BPE
- 一、 BPETrain
- 1、 unicode standard and unicode encoding
- 2、 子词分词(subword tokenization)
- 3、 BPE的训练
- a、 Vocabulary initialization
- b、 Pre-tokenization
- c、 Compute BPE merges
- 4、 train_BPE更多实现上的细节
- 二、 BPETokenizer
- init函数
- from_files
- encode
- decode
- encode_iterable
- 三、 如何测试
- 四、 github完整代码
- 五、 总结
一、 BPETrain
1、 unicode standard and unicode encoding
unicode标准是一个字符集,它将字符对应到一个整数(被称为码点 code point),unicode standard 16包含154,998个字符,涵盖168种语言。
unicode encoding是一种编码方式,它将unicode字符对应到一个字节序列,Unicode standard定义了三种encoding 方式分别为utf-8、utf-16、utf-32,其中utf-8目前最为常用。
三者的对比如下:
| 特性 | UTF-8 | UTF-16 | UTF-32 |
|---|---|---|---|
| 字符长度 | 1-4 字节 | 2 或 4 字节 | 固定 4 字节 |
| ASCII 兼容性 | 完全兼容 | 不兼容 | 不兼容 |
| 存储效率 | 高效(尤其是英文文本) | 中等 | 低效 |
| 处理复杂度 | 处理非 ASCII 字符稍复杂 | 需要处理代理对 | 简单(固定宽度) |
| 适用场景 | 互联网、文件系统、数据库 | 操作系统、编程语言 | 特定需求 |
关于这部分内容可以看一下Python中二进制文件操作,了解一下python操作二进制字节文件的内容。
2、 子词分词(subword tokenization)
字词分词是一种介于byte-level tokenization和word-level tokenization的分词技术,两者的对比如下:
| 对比维度 | Word-level Tokenization(词级分词) | Byte-level Tokenization(字节级分词) |
|---|---|---|
| 分词单位 | 以“词”为最小单位(如 “你好”, “apple”, “the”) | 以“字节”为最小单位(如 b’h’, b’\xe4’) |
| 粒度 | 最粗粒度 | 最细粒度 |
| 词汇量 | 通常几千到几十万个词 | 固定为 256 个基础 token(0~255) |
| 是否支持未知词 | 无法处理未登录词(OOV) | 完全支持所有字符(无 OOV) |
| 是否语言相关 | 通常需要语言特定的词典或规则 | 语言无关,适用于任何语言 |
| 输入长度 | 较短 | 较长(每个字符可能拆成多个字节) |
word-level无法解决oov问题,同时词表长度太大,但是输入长度短,而byte-level可以结局oov问题,同时词表较短,但是输入长度太长,对于现在的LLM,输入长度过长会带来更大计算量,同时会有长距离依赖问题,为了trade-off两者,subword是一种很好的解决办法。
subword-level的思想很简单,就是将byte sequence中出现频次高的内容作为一个词表中新的entry。
关于如何选择subword加入词表,可以使用1994年Gage提出的BPE算法(Byte pair encoding)
3、 BPE的训练
bpe的训练过程主要分为三步:
- 词表初始化(Vocabulary initialization)
- 预分词(Pre-tokenization)
- 合并(Compute BPE merges)
a、 Vocabulary initialization
词表初始化(Vocabulary initialization):由于训练的是byte-level的BPE初始词表的大小应该是256。同时需要将,文本中会有一些special_tokens,这些special_tokens是不参与bpe的训练的,直接将这些内容加入到初始词表中。
## initialize vocabulary step
def initialize_vocabulary(special_tokens: list[str]
) -> dict[int, bytes]:vocabulary = {}vocabulary.update({i: special_tokens[i].encode("utf-8") for i in range(0, len(special_tokens))})vocabulary.update({i + len(vocabulary): bytes([i]) for i in range(256)}) return vocabulary
b、 Pre-tokenization
预分词(Pre-tokenization):如果直接开始进行merge,那么每次都需要遍历整个数据集的文本进行merge,这是一项耗时的操作,同时可能会导致dog! 、 dog.这两个词仅仅因为标点符号不一样就成为两个完全不同的subword被分配不同的id,尽管这两个词在语义上高度相似,它们也被认为是两个完全不同的词。pre-tokenization就是为了解决上面的问题,pre-tokenization可以被看作是一种粗粒度的tokenization,例如text是一个pre-token,同时text在全文中出现了10词,就不再需要看(t,e)pair在全文中出现了多少此,而是直接给(t,e)pair增加10。
这里我实现的pre_tokenization是直接返回的dict[tuple[bytes], int],也就是返回的每个tuple[bytes]出现的次数。
举个例子这里输入为"Hello word<|endoftext|>Hello ",special_tokens=["<|endoftext|>"]得到的结果就是
