B站维度之言:
B 站 2025 新声计划:IndexTTS 全维度拆解
——从开源血统到中文特调的架构复盘
1:打破边界:Index-TTS 的技术动因
场景野心:直播实时口播、无障碍字幕、AI 虚拟 UP 主……B 站需要一把“声音瑞士军刀”,于是 IndexTTS 立项。
1.1站在巨人的肩膀上:Index-TTS的起点
如果把 IndexTTS 比作一辆性能跑车,那它的底盘就是 Coqui 的 XTTS 与 Tortoise——前者负责“多语言漂移”,后者主打“高保真声浪”。可惜,这套原厂配置在上中文赛道时暴露出两大硬伤:
• 多音字陷阱:中文的“长/长、行/行”像连续发卡弯,原版引擎经常读错弯心。
• 实时性瓶颈:Tortoise 的“高保真”等于“慢工出细活”,在 B 站直播这种“零延迟”赛道里明显掉队。
再加上 CosyVoice2、Fish-Speech、F5-TTS 等国产改装件仍留有 WER 偏高、音色发涩的小毛病,B 站干脆自己下场调校——把弹幕、虚拟主播、实时口播这些“极端工况”统统写进需求表,于是 IndexTTS 应运而生:既能在弹幕雨里精准咬字,又能在直播间一脚油门瞬时出音。
1.2需求翻译机:IndexTTS 想一口气解决哪些难题
1.3时间卷轴 & 弹幕回声:IndexTTS 进化日志
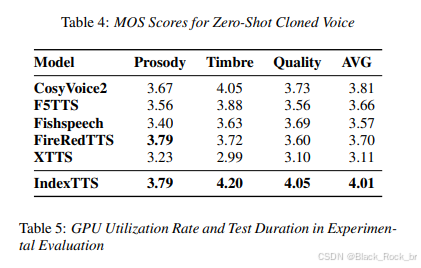
- 音质飞跃,声如其人:全面优化音色克隆能力与语音自然度,让合成声音在情感、语调和细节上更贴近真实人声,实现高保真语音输出。
- 精准发音,告别“读错字”:引入拼音引导机制,有效解决中文多音字识别难题,显著降低词错误率,提升语音表达的准确性和可懂度。
- 高效引擎,规模落地:在不牺牲音质的前提下,大幅优化训练与推理效率,降低资源消耗,支持高并发、低延迟的工业级大规模部署。
项目关键里程碑(基于公开线索与技术趋势推测):
2024年末:B站正式启动 IndexTTS 研发项目,融合 XTTS 的高效架构与 Tortoise-TTS 的高自然度优势,致力于打造新一代开源中文语音合成系统。 2025年2月:项目在社交平台 X 上首次预热,官方透露 IndexTTS 在词错误率(WER)等关键指标上已超越主流模型,引发社区广泛关注。 2025年3月:预计正式开源发布,时间点契合当前技术节奏,有望迅速成为中文语音合成领域的重要力量。
社区反响与潜力预期:
早期曝光后,X 平台用户热议其创新的拼音纠错机制,尤其在处理多音字和生僻词方面表现突出。不少开发者表示期待将其集成至语音助手、有声内容生成等场景。IndexTTS 不仅展现了技术实力,更有望树立中文TTS的新标准。
1.4声临其境:Index-TTS 赋能的智能生态版图
