交叉验证(Cross-Validation)是机器学习中评估模型性能、选择最优参数和防止过拟合的核心技术。它在整个机器学习流程中扮演着关键角色。
一、为什么需要交叉验证?
1. 解决训练/测试划分的局限性
- 问题:随机单次划分训练集/测试集可能导致:
- 评估不稳定:不同划分结果差异大
- 数据利用低效:测试集固定且单一
- 解决方案:交叉验证循环使用数据作为测试集
2. 避免过拟合
- 问题:在测试集上直接调参会导致"模型过拟合测试集"
- 解决方案:在交叉验证的内部循环中进行参数调整,保留独立测试集用于最终评估
3. 提高数据利用效率
- 小样本场景:交叉验证最大化利用有限数据(尤其医疗、金融等数据获取难的领域)
二、交叉验证在机器学习流程中的位置
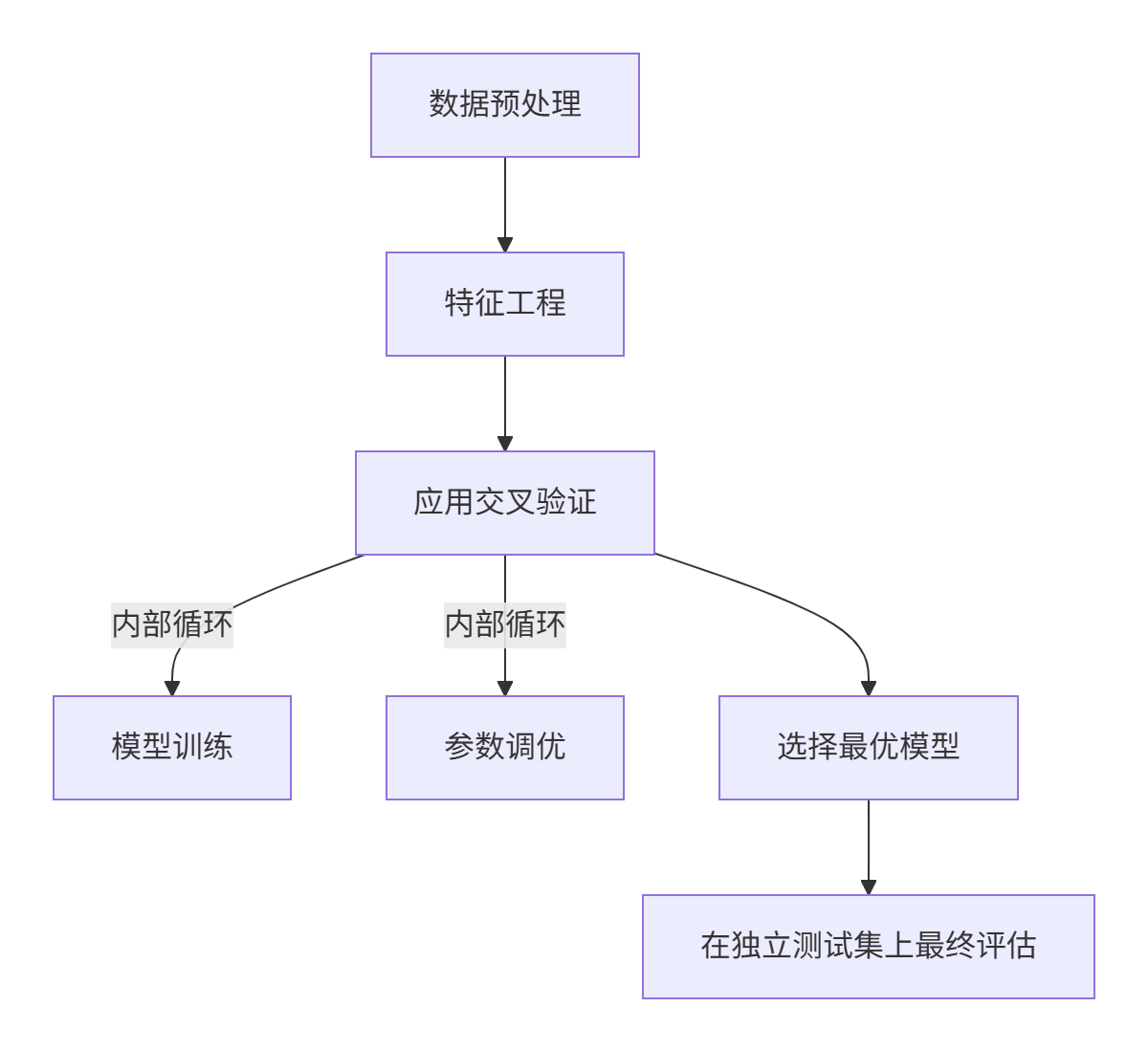
交叉验证在机器学习三大阶段的角色
模型训练阶段
- 交叉验证提供多个训练/验证循环
- 每个循环中用部分数据训练,剩余数据验证
模型评估阶段
- 将k次验证结果平均作为模型性能评估
- 比单次验证更稳定可靠
参数调优阶段
- 网格搜索(GridSearchCV)的核心是交叉验证
- 系统地探索不同参数组合的效果
三、交叉验证的常见类型
1. K折交叉验证(K-Fold)
将数据分为K个大小相似的互斥子集,每次用K-1个子集训练,剩余1个测试

