YOLO — YOLOv5模型以及项目详解
文章目录
- YOLO --- YOLOv5模型以及项目详解
- 一,开源地址
- 二,改进点
- Focus 模块
- 三,网络结构
- 3.1 CSP1_X 与 CSP2_X
- 3.2 自适应Anchor的计算
- 3.3 激活函数
- 3.3.1 SiLU
- 3.3.2 Swish
- 3.4 Bottleneck
- 3.5 C3
- 3.5.1 BottleneckCSP
- 3.5.2 C3
- 3.6 SPPF
- 四,开源项目
- 4.1 项目构建
- 4.2 项目流程
- 4.2.1 下载源码
- 4.2.2 新建环境
- 4.2.3 安装包
- 4.2.4 下载推理文件
- 4.2.5 常用命令
- 4.2.6 数据集
- 4.2.7 模型训练
- 4.2.8 恢复训练
- 4.2.9 导出onnx
- 4.2.10 推理
- 4.2.11 onnx推理
- 4.3 模型应用
- 4.3.1 实例分割
- 4.3.2 图像分类
- 五,优缺点
一,开源地址
-
YOLOV5并没有学术论文,是一个开源项目,是 Ultralytics 公司于 2020 年6月9 日发布的
-
项目可以在 github 搜到:https://github.com/ultralytics/yolov5
二,改进点
- 主干网络是修改后的 CSPDarknet53,后面跟了 SPPF 模块
- 网络最开始增加 Focus 结构
- 颈部网络采用 PANet、FPN
- 激活函数换成了 SiLU、Swish
- 采用 CloU 损失
Focus 模块
-
YOLOv5 刚推出时,为了提升模型效率,采用了 Focus 模块 作为网络的初始特征提取层,传统卷积下采样会丢失部分空间信息,Focus 模块旨在在不丢失信息的前提下进行高效下采样
-
**核心目标:**将高分辨率图像的空间信息通过切片操作转换为通道信息,从而实现高效、无信息损失的下采样
-
Focus 模块是一种用于特征提取的卷积神经网络层,用于将输入特征图中的信息进行压缩和组合,从而提取出更高层次的特征表示,它被用作网络中的第一个卷积层,用于对输入特征图进行下采样,以减少计算量和参数量
-
Focus 层在 YOLOv5 中是图片进入主干网络前,对图片进行切片操作,原理与 Yolov2 的 passthrough 层类似,采用切片操作把高分辨率的图片(特征图)拆分成多个低分辨率的图片(特征图),即隔列采样+拼接
-
