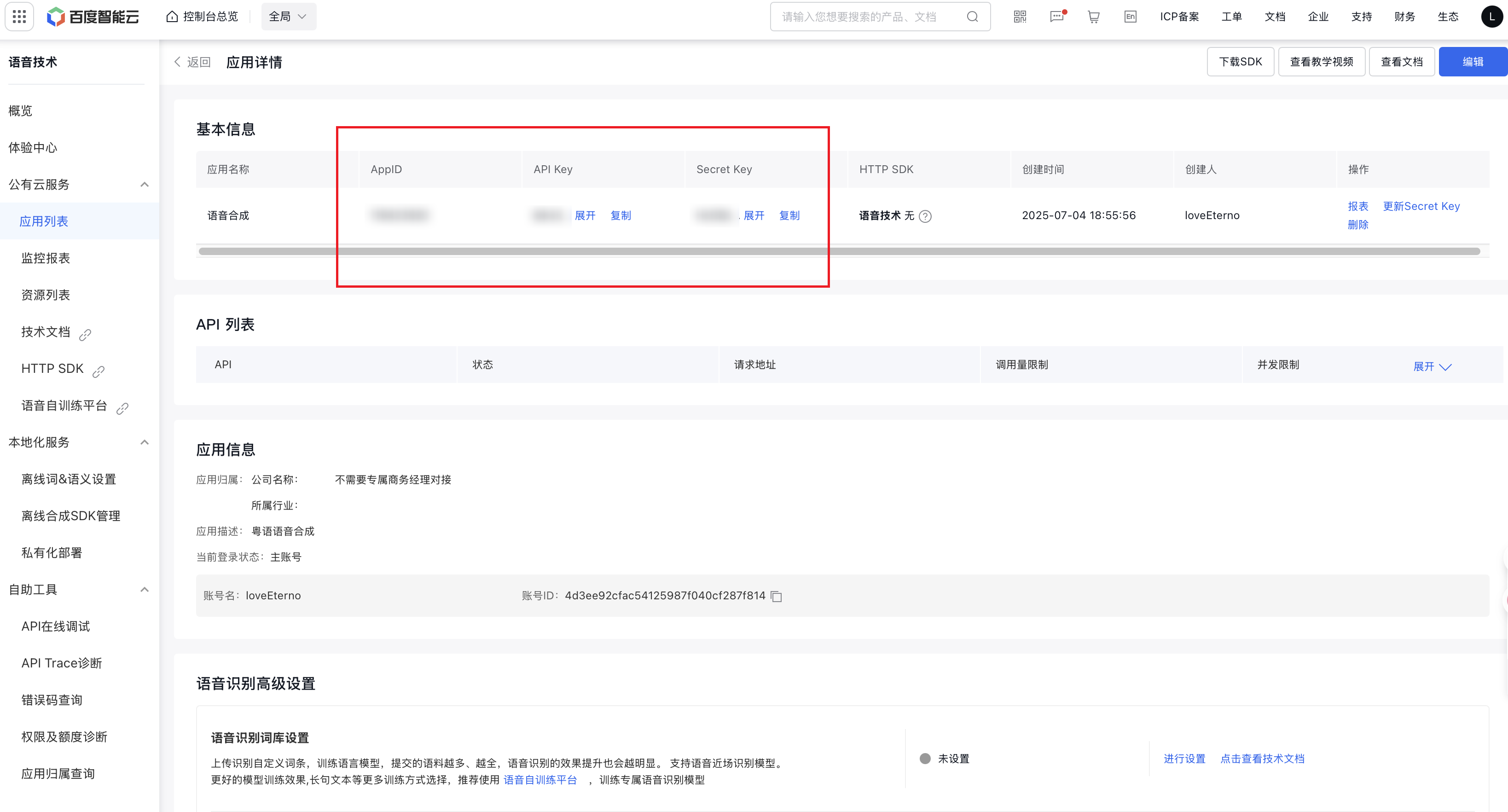
class Config:# --- 百度智能云 API 配置 ---BAIDU_APP_ID = "YOUR_BAIDU_APP_ID"BAIDU_API_KEY = "YOUR_BAIDU_API_KEY"BAIDU_SECRET_KEY = "YOUR_BAIDU_SECRET_KEY"# --- 文心多模态大模型 API 配置 ---# ERNIE_MODEL_NAME可选ernie-4.5-turbo-vl或ernie-4.5-vl-28b-a3bERNIE_API_KEY = "YOUR_ERNIE_API_KEY"ERNIE_BASE_URL = "https://aistudio.baidu.com/llm/lmapi/v3" ERNIE_MODEL_NAME = "ernie-4.5-turbo-vl" # --- 视频源配置 (请提供1个或多个YouTube评测视频链接) ---VIDEO_URLS = ["https://www.youtube.com/watch?v=l-SSk-fuNl8", "https://www.youtube.com/watch?v=YJ_Qs-zziMc"]# --- 工作目录与分析参数 ---WORKING_DIRECTORY = "./auto_market_research"CHUNK_DURATION_SECONDS = 30LANGUAGE_MAP = {"普通话": 1537, "英语": 1737, "粤语": 1637, "四川话": 1837}SELECTED_LANGUAGE = "普通话"# --- 并发与重试 ---MAX_CONCURRENCY = 4MAX_RETRIES = 3# --- 日志与环境设置 ---
os.makedirs(Config.WORKING_DIRECTORY, exist_ok=True)
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger("VideoAnalysisSystem")
5. 辅助工具与预处理模块
包含为Agent工作流准备数据的所有底层函数。它是一个确定性的数据处理管道,负责将视频URL转换为结构化的分析日志。
def extract_json_from_response(text: str) -> dict or list:"""从LLM的返回文本中稳健地提取JSON对象或列表。"""if not text or not isinstance(text, str): return {}match = re.search(r'```(?:json)?\s*(\{.*\}|\[.*\])\s*```', text, re.DOTALL)if match: json_str = match.group(1)else:match = re.search(r'(\{.*\}|\[.*\])', text, re.DOTALL)if not match: return {}json_str = match.group(0)try:return json.loads(json_str)except json.JSONDecodeError: return {}def download_video_with_yt_dlp(video_url: str, output_dir: str, video_id: str) -> str:"""使用 yt-dlp 下载视频,限制分辨率为最高720p以加快处理速度。"""full_video_path = os.path.join(output_dir, f"{video_id}.mp4")ydl_opts = {'format': 'bestvideo[ext=mp4][height<=720]+bestaudio[ext=m4a]/best[ext=mp4][height<=720]/best','outtmpl': full_video_path, 'quiet': True, 'noplaylist': True, 'retries': 3,}try:with yt_dlp.YoutubeDL(ydl_opts) as ydl:ydl.download([video_url])return full_video_path if os.path.exists(full_video_path) else Noneexcept Exception as e:logger.error(f"yt-dlp 下载出错 for {video_url}: {e}")return Nonedef run_audio_transcription(video_path: str, config: Config) -> List[Dict]:"""从视频中提取音频并进行转录。"""