文章目录
- 一、微调技术的底层逻辑
- 1.1 预训练与微调的关系
- 1.2 核心目标:适配任务与数据
- 二、经典微调方法详解
- 2.1 全量微调(Full Fine-Tuning)
- 2.2 冻结层微调(Layer-Freezing Fine-Tuning)
- 2.3 参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
- 2.4 超大规模参数模型的Prompt-Tuning方法
- 2.5 微调方法全面对比
- 三、微调技术的应用场景与挑战
- 3.1 典型应用场景
- 3.2 面临的挑战
- 四、未来发展趋势
一、微调技术的底层逻辑
1.1 预训练与微调的关系
预训练模型如同在"知识海洋"中遨游的学者,在海量无监督数据(如互联网文本、百科知识等)里学习语言模式、语义理解、逻辑推理等通用能力。而微调,就是让这位"学者"进入特定"专业领域"(如医疗诊断、金融分析),通过少量标注数据"进修",将通用知识转化为专项任务的解决能力,实现从"博闻强识"到"术业专攻"的跨越。
1.2 核心目标:适配任务与数据
- 任务适配:让大模型理解特定任务的目标,比如文本分类要区分情感正负、命名实体识别要精准提取实体类型,微调通过调整模型参数,强化模型对任务指令的响应逻辑。
- 数据适配:不同领域的数据有独特的词汇、表述和分布,微调使模型学习到当前数据的特征模式,例如法律文本中的专业术语、医疗报告的严谨表述,让模型输出更贴合领域需求。
二、经典微调方法详解
2.1 全量微调(Full Fine-Tuning)
- 技术原理:对预训练模型的所有参数(包括 Transformer 层、嵌入层等)进行更新,利用下游任务的标注数据,重新调整模型的权重,使模型全方位适配新任务。
- 优缺点分析
- 优点:能最大程度利用任务数据,对模型参数进行全面优化,在充足标注数据支持下,可取得很高的任务精度,适合数据丰富、追求极致性能的场景,如大规模文本分类竞赛。
- 缺点:计算成本极高,需要强大的 GPU 算力支持,大模型全量参数更新耗时久;容易过拟合,尤其是数据量较少时,模型可能过度学习训练数据的细节,泛化性下降;还可能"遗忘"预训练阶段的部分通用知识(灾难性遗忘问题)。