具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了 4 张图片,4 张图片互补,但是没有信息丢失,这样一来,将空间信息就集中到了通道空间,输入通道扩充了 4 倍,即拼接起来的图片相对于原先的 RGB 3 通道模式变成了 12 个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图
-
案例:假设输入一张图像大小为 640x640x3
-
第一步:640 x 640 x 3的图像输入Focus结构,采用切片操作
-
第二步:然后进行一个连接(concat),变成 320 x 320 x 12 的特征图
-
第三步:经过一次 32 个卷积核的卷积操作,最终输出 320 x 320 x 32 的特征图
-
-
在 YOLOv5 刚提出来的时候,有 Focus 结构,从 YOLOv5 第六版开始, 就舍弃了这个结构,改用 k=6×6,stride=2 的常规卷积
三,网络结构
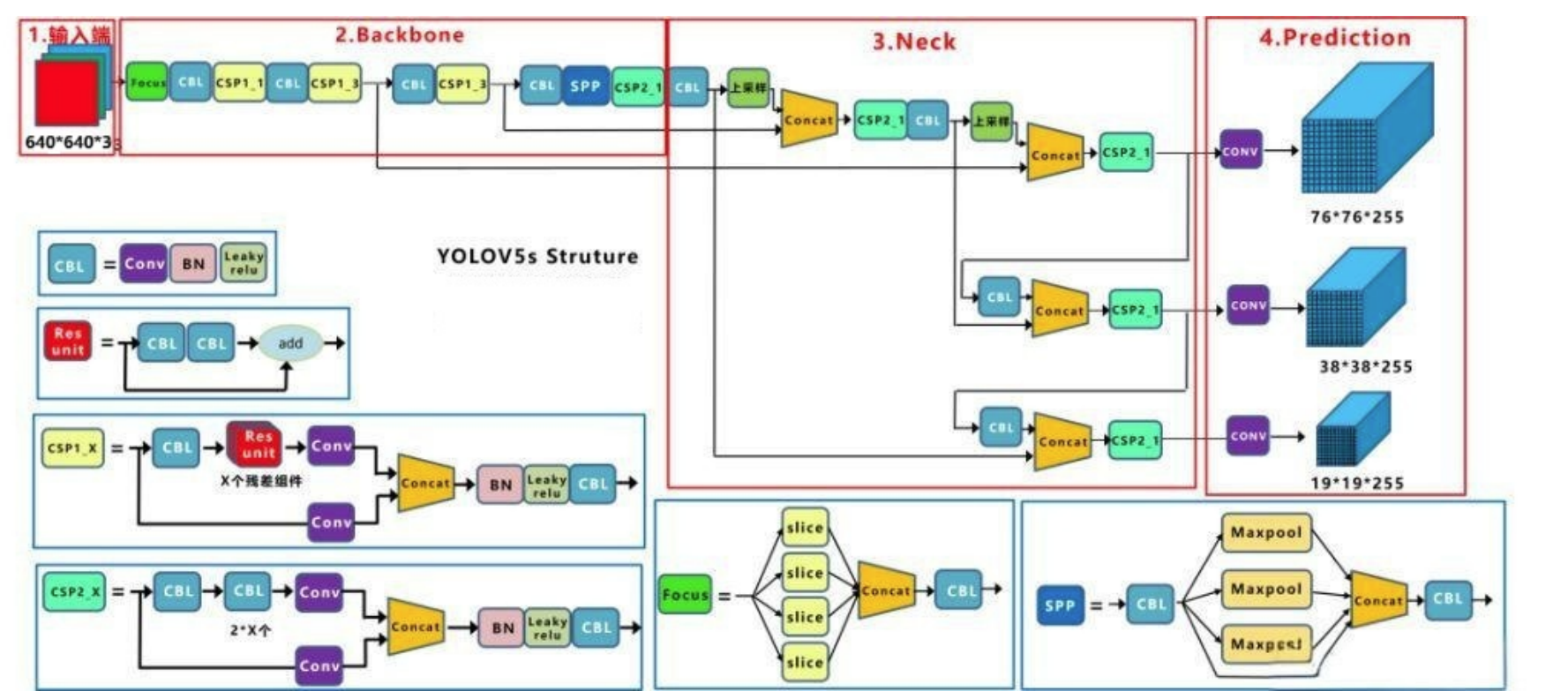
3.1 CSP1_X 与 CSP2_X
| 模块名称 | CSP1_X | CSP2_X |
|---|---|---|
| 定义 | 带 shortcut(残差连接)的 CSP 模块 | 不带 shortcut 的 CSP 模块 |
| 结构特点 | 内部包含带有 shortcut 的 Bottleneck 结构 | 内部没有 shortcut 连接,仅通过卷积操作进行特征提取 |
| 应用场景 | 主要用于 backbone 部分,如 CSPDarknet53,增强特征提取能力 | 主要用于 neck 部分,如 PANet(Path Aggregation Network),进行特征聚合 |
| X 的含义 | 表示 bottleneck 的数量 | 表示 bottleneck 或其他卷积模块的数量 |
3.2 自适应Anchor的计算
- 在 YOLOv3、YOLOv4 中,训练不同的数据集时,计算初始 Anchor 的值是通过单独的程序运行的。但 YOLOv5 中将此功能嵌入到代码中,每次训练时会自适应的计算不同训练集中的最佳 Anchor 值
- 实现方式:
- 在训练开始前,YOLOv5 会自动加载训练集中的标注框
- 使用 K-Means 聚类算法计算 Anchor
- 将结果作为初始 Anchor 值用于模型初始化
3.3 激活函数
激活函数:使用了 SiLU 激活函数、Swish 激活函数两种激活函数
3.3.1 SiLU