{(b'H', b'e', b'l', b'l', b'o'): 2,(b'w', b'o', b'r', b'l', b'd'): 1
}
这里的pre_tokenization会被抛弃,同时也没有保留原来的顺序,这样实现其实不好,对于后面使用tokenizer进行encode是不方便的,还需要重新实现,其实可以直接保留special_tokens, 同时保留原来的顺序,使用list可以满足这样的要求,对于每个tuple[bytes]出现的频率统计可以放到下一步merge中去做。
## pre_tokenization step
def pre_tokenization(input: str, special_tokens: list[str]
) -> dict[tuple[bytes], int]:escaped_tokens = [re.escape(tok) for tok in special_tokens]split_pattern = "|".join(escaped_tokens) # 按special_tokens分割inputmatch_pattern = re.compile(r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""") # 分割后匹配除去special_tokens中的wordsplit_texts = re.split(split_pattern, input) # 得到分割后的文本,格式为listpre_tokens = {}for split_text in split_texts:for word in match_pattern.finditer(split_text):word_str = word.group(0).encode("utf-8")bytes_word_tuple = tuple(bytes([word]) for word in word_str)pre_tokens[bytes_word_tuple] = pre_tokens.get(bytes_word_tuple, 0) + 1 return pre_tokens
c、 Compute BPE merges
合并(Compute BPE merges):迭代合并时不考虑夸pre-token的情况,同时当有多个byte pair频率相同时,选择字典序更大的byte pair进行合并。
出了初始词表中的token、和BPE算法合并产生的token,还有一些special token,这些token有的用来表示元数据具有一些特殊的作用,也应该被加入到词表中。
get_pair_freq:由于pre_tokenization步骤得到的结果是如下格式:
{(b'H', b'e', b'l', b'l', b'o'): 2,(b'w', b'o', b'r', b'l', b'd'): 1
}
而merge需要相邻bytes pair出现频率最高的那一对然后合并,所以get_pair_freq的作用就是统计相邻bytes pair的频率:
def get_pair_freq(word_counts: Counter[tuple[bytes]]
) -> Counter[tuple[bytes]]:freq_pair: Counter[tuple[bytes]] = {}for word, cnt in word_counts.items():for i in range(len(word) - 1):pair = (word[i], word[i + 1])freq_pair[pair] = freq_pair.get(pair, 0) + cntreturn freq_pair
find_pair是为了获得出现频率最高的pair,当有多个这样的pair时会返回字典序最大的。
## merge_tools
def find_pair(freq_pair: Counter[tuple[bytes]]
) -> tuple[bytes]:max_value = max(freq_pair.values())max_pair = max([k for k, v in freq_pair.items() if v == max_value])return max_pair
对于pre_tokenization得到的数据是一个list[tuple[bytes]],分开处理每一个tuple[bytes]
{(b'H', b'e', b'l', b'l', b'o'): 2,(b'w', b'o', b'r', b'l', b'd'): 1
}
也就是说处理对于上面的数据分别处理
(b'H', b'e', b'l', b'l', b'o')
(b'w', b'o', b'r', b'l', b'd')
get_merged_word这个函数就是对每一个tuple[bytes]进行merge,然后返回merge后得到的新tuple[bytes]。
## merge_tools
def get_merged_word(word: tuple[bytes], cmp_pair: tuple[bytes]
) -> tuple[bytes]:new_word = [] # 存储merge后的wordlength, cur = len(word), 0while cur < length:if cur + 1 < length: # 当还能组成的pair时if (word[cur], word[cur + 1]) == cmp_pair: # 找到了可以merge的对象new_word.append(word[cur] + word[cur + 1])cur += 2else:new_word.append(word[cur])cur += 1 else:new_word.append(word[cur])cur += 1return tuple(new_word)
4、 train_BPE更多实现上的细节
由于pre_token非常耗时,所以采用多进程并行处理,如何进行多进程并行处理?