2.2 冻结层微调(Layer-Freezing Fine-Tuning)
- 技术原理:冻结预训练模型的部分层(通常是底层,因底层更多学习通用语法、基础语义),仅对顶层(如输出层、部分高层 Transformer 层)参数进行微调。利用顶层的灵活性适配新任务,底层保留通用知识。
- 优缺点分析
- 优点:降低计算量与显存占用,训练效率提升,适合算力有限或数据量适中的场景;一定程度缓解灾难性遗忘,底层保留的通用知识更稳定。
- 缺点:适配效果依赖冻结层与微调层的划分,若划分不合理(如冻结过多关键层),会限制模型对任务的适配能力,需要反复调试层数配置。
2.3 参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
-
技术分支与原理
-
Adapter Tuning:在预训练模型中插入小型 Adapter 模块(如全连接层组成的瓶颈结构),仅训练 Adapter 的参数,模型主体参数冻结。Adapter 学习任务特定的特征转换,灵活适配任务。其结构通常包含down-project层(将高维度特征映射到低维特征)、非线性层和up-project结构(将低维特征映射回原来的高维特征),同时设计了skip-connection结构,确保在最差情况下能退化为identity(类似残差结构)。
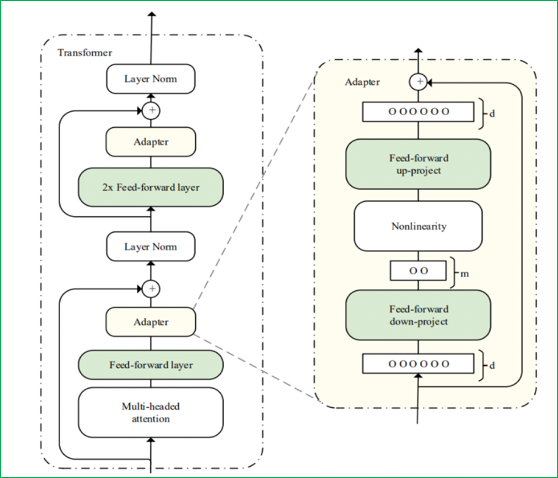
-
LoRA(Low-Rank Adaptation):
数学原理:基于矩阵低秩分解理论,假设权重更新矩阵 ΔW 可分解为两个小矩阵的乘积:
ΔW=B×AΔW = B × AΔW=B×A,其中 B∈Rd×rB ∈ ℝ^{d×r}B∈Rd×r, A∈Rr×kA ∈ ℝ^{r×k}A∈Rr×k, r≪min(d,k)r ≪ min(d,k)r≪min(d,k)
工作机制:- 训练阶段:仅优化低秩矩阵 A、B,预训练权重冻结。矩阵A使用随机高斯分布初始化,矩阵B初始化为全零矩阵,确保训练开始时LoRA模块对模型输出影响为零。