它能让虚拟主播秒换声线,也能给短视频一键“开口说话”;在课堂里化身 AI 朗读助教,在直播间充当实时弹幕播报员。开源社区把它当“新基建”疯狂二创,投资方则盯上了它背后的 SaaS 收费、广告配音、IP 声库等商业化金矿。
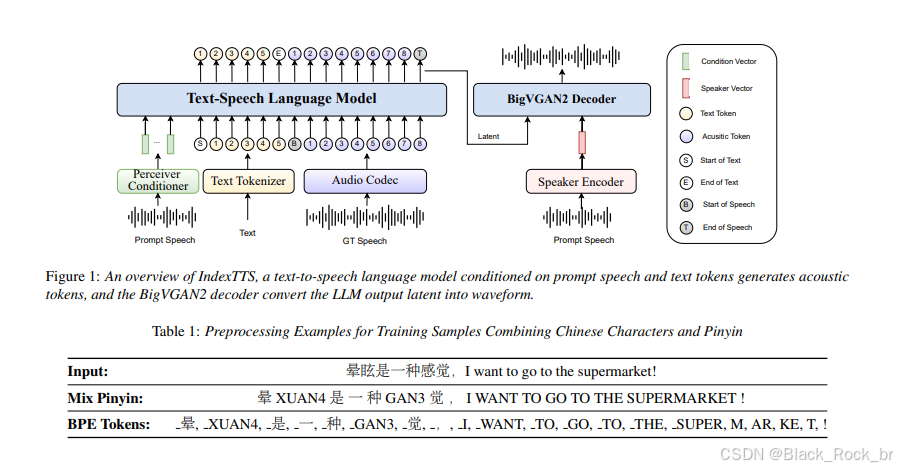
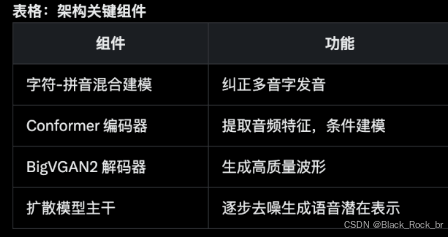
IndexTTS 采用先进的扩散模型与深度神经网络架构,融合了 XTTS 的高效推理能力与 Tortoise-TTS 的高保真语音生成优势,并针对中文语音特点进行了多项创新性改进。通过引入定制化模块,显著提升了语调自然度、多音字处理和音色还原能力。以下是其核心架构与关键技术解析:
1.5汉拼混血引擎:让汉字与拼音同桌飙戏
难题突破:精准攻克中文多音字发音难题
中文中大量存在多音字(如“长”可读作“zhǎng”或“cháng”),其正确发音高度依赖上下文,传统TTS系统常因语义理解不足而误读,影响语音自然度与可懂度。IndexTTS 创新性地引入拼音引导的混合输入建模机制,让用户可通过显式标注拼音来精确控制发音,实现“想怎么读,就怎么读”。
实现方案:
灵活输入层:支持纯文本输入,也支持“文本+拼音”混合模式。用户可在关键位置标注拼音(如“长大”写作“zhǎng大”),系统将拼音作为强先验条件注入生成流程。 智能预处理管道:若未提供拼音,系统自动调用内置语言模型进行上下文感知的拼音预测;若已标注,则优先采用用户指定发音,兼顾自动化与精准控制。
实际效果:
在多音字密集场景下,词错误率(WER)显著下降,发音准确率大幅提升。无论是“重”(chóng / zhòng)、“行”(xíng / háng)还是复杂成语与古诗词,IndexTTS 均能稳定输出符合预期的读音,真正实现“读得准、听得懂”。
1.6声波变形器:Conformer 条件编码的魔法内核
核心架构:基于 Conformer 的多模态特征融合
采用 Conformer(卷积增强型 Transformer)作为骨干网络,融合卷积层的局部感知能力与自注意力机制的长程依赖建模优势,能够高效捕捉语音信号在时间与频域上的复杂特征,为高质量语音合成奠定基础。
• 工作原理:
音色与语调提取:从参考音频中提取声学特征(如梅尔频谱、音高轮廓等),精准捕捉说话人的音色特质和自然语调模式。 条件融合机制:将提取的音频特征与文本及拼音编码进行多层次对齐与融合,作为扩散模型的强引导条件,实现个性化语音的高保真重建。
• 核心优势:
显著提升生成语音的说话人相似度与韵律自然度,让合成声音不仅“像真人”,还能准确还原情感起伏与说话风格,尤其适用于音色克隆、情感化播报等高要求场景。
1.7BigVGAN2:高保真语音重建的核心解码引擎