首先是将数据集进行chunk,具体的chunk规则可以参考assignment1-basics/cs336_basics/pretokenization_example.py中的代码,find_chunk_boundaries这个函数将输入chunk成几个完整的内容,他并不是单一严格按字节分割,而是会在字节后面的第一个special_token位置进行分割。分割的方式如图所示:
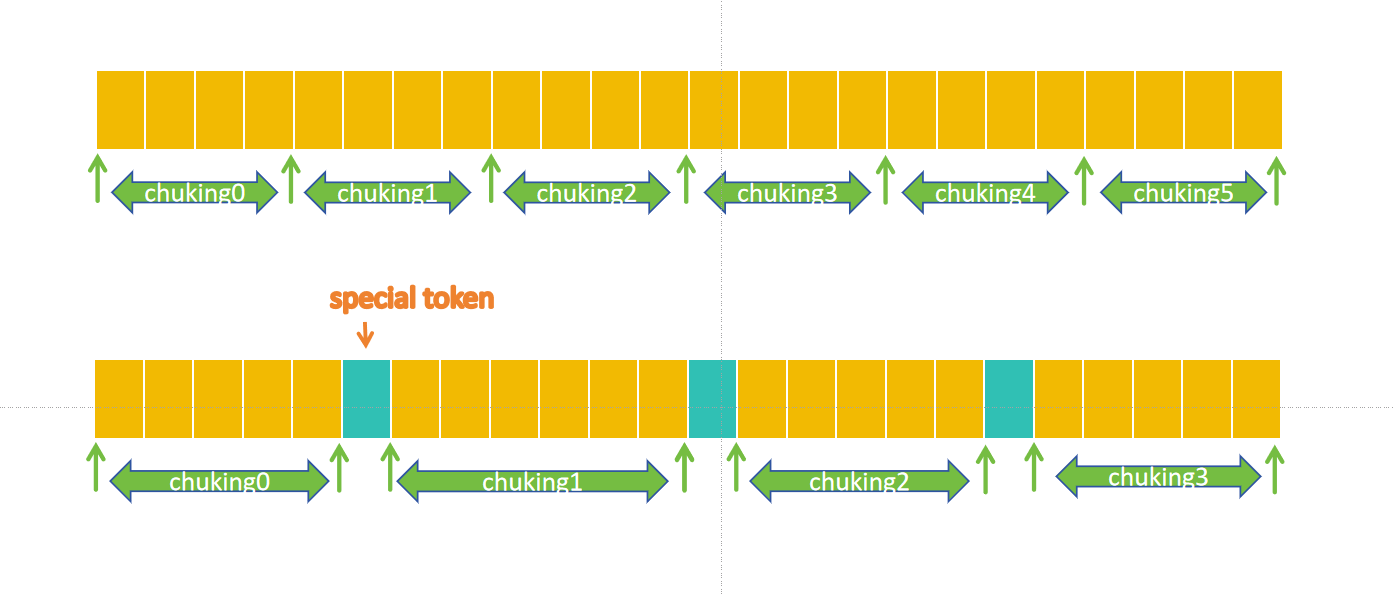
然后分别对每个分割得到chunking进行多进程并行pre-token,多进程可以使用python的内置模块multiprocessing,如果不了解可以参考Python多进程并行multiprocess基础。
下面是多进程训练的代码:merge_pre_tokens用于将得到的多个pre_tokens字典合并为一个字典。
def merge_pre_tokens(dicts: list[Counter[tuple[bytes]]]
) -> Counter[tuple[bytes]]:merged_counter = Counter()for counter in dicts:merged_counter.update(counter)return merged_counter## 多进程进行pre_tokenization
def parallel_pre_tokenization(file_path: str, special_tokens: list[str], num_workers: int = None
) -> Counter[tuple[bytes]]:params = []with open(file_path, 'rb') as f:boundary = find_chunk_boundaries(f, num_workers, special_tokens[0].encode("utf-8")) for left, right in zip(boundary[:-1], boundary[1:]):f.seek(left)chunk = f.read(right - left).decode("utf-8", errors="ignore")params.append((chunk, special_tokens))with Pool(processes=num_workers) as pool:result_dicts = pool.starmap(pre_tokenization, params)return merge_pre_tokens(result_dicts)
最后可以优化merge的过程,由于merge的过程会每次都去遍历pre_tokens,然后统计byte-pair的出现次数,最后找到byte-pair的最大值作为本次merge的byte-pair。这个过程需要遍历所有的tokens,可以采用一种增量遍历的方式。
预处理一个全局byte-pair出现的频次表格式如下:
freq = {(b'a', b'b'): 3,(b'a', b'c'): 2,(b'a', b'd'): 10,(b'a', b'e'): 11,(b'ad', b'e'): 13
}
本次更新选中了(b'a', b'd')作为best_pair,找出来含有best_pair的token,然后对于一个满足的wordA,先全局byte-pair中把A的所有byte-pair减去,然后加上新生成的word产生的pair。
将上面的三个步骤集成起来就得到下面的训练函数
def train_bpe(input_path: str, vocab_size: int, special_tokens: list[str]
) -> tuple[dict[int, bytes], list[tuple[bytes, bytes]]]:## setp1 initinalize vocabularyvocabulary: dict[int, bytes] = initialize_vocabulary(special_tokens)## setp2 pre tokenization# file_path = "assignment1-basics/data/TinyStoriesV2-GPT4-train.txt"word_counts = parallel_pre_tokenization(input_path,special_tokens,16)cur_id: int = len(vocabulary)merges: list[tuple[bytes, bytes]] = []## step3 BPE mergeneed_merge_cnt: int = vocab_size - cur_idpair_freqs = get_pair_freq(word_counts)for i in tqdm(range(need_merge_cnt)): # 迭代merge频次最高的byte-pairif not pair_freqs:breakbest_pair = find_pair(pair_freqs)merges.append(best_pair)vocabulary[cur_id] = best_pair[0] + best_pair[1]cur_id += 1# 找出所有需要更新的wordwords_need_update = {}for word, cnt in word_counts.items():if best_pair[0] in word and best_pair[1] in word:for i in range(len(word) - 1):if (word[i], word[i + 1]) == best_pair:words_need_update[word] = cntbreak# 更新word_countsfor word, cnt in words_need_update.items():# 增量更新pair频率表for i in range(len(word) - 1):pair = (word[i], word[i + 1])pair_freqs[pair] = pair_freqs.get(pair, 0) - cntdel word_counts[word]new_word = get_merged_word(word, best_pair)word_counts[new_word] = word_counts.get(new_word, 0) + cntfor i in range(len(new_word) - 1):pair = (new_word[i], new_word[i + 1])pair_freqs[pair] = pair_freqs.get(pair, 0) + cntreturn vocabulary, merges
二、 BPETokenizer
cs336的文档中已经说明了BPETokenizer类中必须实现的接口。

init函数
即初始化tokenizer,这里的vocab,merges,special_tokens都和上面训练时的格式类型一致。
def __init__(self, vocab: dict[int, bytes], merges: list[tuple[bytes, bytes]], special_tokens: list[str] | None = None): self.vocab = vocabself.merges = mergesself.special_tokens = special_tokens
from_files
文档中要求实现一个可以从路径中加载vocab和merges的功能。这里我是仿照他给的pytest测试里assignment1-basics/tests/test_tokenizer.py的get_tokenizer_from_vocab_merges_path写的,里面的bytes_to_unicode函数就是将256个字节都能可视化显示,因为有很多控制字符space什么的是没法,显示的,这里是因为它测试读取的vocab、merges保存的格式是这样的所以读取的时候还要将它保存的格式转换为0~255的bytes。测试用的vocab、merges在assignment1-basics/tests/fixtures/gpt2_vocab.json和assignment1-basics/tests/fixtures/gpt2_merges.text。
