本篇文章将利用GET请求从OPPO官方网站或公开接口中获取官方授权体验店的分布信息,并通过Python编程语言中的requests库来实现HTTP请求,从而提取详细的门店位置数据。随着OPPO品牌的发展和市场布局的扩展,其官方授权体验店已经遍布全国各大城市和地区,成为连接消费者与品牌的桥梁。因此,掌握如何高效地从网络资源中抓取这些信息变得尤为重要。
首先,我们将探讨如何使用Python的requests库发送GET请求以访问OPPO官方网站或API接口。这包括设置正确的请求头(headers),以便模拟真实的浏览器行为,避免被服务器识别为自动化脚本而拒绝服务。接下来,我们会详细讲解如何解析返回的数据——无论是JSON格式还是HTML页面内容——从中提取所需的门店信息,如店铺名称、地址、经纬度坐标、营业时间等。
在成功获取数据后,本文还将介绍如何对这些原始数据进行清洗和结构化处理,使其更加适合后续分析。例如,可以将数据转换成易于管理和查询的表格形式,或者导入到数据库中。通过对这些结构化数据的深入分析,我们可以揭示OPPO在全国范围内的市场渗透策略、不同城市的布局密度及其与当地人口消费特征之间的关系。
OPPO官方授权体验店门店查询:OPPO 官方授权体验店查询 | OPPO 官方网站
首先,我们找到门店数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
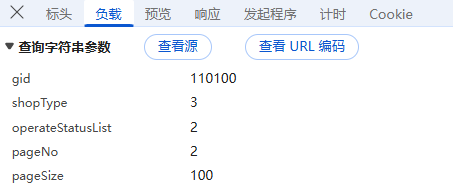
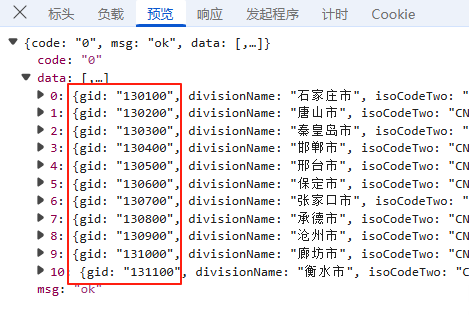
负载:对于GET请求:负载通常包含了传递的参数,有些网页负载可能为空,或者没有负载,因为所有参数都通过URL传递,这里我们可以看到城市编码,当前页数,还是明文,没有进行加密;
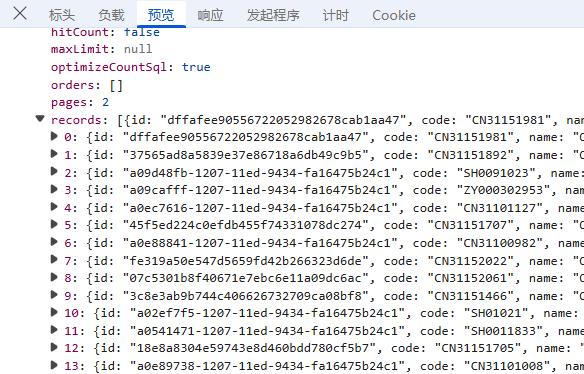
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应数据存储位置,获取所有店铺列表的相关标签数据;
- 我们通过获取和改变行政区编码,来遍历全国门店数据;
- 地址转经纬度,通过coord-convert库实现GCJ-02转WGS84;
第一步:我们先找到对应数据存储位置,获取所有门店列表,经过测试,这里可以选择"通过行政区筛选",再选择"所有区域",每个区域会根据页数生成对应数量的html,我们通过修改行政区编码来进行数据获取,为了方便我们可以建立一个包含市级行政区编码的字典,通过遍历行政区编码来查询全国数据;
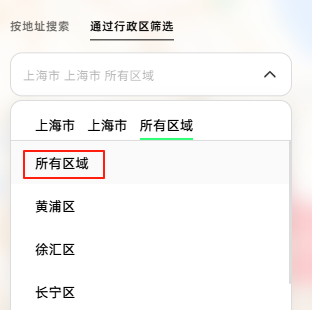
通过测试发现非直辖市,数据要想选到"所有区域",就得选择到市,以河北省为例,就是河北省→石家庄市,当然数据同样是通过改变编码进行传递的,但是这里是通过查询一个省,返回一个响应,所以意味着要查询所有省和自治区,才能知道所有编码;
但是我国的行政区编码通常都是一致的,所有我们去中华人民共和国民政部找最新的行政区划编码,下载下来;

通常,中国的行政区划编码规则如下:
- 省级:前两位有效,后四位为 0000(如 110000 北京市)
- 市级:前四位有效,后两位为 00,且不是 0000(如 110100 北京市市辖区)
- 县级:六位均为有效数字(如 110101 东城区)
因此,我们可以通过判断编码是否满足 XXXX00 且不等于 XXXX00(排除省级)来提取市级编码;
完整代码#运行环境 Python 3.11
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import csv# 配置表头
url = "https://www.mca.gov.cn/mzsj/xzqh/2023/202301xzqh.html"
headers = {"User-Agent": "Mozilla/5.0"}
output_file = "city_codes_2023.csv"# 获取并解析
print("正在获取数据...")