- YOLOv5 的 Backbone 和 Neck 模块和 YOLOv4 中大致一样,都采用 CSPDarkNet 和 FPN+PAN 的结构,但是网络中其他部分进行了调整,其中 YOLOv5 使用的激活函数是 SiLU
- SiLU(x)=x⋅σ(x)SiLU(x) = x·\sigma(x)SiLU(x)=x⋅σ(x),具备无上界有下届、平滑、非单调的特性
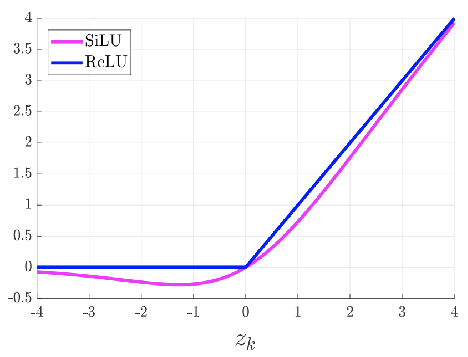
3.3.2 Swish
Swish 激活函数是一个近似于 SiLU 函数的非线性激活函数
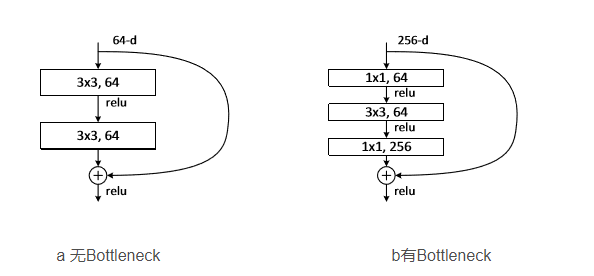
3.4 Bottleneck
Bottleneck 是用于减少参数和计算量的结构,其设计灵感来自于ResNet,结构如下:
- 1x1卷积:用于减少特征图的通道数
- 3x3卷积:用于提取特征,后接一个 Batch Normalization 层和 ReLU 激活函数
- 1x1卷积:用于恢复特征图的通道数,后接一个BN层
- 跳跃连接(Shortcut):将输入直接加到输出上,以形成残差连接
3.5 C3
- YOLOv5 中的 C3 模块在 CSP上进行了优化,非常相似但略有不同:
- YOLOv5 一共使用过两种 CSP 模块
- v4.0 版本之前的 BottleneckCSP,用的 LeakyReLU 作为激活函数
- v4.0 版本之后的 C3,用的 SiLU 作为激活函数
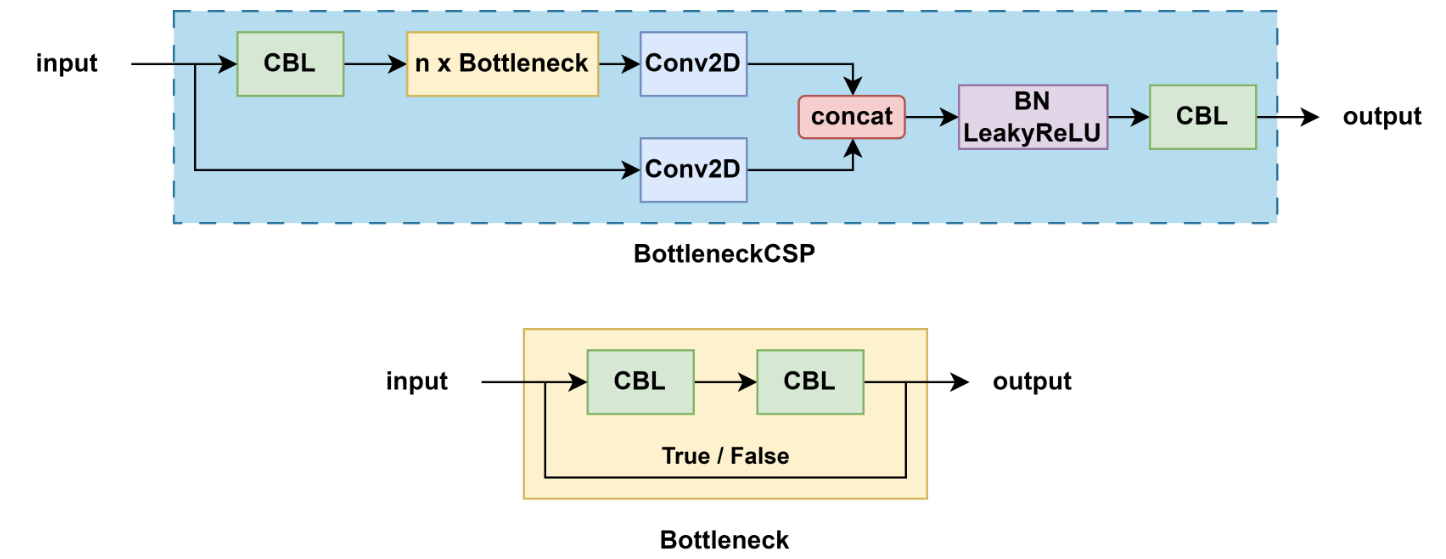
3.5.1 BottleneckCSP
- 结构特点:
- 包含多个带 shortcut 的 Bottleneck
- 输入通道被划分,一部分直接传递,一部分经过 Bottleneck 块
- 激活函数:LeakyReLU
- 用途:主要用于早期 YOLOv5 的 backbone
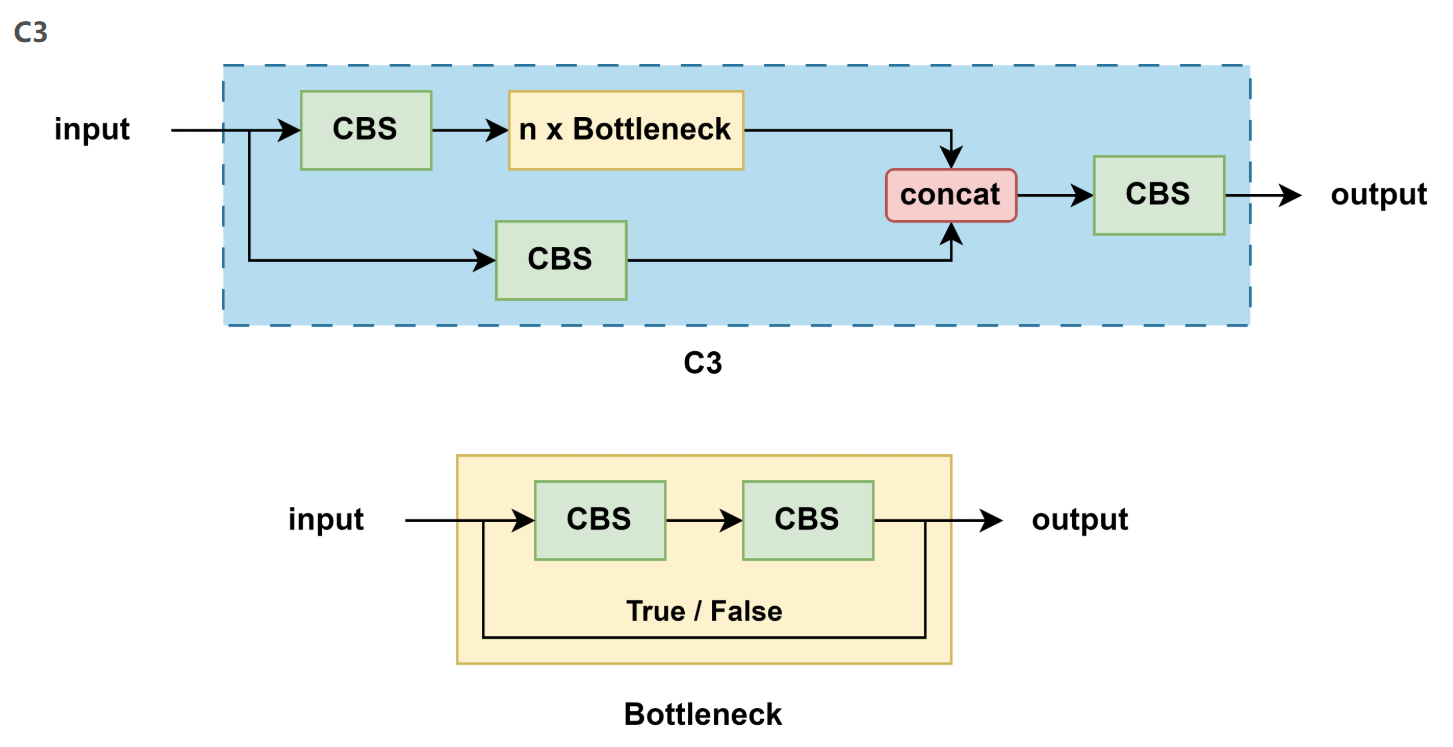
3.5.2 C3
- 结构特点:
- 不再使用 shortcut(即 Bottleneck 不带残差连接)
- 更加简洁,更适合部署
- 激活函数:SiLU
- 用途:广泛用于 backbone 和 neck(如 PANet)
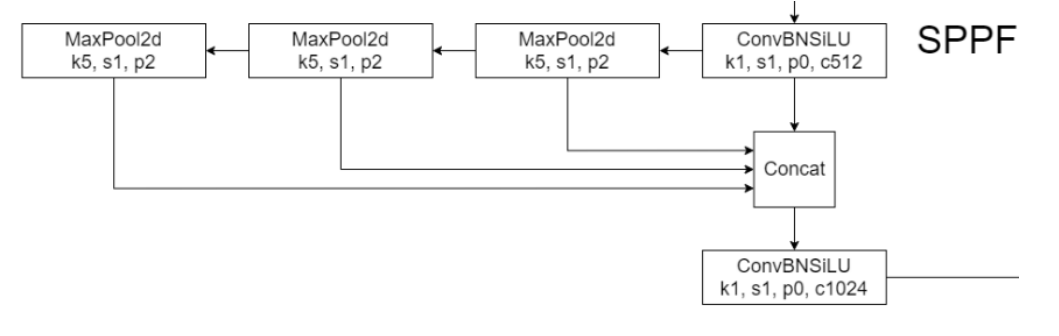
3.6 SPPF
- 将卷积核大小变成相同,然后将并行变成了串行+并行,2个K5池化=1个K9池化,3个K5池化=1个K13池化,也就是结果相同的基础上,速度更快,计算量更小
- 对于连续堆叠 n 层,每层使用大小为 k 的核的操作(例如卷积或池化),其等效感受野大小可以通过以下公式计算:K等效=1+n(k−1)K_{等效}=1+n(k−1)K等效=1+n(k−1)