@classmethoddef from_files(cls, vocab_filepath: str, merges_filepath: str, special_tokens: list[str] | None = None) -> BPETokenizer:@lru_cachedef bytes_to_unicode() -> dict[int, str]:bs = list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))cs = bs[:]n = 0for b in range(2**8):if b not in bs:bs.append(b)cs.append(2**8 + n)n += 1characters = [chr(n) for n in cs]d = dict(zip(bs, characters))return ddef bytes_to_str(b: bytes) -> str:byte_to_uni = bytes_to_unicode()s = ""for bit in b:s.join(byte_to_uni[bit])return sdef str_to_bytes(s: str) -> bytes:byte_to_uni = bytes_to_unicode()byte_decoder = {v: k for k, v in byte_to_uni.items()}ans = bytearray()for c in s:ans.extend([byte_decoder[c]])return bytes(ans)# 处理vocabtry:with open(vocab_filepath, "r", encoding="utf-8") as f:vocab_ = json.load(f)except Exception as e:raise RuntimeError(f"Error loading vocabulary from {vocab_filepath}: {e}")vocab = {v: str_to_bytes(k) for k, v in vocab_.items()}# 处理mergesmerges_ = []with open(merges_filepath, 'r', encoding="utf-8") as f:for line in f:clean_line = line.strip()if clean_line and len(clean_line.split(" ")) == 2:merges_.append(tuple(clean_line.split(" ")))if special_tokens:for special_token in special_tokens:byte_encoded_special_token = special_token.encode("utf-8")if byte_encoded_special_token not in set(vocab.values()):vocab[len(vocab)] = byte_encoded_special_tokenmerges = [(str_to_bytes(str1), str_to_bytes(str2),)for str1, str2 in merges_]return cls(vocab, merges, special_tokens)
encode
当我们训练好了一个BPEtokenzier后,就可以通过得到vocab和一个merge对输入的文本进行tokenization。
这里encode的步骤分为三步,第一步首先进行pre-tokenization,然后进行merge,最后在词表中查看每个词元对应的id。
首先是pre-tokenization,训练时的pre-tokenization是先按special_tokens进行split,然后将special_tokens丢弃,然后再按gpt2的pat模式去分割。在使用时,不能舍弃special_tokens,同时需要保留每个词的顺序。
十分需要注意并小心的corner case就是special_tokens为None的情况,当special_tokens为None时,不都对special_tokens使用sorted,同时第一步按special_tokens分割,结果应该是[text],list包裹原始文本。
def pre_tokenization(self,text: str, ) -> list[tuple[bytes]]:special_tokens = sorted(self.special_tokens, key=lambda x: -len(x)) if self.special_tokens is not None else []escaped_tokens = [re.escape(tok) for tok in special_tokens] if special_tokens else []split_pattern = "(" + "|".join(escaped_tokens) + ")" # 按special_tokens分割inputmatch_pattern = re.compile(r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")split_texts = re.split(split_pattern, text) if len(escaped_tokens) != 0 else [text]# 得到分割后的文本,格式为listpre_tokens = []for split_text in split_texts: if self.special_tokens != None and split_text in self.special_tokens:pre_tokens.append((split_text.encode('utf-8'),))else:for word in match_pattern.finditer(split_text):word_str = word.group(0).encode("utf-8")bytes_word_tuple = tuple(bytes([word]) for word in word_str)pre_tokens.append(bytes_word_tuple)return pre_tokens
其次是merge,这里merge要按保存的byte-pair的顺序去merge,因为本身文本训练的时候merge就是按顺序的,最开始写这个merge的时候没有按顺序debug了好久。
这里merge这一步我实现了两个函数,首先是merge函数,这个merge函数用于pre_tokenization得到的单个的tokens就是tuple[bytes]的merge,tokens的形状类似是这样的(b'h', b'e', b'l', b'l', b'o'),然后返回的结果的类型是tuple[bytes],对于(b'h', b'e', b'l', b'l', b'o')这个例子,返回的结果可能是(b'he', b'll', b'o')。
def merge(self,pre_token: tuple[bytes],ranked_merges: dict[bytes, int]) -> tuple[bytes]: while True:cur_min_rank = len(ranked_merges)best_pair = Nonefor i in range(len(pre_token) - 1):pair = pre_token[i] + pre_token[i + 1]rk = ranked_merges.get(pair, float('inf'))if rk < cur_min_rank:cur_min_rank = rkbest_pair = pairif best_pair is None:breaknew_token = []i = 0while i < len(pre_token):if i + 1 < len(pre_token) and pre_token[i] + pre_token[i + 1] == best_pair:new_token.append(best_pair)i += 2 else:new_token.append(pre_token[i])i += 1pre_token = new_tokenreturn pre_token
merge_pre_tokens是将pre_tokenization得到的pre_tokens列表里面的每个pre_tokens都应用上面的merge合并,得到的结果就是最终的合并后的tokens。
这里的小细节需要注意的是对于special_tokens,其不需要merge,也就是说我们在遍历的时候遇到了
(b'<|endoftext|>, )'的时候直接将他append进我们的结果列表中即可
def merge_pre_tokens(self,pre_tokens: list[tuple[bytes]],) -> list[tuple[bytes]]:merged_tokens: list[tuple[bytes]]= []special_tokens_bytes = ([tuple(special_token.encode('utf-8')) for special_token in self.special_tokens]if self.special_tokens else [])ranked_merges = {bytes1 + bytes2: idx for idx, (bytes1, bytes2) in enumerate(self.merges)}for pre_token in pre_tokens:if pre_token in special_tokens_bytes:merged_tokens.append(pre_token)else:merged_tokens.append(self.merge(pre_token, ranked_merges))return merged_tokens