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')data = []
for row in soup.find_all('tr'):cells = row.find_all('td')if len(cells) >= 3:code = cells[1].get_text(strip=True)name = ''.join(cells[2].get_text().split()) # 清理空白if code.isdigit() and len(code) == 6 and code.endswith('00') and not code.endswith('0000'):if name not in ['市辖区', '县']:data.append((code, name))# 保存为CSV(带BOM,兼容Excel)
with open(output_file, 'w', encoding='utf-8-sig', newline='') as f:writer = csv.writer(f)writer.writerow(['编码', '名称'])writer.writerows(data)print(f"完成!共提取 {len(data)} 个市级单位,已保存为 '{output_file}'")
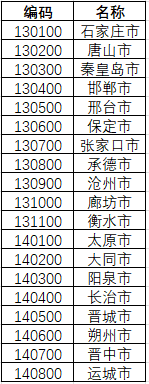
获取数据标签如下,城市编码城市名称,数据保存为city_codes_2023.csv,这里需要把上海(310100)、北京(110100)、天津(120100)、重庆(500100)这些直辖市手动加上,需要注意的是,例如北京市行政区划代码为110000,其中,110100为市辖区汇总码,所以这里直辖市使用的都是市辖区汇总码;
第二步:利用GET请求获取所有门店列表,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
# -*- coding: utf-8 -*-import requests
import csv
import time
from datetime import datetime# ================== 配置 ==================
CSV_INPUT = "city_codes_2023.csv" # 城市编码文件(含 "编码" 列)
CSV_OUTPUT = "oppo_shops_all_cities.csv" # 输出文件
API_URL = "https://opsiteapi-cn.oppo.com/api/public/v1/sfa/search"
HEADERS = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36","Referer": "https://www.oppo.com/"
}
PAGE_SIZE = 100
DELAY = 0.5 # 每个城市请求后延迟0.5秒,礼貌爬取# ================== 读取城市编码 ==================
def load_city_codes(filename):codes = []try:with open(filename, 'r', encoding='utf-8-sig') as f:reader = csv.DictReader(f)for row in reader:code = row.get("编码", "").strip()if code.isdigit() and len(code) == 6:codes.append(code)print(f"加载 {len(codes)} 个城市编码")except FileNotFoundError:print(f"错误:未找到文件 {filename},请确保 city_codes_2023.csv 存在")return []except Exception as e:print(f"读取城市编码失败: {e}")return []return codes# ================== 获取单个城市的所有门店数据 ==================