temp_audio_path = os.path.join(config.WORKING_DIRECTORY, f"temp_audio_{os.path.basename(video_path)}.wav")try:with VideoFileClip(video_path) as video:video.audio.write_audiofile(temp_audio_path, codec='pcm_s16le', fps=16000, logger=None)full_audio = AudioSegment.from_wav(temp_audio_path).set_channels(1)asr_client = AipSpeech(config.BAIDU_APP_ID, config.BAIDU_API_KEY, config.BAIDU_SECRET_KEY)dev_pid = config.LANGUAGE_MAP.get(config.SELECTED_LANGUAGE, 1537)tasks = [{"start_time": i / 1000.0, "data": full_audio[i:i + config.CHUNK_DURATION_SECONDS * 1000].raw_data}for i in range(0, len(full_audio), config.CHUNK_DURATION_SECONDS * 1000)if len(full_audio[i:i + config.CHUNK_DURATION_SECONDS * 1000].raw_data) > 1000]transcripts = []with ThreadPoolExecutor(max_workers=config.MAX_CONCURRENCY) as executor:future_to_task = {executor.submit(asr_client.asr, task["data"], 'pcm', 16000, {'dev_pid': dev_pid}): task for task in tasks}for future in tqdm(as_completed(future_to_task), total=len(tasks), desc=f"音频转录 ({os.path.basename(video_path)})"):result = future.result()if result and result.get("err_no") == 0 and result.get("result"):task_info = future_to_task[future]transcripts.append({"start_time": task_info["start_time"], "end_time": task_info["start_time"] + config.CHUNK_DURATION_SECONDS, "text": "".join(result["result"])})return sorted(transcripts, key=lambda x: x['start_time'])finally:if os.path.exists(temp_audio_path): os.remove(temp_audio_path)def run_vision_analysis(video_path: str, transcripts: List[Dict], config: Config) -> List[Dict]:"""对视频帧进行分块分析。"""vision_client = OpenAI(api_key=config.ERNIE_API_KEY, base_url=config.ERNIE_BASE_URL)cap = cv2.VideoCapture(video_path)duration = cap.get(cv2.CAP_PROP_FRAME_COUNT) / cap.get(cv2.CAP_PROP_FPS)tasks = []for start_s in range(0, int(duration), config.CHUNK_DURATION_SECONDS):end_s = min(start_s + config.CHUNK_DURATION_SECONDS, duration)frames_b64 = []for i in range(int(end_s - start_s)):cap.set(cv2.CAP_PROP_POS_MSEC, (start_s + i) * 1000)ret, frame = cap.read()if ret:_, buffer = cv2.imencode('.jpg', frame, [int(cv2.IMWRITE_JPEG_QUALITY), 70])frames_b64.append(base64.b64encode(buffer).decode('utf-8'))if frames_b64:context_transcript = " ".join([t['text'] for t in transcripts if max(start_s, t['start_time']) < min(end_s, t['end_time'])])tasks.append({"start_time": start_s, "end_time": end_s, "frames": frames_b64, "transcript": context_transcript})cap.release()vision_analysis = []with ThreadPoolExecutor(max_workers=config.MAX_CONCURRENCY) as executor:future_to_task = {}for task in tasks:prompt = f"你是一个视频分析AI。请结合语音内容“{task['transcript']}”和以下图像帧,用一段话详细描述从{int(task['start_time'])}秒到{int(task['end_time'])}秒的视频场景和核心事件。"content_list = [{"type": "text", "text": prompt}] + [{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{f}"}} for f in task['frames']]messages = [{"role": "user", "content": content_list}]future = executor.submit(vision_client.chat.completions.create, model=config.ERNIE_MODEL_NAME, messages=messages, temperature=0.1, max_tokens=2048)future_to_task[future] = taskfor future in tqdm(as_completed(future_to_task), total=len(tasks), desc=f"视觉分析 ({os.path.basename(video_path)})"):response = future.result()task_info = future_to_task[future]vision_analysis.append({"start_time": task_info['start_time'], "end_time": task_info['end_time'], "description": response.choices[0].message.content.strip()})return sorted(vision_analysis, key=lambda x: x['start_time'])def batch_preprocess_videos(config: Config) -> Dict[str, str]:"""批量预处理视频,并增加缓存机制,跳过已处理的视频。"""video_log_paths = {}for url in config.VIDEO_URLS:try:video_id = url.split("=")[-1].split("&")[0]log_path = os.path.join(config.WORKING_DIRECTORY, f"log_{video_id}.json")if os.path.exists(log_path):logger.info(f"✅ [缓存] 发现已处理的日志,跳过预处理: {video_id}")video_log_paths[video_id] = log_pathcontinuelogger.info(f"--- 开始预处理新视频: {video_id} ---")video_path = download_video_with_yt_dlp(url, config.WORKING_DIRECTORY, video_id)if not video_path: continuetranscripts = run_audio_transcription(video_path, config)vision_analysis = run_vision_analysis(video_path, transcripts, config)analysis_log = [{"start_time": v['start_time'], "end_time": v['end_time'], "transcript": " ".join([t['text'] for t in transcripts if max(v['start_time'], t['start_time']) < min(v['end_time'], t['end_time'])]), "vision_description": v['description']} for