最后实现文档要求的接口encode,集成上面的功能,在vocab中查找每个bytes对应的id进行替换,然后返回id的列表即可。
def encode(self, text: str) -> list[int]:token_to_id = {token: id for id, token in self.vocab.items()}tokens = []pre_tokens = self.pre_tokenization(text)merged_tokens = self.merge_pre_tokens(pre_tokens)joined_tokens = []for word in merged_tokens:for b in word:joined_tokens.append(b)return [token_to_id.get(token, -1) for token in joined_tokens]
decode
decode函数就很简单了,查找词表vocab,将每个token_id还原回bytes,然后进行拼接,再按utf-8的格式decode成str即可。 errors="replace"这个参数的作用实现的是文档里面黄色的部分,即可能decode的输入token_ids并非是配套的encode得到的,就可能有不合法的部分。无法用unicode解码的就用U+FFFD替换。

def decode(self, ids: list[int]) -> str:joined_bytes = bytearray()for id in ids:joined_bytes.extend(self.vocab[id])return bytes(joined_bytes).decode("utf-8", errors="replace")
encode_iterable
当需要encode比较大的文件时,可能无法将本文全部加载进内存,这时就需要流式读取,一部分一部分进行encode。已经实现了上面的encode这个功能就比较简单了,就是调用一下encode,然后使用python中的yield from即可。关于yield from的用法参考Python中yield和yield from
def encode_iterable(self, iterable: Iterable[str]) -> Iterator[int]:for chunk in iterable:if not chunk:continuetoken_ids = self.encode(chunk)yield from token_ids
三、 如何测试
这门课程可以使用pytest在本地进行测试,先进入assignment1-basic/tests中。
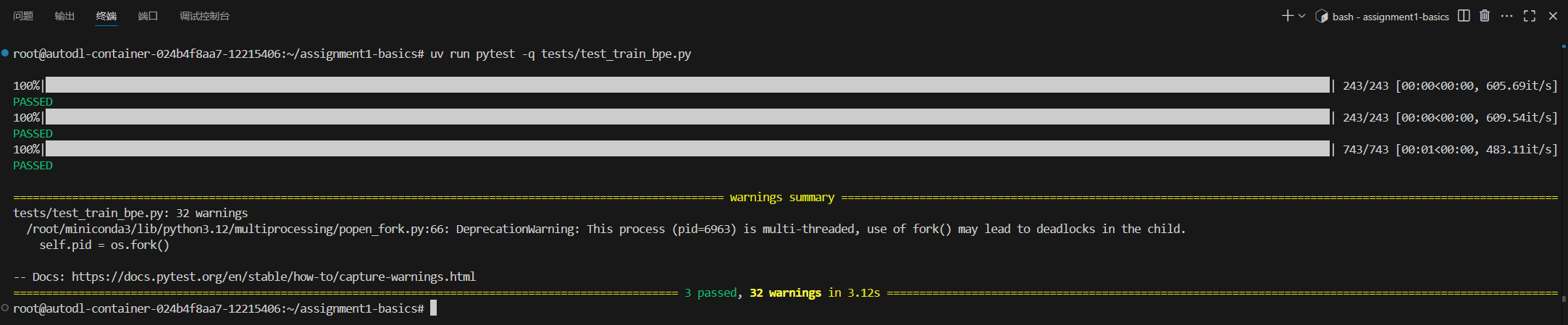
要测试train_bpe部分的内容就运行
pytest train_bpe.py
上面的pytest命令会运行train_bpe.py中以**test_**开头的所有测试函数。
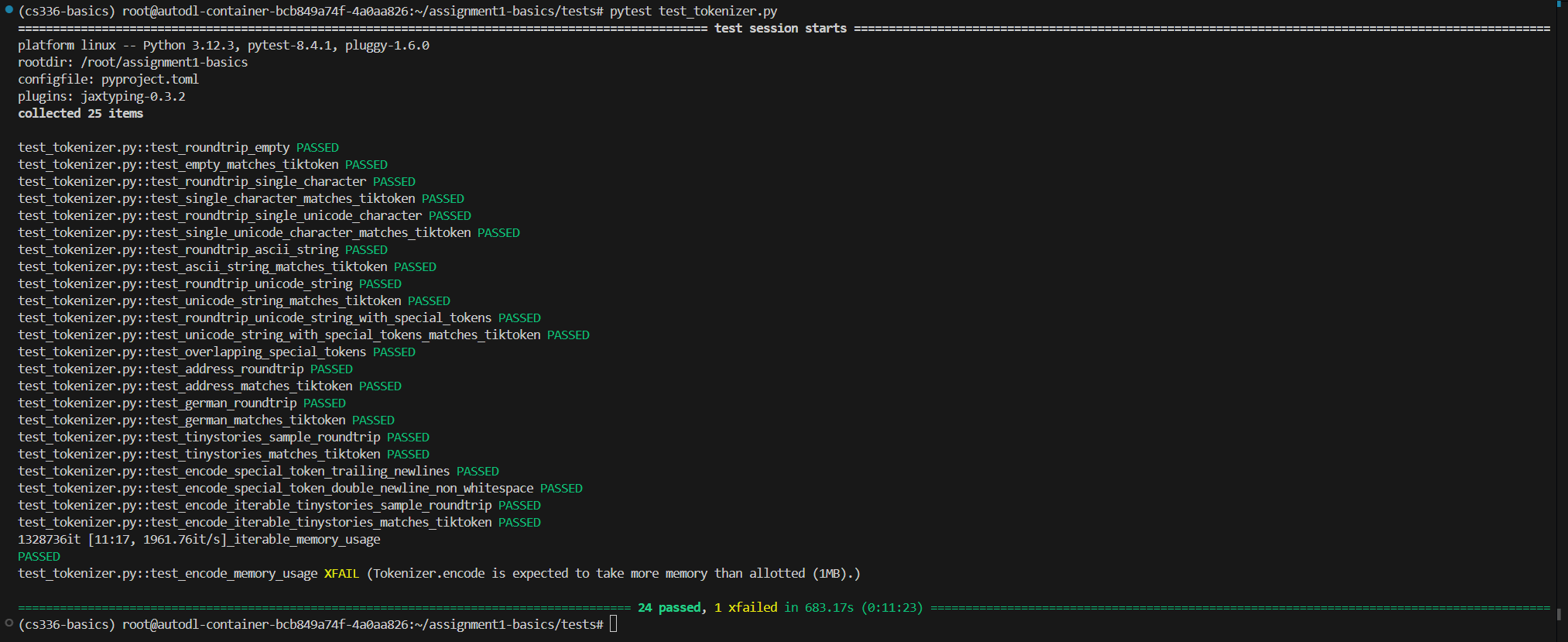
要测试tokenizer部分的内容就运行:
pytest test_tokenizer.py
当然对于具体哪个测试没过可以看一下测试代码,也方便debug。
关于pytest的应用可以参考这个链接coming soon(还没写,写好再发)
然后你就可以顺利通过测试了~~,需要注意的是test_tokenizer的最后一个测试出现XFailed没有关系,可以进到test中看一下那个函数,里面有说明。
四、 github完整代码
github仓库链接cs336 assignment1 BPETokenizer
五、 总结
关于这个BPE Tokenizer的细节确实很多,实现的时候也学到了很多东西。



)







![洛谷P1036 [NOIP 2002 普及组] 选数](http://pic.xiahunao.cn/洛谷P1036 [NOIP 2002 普及组] 选数)
文件共享)



详细教程(2025.3最新可用镜像,全网最详细))