def fetch_all_pages(gid):all_shops = []page_no = 1while True:params = {"gid": gid,"shopType": "3","operateStatusList": "2","pageNo": page_no,"pageSize": PAGE_SIZE}try:response = requests.get(API_URL, params=params, headers=HEADERS, timeout=10)response.raise_for_status()data = response.json()if data.get("code") != "0":print(f"API 返回异常 (gid={gid}, page={page_no}): {data.get('message', 'Unknown')}")breakrecords = data["data"]["records"]all_shops.extend(records)# 获取总页数total_pages = data["data"]["pages"]print(f"获取 gid={gid} 第 {page_no}/{total_pages} 页,共 {len(records)} 条")if page_no >= total_pages:breakpage_no += 1time.sleep(0.1) # 短暂延迟,避免频率过高except Exception as e:print(f"请求 gid={gid} 第 {page_no} 页失败: {e}")breakreturn all_shops# ================== 保存所有门店数据 ==================
def save_to_csv(all_shops, filename):fieldnames = ["city_gid", "id", "name", "code", "fullShopAddress","lng", "lat", "shopBusinessStart", "shopBusinessEnd", "shopContactNumber"]with open(filename, "w", encoding="utf-8-sig", newline="", errors="replace") as f:writer = csv.DictWriter(f, fieldnames=fieldnames)writer.writeheader()for shop in all_shops:loc = shop.get("locationDTO", {}) or {}writer.writerow({"city_gid": shop.get("city_gid"), # 标记来源城市"id": shop["id"],"name": shop["name"],"code": shop["code"],"fullShopAddress": loc.get("fullShopAddress", ""),"lng": loc.get("lng", ""),"lat": loc.get("lat", ""),"shopBusinessStart": shop.get("shopBusinessStart", ""),"shopBusinessEnd": shop.get("shopBusinessEnd", ""),"shopContactNumber": shop.get("shopContactNumber", "")})print(f"所有数据已保存至: {filename}")# ================== 主函数 ==================
def main():print(f"开始获取 OPPO 门店数据 | {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")# 1. 加载城市编码city_codes = load_city_codes(CSV_INPUT)if not city_codes:returnall_shops = []success_count = 0fail_count = 0# 2. 