- 推理阶段:将 Wnew=W0+BAW_{new} = W_0 + BAWnew=W0+BA 合并为单一权重,实现零延迟推理
核心优势: - 参数效率:13B 模型全量微调需 130 亿参数,LoRA 仅需 650 万(r=8)
- 避免遗忘:冻结原权重保留通用知识
- 多任务切换:不同任务使用独立 LoRA 权重
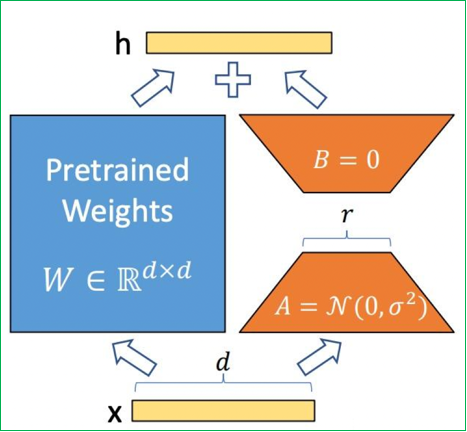
-
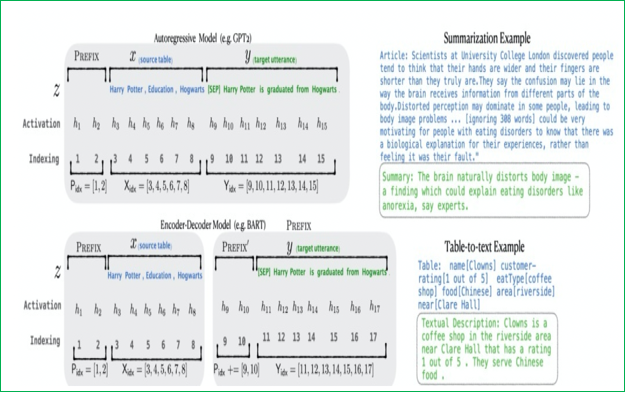
Prefix Tuning:在输入序列前构造一段任务相关的伪tokens作为Prefix,训练时只更新Prefix部分的参数,而Transformer中的其他部分参数固定。它在Transformer模型的每一层内部,注入可学习的“前缀”,这些前缀被添加到Attention机制中的Key(K)和Value(V)向量的计算中。由于直接更新Prefix的参数会导致训练不稳定,通常在Prefix层前面加MLP结构,训练完成后只保留Prefix的参数。
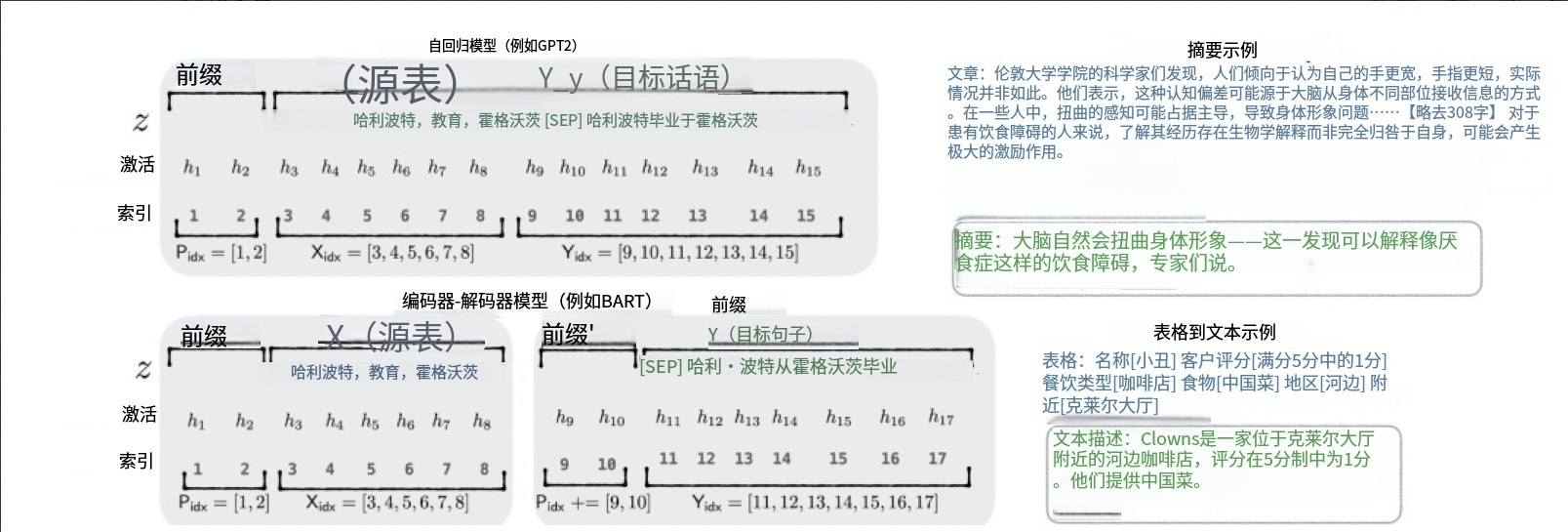
-
Prompt-Tuning:在不修改或更新大型预训练语言模型自身大量参数的前提下,通过学习一小段连续的、可训练的向量序列(即“软提示”Soft Prompt),将其作为输入的一部分,来引导模型在特定下游任务上产生期望的输出。与Prefix-Tuning相比,Prompt-Tuning只在输入层加入prompt tokens,可看作是Prefix-Tuning的简化。
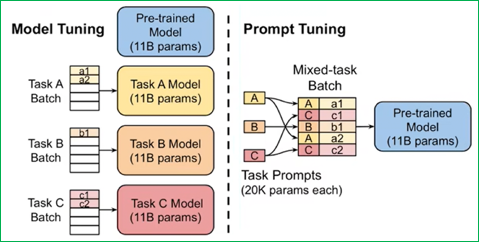
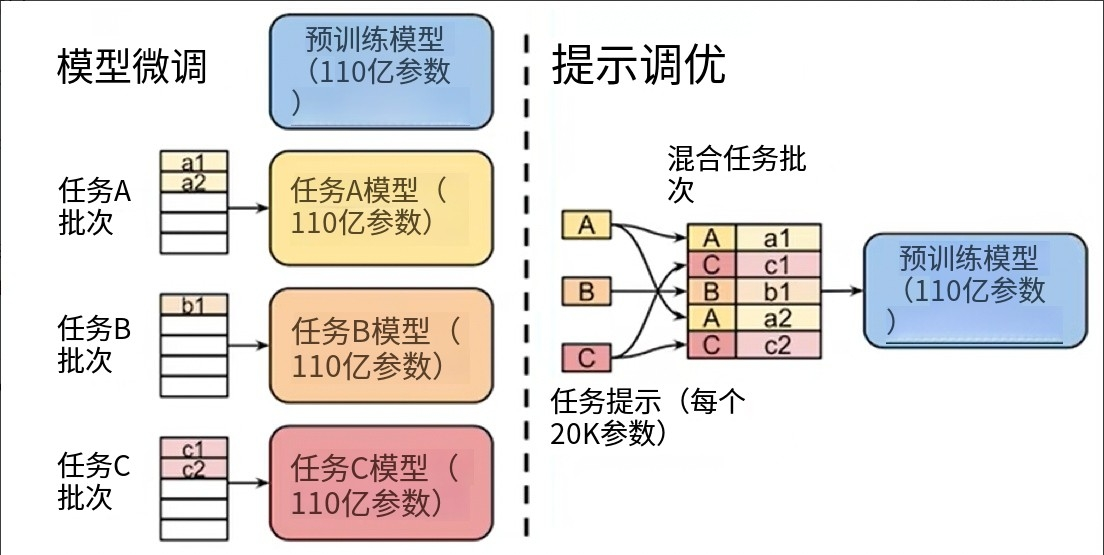
-
-
优缺点分析
- 优点:可训练参数极少(如 LoRA 可减少至原参数的 0.1%-2%),大幅降低算力与显存需求,能在消费级 GPU 甚至 CPU 环境尝试微调大模型;适配多任务场景时,不同任务的 Adapter 或低秩矩阵可快速切换,灵活性高。