v in vision_analysis]with open(log_path, 'w', encoding='utf-8') as f:json.dump(analysis_log, f, indent=2, ensure_ascii=False)video_log_paths[video_id] = log_pathlogger.info(f"✅ 视频 {video_id} 预处理完成 -> {log_path}")except Exception as e:logger.error(f"❌ 视频 {url} 预处理失败: {e}", exc_info=True)return video_log_paths
6. 🤖 Agent 工作流定义
这是项目的核心大脑,定义了三个智能体角色(探索者、分析师、策略师)以及驱动它们的agno工作流。
def create_llm(config: Config, temperature: float = 0.2):"""创建配置好的LLM实例"""return OpenAIChat(id=config.ERNIE_MODEL_NAME, api_key=config.ERNIE_API_KEY, base_url=config.ERNIE_BASE_URL,temperature=temperature)class AutoMarketResearchWorkflow(Workflow):def __init__(self, config: Config, video_log_paths: Dict[str, str]):super().__init__()self.config = configself.video_logs = {vid: json.load(open(path, 'r', encoding='utf-8')) for vid, path in video_log_paths.items()}def run(self) -> Iterator[RunResponse]:# --- 阶段1: 探索 Agent (自动发现关键维度) ---yield RunResponse(content="--- **阶段1: 探索Agent** 正在自动发现核心分析维度 ---\n")explorer_agent = Agent(model=create_llm(self.config, temperature=0.0),instructions=["你是一个市场洞察专家,任务是从多个视频的分析日志中,自动归纳出被反复讨论的【产品核心特性】和被明确提及的【竞争对手】。你的输出必须是一个格式正确的JSON对象,包含`key_features`和`competitors`两个列表。"])all_logs_text = json.dumps(self.video_logs, ensure_ascii=False, indent=2)response = explorer_agent.run(f"请分析以下来自多个视频的日志,归纳出核心特性和竞争对手。\n```json\n{all_logs_text}\n```")discovered_dims = extract_json_from_response(response.content)self.session_state['key_features'] = discovered_dims.get('key_features', [])self.session_state['competitors'] = discovered_dims.get('competitors', [])yield RunResponse(content=f"✅ **探索完成!**\n - **发现特性**: {self.session_state['key_features']}\n - **发现竞品**: {self.session_state['competitors']}\n")# --- 阶段2: 分析师 Agent (基于发现的维度进行标注) ---yield RunResponse(content="\n--- **阶段2: 分析师Agent** 正在对视频进行聚焦分析和情感标注 ---\n")analyst_agent = Agent(model=create_llm(self.config),instructions=["你是一位严谨的分析师,任务是精读一份视频日志,抽取出所有关于指定【分析维度】的观点,并标注情感。你的输出必须是一个格式正确的JSON列表,每个对象包含`dimension`, `sentiment` ('positive', 'negative', 'neutral'), `quote`, 和 `timestamp`。"])