遍历每个城市for i, gid in enumerate(city_codes, 1):print(f"[{i}/{len(city_codes)}] 正在获取城市 gid={gid} 的门店数据...")shops = fetch_all_pages(gid)# 添加城市标识for shop in shops:shop["city_gid"] = gidif shops:all_shops.extend(shops)success_count += 1else:fail_count += 1time.sleep(DELAY) # 控制请求频率# 3. 保存结果if all_shops:save_to_csv(all_shops, CSV_OUTPUT)print(f"完成!共获取 {len(all_shops)} 条门店数据,来自 {success_count} 个城市")if fail_count > 0:print(f"{fail_count} 个城市获取失败")else:print("未获取到任何门店数据")# ================== 运行 ==================
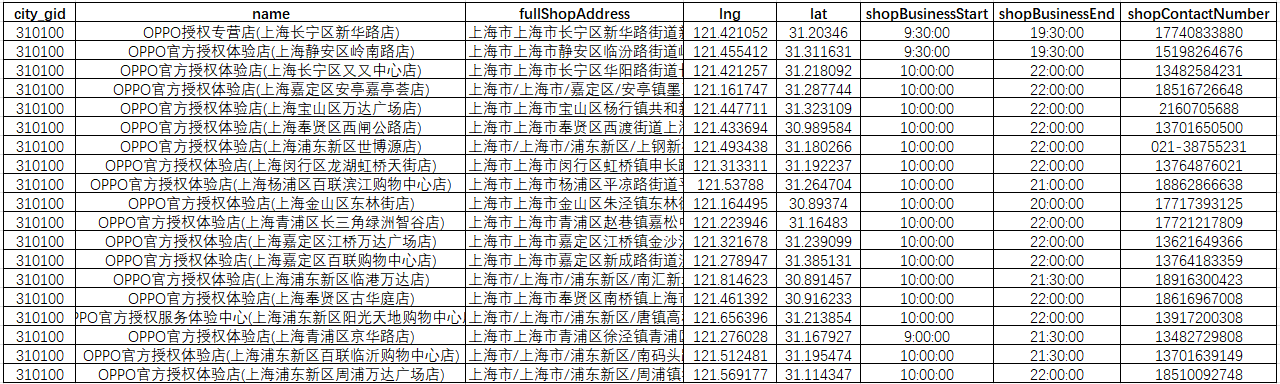
if __name__ == "__main__":main()获取数据标签如下,city_gid(行政区id)、id(门店id)、name(门店名称)、fullShopAddress(门店地址)、lng & lat(地理坐标)、shopBusinessStart(开始营业时间)、shopBusinessEnd(结束营业时间)、shopContactNumber(门店电话),其他一些非关键标签,这里省略;
第三步:坐标系转换,由于OPPO官方授权体验店门店数据使用的是高德坐标系(GCJ02),为了在ArcGIS上准确展示而不发生偏移,我们需要将门店的坐标从GCJ02转换为WGS-84坐标系。我们可以利用coord-convert库中的gcj2wgs(lng, lat)函数,也可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具;
对CSV文件中的服务网点坐标列进行转换,完成坐标转换后,再将数据导入ArcGIS进行可视化;
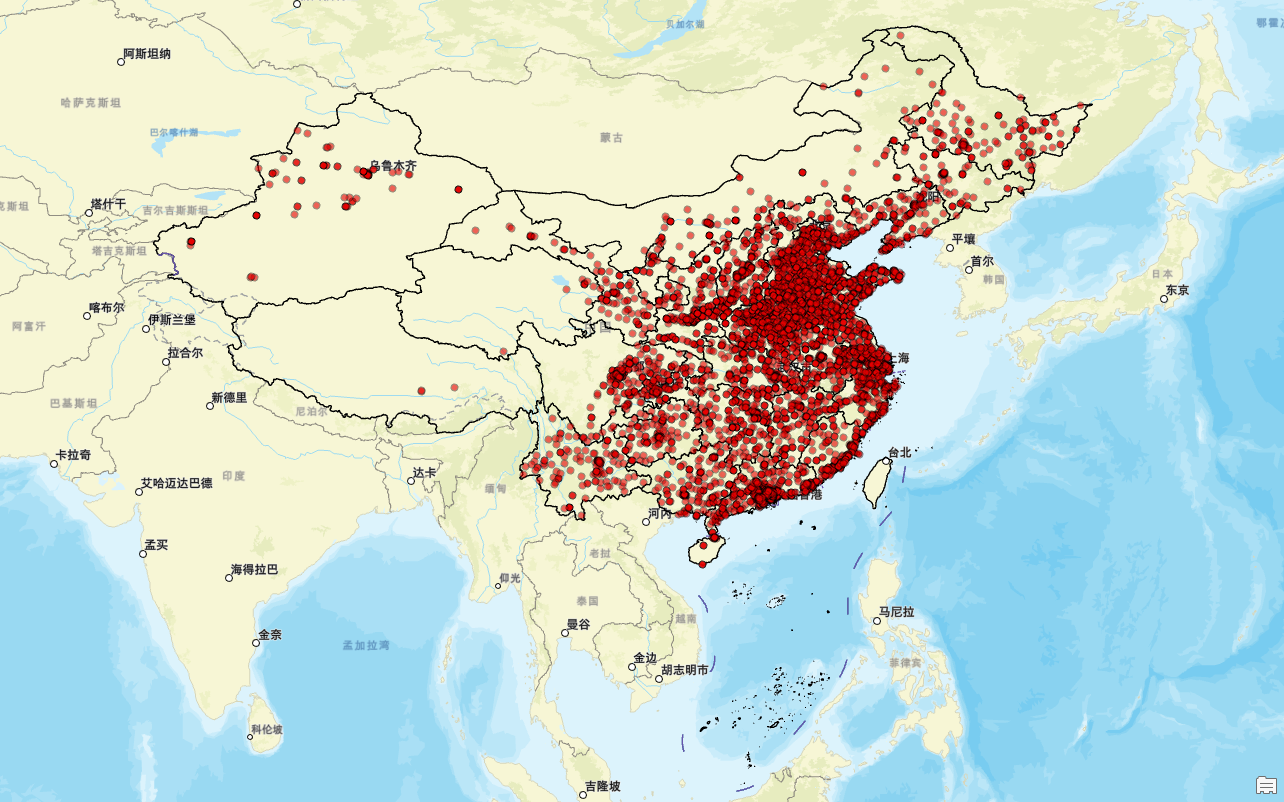
接下来,我们进行看图说话:
OPPO官方授权体验店在中国呈现出明显的地域性差异。高度集中的现象主要出现在东部和南部地区,尤其是华东、华南以及华中地区,这些区域店铺的数量显著多于其他地区。这表明OPPO在这些经济发达、人口密集且消费能力较强的区域有着更为广泛的布局。相对而言,稀疏分布的情况则出现在西北、东北及青藏高原等地理环境较为复杂的地区。
具体来看,在东部沿海地区,包括山东、江苏、浙江、福建和广东等省份,是体验店最为密集的地方。这里不仅是我国经济发展的前沿阵地,也是电子消费品的主要市场之一。城市覆盖广的特点不仅体现在省会城市和大城市,还包括了一些中小城市,显示出OPPO对于该地区市场的重视程度。而在中部地区,如河南、湖北、湖南等地,则构成了次级集中区。尽管店铺数量不及东部沿海,但依然反映出这些地区拥有较大的市场潜力和发展空间。
相比之下,西部和北部地区的分布显得较为稀疏。例如新疆、青海、西藏、内蒙古以及黑龙江等省份,由于地理环境、人口密度及经济发展水平等因素的影响,这里的体验店数量较少。不过,即便是这些地区,OPPO也倾向于选择省会城市或较大的城市进行重点布局,如乌鲁木齐、呼和浩特等,以确保品牌影响力和服务质量。
影响上述分布的因素众多,其中经济因素扮演着重要角色。经济发展水平和商业氛围较好的地方往往更受青睐;同时,人口因素也不可忽视,人口密度高且年轻人口比例大的地区,对于电子产品的需求量更大。此外,政策因素同样起到了推动作用,比如部分地区可能享有政府提供的税收优惠或者租金补贴等支持措施。
展望未来,OPPO有望继续深化其在东部和中部市场的战略布局,进一步增加体验店数量,并提升服务质量。与此同时,随着国家对西部大开发和东北振兴等战略的支持力度加大,逐步拓展西部和北部市场也将成为可能。通过不断优化店面选址和运营策略,OPPO可以根据不同地区的市场需求提供更加个性化和优质的服务,满足广大消费者的需求。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。

:解码器块,去模糊和提升图像清晰度)

)


免安装中文版)




)






)