- 缺点:部分方法(如 Adapter Tuning)可能因 Adapter 与主体模型的融合问题,在复杂任务上性能略逊于全量微调;LoRA 的低秩分解假设若与模型实际参数分布偏差大,会影响效果,需要调整秩的设置;Prompt-Tuning在小样本学习场景表现欠佳,收敛速度较慢且调参复杂。
2.4 超大规模参数模型的Prompt-Tuning方法
对于超过10亿参数量的模型,Prompt-Tuning所带来的增益往往高于标准的Fine-tuning,主要包括以下几种方法:
-
上下文学习(In-Context Learning):从训练集中挑选少量的标注样本,设计任务相关的指令形成提示模板,用于指导测试样本生成相应结果。包括零样本学习(直接让预训练好的模型进行任务测试)、单样本学习(插入一个样本做指导后再测试)、少样本学习(插入N个样本做指导后再测试)。其优点是零样本或少样本学习、可快速适应不同任务且简单易用;但性能受示例质量影响大,对模型规模要求高,受上下文长度限制且推理成本高。
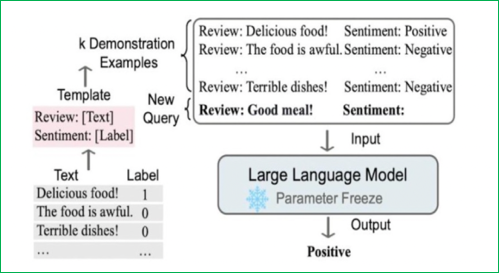
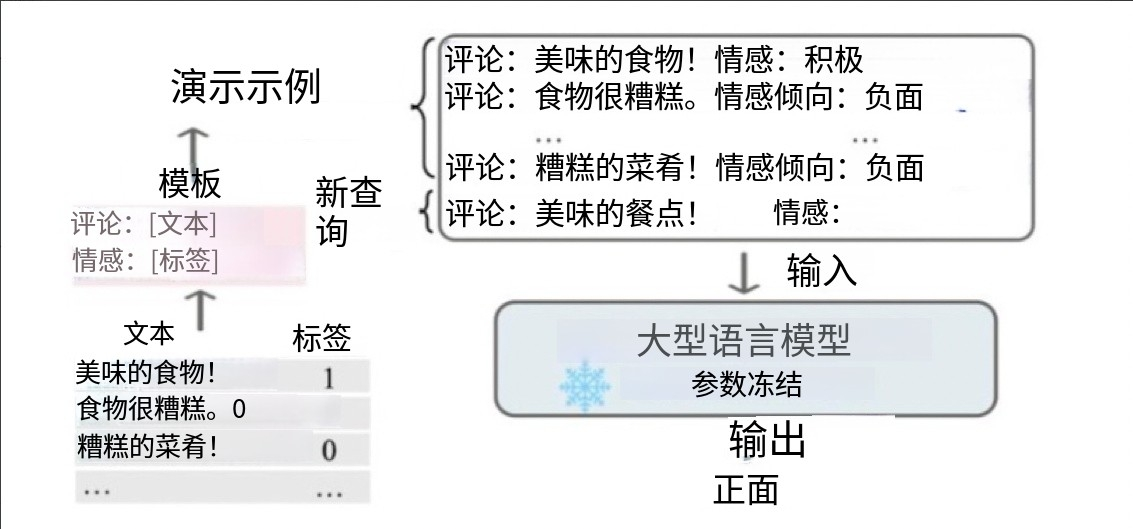
-
指令学习(Instruction-Tuning):为各种类型的任务定义指令并进行训练,以提高模型对不同任务的泛化能力。通过给出更明显的指令/指示,激发语言模型的理解能力,让模型理解并做出正确的action。实现步骤包括收集大量覆盖各种任务类型和语言风格的指令数据,然后在这些数据上对LLM进行微调。其优点是能提高模型对未见过任务的泛化能力、零样本学习能力和指令遵循能力;但需要大量高质量指令数据,收集成本高且微调成本高。
-
思维链(Chain-of-Thought):一种改进的提示策略,用于提高LLM在复杂推理任务中的性能。相比传统上下文学习,多了中间的推导提示。包括Few-shot CoT(将每个演示扩充为包含推理步骤的形式)和Zero-shot CoT(直接生成推理步骤导出答案)。其优点是能提高复杂推理能力且增强可解释性;但需要人工设计CoT示例,对模型规模要求高且推理成本高。