tagged_reports = {}analysis_dims = self.session_state['key_features'] + self.session_state['competitors']for video_id, log_data in self.video_logs.items():prompt = f"分析以下视频日志,抽取出所有关于【分析维度: {analysis_dims}】的观点。\n日志:\n```json\n{json.dumps(log_data, ensure_ascii=False, indent=2)}\n```"response = analyst_agent.run(prompt)tagged_reports[video_id] = extract_json_from_response(response.content)self.session_state['tagged_reports'] = tagged_reportsyield RunResponse(content=f"✅ **观点标注完成**,已处理所有视频。\n")# --- 阶段3: 策略师 Agent (整合数据并撰写报告) ---yield RunResponse(content="\n--- **阶段3: 市场策略师Agent** 正在撰写最终洞察报告 ---\n")consolidated_db = {}for video_id, report in tagged_reports.items():if isinstance(report, list):for item in report:if isinstance(item, dict) and 'dimension' in item:dim = item['dimension']if dim not in consolidated_db: consolidated_db[dim] = []consolidated_db[dim].append({**item, "source_video": video_id})strategist_agent = Agent(model=create_llm(self.config, temperature=0.4),instructions=["你是一位高级市场策略师,任务是基于一份聚合后的舆情数据库,撰写一份给公司高层看的、专业的Markdown市场洞察报告。报告必须包含:1. 核心特性正负面评价统计分析。2. 主要优缺点总结(引用原话)。3. 竞品对比分析。4. 结论与建议。"])prompt = f"这是关于新款汽车的聚合舆情数据。请基于此数据撰写一份深入的Markdown洞察报告。\n聚合舆情数据库:\n```json\n{json.dumps(consolidated_db, ensure_ascii=False, indent=2)}\n```"response = strategist_agent.run(prompt)final_report = response.contentself.session_state['final_report'] = final_reportyield RunResponse(content="\n--- **工作流成功结束** ---")yield RunResponse(content="\n\n" + "="*80 + "\n 最终舆情洞察报告\n" + "="*80 + "\n\n")yield RunResponse(content=final_report)
7. 🎬 主程序执行
运行此单元格将启动整个流程,并最终在下方渲染出完整的Markdown报告。
def main():"""主执行入口"""# 检查配置是否填写if not Config.BAIDU_APP_ID or "YOUR_" in Config.BAIDU_APP_ID or \not Config.ERNIE_API_KEY or "YOUR_" in Config.ERNIE_API_KEY:logger.error("❌ 致命错误: 请在第4步的 Config 类中填入您真实的百度智能云和文心模型的 API Keys。")return# 步骤1: 批量预处理,带有缓存机制logger.info(">>> 开始批量视频预处理...")video_log_paths = batch_preprocess_videos(Config)if not video_log_paths:logger.error("所有视频均预处理失败,工作流终止。请检查视频链接或网络连接。")