| 层数 n | 卷积核大小 k | 等效感受野 |
|---|---|---|
| 1 | 5 | 1+1×(5−1)=5 |
| 2 | 5 | 1+2×(5−1)=9 |
| 3 | 5 | 1+3×(5−1)=13 |
四,开源项目
4.1 项目构建
使用github或者gitee
-
GitHub 官方仓库:
https://github.com/ultralytics/yolov5 -
Gitee 镜像地址:
https://gitee.com/mirrors/YOLOv5
4.2 项目流程
4.2.1 下载源码
第一步:下载 yolov5 源码,前面的步骤已经完成
4.2.2 新建环境
第二步:新建环境,见
https://blog.csdn.net/m0_73338216/article/details/146123256
4.2.3 安装包
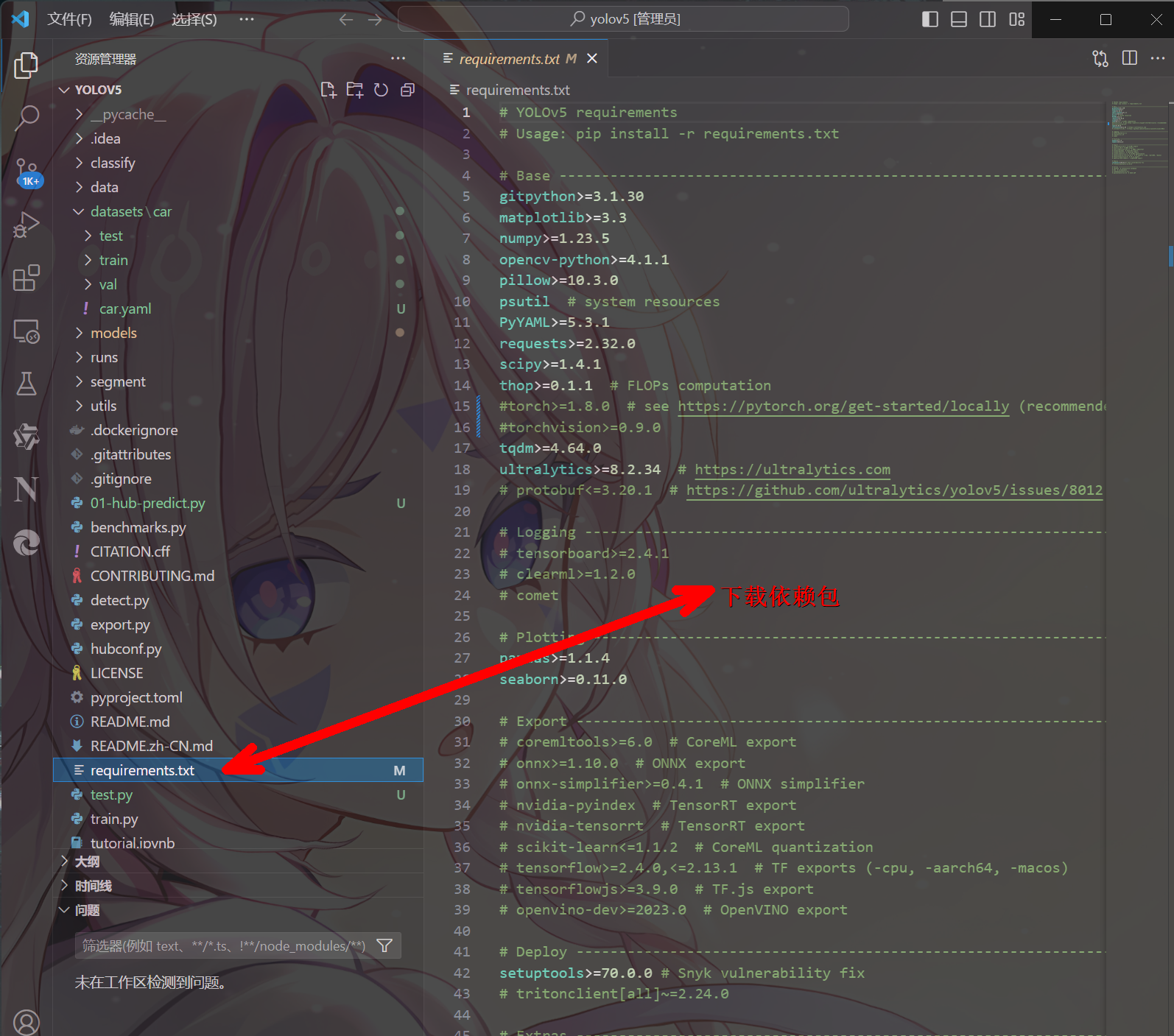
第三步:在 Python>=3.8.0 环境中安装 requirements.txt,且要求 PyTorch>=1.8,命令pip install -r requirements.txt,可以加上镜像地址提高下载速度,命令:pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple

- 详细安装的内容信息可以打开 yolov5 源码中的 requirements.txt 文件查看
- **注意:**因为 pytorch 框架对应的内容,我们事先已经通过命令的方式安装好了,所以在安装 requirements.txt 内容之前,我们需要把安装 pytorch 框架相关的内容注释掉,如下:
4.2.4 下载推理文件
第四步:下载 yolov5 推理模型,地址https://github.com/ultralytics/yolov5/tree/master/models
- YOLOv5的一些主要模型变体:
- YOLOv5n:
- 这是最小的变体,适用于嵌入式设备或资源受限的环境
- 牺牲了一定的准确性以换取更快的速度
- YOLOv5s:选择
- 较小的模型,适合在边缘设备上使用
- 相比于更大的模型,它提供了更好的速度,但在精度上有所降低
- YOLOv5m:
- 中等大小的模型,平衡了速度和精度
- 适用于大多数常规硬件
- YOLOv5l:
- 较大的模型,提供了更高的检测精度
- 在高端硬件上可以运行良好,但速度较慢