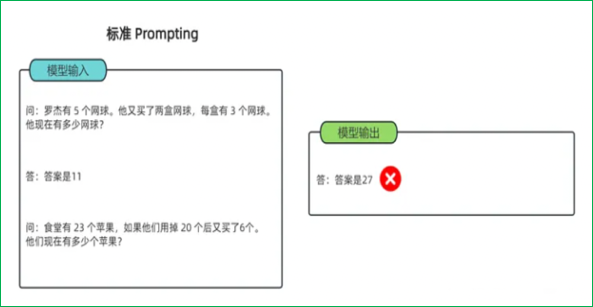
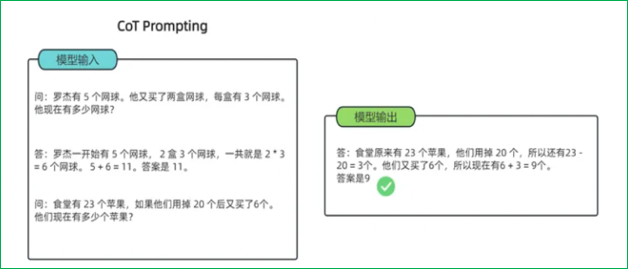
2.5 微调方法全面对比
| 方法 | 可训练参数量 | 显存占用 | 训练速度 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|---|
| 全量微调 | 100% | 极高 | 慢 | 性能最优 | 计算成本高,灾难性遗忘 | 数据充足,追求极致性能 |
| 冻结微调 | 10%-20% | 高 | 中等 | 缓解遗忘,效率较高 | 层选择敏感 | 任务与预训练分布相似 |
| Adapter | 0.5%-5% | 中等 | 中等 | 多任务切换灵活 | 增加推理延迟 | 需要快速适配多任务 |
| Prefix-Tuning | 0.1%-1% | 中等 | 中等 | 无架构修改 | 序列长度受限 | 生成类任务(翻译、摘要) |
| Prompt-Tuning | <0.1% | 低 | 中等 | 最轻量 | 仅适合简单任务 | Few-shot 任务 |
| LoRA | 0.1%-2% | 低 | 快 | 零推理延迟,参数高效 | 秩选择敏感 | 资源受限场景,多任务适配 |
| QLoRA | 0.1%-1% | 极低 | 快 | 4-bit量化,显存需求降70% | 轻微精度损失 | 消费级GPU训练大模型 |
核心结论:
- LoRA 在参数量 (0.1%~1%)、计算成本、显存占用和灵活性上取得最佳平衡,是当前大模型微调的主流选择。
- Prompt-Tuning 最轻量 (参数量<0.1%),但仅适合简单任务。
- Full Fine-Tuning 效果最优但成本极高,适合算力充足的场景。
- Adapter 因引入推理延迟,逐渐被LoRA替代。
三、微调技术的应用场景与挑战
3.1 典型应用场景
- 垂直领域适配:金融领域的舆情分析、医疗领域的病历解读、法律领域的合同审查,通过微调让大模型掌握领域专业知识与任务流程。