return# 步骤2: 初始化并运行Agent工作流logger.info("\n>>> 预处理完成,开始运行Agent工作流...")workflow = AutoMarketResearchWorkflow(Config, video_log_paths)final_report_content = ""# 流式打印工作流的每一步输出for response in workflow.run():print(response.content, end="")# 持续捕获最终报告的完整内容if "最终舆情洞察报告" in response.content:final_report_content = "" # 报告开始,清空内容else:final_report_content += response.content# 步骤3: 使用Markdown格式优雅地展示最终报告logger.info("\n\n>>> 工作流执行完毕,正在渲染最终报告...")final_report_from_state = workflow.session_state.get('final_report')if final_report_from_state:# 使用Markdown格式优雅地展示最终报告display(Markdown(final_report_from_state))else:# 如果因为某些原因 state 中没有报告,再给出一个明确的失败提示error_message = "# 未能生成最终报告\n工作流已结束,但在 session_state 中未找到 'final_report'。请检查策略师Agent的运行日志。"display(Markdown(error_message))# --- 运行! ---
if __name__ == "__main__":main()
最终输出:
新款汽车市场洞察报告
1. 核心特性正负面评价统计分析
根据聚合舆情数据库,我们对新款汽车的核心特性进行了正负面评价的统计分析。以下是主要特性的情感分布:
- 3.0T直列六缸发动机: 正面评价: 100%
- 48伏轻混系统: 正面评价: 100%
- 采埃孚变速箱: 正面评价: 100%
- 前置适时四驱和多片离合器: 正面评价: 100%
- 华为ADS 2.0智驾系统: 正面评价: 100%
- CDC可变阻尼减震器和单腔空气悬挂: 正面评价: 100%
- 竞品对比(奔驰、宝马、奥迪): 负面评价较多
2. 主要优缺点总结
优点
-
3.0T直列六缸发动机:
- 用户评价:“3.0t,直接最大马力381匹,最大扭矩520牛米,百公里加速仅需4.8秒。”
-
48伏轻混系统:
- 用户评价:“车加入了48伏轻混系统,当速度起来之后,发动机介入,动力采用了直列六缸布局,可以做到动力输出更强劲,更平稳。”
-
采埃孚变速箱:
- 用户评价:“变速箱的换挡逻辑清晰,仿佛它能读懂你的心思,迅速降低到合适的档位,既满足了动力需求,同时也尽量减少了更多的顿挫感。”
-
前置适时四驱和多片离合器:
- 用户评价:“在非铺装路面上,它才会自动切换到四驱,可以提供更好的驾驶体验和稳定性。”
-
华为ADS 2.0智驾系统:
- 用户评价:“它搭载了华为研发的ADS 2.0智驾系统,基本上哪里都能开。”
-
CDC可变阻尼减震器和单腔空气悬挂:
- 用户评价:“底盘采用了电动四驱,领先全系标配的CDC可变阻尼减震器和单腔空气悬挂,不论是配置还是用料都属于上乘。”
缺点
- 竞品对比中的负面评价:
- 用户评价(奔驰、宝马、奥迪): “呆个两三年哪有BBA(奔驰、宝马、奥迪)有面子,甚至不如奥迪A6L有面子,一个小康出品的车吧,就是个杂牌货被你吹得像个豪车。”
3. 竞品对比分析
-
奔驰:
- 负面评价集中在品牌价值方面,认为新款汽车不如奔驰有面子。
- 用户评价:“你你却还停留在70、80后的BBA(奔驰、宝马、奥迪)时代,问界M9提鞋都不配。”
-
宝马:
- 正面评价:宝马的驾驶体验仍然受到认可。
- 负面评价:认为新款汽车在某些方面已经超越宝马。
- 用户评价:“论舒适豪华都说奔驰舒适豪华,但问界M9比奔驰还要舒适,内饰要比奔驰E还豪华,高档,加速也比宝马快。”
-
奥迪:
- 负面评价:与奔驰、宝马类似,认为新款汽车在某些方面已经超越奥迪。
- 用户评价:“满大街的BBA,眼下国内很多款车型已经超越了我们一代人过时的梦想了。”
-
问界M9:
- 正面评价:在多个方面(舒适性、内饰豪华度、加速性能、智能化和辅助驾驶)都得到了高度评价。
- 用户评价:“买问界M9的车主,那都是真大哥,家里都是已经有两部三部车子的了,都是家里已经有奔驰、宝马、奥迪的了,再买问界M9是为了提高享受生活,提升出行的品质。”
4. 结论与建议
结论
- 新款汽车在动力性能、驾驶体验、智能化和辅助驾驶方面得到了用户的高度评价。
- 竞品对比中,奔驰、宝马和奥迪在品牌价值方面仍然有一定优势,但新款汽车在多个方面已经表现出超越竞品的潜力。
- 问界M9作为新款汽车的竞品,在舒适性、内饰豪华度、加速性能、智能化和辅助驾驶方面都得到了用户的认可。
建议
- 品牌建设:加强品牌宣传,提升品牌价值和知名度,以更好地与奔驰、宝马和奥迪等竞品竞争。
- 产品优化:继续优化产品性能,特别是在智能化和辅助驾驶方面,以保持领先地位。
- 市场定位:明确市场定位,针对已有豪车(如奔驰、宝马、奥迪)的车主进行精准营销,强调新款汽车在提升生活品质和出行体验方面的优势。
通过以上分析和建议,我们相信新款汽车在市场上将有更大的发展潜力和竞争力。


)





)

)

)


)