- YOLOv5x:
- 最大的模型,具有最高的精度
- 需要高性能的硬件来保证实时处理速度
- YOLOv5n:
- 各个模型测试速度参数:
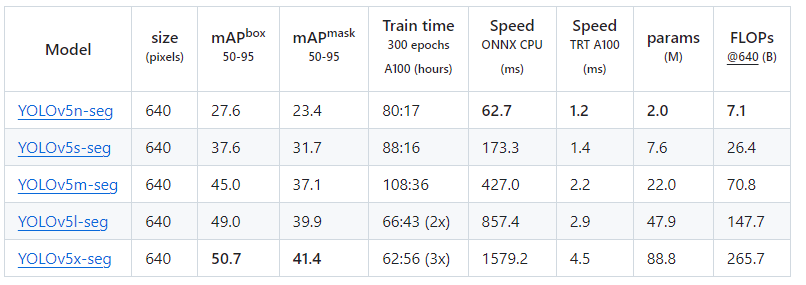
下载好模型后将其复制在主目录下
4.2.5 常用命令
第五步:执行命令python detect.py --weights <weights_path> --source <source>,完成推理,结果默认保存到 runs/detect
| 参数 | 作用 | 示例与说明 |
|---|---|---|
detect.py | YOLOv5 提供的目标检测脚本 | 运行检测的主入口 |
--weights <weights_path> | 指定模型权重文件路径 | --weights yolov5s.pt 使用 YOLOv5-s 预训练权重 |
--source <source> | 指定输入源,支持多种形式 | 见下表,按类型分列 |
| 输入源类型 | 示例 | 说明 |
|---|---|---|
| 默认摄像头 | 0 | 使用电脑默认摄像头(内置或外接) |
| 单张图像 | img.jpg | 直接指定一张图片 |
| 单个视频 | vid.mp4 | 直接指定一个视频文件 |
| 屏幕截图 | screen | 实时截取屏幕作为输入(部分版本需验证支持) |
| 目录 | path/ | 目录下所有支持的图像/视频文件均作为输入 |
| 文本列表 | list.txt | 每行一个图像/视频路径 |
| 流媒体列表 | list.streams | 每行一个流媒体链接 |
| Glob 模式 | 'path/*.jpg' | 匹配目录下所有 .jpg 图片 |
| YouTube 视频 | 'https://youtu.be/LNwODJXcvt4' | 直接从 YouTube URL 读取视频流 |
| 网络流 | 'rtsp://example.com/media.mp4' | 通过 RTSP / RTMP / HTTP 协议读取实时或点播视频 |
4.2.6 数据集
第六步:数据集标注
-
模型训练的数据、验证的数据都是由专门的人标注制作的,常用的标注工具labelImg、labelme。 这里介绍 labelImg 的使用
- 新建虚拟环境,略 -
激活环境,输入命令
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple安装 labelimg 库