BigVGAN2:把扩散模型吐出的“草图”瞬间渲染成 Hi-Fi 声波
• 身份:GAN 家族的 2.0 号音效师,BigVGAN 的极速升级版
• 工作流程:
① 接过扩散模型生成的中间声纹“线稿”
② 用对抗训练这把“超清画笔”填补细节、锐化音质
• 战绩:同 WaveNet 这类“老工匠”相比,声线更通透、渲染耗时砍半,推理像开倍速播放一样快。
1.8从噪声到波形:扩散主干的“去噪魔法阵”
传承与进化:基于 XTTS 扩散架构的深度优化
IndexTTS 很可能继承自 XTTS 的核心生成机制,采用去噪扩散概率模型(Denoising Diffusion Probabilistic Models, DDPM),通过逐步从噪声中恢复语音的潜在表示,实现高保真语音合成。
关键改进:
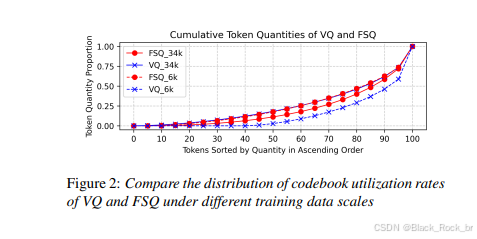
在原始扩散架构基础上,引入 Conformer 编码器增强上下文建模能力,并融合拼音级语言信息作为强条件引导,显著提升去噪过程中的语义连贯性与发音准确性。这一优化不仅加快了生成收敛速度,更有效避免了语音断续、错读或多音字混淆等问题,使合成语音在自然度和可懂度上实现双重跃升。
1.9从数据到模型:IndexTTS 的训练体系解析
燃料与靶心
• 燃料:B 站自家 UP 主的海量语音 + 公开 AISHELL,全部打上拼音标签,像给每段音频配了“发音说明书”。
• 靶心:同时瞄准三发十环——词错率压到最低、音色 MOS 逼近真人、推理延迟砍到毫秒级。
2:从创新到落地:IndexTTS 的高光时刻与现实约束
2.1从痛点出发,打造真正懂中文的TTS
三大杀招,一次说清:
1. 拼音外挂:遇到多音字直接“点名”,读音零踩坑。
2. Conformer+BigVGAN2 双剑合璧:前者精准建模,后者秒级出高清声线,既好听又不卡。
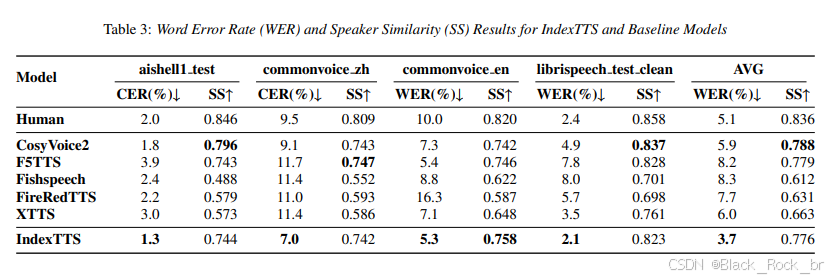
3. 成绩单刷新:WER 把 CosyVoice2 等前辈甩在身后,直接立起中文 TTS 新标杆。
2.2现阶段的不足与未来优化空间
拼音外挂虽好,却像强制“带身份证”——用户得先给句子注音,步骤多一步。
中文专精是把双刃剑:英文、日语等场景暂时“口音生疏”,多语言版图比 XTTS 小一圈。
速度确实快了,但离直播级“150 ms 内响枪”仍有小半步,实时党依旧想再挤一挤性能牙膏。
相关文献
github地址:https://github.com/index-tts/index-tts?tab=readme-ov-file
arxv论文:https://arxiv.org/pdf/2502.05512








)