from sklearn.model_selection import KFoldkf = KFold(n_splits=5) # 5折交叉验证
for train_index, test_index in kf.split(X):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]# 训练并评估模型
from sklearn.model_selection import cross_val_score# 执行交叉验证(此处为示例模板,实际需要具体模型和数据)
scores = cross_val_score(estimator, # 模型对象(如LogisticRegression)X, # 特征矩阵y, # 目标向量cv=5, # 交叉验证折叠数(K折交叉验证)scoring='accuracy', # 评估指标(可用'recall', 'precision', 'f1'等)n_jobs=-1 # 使用全部CPU核心并行计算
)# 实际应用中模型和评分指标选择示例:
# from sklearn.linear_model import LogisticRegression
# model = LogisticRegression()
# scores = cross_val_score(model, X, y, cv=5, scoring='recall', n_jobs=-1)2. 分层K折交叉验证(Stratified K-Fold)
保持每个折中类别的分布与完整数据集相同
from sklearn.model_selection import StratifiedKFoldskf = StratifiedKFold(n_splits=5) # 分层5折3. 留一交叉验证(Leave-One-Out, LOO)
每个样本都单独作为测试集一次(极端的K=N折)
from sklearn.model_selection import LeaveOneOutloo = LeaveOneOut()4. 时间序列交叉验证(Time Series Split)
考虑时间依赖关系,确保未来数据不用于预测过去
from sklearn.model_selection import TimeSeriesSplittscv = TimeSeriesSplit(n_splits=5)四、交叉验证在模型选择中的应用示例
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression# 创建逻辑回归模型
model = LogisticRegression(max_iter=1000)# 执行5折交叉验证
cv_scores = cross_val_score(model, X_train, y_train,cv=5, # 5折交叉验证scoring='recall', # 评估指标为召回率n_jobs=-1 # 使用所有CPU核心
)# 计算平均分
mean_recall = np.mean(cv_scores)
print(f"平均召回率: {mean_recall:.4f} (±{np.std(cv_scores):.4f})")五、交叉验证在网格搜索中的应用示例
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100],'penalty': ['l1', 'l2']
}# 设置网格搜索交叉验证
grid_search = GridSearchCV(LogisticRegression(solver='liblinear', max_iter=1000),param_grid,cv=5, # 5折交叉验证scoring='roc_auc',# 使用AUC评分n_jobs=-1
)# 执行网格搜索
grid_search.fit(X_train, y_train)# 输出最优参数
print(f"最优参数: {grid_search.best_params_}")六、交叉验证与数据集大小的关系
| 数据规模 | 推荐方法 | 原因 |
|---|---|---|
| 大样本(>10万) | 简单训练/验证/测试分割 | 计算效率优先 |
| 中样本(1千-10万) | K折交叉验证(K=5或10) | 平衡稳定性和计算量 |
| 小样本(<1千) | 留一交叉验证或分层K折(K=10) | 最大化数据利用 |
七、交叉验证的最佳实践
数据分布:
- 不平衡数据使用分层交叉验证
- 时间序列数据使用时序交叉验证
计算效率:
- 数据量大时考虑缩小K值或使用ShuffleSplit
- 并行计算加速(n_jobs参数)
结果解释:
- 考虑交叉验证分数的方差
- 检查不同折之间的性能差异
避免泄露:
- 所有特征工程步骤应在每个折叠中独立进行
- 永远不要在交叉验证循环中包含测试集数据
交叉验证是机器学习实践中最实用、最核心的技术之一,掌握它可以显著提升建模的稳健性和可靠性。在整个机器学习流程中,从模型开发到参数选择再到最终评估,交叉验证都扮演着不可或缺的角色。

)







![洛谷P1036 [NOIP 2002 普及组] 选数](http://pic.xiahunao.cn/洛谷P1036 [NOIP 2002 普及组] 选数)
文件共享)



详细教程(2025.3最新可用镜像,全网最详细))



)
-卷积神经网络架构)