在激活环境下,执行命令labelimg打开 labelimg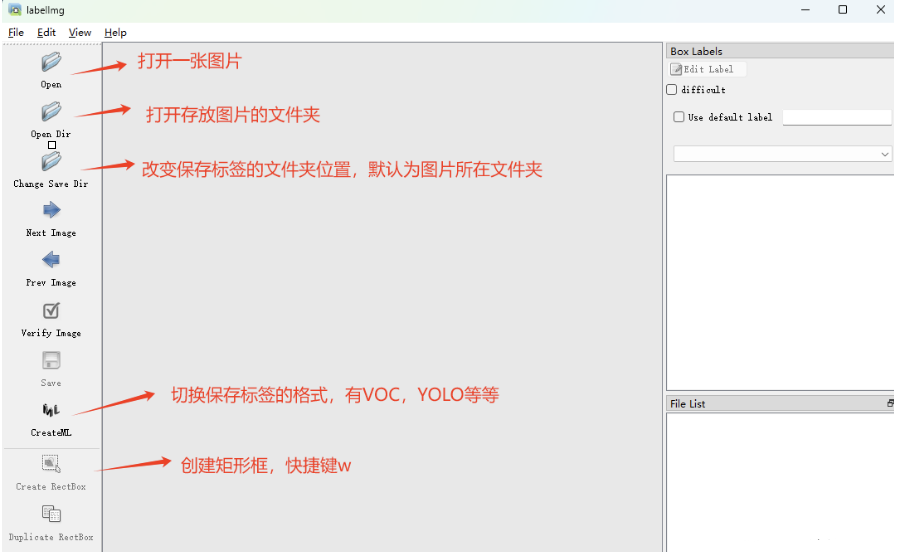
标注完成后的数据集,图示: -
images:存放需要被标注的图片信息
-
labels:存放标注的图片的位置、类型信息
4.2.7 模型训练
执行以下命令训练模型,结果默认保存到 runs/train
python train.py --data .\data\coco.yaml --img 640 --epochs 25 --weights .\yolov5s.pt --cfg .\models\yolov5s.yaml --batch-size 2 --device 0
| 参数 | 说明 | 示例/取值解释 |
|---|---|---|
train.py | 主训练脚本:负责加载数据、构建模型、设置优化器、定义损失函数并执行训练循环。 | 直接运行 python train.py … |
--data | 数据集配置文件路径(YAML),内含训练/验证集路径、类别数等信息。 | --data coco.yaml 或自定义 --data mydata.yaml |
--img | 输入图像尺寸(正方形边长,像素)。 | --img 640 表示 640×640 |
--epochs | 训练总轮数(完整遍历数据集的次数)。 | --epochs 25 表示训练 25 个 epoch |
--weights | 初始权重文件路径;空串 '' 表示从零开始训练。 | --weights ./yolov5s.pt 加载预训练权重 |
--cfg | 模型架构配置文件路径(YAML)。 | --cfg yolov5s.yaml 使用 YOLOv5-small 结构 |
--batch-size | 每轮迭代使用的样本数量;越大越稳定,但显存占用高。 | --batch-size 2 |
--device | 训练设备选择。 • 0:第 0 块 GPU• cpu:强制使用 CPU• -1:自动选择可用 GPU | --device 0 |
-
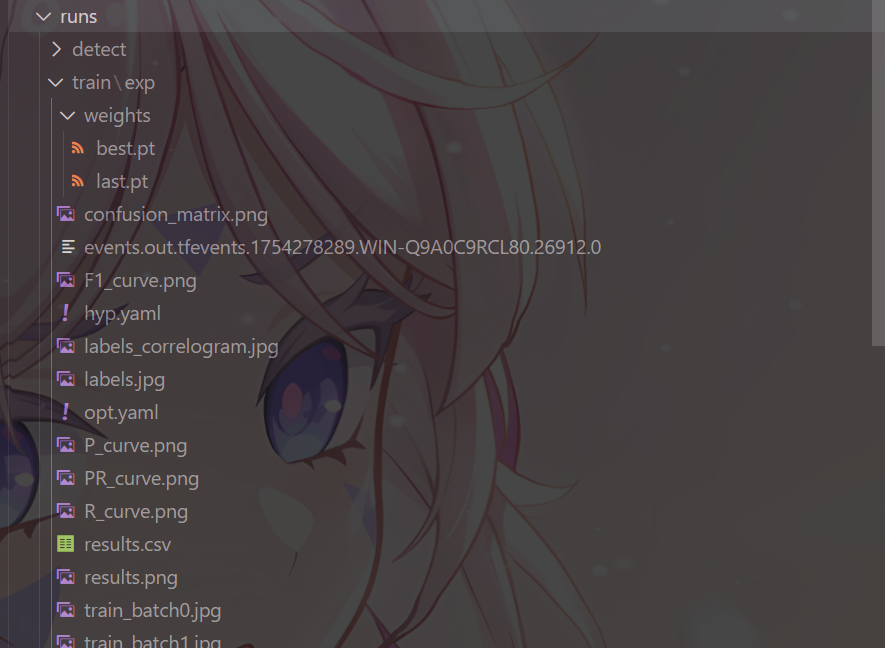
训练结果,这个文件夹中包含了很多文件,重要内容如下:
-
weights 文件夹下,有两个后缀名为
.pt的文件best.pt:表示在整个训练过程中性能最佳的模型权重,用于推理last.pt:表示训练结束时的最后一个模型权重,用于设置下次训练基于这个基础上继续训练,但是需要修改很多参数
4.2.8 恢复训练
如果训练过程中意外停止,在训练指令后面加上 --resume 参数可以恢复训练,并且不需要同时指定 --weights 参数。--resume 会自动加载最近一次保存的检查点(包括模型权重、优化器状态等)