- 小众任务落地:如古籍文本的实体识别、方言情感分析,利用微调,以少量标注数据驱动大模型适配小众、稀缺数据的任务。
- 多任务统一优化:在一个模型中适配文本分类、问答、摘要等多个任务,通过 PEFT 等方法,用不同 Adapter 或前缀向量,让模型高效处理多任务场景。
3.2 面临的挑战
- 算力与资源限制:即使 PEFT 技术降低了需求,大模型微调仍对硬件有较高要求,中小企业或个人开发者难以获取充足算力,限制技术落地。
- 数据质量与偏见:下游任务数据可能存在标注错误、样本偏差(如某类情感样本过多),微调会让模型学习到错误或有偏的模式,影响输出公正性与准确性。
- 知识遗忘与冲突:微调过程中,模型可能遗忘预训练的通用知识,或新学的任务知识与通用知识产生冲突(如特定领域的表述与通用语义矛盾 ),需要更优的参数更新策略缓解。
四、未来发展趋势
- 更高效的 PEFT 技术演进:不断探索新的低秩分解、参数更新方式,进一步压缩可训练参数,同时提升适配效果,让微调在极致算力限制下也能高效开展。
- 结合强化学习的微调:引入强化学习(RL),让模型在微调过程中根据奖励机制(如用户反馈、任务效果指标)自主优化,提升模型的长期适应能力与决策质量。
- 跨模态微调拓展:大模型向多模态(文本 + 图像 + 语音)发展,微调技术需适配跨模态任务,学习不同模态数据的融合与任务适配,如多模态情感分析、跨模态生成。
大模型微调技术正处于快速发展与迭代中,从全量微调的“全面革新”,到 PEFT 的“精准高效”,每一种方法都在适配不同的应用需求与资源条件。掌握这些技术,既能让大模型在专业领域发挥价值,也为 AI 落地千行百业提供了可行路径。未来,随着技术突破与生态完善,微调将持续推动大模型从“通用智能体”向“专属任务专家”转变,解锁更多 AI 应用的可能性。
)







![[激光原理与应用-254]:理论 - 几何光学 - 自动对焦的原理](http://pic.xiahunao.cn/[激光原理与应用-254]:理论 - 几何光学 - 自动对焦的原理)







——matplotlib库)