python train.py --weights runs/train/exp/weights/last.pt --resume
4.2.9 导出onnx
python export.py --weights yolov5s.pt --img 640 --batch 1 --device 0 --include onnx
4.2.10 推理
使用 detect.run 进行推理:
from yolov5 import detect
detect.run(weights='yolov5s.onnx', # 权重文件路径source='data/images', # 输入源路径img_size=640, # 输入图像尺寸conf_thres=0.25, # 置信度阈值iou_thres=0.45, # IoU阈值max_det=1000, # 最大检测数量device='0', # 设备view_img=False, # 显示检测结果save_txt=False, # 保存检测结果为txt文件save_conf=False, # 保存置信度到txt文件save_crop=False, # 裁剪并保存检测到的对象nosave=False, # 保存图像/视频classes=None, # 检测所有类agnostic_nms=False, # 类无关的非极大值抑制augment=False, # 推理增强visualize=False, # 可视化特征图update=False, # 更新所有模型project='runs/detect', # 结果保存目录name='exp', # 结果保存子目录exist_ok=False, # 允许现有目录line_thickness=3, # 画框线条粗细hide_labels=False, # 隐藏标签hide_conf=False, # 隐藏置信度half=False, # 半精度推理dnn=False # 使用OpenCV DNN模块
)
4.2.11 onnx推理
import onnxruntime as ort
import numpy as np
import cv2# 创建ONNX Runtime推理会话
providers = ['CUDAExecutionProvider'] # ['CPUExecutionProvider'] 这是指定CPU
session = ort.InferenceSession('yolov5s.onnx', providers=providers)
# 读取输入图像
img = cv2.imread('data/images/bus.jpg')
img = cv2.resize(img, (640, 640))
img = img.transpose((2, 0, 1)) # HWC to CHW
img = np.expand_dims(img, axis=0).astype(np.float32) / 255.0
# 进行推理
outputs = session.run(None, {'images': img})
print(outputs[0].shape)
4.3 模型应用
4.3.1 实例分割
下载yolov5s-seg.pt文件
python segment/predict.py --weights yolov5s-seg.pt --source data/images/bus.jpg
4.3.2 图像分类
下载yolov5s-cls.pt文件
python classify/predict.py --weights yolov5s-cls.pt --source data/images/bus.jpg
五,优缺点
| 维度 | 优点 | 缺点 |
|---|---|---|
| 速度 | • 单阶段架构,推理极快,可达数百 FPS • 轻量级,适合实时应用与边缘部署 | • 计算量仍高于 YOLOv8-nano 等轻量模型 |
| 精度 | • COCO mAP≈56.8%,处于同期 SOTA 水平 • 数据增强 + 自适应锚框,泛化能力较强 | • 小目标检测、密集重叠场景、旋转/倾斜目标易漏检 • 极端遮挡、低光照环境下精度下降 |
| 模型与训练 | • 代码开源完整,社区生态丰富 • 支持多 scale 训练、断点续训、混合精度 | • anchor-based,需预设锚框,对形状不规则目标不友好 • 在新数据集上往往需要额外微调 |
| 部署 | • 支持 ONNX、TensorRT、OpenVINO、ncnn 等多种格式,跨平台方便 | • 对显存/内存仍有要求,极低算力嵌入式设备需做剪枝或量化 |
| 易用性 | • pip 一键安装,命令行/脚本接口简单 | • 超参数较多,新手调参门槛高于 YOLOv8 的“零参”模式 |







:重构威胁追溯体系)




![[特殊字符] TTS格局重塑!B站推出Index-TTS,速度、音质、情感表达全维度领先](http://pic.xiahunao.cn/[特殊字符] TTS格局重塑!B站推出Index-TTS,速度、音质、情感表达全维度领先)






